目录
实验一 熟悉实验环境VSCode并完成正则表达式转换为NFA
一、实验目的
二、预备知识
三、实验内容
VSCode的基本使用方法
安装和启动VSCode
VSCode的窗口布局
使用VSCode将项目克隆到本地磁盘
使用VSCode登录平台
查看项目中的文件
实验源代码
演示程序的执行过程
四、实验过程
完成“input2.txt”NFA片段的构造
完成“input3.txt”NFA片段的构造
完成“input4.txt”NFA片段的构造
完成“input5.txt”NFA片段的构造
自动化验证
思考与练习
五、实验总结
实验一 熟悉实验环境VSCode并完成正则表达式转换为NFA
一、实验目的
- 熟悉实验环境的基本使用方法。
- 掌握正则表达式和NFA(非确定有穷自动机)的含义。
- 实现正则表达式到NFA的转换。
二、预备知识
- 在这个实验中NFA状态结构体使用了类似于二叉树的数据结构,还包括了单链表插入操作以及栈的一些基本操作。如果读者对这一部分知识有遗忘,可以复习一下数据结构中的相关内容。
- 实验中需要把正则表达式转换为NFA(非确定有穷自动机),所以要对正则表达式和NFA有初步的理解。读者可以参考配套的《编译原理》教材,学习这一部分内容。
三、实验内容
VSCode的基本使用方法
安装和启动VSCode
我是访问“杰创科技”平台中提供的下载链接安装的VSCode和Git Bash;Python环境之前安装过,版本为“Python 3.8.6rc1”。安装和启动方式非常简单,不做赘述。
VSCode的窗口布局
VSCode的窗口布局由下面的若干元素组成:
- 编辑器:这是主要的代码编辑区域,可以多列或者多行的打开多个编辑器。
- 侧边栏:位于左侧的侧边栏包含了文件资源管理器、文件搜索、源代码版本管理、调试与运行、插件等基本视图。
- 活动栏:位于侧边栏的左侧,可以方便的让用户在不同的视图之间进行切换。
- 状态栏:位于底部的状态栏用于显示当前打开文件的光标位置、编码格式等信息。
- 面板:编辑器的下方可以展示不同的面板,包括显示输出信息的面板、显示调试信息的面板、显示错误信息的面板和集成终端。面板也可以被移动到编辑器的右侧。
使用VSCode将项目克隆到本地磁盘
先从“杰创科技”平台,找到对应课程《编译原理》:

在窗口左侧选择“任务”,可以看到任务列表;点击进入“实验1 实验环境的使用”:
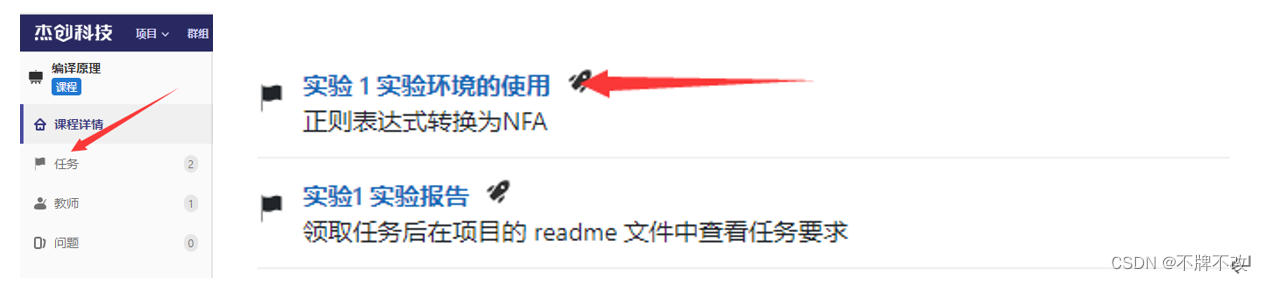
从平台领取了任务之后,可以按照下面的步骤将个人项目克隆到本地磁盘中。
1. 在VSCode的“View”菜单中选择“Command Palette...”,会在VSCode的顶部中间位置显示一个用来输入命令的面板:
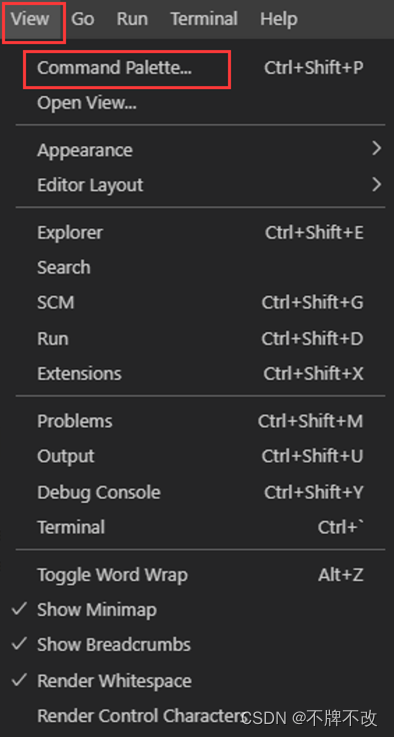
2. 在VSCodc的命令面板中输入“Git”后,法列表中提示出所有与Git相关的命令。选择列表中的“Git:Clone”命令后按回车,会提示输入Git远程库的URL,将之前复制的个人项目的URL粘贴到命令面板中并按回车:
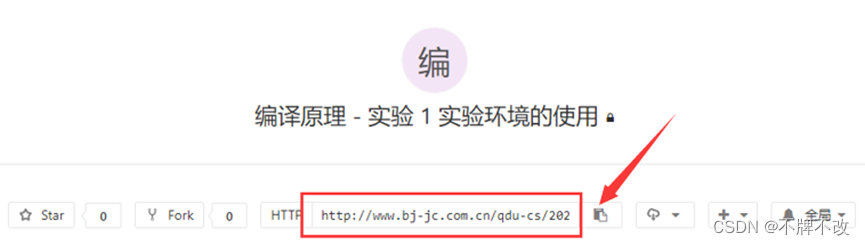
输入“Git:Clone”:

