窗口Window机制
- 窗口概述
- 窗口的分类
- 是否按键分区
- 按键分区窗口
- 非按键分区
- 按照驱动类型
- 按具体分配规则
- 滚动窗口Tumbling Windows
- 滑动窗口 Sliding Windows
- 会话窗口 Session Windows
- 全局窗口 Global Windows
- 时间语义
- 窗口分配器 Window Assigners
- 时间窗口
- 计数窗口
- 例子
- 窗口函数 Window Functions
- 增量聚合函数
- ReduceFunction
- AggregateFunction
- 全窗/全量口函数
- WindowFunction
- ProcessWindowFunction
- 增量聚合和全窗口函数的结合
- 其他
- 触发器 Trigger
- 移除器 Evictor
窗口概述
在大多数场景下,需要统计的数据流都是无界的,因此无法等待整个数据流终止后才进行统计。通常情况下,只需要对某个时间范围或者数量范围内的数据进行统计分析
例如:
每隔10分钟统计一次过去30分钟内某个对象的点击量
每发生100次点击后,就去统计一下每个对象点击率的占比
因此,在Apache Flink中,窗口是对无界数据流进行有界处理的机制。窗口可以将无限的数据流划分为有限的、可处理的块,使得可以基于这些有限的数据块执行聚合、计算和分析操作。
窗口的分类
是否按键分区
在定义窗口操作之前,首先需要确定,到底是基于按键分区的数据流KeyedStream来开窗,还是直接在没有按键分区的DataStream上开窗。
两者区别:
1.keyed streams要调用keyBy(...)后再调用window(...) , 而non-keyed streams只用直接调用windowAll(...)
2.对于keyed stream,其中数据的任何属性都可以作为key。 允许窗口计算由多个task并行,因为每个逻辑上的 keyed stream都可以被单独处理。 属于同一个key的元素会被发送到同一个 task。
3.对于non-keyed stream,原始的stream不会被分割为多个逻辑上的stream, 所有的窗口计算会被同一个 task完成,也就是parallelism为1
按键分区窗口
经过按键分区keyBy操作后,数据流会按照key被分为多条逻辑流,这就是KeyedStream。
基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。
相同key的数据会被发送到同一个并行子任务,而窗口操作会基于每个key进行单独的处理。
所以可以认为,每个key上都定义了一组窗口,各自独立地进行统计计算。
按键分区窗口写法:
stream
.keyBy(...) <- 仅 keyed 窗口需要
.window(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (省略则使用默认 trigger)
[.evictor(...)] <- 可选项:"evictor" (省略则不使用 evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (省略则为 0)
[.sideOutputLateData(...)] <- 可选项:"output tag" (省略则不对迟到数据使用 side output)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
代码示例:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从socket接收数据流
SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);
// 将输入数据转换为(key, value)元组
DataStream<Tuple2<String, Integer>> dataStream = source.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2 map(String s) throws Exception {
int number = Integer.parseInt(s);
String key = number % 2 == 0 ? "key1" : "key2";
Tuple2 tuple2 = new Tuple2(key, number);
return tuple2;
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
// keyBy操作
KeyedStream<Tuple2<String, Integer>, String> keyBy = dataStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> tuple2) throws Exception {
return tuple2.f0;
}
});
// 每10秒统计一次数量和
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = keyBy.window(TumblingProcessingTimeWindows.of(Time.seconds(10))).sum(1);
streamOperator.print();
