导语:本文为四川华迪数据计算平台使用 OceanBase 替代 Hadoop 的实践,验证了 OceanBase 在性能和存储成本方面的优势:节省了 60% 的硬件成本,并将运维工作大幅减少,从 Hadoop 海量组件中释放出来;一套系统处理 HTAP 场景需求,简化了运维复杂度。
作者简介:向平,现任四川华迪信息技术有限公司智慧医养研发部技术总监,主要负责智慧医养板块大数据和人工智能相关架构设计和团队管理工作。
随着老龄化现象加剧,养老问题逐渐成为社会广泛关注的话题,尤其是健康养老这个难题,需要汇聚社会各方智慧、资源和力量来破解。
四川华迪信息技术有限公司(以下简称“华迪”)充分利用大数据、云计算、物联网、人工智能、移动互联网等新一代信息技术的融合创新,打造了“齐家乐智慧医养大数据公共服务平台”。并与项目示范所在地政府及其主管部门合作共同探索和创建了“校地企智慧医养新模式”,汇聚居民社区、老人亲属、养老机构、医疗机构、医学院、地方政府、科技企业、以及生活服务机构等各方力量,为适龄老人提供专业、高效、便捷、安全的健康养老服务。
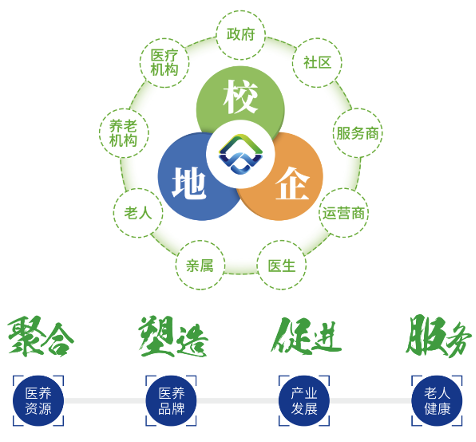

“齐家乐”平台是医养结合的资源整合平台、工作平台、服务平台、宣传平台,将健康信息预警、慢病和老年病辅助决策、医养结合服务、健康知识学习等功能融为一体,形成了纵贯省、市、县(区)、乡镇(街道)、村(社区)五级,全方位、专业化、综合性医养公共服务网络,打造多层级“健康数据采集→大数据分析预警→干预服务→效果评价”的智慧医养闭环服务体系。形成了以老年人群为主,聚合家庭、社区、医养机构、医院、政府为一体的多场景医养服务模式,通过实时、实名、动态、连续的现代社区智慧医养服务,实现医养信息和医养资源的人联、智联、物联。
我们依托医院和政府积累的医疗数据、养老数据、产业数据,形成数据资源池,借助大数据系统对资源进行存储和计算,完成了一个处理能力强且易于扩展的数据计算平台的搭建。我们的数据计算平台能够对海量数据进行存储、清洗、加工、建模、分析等,并且充分利用资源池中的每一条数据,形成各个维度数据的聚合,为统计决策分析、算法分析服务、大数据预测等应用提供更充足的参考数据,从而实现对医疗数据更深层的价值挖掘。

目前,我们已经积累了 20TB 左右数据总量,前期使用 Hadoop 生态搭建数据计算平台,如下图所示。
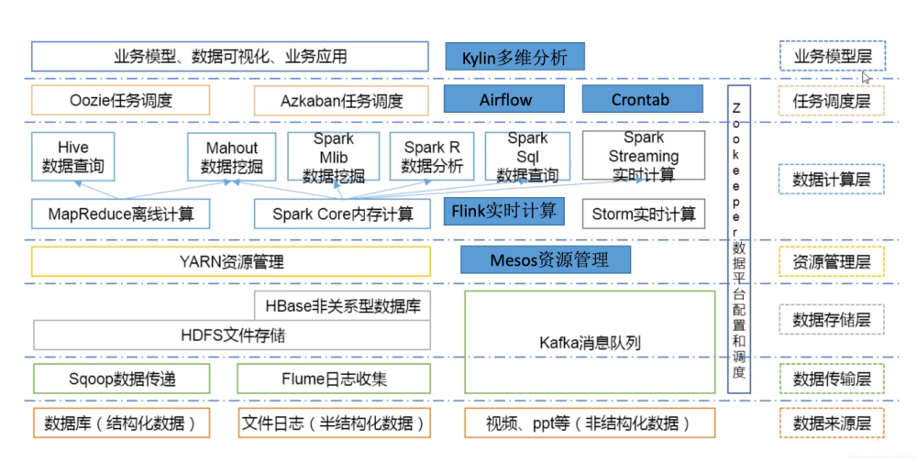
但是我们在使用和运维这套环境的过程中遇到很多问题,比如组件过多、搭建复杂、运维成本高。最关键的问题是,这套复杂的环境出现故障后难以排查,不能及时解决。