再输入刚刚复制的URL:

3.Git远程库的URL输入成功后,会自动打开“选择文件夹”窗口,提示用户选择一个本地文件夹用来保存项目。此时,读者就可以在本地磁盘中选择一个合适的文件夹(注意,本地文件夹路径中不要包含中文字符和空格),然后点击“Select Repository Location”按钮:
4. 选择本地文件夹后,VSCode会在命令面板中提示输入“Username”,输入平台的用户名后按回车。接下来会提示输入“Password”,输入平台的密码后按回车。用户名和密码校验成功后就开始将Git远程库克隆到本地了。
选择完成后,窗口右下角会显示:
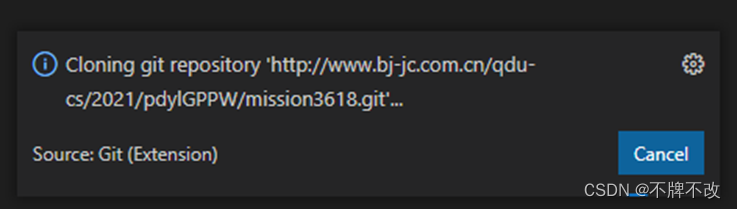
虽然显示是一直在加载,其实是在等待用户输入用户名和密码,即“杰创科技”平台激活的账号和密码。在输入“Git:Clone”的输入框中根据用户提示依次输入username和password。
5. 克隆成功后,会在 VSCode的右下角弹出克隆完成提示框,点击其中的“open”按钮会使用VSCode打开克隆到本地的项目。
使用VSCode登录平台
使用VSCode打开项目后,VSCode会自动在顶部中间位置弹出登录平台的提示框,只有登录平台后才能继续使用为编译原理实验定制的功能。
登录平台的步骤如下:
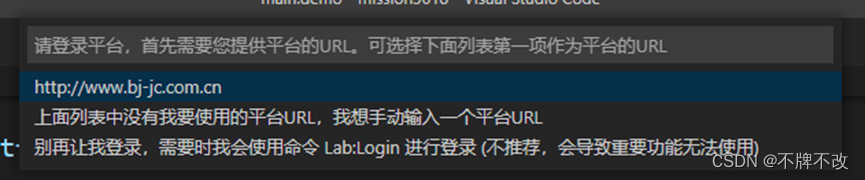
- 首先,需要在VSCode顶部弹出的列表中选择平台URL。如果是第一次登录平台,URL列表应该是空的,此时就需要选择列表中手动输入平台URL的那一项。
- 在弹出的编辑框中根据提示信息输入平台URL后按回车。平台URL为每次实验中给定的网站链接。
- 最后,按照提示依次输入平台的用户名和密码即可完成登录。
当输入登录过一次之后,用户就无需再去复制网站链接,重新输入用户名和密码了,VSCode会记录下来访问记录,下次登录只需要简单地进行点击选择即可:

登录成功后,右下角会显示:

查看项目中的文件
将项目克隆到本地磁盘后,在VSCode左侧的“文件资源管理器”窗口中可以查看项目包含的所有文件夹和源代码文件。也可以使用Windows资源管理器打开项日所在的文件夹,方法是在“文件资源管理器”窗口中的任意一个文件夹或文件节点上点击石键,然后在弹出的快捷菜单中选择“Reveal in File Explorer”。
实验源代码
该实验主要包含了三个头文件RegexpToNFA.h、RegexpToPost.h、NFAFragmentStack.h和三个C源文件main.c、RegexpToPost.c、NFAFragmentStack.c。
下面对这些文件的主要内容、结构和作用进行说明:
main.c:
在“EXPLORER”窗口中双击“main.c”打开此文件。此文件主要包含了以下内容:
1. 在文件的开始位置,使用预处理命令包含了RegexpToNFA.h、RegexpToPost.h和NFAFragmentStack.h文件。
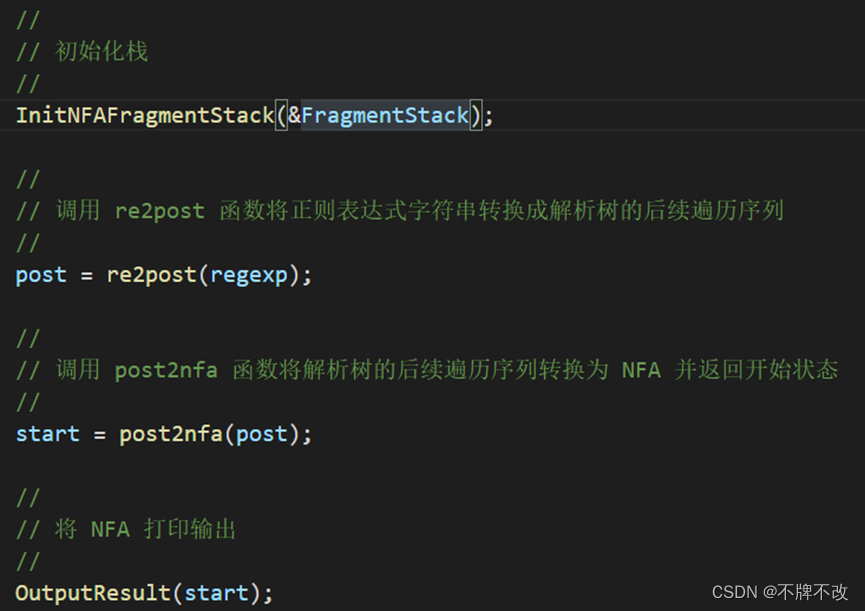
2. 定义了main函数。在其中实现了栈的初始化。然后,调用了re2post函数,将正则表达式转换到解析树的后序序列。最后,调用post2nfa函数,将解析树的后序序列转换到NFA。
3. 在main函数的后面,定义了函数CreateNFAState和 MakeNFAFragment,这两个函数分别是用来创建一个新的NFA状态和构造一个新的Fragment。接着定义了函数post2nfa,关于此函数的功能、参数和返回值,可以参见其注释。在这个函数中用‘$’表示空转换。
RegexpToPost.c:
- 在文件的开始位置,使用预处理命令包含了RegexpToPost.h文件。
- 定义了re2post函数,此函数主要功能是将正则表达式转换成为解析树的后序序列形式。
NFAFragmentStack.c:
- 在文件的开始位置,使用预处理命令包含了NFAFragmentStack.h文件。
- 定义了与栈相关的操作函数。在构造NFA的过程中,这个栈主要用来放置NFA片段。


RegexpToNFA.h:
- 包含用到的C标准库头文件。目前只包含了标准输入输出头文件“stdio.h”。
- 包含其他模块的头文件。目前没有其他模块的头文件需要被包含。
- 定义了与NFA相关的数据结构,包括NFA状态NFAState和NFA片段NFAFragment。
- 声明函数和全局变量。


RegexpToPost.h:
- 包含其他模块的头文件。目前只包含了头文件“RegexpToNFA.h”。
- 声明函数。为了使程序模块化,所以将re2post函数声明包含在一个头文件中再将此头文件包含到“main.c”中。
NFAFragmentStack.h:
- 包含其他模块的头文件。目前只包含了头文件“RegexpToNFA.h”。
- 定义重要的数据结构。定义了与栈相关的数据结构。
- 声明函数。声明了与栈相关的操作函数。
演示程序的执行过程
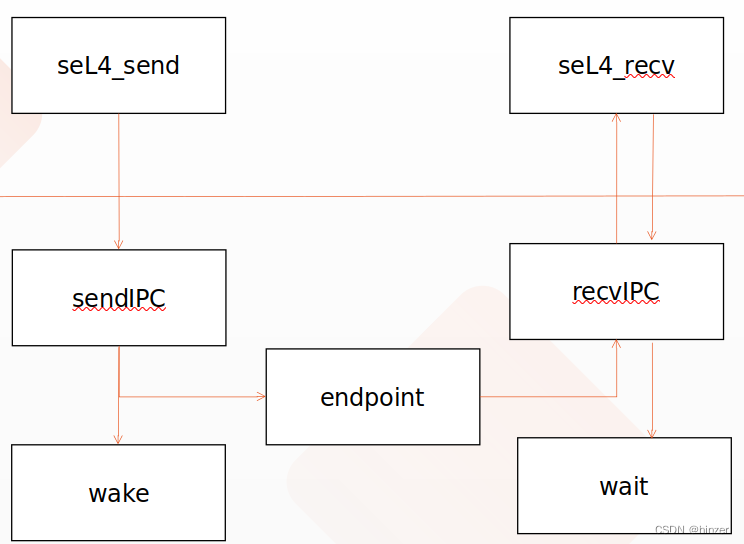
我们先不考虑“初始化栈”、“re2post”和“OutputResult”函数的实现,仅考虑main.demo中“post2nfa”,该函数的功能为:调用 post2nfa 函数将解析树的后续遍历序列转换为 NFA 并返回开始状态。
两个核心结构体:NFAState和NFAFragment。
这两个结构体分别是对NFA中每个状态的定义和NFA中从一个状态转移到另一个状态的NFA片段,简单来说就是保存了若干步状态转移的起始状态和结束状态。