env.execute();
}
发送测试数据
[root@administrator ~]# nc -lk 8086
1
2
3
4
等待10秒后,控制台打印如下
(key2,4)
(key1,6)
非按键分区
如果没有进行keyBy,那么原始的DataStream就不会分成多条逻辑流。这时窗口逻辑只能在一个任务task上执行,就相当于并行度变成了1。
非按键分区窗口写法:
stream
.windowAll(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (else default trigger)
[.evictor(...)] <- 可选项:"evictor" (else no evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (else zero)
[.sideOutputLateData(...)] <- 可选项:"output tag" (else no side output for late data)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
代码示例:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从socket接收数据流
SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);
// 将输入数据转换为Integer
DataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));
// 每10秒统计一次数量和
SingleOutputStreamOperator<Integer> streamOperator = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10))).sum(0);
streamOperator.print();
env.execute();
}
按照驱动类型
窗口按照驱动类型可以分成时间窗口和计数窗口,这两种窗口类型根据其触发机制和边界规则的不同,适用于不同的应用场景。
时间窗口 Time Windows:
时间窗口根据事件时间Event Time或处理时间Processing Time来划分
时间窗口根据时间的进展划分数据流,当一个窗口的时间到达或窗口中的元素数量达到阈值时,触发窗口计算
计数窗口 Count Windows:
计数窗口根据元素的数量或元素的增量来划分
计数窗口在数据流中累积固定数量的元素后,触发窗口计算
窗口的大小可以是固定的,也可以是动态变化的,取决于所设置的阈值和策略
按具体分配规则
窗口按照具体的分配规则,又有滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。
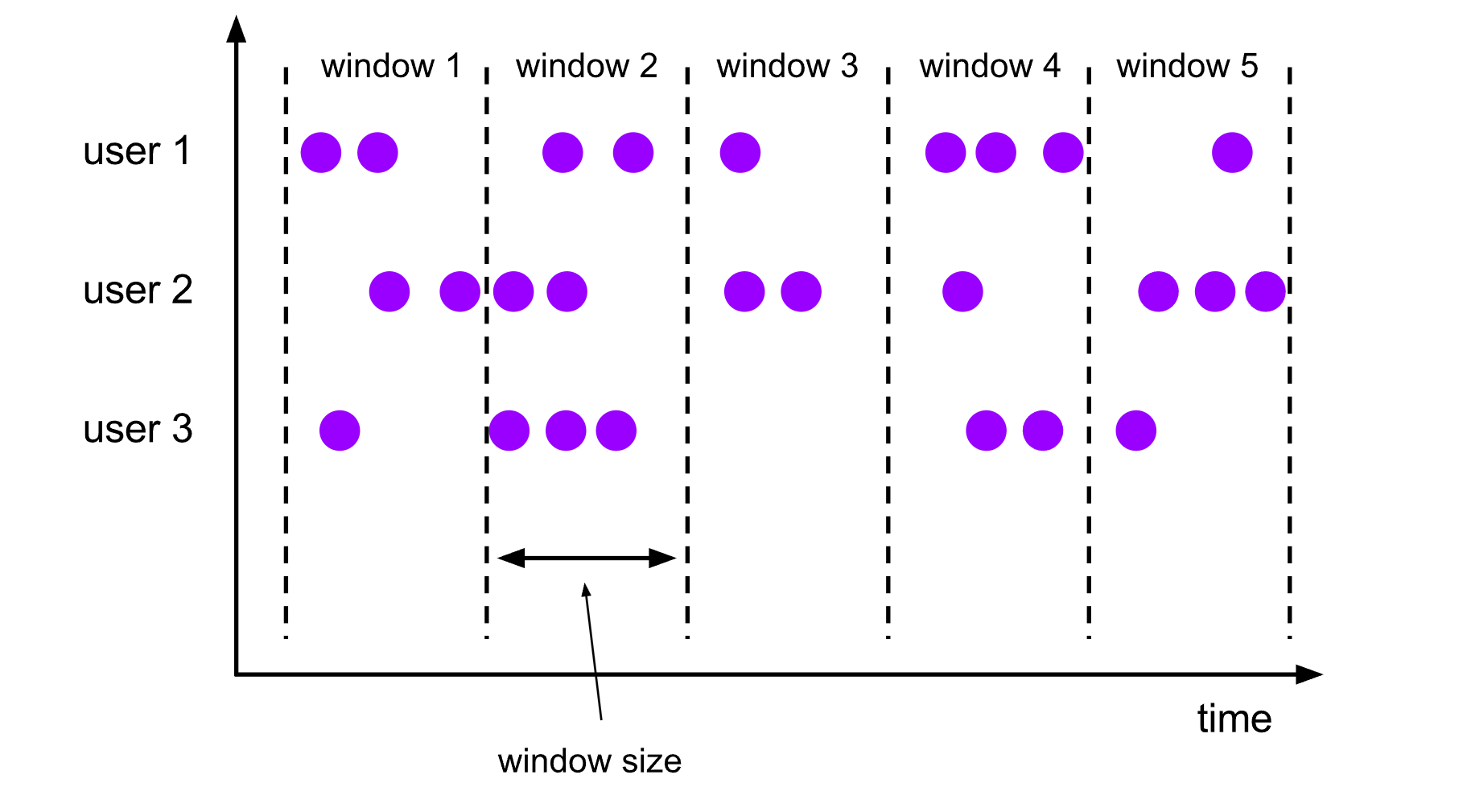
滚动窗口Tumbling Windows
滚动窗口将数据流划分为固定大小的、不重叠的窗口。
例如:将数据流按照5秒的滚动窗口大小进行划分,每个窗口包含5秒的数据。那么每5秒就会有一个窗口被计算,且一个新的窗口被创建
代码示例:
DataStream<T> input = ...;
// 滚动 event-time 窗口
input
.keyBy(<key selector>)
// 间间隔可以用 Time.milliseconds(x)、Time.seconds(x)、Time.minutes(x) 等来指定
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// 滚动 processing-time 窗口
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// 长度为一天的滚动 event-time 窗口, 偏移量为 -8 小时。
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
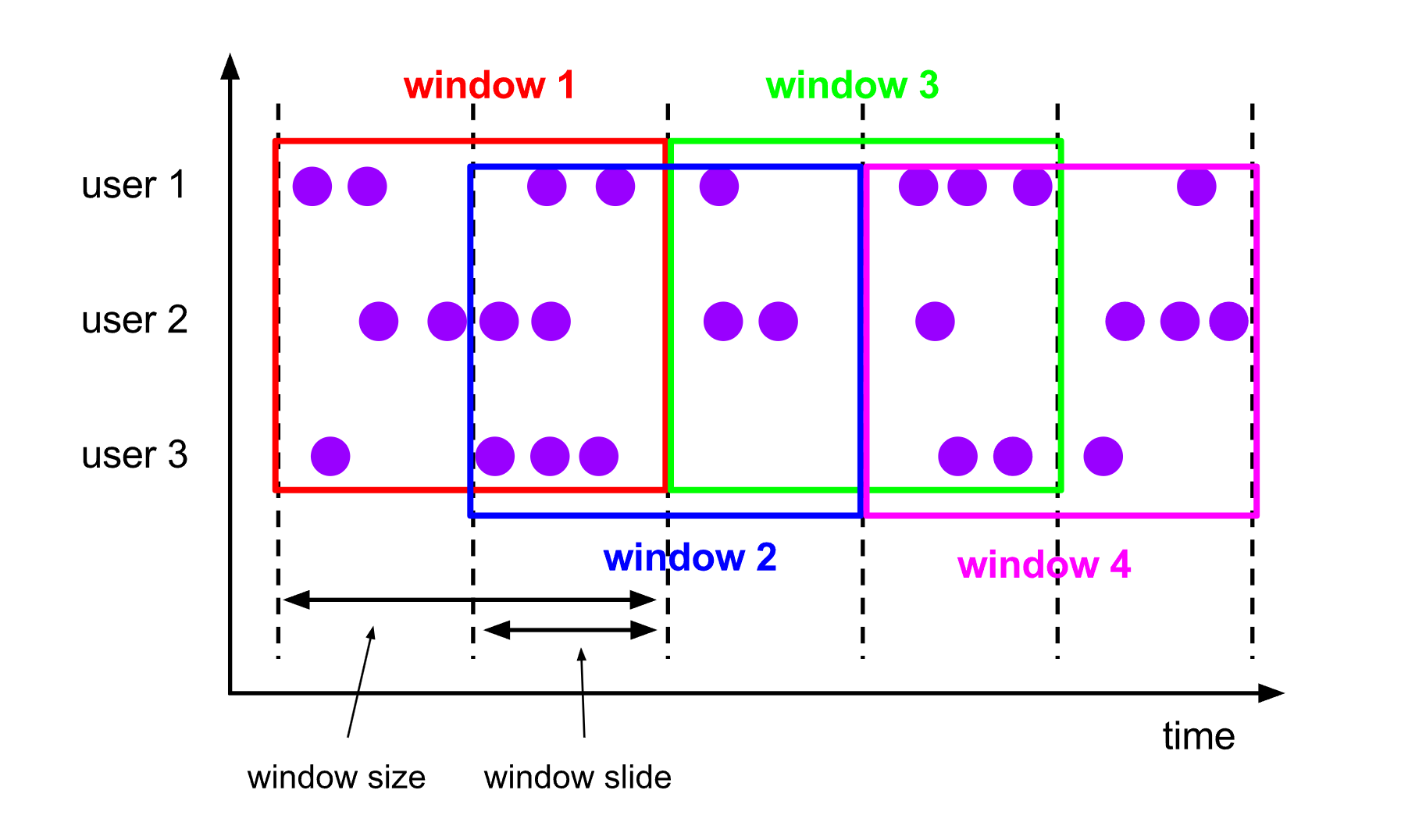
滑动窗口 Sliding Windows
滑动窗口将数据流划分为固定大小的窗口,窗口大小通过window size参数设置,需要一个额外的滑动距离window slide参数来控制生成新窗口的频率。
如果slide小于窗口大小,滑动窗口可以允许窗口重叠。这种情况下,一个元素可能会被分发到多个窗口。
例如:将数据流按照5秒的滑动窗口大小和3秒的滑动步长进行划分,窗口之间有2秒的重叠。
DataStream<T> input = ...;
// 滑动 event-time 窗口
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// 滑动 processing-time 窗口
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// 滑动 processing-time 窗口,偏移量为 -8 小时
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
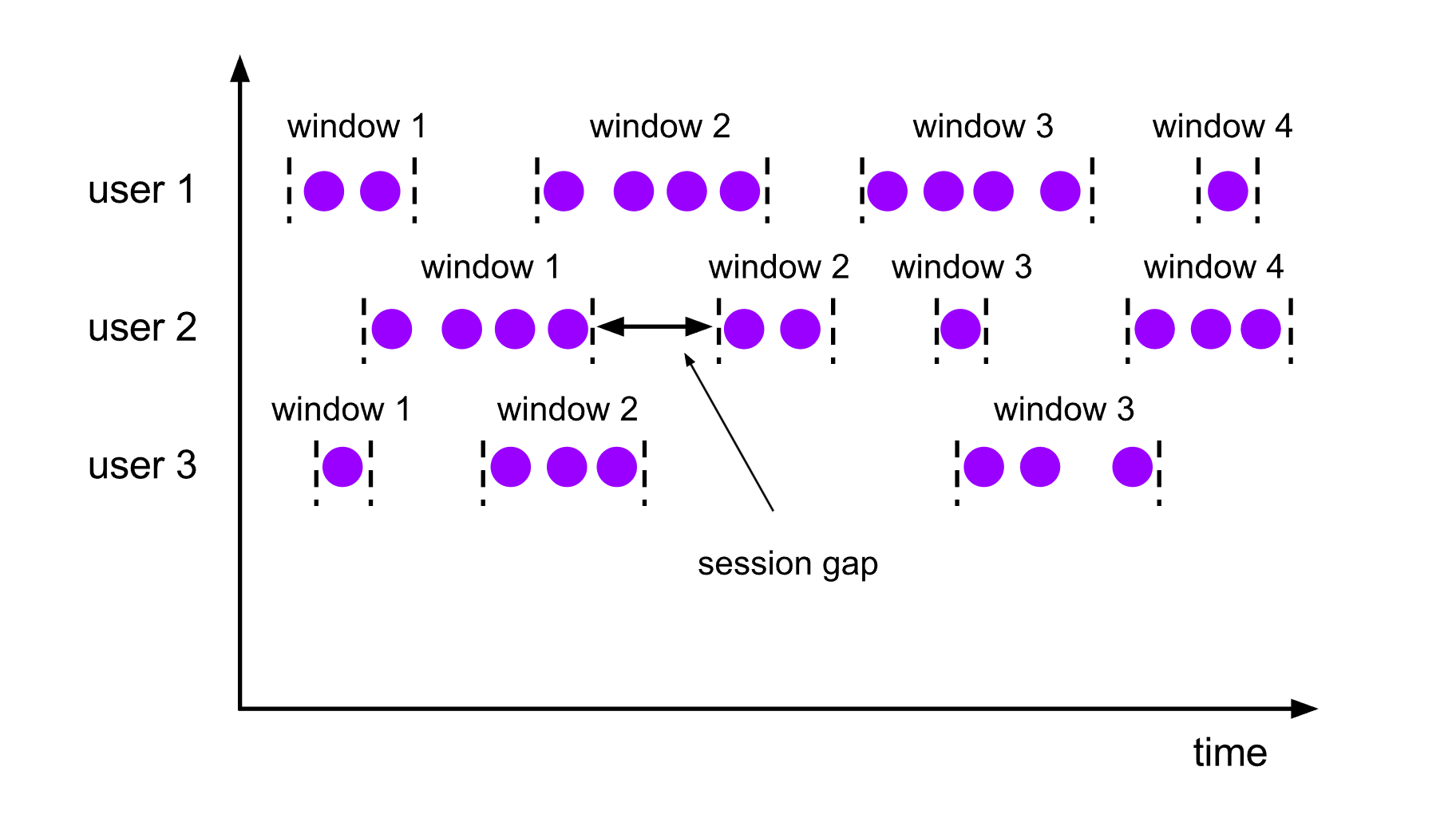
会话窗口 Session Windows