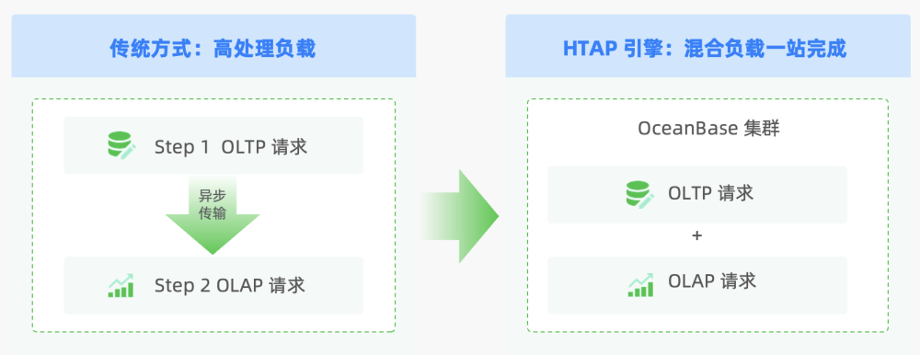
为了解决上述问题,我们开始对分布式数据库进行调研。其中,我们通过阅读 OceanBase 官方文档、浏览开源社区中的博客和问答区的内容,了解到 OceanBase 支持单集群部署上千个 OBServer 节点,单集群最大数据量早已达到 PB 级别,最大单表行数达万亿级。基于“同一份数据,同一个引擎”,同时支持在线实时交易及实时分析两种场景,“一份数据” 的多个副本可以存储成多种形态,用于不同工作负载。并且提供了自动迁移工具 OMS,支持迁移评估和反向同步以保障数据迁移安全。
考察到 OceanBase 的开源生态产品可以满足我们数据的规模和数据计算平台的需求后,我们进行了初步测试。我们首先注意到了 OceanBase 的 HTAP 能力,其次还提供了以下 5 项能力,这对我们而言非常重要。
-
易运维。每个 OBServer 节点内都包含了存储引擎和计算引擎,节点之间对等,组件数量少、部署简单、易于运维,不需要我们再为数据库补充其他组件来实现高可用及自动故障转移等功能。
-
高压缩。基于 LSM-Tree 数据组织形式,全量数据 = 增量数据 + 基线数据。因为数据首先会写入增量数据中的 Memtable 中,Memtable 是内存中的数据,所以写入性能相当于内存数据库的性能。基线数据是静态数据,只有在下次合并的时候才会有变化,可以采用比较激进的压缩算法,从而实现了至少 60% 的压缩率。我们从 Oracle RAC 集群把数据迁移到 OceanBase 之后,利用三备份存储模式磁盘占用率只用到原先的 1/3 左右。(*关于 OceanBase 数据压缩的核心技术可以阅读《历史库存储成本节约至少 50% ,OceanBase数据压缩核心技术解读》)
-
高兼容。目前 OceanBase 社区版本几乎完美兼容了 MySQL 的语法和功能,大部分统计分析任务基于 SQL 就可以达到目的, OceanBase 还支持我们经常用到的存储过程、触发器等高级功能。
-
高扩展。OceanBase 提供线性扩展的能力,在数据量增大之后,可通过增加服务器节点的数量实现性能的线性扩展,并且增加节点只需要我们的 DBA 执行一条命令。集群扩容之后,数据会在节点之间进行自动的负载均衡,DBA 同学不需要再亲自去搬迁数据了。
-
高可用。OceanBase 原生具备高可用的能力,通过 Paxos 协议实现分区级别的高可用,在少数派节点出现故障之后,依然能够提供服务,对业务无影响。

(一)架构变化