这样看来,完全可以讲NFA视为链式存储,将每个状态或子NFA连接在一起,最终构成完整的NFA。
post2nfa函数中先进行初始化,之后遍历后序序列。如果遇到的字符非“.”、“|”、“*”、“?”、“+”,那么进入default分支:

先创建两个新状态,通过观察CreateNFAState函数可以很清楚地看到该函数就是对NFAState结构体进行初始化后返回。修改起始状态的Transform字符,即更新其对应的输入字符,修改起始状态经过Transform转移到的状态为NewAcceptState,将NewAcceptState状态标记为可接受状态。将两个状态传入构造NFA片段的函数中保存在fm变量中,再将NFA片段入栈,结束,枚举下一个字符。

如果遇到的字符是“.”,那么将弹出栈顶的两个NFA片段进行拼接,同时修改前一个NFA片段的AcceptState为不可接受状态,因为相当于两个链表的合并,合并之后第一个链表的尾节点将不再是整个链表的尾节点,所以要修改为不可接受状态;类似于拼接链表,还要将前一个NFA片段的AcceptState的Next指针指向后一个NFA片段的StartState;将从前一个NFA片段的AcceptState转换为后一个NFA片段的StartState的Transform修改为$,表示进行空转换。
最后将链表的起始状态和结束状态传入构造NFA片段的函数中,得到NFA片段,压入栈中。注意,我们栈中元素为NFA片段结构体,NFA片段结构体只包含两个指针,起始状态的指针和结束状态的指针,因为是链表,所以完全可以不记录转移过程中中间的状态,通过Next指针即可访问到下一个节点。
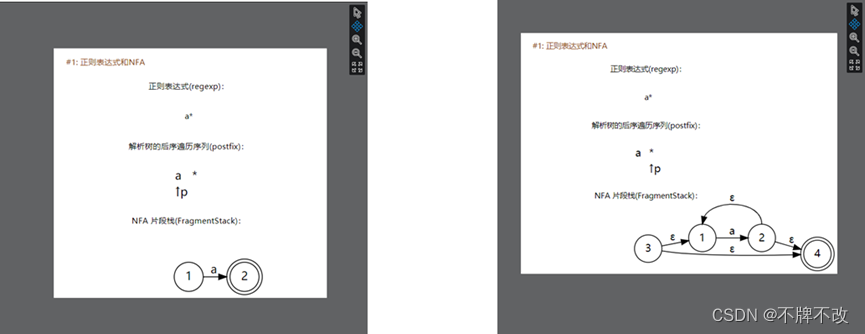
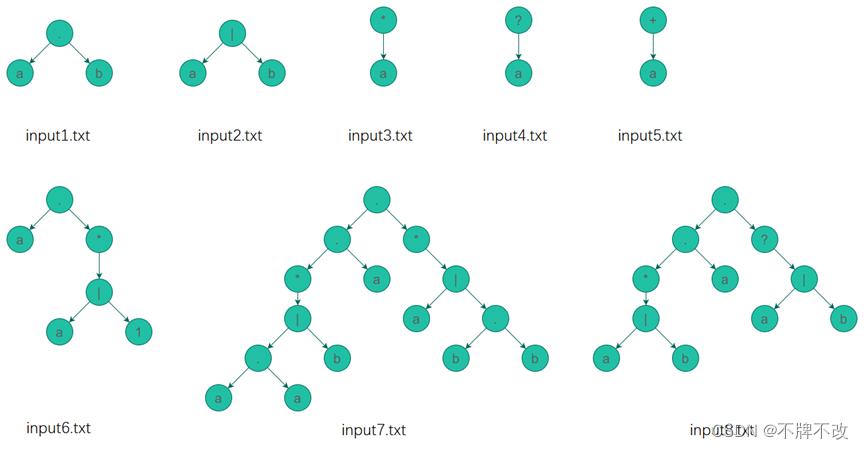
input1.txt中的内容为“ab”,对应的正则表达式的解析树为:
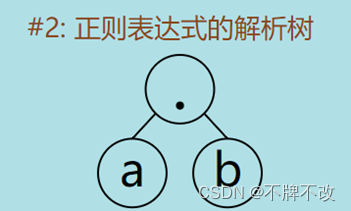
其后续遍历为“a b .”。根据上面描述的流程,我们可以知道遍历到“a”,构建状态1经过“a”转移到状态2的NFA片段,状态2为可接受状态。