与滚动窗口和滑动窗口不同,会话窗口不会相互重叠,且没有固定的开始或结束时间。 会话窗口在一段时间没有收到数据之后会关闭,即在一段不活跃的间隔之后。
如果会话窗口有一段时间没有收到数据, 会话窗口会自动关闭, 这段没有收到数据的时间就是会话窗口的gap(间隔)
可以配置静态的gap, 也可以通过一个gap extractor函数来定义gap的长度
当时间超过了这个gap, 当前的会话窗口就会关闭, 后序的元素会被分配到一个新的会话窗口
DataStream<T> input = ...;
// 设置了固定间隔的 event-time 会话窗口
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// 设置了动态间隔的 event-time 会话窗口
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
.<windowed transformation>(<window function>);
// 设置了固定间隔的 processing-time session 窗口
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// 设置了动态间隔的 processing-time 会话窗口
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
.<windowed transformation>(<window function>);
全局窗口 Global Windows
全局窗口将整个数据流作为一个窗口进行处理,不进行分割。全局窗口适用于需要在整个数据流上执行聚合操作的场景。

DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>);
时间语义
在Flink的流式操作中, 会涉及不同的时间概念,即时间语义,它是指在数据处理中确定事件的时间基准的机制。
在实时数据流处理中,常见的时间语义有以下三种:
1.处理时间(Processing Time):
处理时间是指数据处理引擎的本地时钟时间,也称为机器时间或系统时间
使用处理时间时,事件的时间顺序是根据数据到达处理引擎的顺序来确定的
处理时间是一种简单和实时性较高的时间语义,但不考虑数据可能存在的延迟或乱序
2.事件时间(Event Time):
事件时间是数据流中记录的实际时间,通常是数据本身携带的时间戳
使用事件时间时,数据记录的时间戳决定事件在时间轴上的顺序,而不受数据到达引擎的顺序影响
事件时间是一种准确和可重现的时间语义,能够处理延迟和乱序数据,但可能需要关注水印的处理
3.摄取时间(Ingestion Time):
注意:较新版本的Flink已经弃用,推荐使用事件时间
摄取时间是数据进入数据处理引擎的时间
使用摄取时间时,数据到达引擎的顺序决定事件的时间顺序
摄取时间是介于处理时间和事件时间之间的折中方案。它可以处理一定程度的延迟和乱序数据,但不会像事件时间那样需要处理水印。
区别:
处理时间适用于实时性要求较高、不关心事件的顺序和时间戳的场景
事件时间适用于需要准确处理事件顺序和考虑延迟、乱序数据的场景
摄取时间提供了某种程度上的准确性和实时性折中
窗口分配器 Window Assigners
在Apache Flink中,窗口分配器(Window Assigner)用于定义如何将数据流中的元素分配到窗口。窗口分配器确定了窗口的边界以及如何对元素进行分组和分配
窗口分配器最通用的定义方式:
如果是按键分区窗口, 直接调用.keyBy().window()方法,传入一个WindowAssigner作为参数,返回WindowedStream。
如果是非按键分区窗口,直接调用.windowAll()方法,传入一个WindowAssigner,返回的是AllWindowedStream。
时间窗口
时间窗口是最常用的窗口类型,可以大致细分为滚动、滑动和会话三种。
1.滚动处理时间窗口
窗口分配器由类TumblingProcessingTimeWindows提供,需要调用它的静态方法.of(),需要传入一个Time类型的参数size,表示滚动窗口的大小
// 非按键分区 滚动事件时间窗口,窗口长度10s。每10秒操作一次
dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 按键分区
dataStream.keyBy().window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
2.滚动事件时间窗口
窗口分配器由类TumblingEventTimeWindows提供,用法与滚动处理事件窗口完全一致。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
3.滑动处理时间窗口
窗口分配器由类SlidingProcessingTimeWindows提供,同样需要调用它的静态方法.of(),需要传入两个Time类型的参数:size和slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长
// 窗口长度10s,滑动步长2s。 每2秒滑动一次,窗口大小为10秒的滑动时间窗口,并对窗口中的元素进行操作。
dataStream.windowAll(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(2)));