我们原来数据计算平台的架构是利用 10 台机器部署的一个 Hadoop 环境,其中使用了 20 多种不同的开源组件,这些组件分别负责数据导入导出、数据清洗和 AP 分析等功能。我们会先使用 ETL 工具把原始数据传到 HDFS 上,然后通过 Hive 的命令进行装载,最后再用 Spark SQL 做数据分析。
在这种架构下,数据需要来来回回地反复倒腾,而且和大量组件相关的版本适配、性能调优等工作,也需要非常专业的同学来做。最关键的是组件多、链路长,排查问题的环节太多,很多问题难以在短时间内定位具体是哪个组件出了问题。
最初,我们只是想使用 OceanBase 对数据进行整合和清洗:数据通过专线拉到前置机(Oracle RAC),再从前置机通过 ETL 工具 DataX 把数据拉到 OceanBase ,在 OceanBase 中进行数据的解密、清洗和整合,最后将清洗之后的数据从 OceanBase 拉到 Hadoop 环境进行 AP 分析(见下图)。
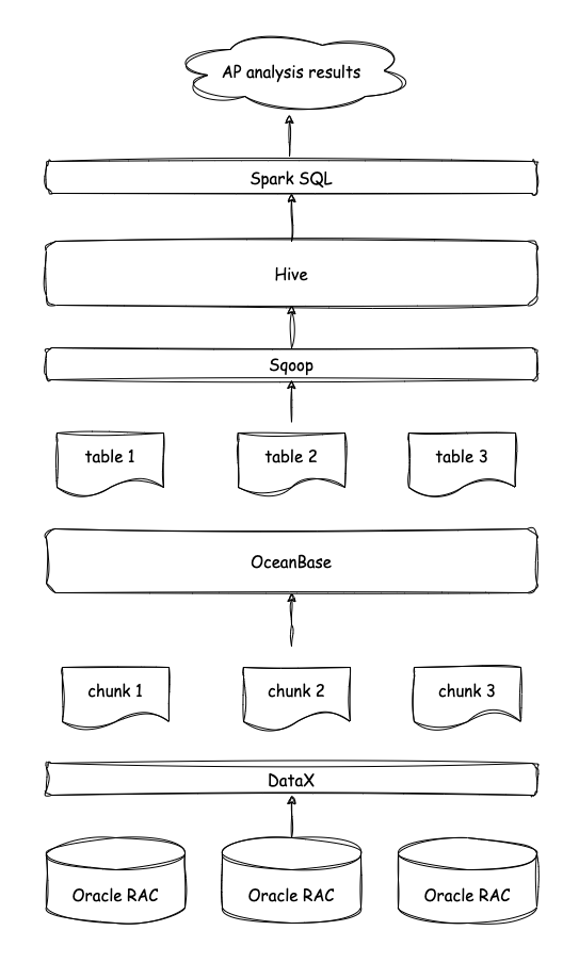
后来我们看到 OceanBase 官网提到了 HTAP 的能力,就尝试直接在 3 台 OceanBase 节点构成的集群中对数据进行 AP 分析,却意外发现即使在 OceanBase 中没有对数据进行分区,也没有使用并行执行,对 5 亿行的数据进行 AP 分析的时间都可以控制在一分钟以内。
原来是使用相同规格的 10 台机器部署的 Hadoop 环境,其 AP 分析性能居然已经被 3 台 OceanBase 超越。出乎我们意料的是,目前直接在 OceanBase 里写 SQL 就好,不需要再把数据装载到 hive 后再用 Spark SQL 进行分析,也不用依赖各种各样的开源组件,数据计算平台的链路就可以被简化成下图所示。
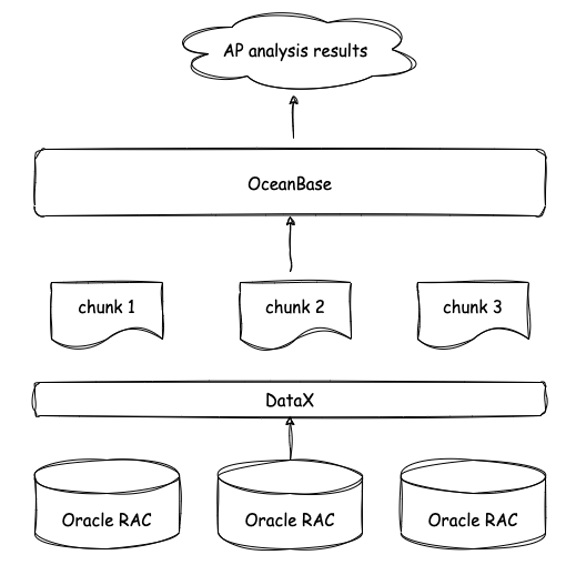
本来打算把数据导入 OceanBase 进行数据整合,然后再导入 Hadoop,然而,我们发现链路中 OceanBase 后面的整套 Hadoop 集群好像都没有用武之地了,再加上 OceanBase 是分布式数据库,可以水平扩展,所以这套 Hadoop 集群目前已经被弃用。
我们现在还没有花精力对 OceanBase 进行性能调优,后续将会在更多数据的环境中使用 OceanBase 对 100 亿数据进行 AP 分析,到时再研究下 OceanBase 的分区和并行执行这些功能。
最终,我们的数据计算平台架构调整为利用 4 台机器(1 台 OCP,3 台 OB)部署的一个 OceanBase 集群,基于 OceanBase 集群构建的计算平台的服务器配置如下。
| OCP | CentOS7 (64 位) | 64G | 20 vCPUs | 2T |