接下来遍历到了“b”,依然进入default分支。创建状态3经过“b”到达可接受状态4的NFA片段。
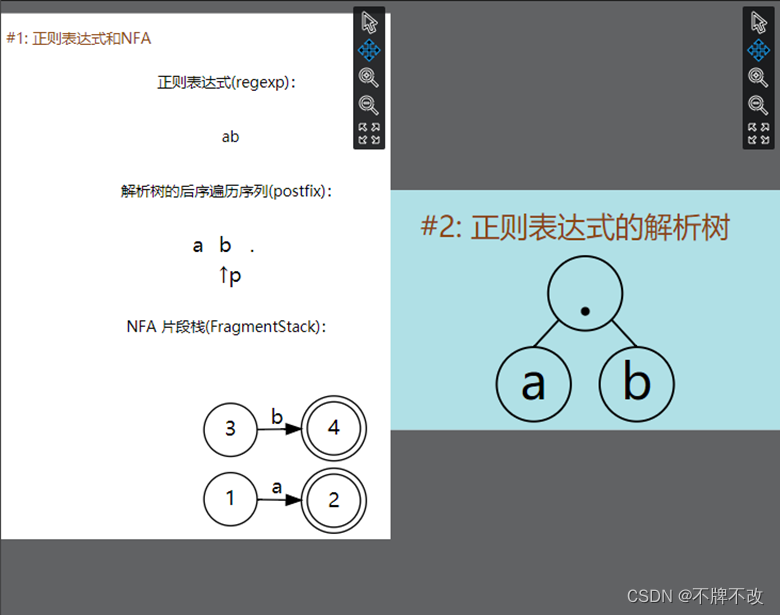
最后遇到“.”,需要获取栈顶两个NFA片段并进行合并后再入栈。由于遍历完最后一个字符后会直接弹出栈顶的唯一一个NFA片段,也就是最终完整的NFA。
四、实验过程
完成“input2.txt”NFA片段的构造
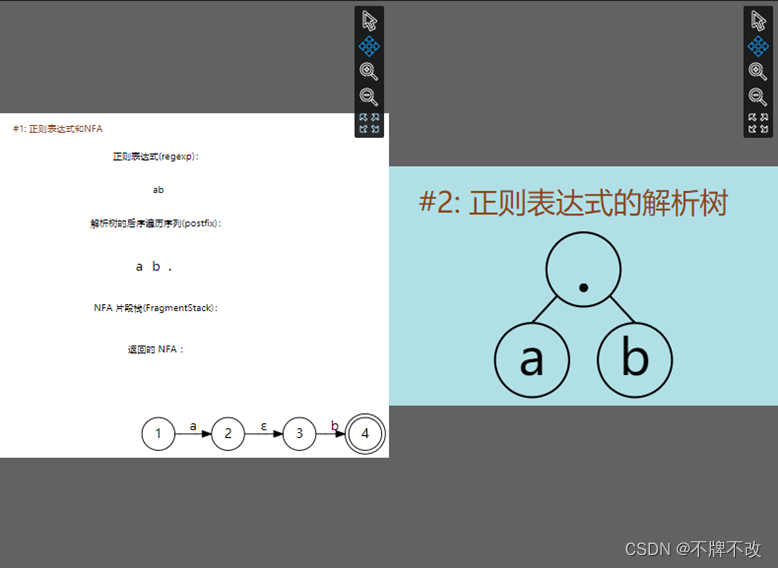
“a|b”对应的解析树:
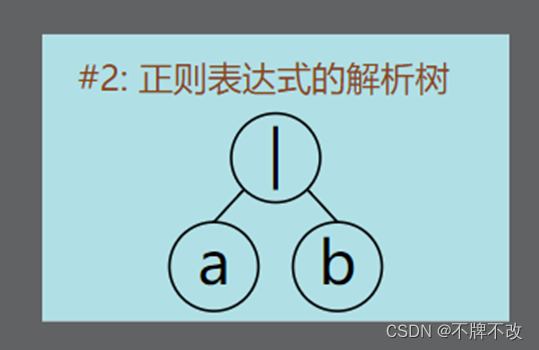
根据输出的结果,我们可以判断出NFA片段拼接方案:
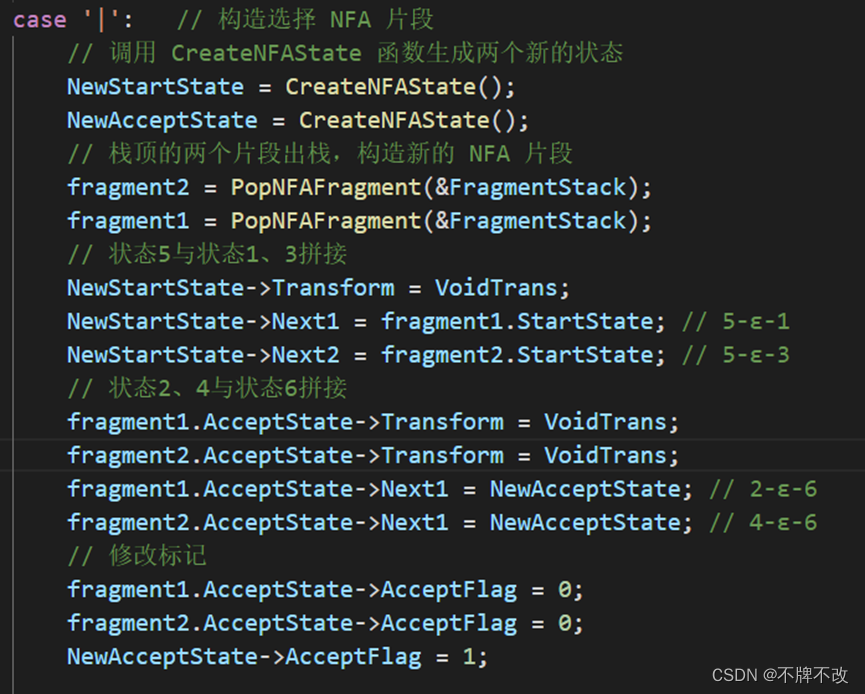
先构造出新状态5和6,将5的两个Next指针指向状态1和状态3,将状态2和状态4的Next指针指向状态6。注意修改状态2、4、5的Transform,并将状态2和4的AcceptFlag修改为0,将新状态6的AcceptFlag修改为1,表示到达可接受状态。
补充代码如下:
添加断点观察过程:

完成“input3.txt”NFA片段的构造
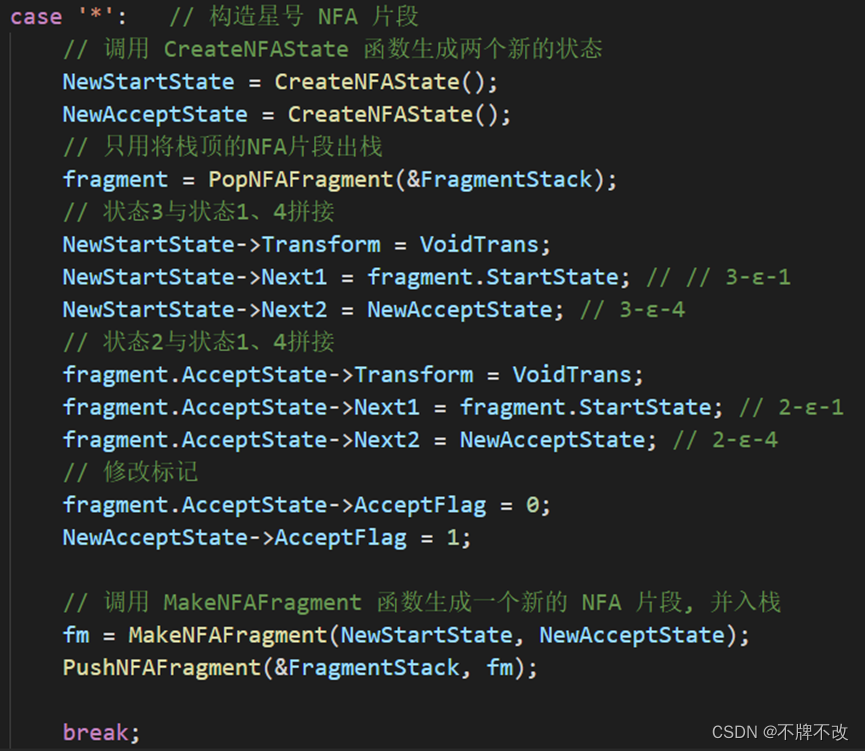
“a*”对应的解析树:
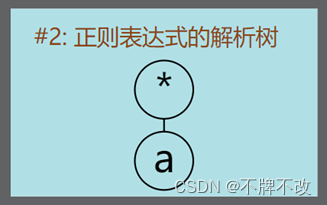
根据输出的结果,我们可以判断出NFA片段拼接方案:
先构造出新状态3和4,将2的两个Next指针指向状态1和状态4,将状态1的两个Next指针指向状态1和状态4。注意修改状态2、3的Transform,并将状态2的AcceptFlag修改为0,将新状态4的AcceptFlag修改为1,表示到达可接受状态。
补充代码如下:
添加断点观察过程:
完成“input4.txt”NFA片段的构造
“a?”对应的解析树:
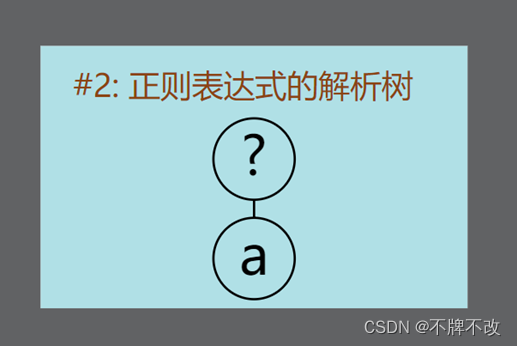
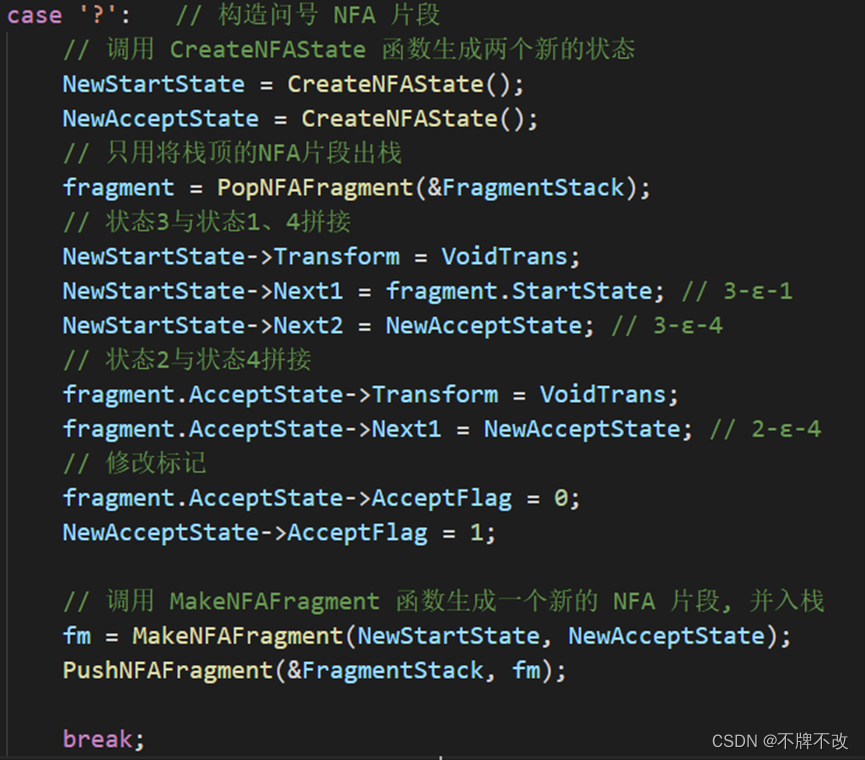
根据输出的结果,我们可以判断出NFA片段拼接方案:
与“*”类似,先构造出新状态3和4,将2的Next指针指向状态4,将状态1的两个Next指针指向状态1和状态4。注意修改状态2、3的Transform,并将状态2的AcceptFlag修改为0,将新状态4的AcceptFlag修改为1,表示到达可接受状态。
补充代码如下:
添加断点观察过程:
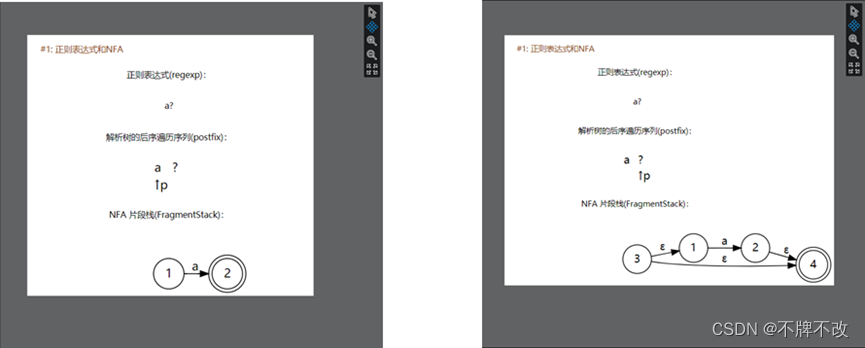
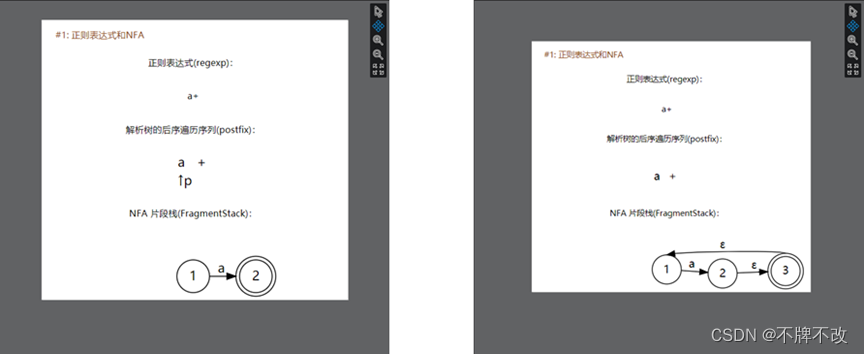
完成“input5.txt”NFA片段的构造
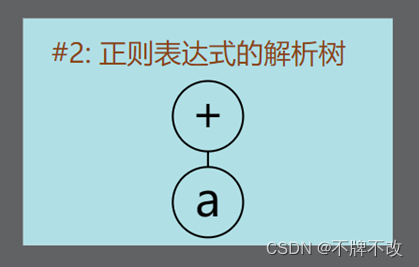
“a+”对应的解析树:
根据输出的结果,我们可以判断出NFA片段拼接方案:
先构造出新状态3,将2的Next指针指向状态3,将状态3的Next指针指向状态1。注意修改状态2、3的Transform,并将状态2的AcceptFlag修改为0,将新状态3的AcceptFlag修改为1,表示到达可接受状态。
补充代码如下:
添加断点观察过程:
自动化验证
1. 在VSCode的“Terminal”菜单中选择“Run Build Tasks...”(快捷键是Ctrl+Shift+B),在弹出的下拉列表中选择“测试”。
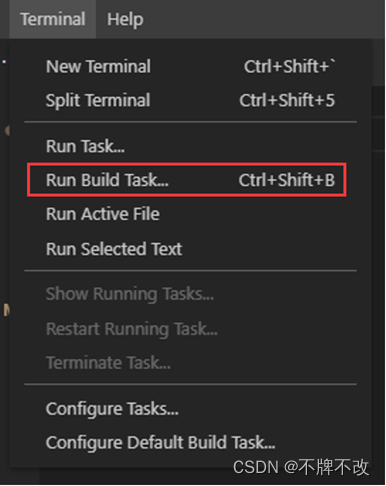
2. 在验证过程中,VSCode底部的“TERMTNAL”窗口会显示验证的过程和最后的结果。
3. 由于 post2nfa 函数还不完整,所以会导致验证失败。此时,会使用浏览器白动打开result_comparation.html 文件,在其中显示了标准答案文件与读者编写的应用程序产生的结果文件的不同之处,从而帮助读者准确定位失败的原因。