4.滑动事件时间窗口
窗口分配器由类SlidingEventTimeWindows提供,用法与滑动处理事件窗口完全一致
dataStream.windowAll(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)));
5.处理时间会话窗口
窗口分配器由类ProcessingTimeSessionWindows提供,需要调用它的静态方法withGap()或者withDynamicGap()。需要传入一个Time类型的参数size,表示会话的超时时间
// 会话窗口,超时间隔5s
dataStream.windowAll(ProcessingTimeSessionWindows.withGap(Time.seconds(5)));
6.事件时间会话窗口
窗口分配器由类EventTimeSessionWindows提供,用法与处理事件会话窗口完全一致。
dataStream.windowAll(EventTimeSessionWindows.withGap(Time.seconds(10)));
计数窗口
1.滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数size,表示窗口的大小。
当窗口中元素数量达到size时,就会触发计算执行并关闭窗口。
// 滚动窗口,窗口长度2个元素
dataStream.countWindowAll(2);
2.滑动计数窗口
在countWindow()调用时传入两个参数:size和slide,前者表示窗口大小,后者表示滑动步长。
每个窗口统计size个数据,每隔slide个数据就统计输出一次结果。
// 滑动窗口,窗口长度2个元素,滑动步长2个元素
dataStream.countWindowAll(5,2);
3.全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由GlobalWindows类提供。
// 全局窗口,需要自定义的时候才会用
dataStream.windowAll(GlobalWindows.create());
dataStream.keyBy().window(GlobalWindows.create());
注意:使用全局窗口必须自行定义触发器才能实现窗口计算,否则不起作用。
例子
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从socket接收数据流
SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);
// 将输入数据转换为Integer
DataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));
// 时间窗口示例:滚动处理时间窗口,窗口长度10s。 每10秒统计一次数量和
SingleOutputStreamOperator<Integer> streamOperator = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10))).sum(0);
streamOperator.print();
env.execute();
}
发送测试数据
[root@administrator ~]# nc -lk 8086
1
2
3
4
等待10秒后,控制台打印如下
10
窗口函数 Window Functions
定义了window assigner之后,需要指定当窗口触发之后,如何计算每个窗口中的数据, 这就是window function的职责
窗口函数是在窗口操作中应用于窗口中元素的函数。Flink提供了丰富的窗口函数,用于对窗口中的元素进行各种操作和计算。
根据处理的方式可以分为两类:增量聚合函数和全窗/全量口函数,它们是Flink中用于窗口计算的两种不同的函数。
增量聚合函数
增量聚合函数是指对窗口中的数据进行累积计算的函数。它会在每个元素到达窗口时进行计算,并且仅保留窗口计算所需的中间状态。这种方式可以显著提高计算性能,尤其适用于大规模数据和长窗口的情况。
对于增量聚合函数,Flink 提供了一系列内置的聚合函数,例如 sum、min、max、avg等,它们的底层,其实都是通过AggregateFunction来实现的。还可以通过实现 AggregateFunction接口来定义自定义的增量聚合函数。
典型的增量聚合函数有两个:ReduceFunction和AggregateFunction。
ReduceFunction
ReduceFunction指定两条输入数据如何合并起来产生一条输出数据,输入和输出数据的类型必须相同。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从socket接收数据流
SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);
// 将输入数据转换为Integer
DataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));
// 指定窗口分配器
AllWindowedStream<Integer, TimeWindow> allWindowedStream = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 指定窗口函数,使用 增量聚合Reduce