| observer 1 | CentOS7(64位) | 64G | 20 vCPUs | 2T |
| observer 2 | CentOS7(64位) | 64G | 20 vCPUs | 2T |
| observer 3 | CentOS7(64位) | 64G | 20 vCPUs | 2T |
在通过 ETL 工具把数据导入OceanBase 之后,数据解密、数据清洗、聚合和 AP 分析等功能都在 OceanBase 内完成,而且 AP 分析方面还能获取一些性能提升。OceanBase 集群中除了单独部署的集群管理工具 OCP 外,就只有 OBServer 一种节点,节点和节点之间完全对等,极大地降低了运维管理难度。
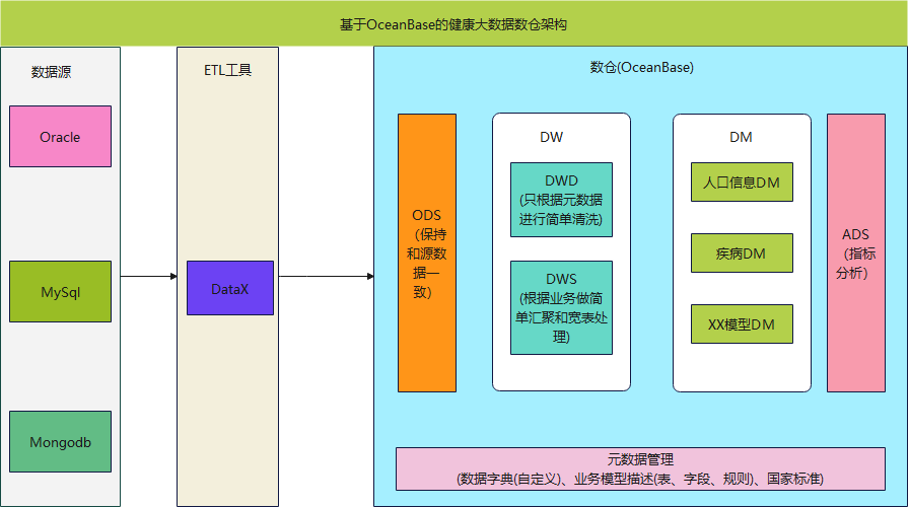
📚 术语解释:
-
ODS(Operational Data Store):操作性数据存储,存放原始数据,直接加载原始数据,数据保持原样不做处理。
-
DW(Data Warehouse):数据仓库层,用于存储已经结构化、已清洗和已经聚合过的数据,主要是为企业提供决策支持和数据分析服务。
-
DWD(Data Warehouse Detail):数据仓库明细层,对ODS层数据进行清洗(去除空值、脏数据,不符合元数据标准的数据),用于存储详细、完整的数据,支持企业数据的跨部门和跨系统共享和查询。
-
DWS(Data Warehouse Summary):数据仓库汇总层,用于提供业务汇总分析服务,对原始数据进行聚合计算和加工,供企业决策层使用。
-
ADS(Application Data Service):应用数据服务,用于存放数据产品个性化的统计指标数据,报表数据。
-
DM(Data Mart):数据集市,为了特定的应用目的,而从数据仓库中独立出来的主题数据,数据结构清晰,针对性强、拓展性好。
图:整体技术架构图
(二)存储成本
我们分别使用 5 台相同规格的集群部署了 Oracle 和 OceanBase 集群,使用一个有 5 亿行数据记录、大小为 372 GB 的数据文件,进行了数据导入导出的测试。数据导入方面,我们对比 Oracle 和 OceanBase 导入相同数据之后的存储空间开销:
-
将数据文件导入到 Oracle 中,占用220 GB 的存储空间。
-
相同的数据文件,通过 OBLOADER 导入 OceanBase 中,利用三备份存储只占用了 78GB 存储空间。
可见,相同的数据,OceanBase 在三备份的情况下占用的存储空间只有 Oracle 的 1/3 到 1/4 左右。