思考与练习
1. 编写一个FreeNFA函数,当在main函数的最后调用此函数时,可以将整个NFA的内存释放掉,从而避免内存泄露。
定义:
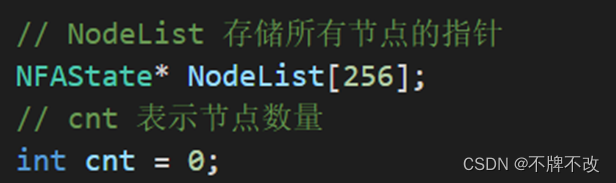
修改一下CreateNFAState函数:

定义函数,添加调用语句:

2. 编写完代码之后可以对input2.txt到input5.txt中的算例进行一一验证,确保程序可以将所有形式的正则表达式转换为正确的NFA,并验证通过。
上文中已进行验证,且均已通过。
3. 对input6.txt、input7.txt、input8.txt文件中的正则表达式进行验证,并画出例7和例8的NFA状态图。
上文中已进行验证,且均已通过。
input7.txt对应的NFA状态图:
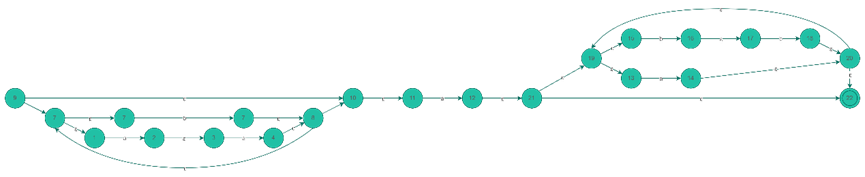
input8.txt对应的NFA状态图:

4. 详细阅读re2post函数中的源代码,并尝试在源代码中添加注释。然后尝试为本实验中所有的例子绘制解析树(类似二叉树)。
五、实验总结
本次实验主要是对环境进行配置,同时补全了由解析树的后序遍历序列生成NFA的代码。
根据实验指导手册,了解了在VSCode环境中Git的基本使用方法,并学会了断点调试与配置launch.json文件。对于不同的exe文件,可以通过配置launch.json文件的configurations数组中对应的name和args来控制对不同txt文件进行重定向输入,通过更改program可以将内容输入到不同的exe可执行文件中执行并输出。
学会断点的设置与调试会大大增强程序员debug的能力。可以在任意语句对应行号的左侧点击以添加或删除断点;F5是启动调试的快捷键,也是“下一步”的快捷键,ctrl+F5是结束调试的快捷键;黄色箭头指向中断的代码行,中断的代码行表示该行代码还没有执行,也就是说该行代码是下一步将要执行的代码;在调试演示demo程序的过程中,main.demo文件中包含了很多隐藏的断点,所以我们并不需要自己添加断点。但是,在我们自己编程的时候要学会在合适的位置加断点以观察变量内存信息。
学习的另一部分内容是将解析树的后续遍历系列转换为NFA。这一部分是与课程内容相挂钩的,整体的设计思路已经由源代码给出,我们只需要处理遇到不同的字符时应当对状态栈进行怎样的出栈和入栈操作,以及如何处理每个状态的属性。补全代码主要是根据输出结果的NFA状态图进行链表的拼接操作,可能存在的难点是理解NFAState和NFAFragment结构体的含义、对链表不够熟悉、对修改链表指针的操作陌生。当克服了这些问题后,生成NFA部分的代码补全会变得比较容易。虽然顺利完成了main.c的代码补全,但是对于模块内部调用的其他函数不能很好地理解,后续会继续投入时间去理解和掌握。