SingleOutputStreamOperator<Integer> reduce = allWindowedStream.reduce(
new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2) throws Exception {
System.out.println("前一个值: " + value1 + " ,后一个值:" + value2);
return value1 + value2;
}
}
);
// 在窗口触发的时候,才会输出窗口的最终计算结果
reduce.print();
env.execute();
}
发送测试数据:
[root@administrator ~]# nc -lk 8086
1
2
3
4
5
控制台输出:
前一个值: 1 ,后一个值:2
前一个值: 3 ,后一个值:3
前一个值: 6 ,后一个值:4
前一个值: 10 ,后一个值:5
15
AggregateFunction
ReduceFunction接口存在一个限制:聚合状态的类型、输出结果的类型都必须和输入数据类型一样。聚合函数则突破了这个限制,可以定义更加灵活的窗口聚合操作。
AggregateFunction函数接口方法参数有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。
输入类型IN就是输入流中元素的数据类型
累加器类型ACC则是我们进行聚合的中间状态类型
而输出类型当然就是最终计算结果的类型
接口中有四个方法:
createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次
add():将输入的元素添加到累加器中
getResult():从累加器中提取聚合的输出结果
merge():合并两个累加器,并将合并后的状态作为一个累加器返回
与ReduceFunction相同,AggregateFunction也是增量式的聚合,而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从socket接收数据流
SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);
// 将输入数据转换为Integer
DataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));
// 指定窗口分配器
AllWindowedStream<Integer, TimeWindow> allWindowedStream = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 窗口函数 增量聚合 Aggregate
SingleOutputStreamOperator<String> aggregate = allWindowedStream.aggregate(new MyAggregateFunction());
aggregate.print();
env.execute();
}
/**
* 第一个类型: 输入数据的类型
* 第二个类型: 累加器的类型,存储的中间计算结果的类型
* 第三个类型: 输出的类型
*/
public static class MyAggregateFunction implements AggregateFunction<Integer, Integer, String> {
/**
* 创建累加器,初始化累加器
*
* @return
*/
@Override
public Integer createAccumulator() {
System.out.println("createAccumulator方法执行");
return 0;
}
/**
* 聚合逻辑
* 来一条计算一条,调用一次add方法
*
* @param value 当前值
* @param accumulator 累加器的值
* @return
*/
@Override
public Integer add(Integer value, Integer accumulator) {
System.out.println("add方法执行,当前值 :" + value + "累加器值 :" + accumulator);
return value + accumulator;
}
/**
* 获取最终结果,窗口触发时输出
*
* @param accumulator
* @return
*/
@Override
public String getResult(Integer accumulator) {
System.out.println("getResult方法执行");
return "最终计算值:" + accumulator;
}
@Override
public Integer merge(Integer a, Integer b) {
// 只有会话窗口才会用到
System.out.println("merge方法执行");
return null;
}
}
发送测试数据:
[root@administrator ~]# nc -lk 8086
1
2
3
4
5
控制台输出:
createAccumulator方法执行
add方法执行,当前值 :1累加器值 :0