(三)生态工具
OceanBase 拥有非常丰富的生态,除了 400+ 家上下游生态产品外,自研的工具如 OCP、obdumper/obloader 都使其变得更加易用。
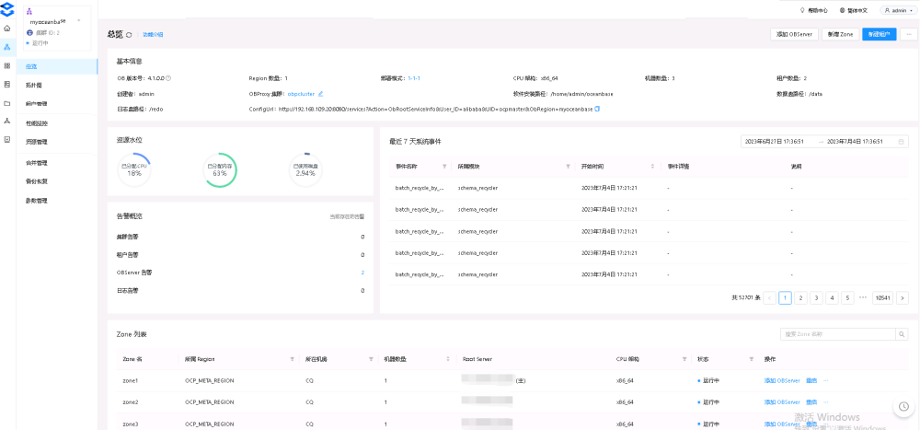
1. OCP
运维管理工具 OCP 是我们经常使用的工具,帮助我们直观地进行性能监控。
2. obdumper/obloader
这是 OceanBase 的导数工具,用于数据的逻辑备份和恢复。例如 5 亿行的数据,通过 obdumper 进行备份,最终备份文件的大小约 400 GB 。生成备份文件的时间可以控制在几十分钟。且用法也非常简单,只需一条命令即可。
3. 与其他开源产品的集成和融合
据了解,OceanBase 社区版与 Flink、Canal、Otter、Datax 等 400+ 家生态上下游做了深度的集成和融合,这对我们来说非常方便。例如,我们通过 Datax 把数据抽取到 OceanBase,集群中总共有 168 个 ETL 任务在实时运行。
4. 使用过程中遇到的一些问题
-
使用 ODC 去管理存储过程的时候,给了 replace procedure 的选项,但是无法选择,只能先 drop 再 create。我们经常遇到一大段存储过程只需要改一小部分的情况,希望 ODC 后面能够支持一下 replace procedure 的能力,让存储过程的修改更简单。
-
最早开源的 OceanBase 3.x 版本不支持 DBlink,不允许在一个数据库中访问和操作另一个数据库中的表、视图和数据,目前 4.x 版本已经支持。
-
我们当初部署时比较繁琐,因为那时 OceanBase 社区版还没有提供一键安装包 (OceanBase All in One)。

从 2021 年起我们就关注 OceanBase,并使用了彼时刚开源的 OceanBase 3.x 版本。我们通过真实业务场景,验证了 20TB 数据量直接通过 OceanBase 进行所有数据分析的可行性,原来需要 10 台机器完成的任务现在只需 4 台机器即可完成,节省了 60% 的硬件成本,并将运维工作大幅减少,从 Hadoop 海量组件中释放出来。
OceanBase 通过一套引擎支持 OLAP + OLTP 工作负载,同时实现两套系统的功能,在满足我们 AP 性能要求的同时,也简化了运维复杂度,大幅降低成本。OceanBase 在性能和存储成本方面的优势,也在我们的业务环境得到验证。
未来我们还将加强与 OceanBase 的合作,并尝试使用 OceanBase 开源生态中丰富的周边工具打造出企业级的产品。