add方法执行,当前值 :2累加器值 :1
add方法执行,当前值 :3累加器值 :3
add方法执行,当前值 :4累加器值 :6
add方法执行,当前值 :5累加器值 :10
getResult方法执行
最终计算值:15
全窗/全量口函数
全窗口函数是对窗口中的所有元素进行计算的函数。它会在窗口触发时对窗口中的所有元素进行处理,并输出一个或多个结果。全窗口函数可以访问窗口的所有元素,并且可以使用窗口中的状态信息。
对于全窗口函数,Flink提供了 ProcessWindowFunction 和 WindowFunction 两个接口供用户使用。
ProcessWindowFunction: 可以处理每个元素,并输出零个、一个或多个结果
WindowFunction: 是一个转换函数,对窗口的所有元素进行转换,并输出一个或多个结果。
与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
WindowFunction
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从socket接收数据流
SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);
// 将输入数据转换为(key, value)元组
DataStream<Tuple2<String, Integer>> dataStream = source.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2 map(String s) throws Exception {
int number = Integer.parseInt(s);
String key = number % 2 == 0 ? "key1" : "key2";
Tuple2 tuple2 = new Tuple2(key, number);
return tuple2;
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
// keyBy操作
KeyedStream<Tuple2<String, Integer>, String> keyedStream = dataStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> tuple2) throws Exception {
return tuple2.f0;
}
});
// 指定窗口分配器 非键分区窗口
// AllWindowedStream<Integer, TimeWindow> allWindowedStream = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 键分区窗口
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 使用WindowFunction窗口函数
SingleOutputStreamOperator<String> apply = windowedStream.apply(new MyWindowFunction());
apply.print();
env.execute();
}
/**
* 窗口函数
* <p>
* 窗口触发时才会调用一次,统一计算窗口的所有数据
*/
public static class MyWindowFunction implements WindowFunction<Tuple2<String, Integer>, String, String, TimeWindow> {
/**
* @param s 分组的key,非键分区窗口则无该参数
* @param window 窗口对象
* @param input 存的数据
* @param out 采集器
*/
@Override
public void apply(String s, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<String> out) throws Exception {
// 上下文拿到window对象,获取相关信息
long start = window.getStart();
long end = window.getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss");
long count = input.spliterator().estimateSize();
out.collect("分组 " + s + " 的窗口,在时间区间: " + windowStart + "-" + windowEnd + " 产生" + count + "条数据,具体数据:" + input.toString());
}
}
]# nc -lk 8086
1
2
3
4
5
分组 key2 的窗口,在时间区间: 2023-06-27 16:50:10-2023-06-27 16:50:20 产生3条数据,具体数据:[(key2,1), (key2,3), (key2,5)]
分组 key1 的窗口,在时间区间: 2023-06-27 16:50:10-2023-06-27 16:50:20 产生2条数据,具体数据:[(key1,2), (key1,4)]
ProcessWindowFunction
// 使用ProcessWindowFunction处理窗口函数
SingleOutputStreamOperator<String> process = windowedStream.process(new MyProcessWindowFunction());
/**
* 处理窗口函数
* <p>
* 窗口触发时才会调用一次,统一计算窗口的所有数据
*/
public static class MyProcessWindowFunction extends ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow> {
/**
* @param s 分组的key,非键分区窗口则无该参数
* @param context 上下文
* @param input 存的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable<Tuple2<String, Integer>> input, Collector<String> out) throws Exception {
// 上下文拿到window对象,获取相关信息
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss");
long count = input.spliterator().estimateSize();
out.collect("分组 " + s + " 的窗口,在时间区间: " + windowStart + "-" + windowEnd + " 产生" + count + "条数据,具体数据:" + input.toString());
}
}
增量聚合和全窗口函数的结合
在调用窗口的增量聚合函数方法时,第一个参数直接传入一个ReduceFunction或AggregateFunction进行增量聚合,第二个参数传入一个全窗口函数WindowFunction或者ProcessWindowFunction。
基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合
等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果
注意这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了Iterable类型的输入
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从socket接收数据流
SingleOutputStreamOperator<String> source = env.socketTextStream("node01", 8086);
// 将输入数据转换为Integer
DataStream<Integer> dataStream = source.map(str -> Integer.parseInt(str));
// 指定窗口分配器 非键分区窗口
AllWindowedStream<Integer, TimeWindow> allWindowedStream = dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 使用ProcessWindowFunction处理窗口函数
SingleOutputStreamOperator<String> process = allWindowedStream.aggregate(new MyAggregateFunction(), new MyProcessWindowFunction());
process.print();
env.execute();
}
/**
* 第一个类型: 输入数据的类型
* 第二个类型: 累加器的类型,存储的中间计算结果的类型
* 第三个类型: 输出的类型
*/
public static class MyAggregateFunction implements AggregateFunction<Integer, Integer, String> {
/**
* 创建累加器,初始化累加器
*
* @return
*/
@Override
public Integer createAccumulator() {
System.out.println("createAccumulator方法执行");
return 0;
}
/**
* 聚合逻辑
* 来一条计算一条,调用一次add方法
*
* @param value 当前值
* @param accumulator 累加器的值
* @return
*/
@Override
public Integer add(Integer value, Integer accumulator) {
System.out.println("add方法执行,当前值 :" + value + " 累加器值 :" + accumulator);
return value + accumulator;
}
/**
* 获取最终结果,窗口触发时输出
*
* @param accumulator
* @return
*/
@Override
public String getResult(Integer accumulator) {
System.out.println("getResult方法执行");
return "最终计算值:" + accumulator;
}
@Override
public Integer merge(Integer a, Integer b) {
// 只有会话窗口才会用到
System.out.println("merge方法执行");
return null;
}
}
/**
* 处理窗口函数
* <p>
* 窗口触发时才会调用一次,统一计算窗口的所有数据
* <p>
* 注意:增量聚合函数的输出类型 是 全窗口函数的输入类型
*/
public static class MyProcessWindowFunction extends ProcessAllWindowFunction<String, String, TimeWindow> {
/**
* @param context 上下文
* @param input 存的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(Context context, Iterable<String> input, Collector<String> out) throws Exception {
// 上下文拿到window对象,获取相关信息
long start = context.window().getStart();
long end = context.window().getEnd();
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss");
long count = input.spliterator().estimateSize();
out.collect("窗口在时间区间: " + windowStart + "-" + windowEnd + " 产生" + count + "条数据,具体数据:" + input.toString());
}
}
createAccumulator方法执行
add方法执行,当前值 :1 累加器值 :0
add方法执行,当前值 :2 累加器值 :1
add方法执行,当前值 :3 累加器值 :3
add方法执行,当前值 :4 累加器值 :6
add方法执行,当前值 :5 累加器值 :10
getResult方法执行
窗口在时间区间: 2023-06-27 17:07:50-2023-06-27 17:08:00 产生1条数据,具体数据:[最终计算值:15]
其他
触发器 Trigger
Trigger决定了一个窗口(由windowassigner定义)何时可以被windowfunction处理。每个WindowAssigner都有一个默认的Trigger。如果默认trigger无法满足需要,可以在trigger(…)调用中指定自定义的trigger。
Trigger接口提供了五个方法来响应不同的事件:
onElement()方法在每个元素被加入窗口时调用
onEventTime()方法在注册的event-timetimer触发时调用
onProcessingTime()方法在注册的processing-timetimer触发时调用
onMerge()方法与有状态的trigger相关。该方法会在两个窗口合并时,将窗口对应trigger的状态进行合并,比如使用会话窗口时
clear()方法处理在对应窗口被移除时所需的逻辑
注意:
前三个方法通过返回TriggerResult来决定trigger如何应对到达窗口的事件。
应对方案:
CONTINUE: 什么也不做
FIRE: 触发计算
PURGE: 清空窗口内的元素
FIRE_AND_PURGE: 触发计算,计算结束后清空窗口内的元素
内置触发器
EventTimeTrigger:基于事件时间和watermark机制来对窗口进行触发计算
ProcessingTimeTrigger: 基于处理时间触发
CountTrigger:窗口元素数超过预先给定的限制值的话会触发计算
PurgingTrigger:作为其它trigger的参数,将其转化为一个purging触发器
基于WindowedStream调用.trigger()方法,就可以传入一个自定义的窗口触发器
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())
移除器 Evictor
Evictor可以在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素。Evictor是一个接口,不同的窗口类型都有各自预实现的移除器。
内置evictor:
默认情况下,所有内置的 evictor 逻辑都在调用窗口函数前执行。
CountEvictor: 仅记录用户指定数量的元素,一旦窗口中的元素超过这个数量,多余的元素会从窗口缓存的开头移除
DeltaEvictor: 接收 DeltaFunction 和 threshold 参数,计算最后一个元素与窗口缓存中所有元素的差值, 并移除差值大于或等于 threshold 的元素。
TimeEvictor: 接收 interval 参数,以毫秒表示。 它会找到窗口中元素的最大 timestamp max_ts 并移除比 max_ts - interval 小的所有元素
基于WindowedStream调用.evictor()方法,就可以传入一个自定义的移除器
stream.keyBy(...)
.window(...)
.evictor(new MyEvictor())