字符输入流Reader的超详细用法及底层原理
- 一、背景
- 二、字符输入流Reader正式出场
- 三、IO流体系图概览
- 四、Reader继承人:FileReader出场
- 五、字符流原理解析
一、背景
当我们使用字节输入流时,经常会出现乱码问题,具体原因如下:
- 解码和编码时的方式不统一
- 读取数据时未读完整个汉字,因为字节输入流,是一次读一个字节,而一个汉字会占多个字节,当读到某个汉字时,未读完其所有字节,就会出现乱码
二、字符输入流Reader正式出场
核心奥义:
- 字符输入流Reader,也是一次读一个字节,但是当遇到中文时,就会一次读多个字节,相当于直接读一个汉字出来,这样就解决了字节输入流未读完整个汉字,出现乱码的问题。
字符流 - 底层揭秘
- 字符流 = 字节流 + 字符集

字符流特点 - 字符输入流:一次读一个字节,遇到中文时,一次读多个字节(可能是2个字节或3个字节,这个跟字符集有个哦)【对字符集有疑问的同学可以参考我之前的文章https://flypeppa.blog.csdn.net/article/details/133838023】
- 字符输出流:底层会把数据按照指定的编码方式进行编码,变成字节再写到文件中
- 最大的特点是,如果文件中有中文,使用字符流操作,不会出现乱码问题
使用场景
- 对于纯文本文件进行读写操作
三、IO流体系图概览
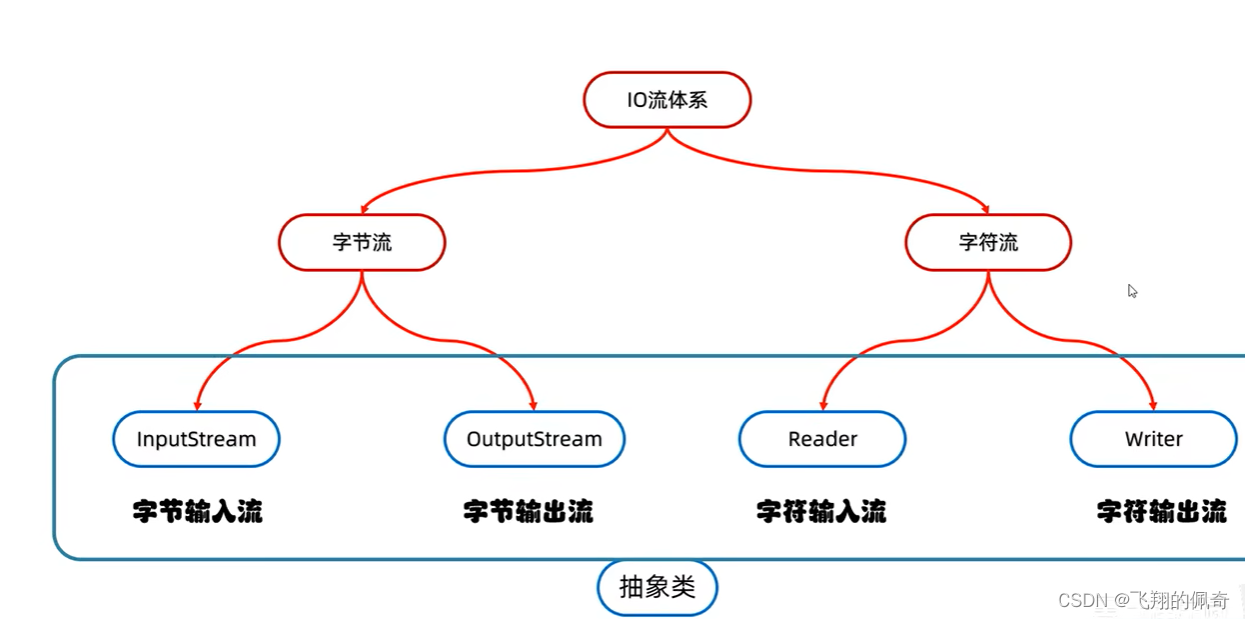
因为我们本次学习的是字符流,所以看一下字符流的体系图
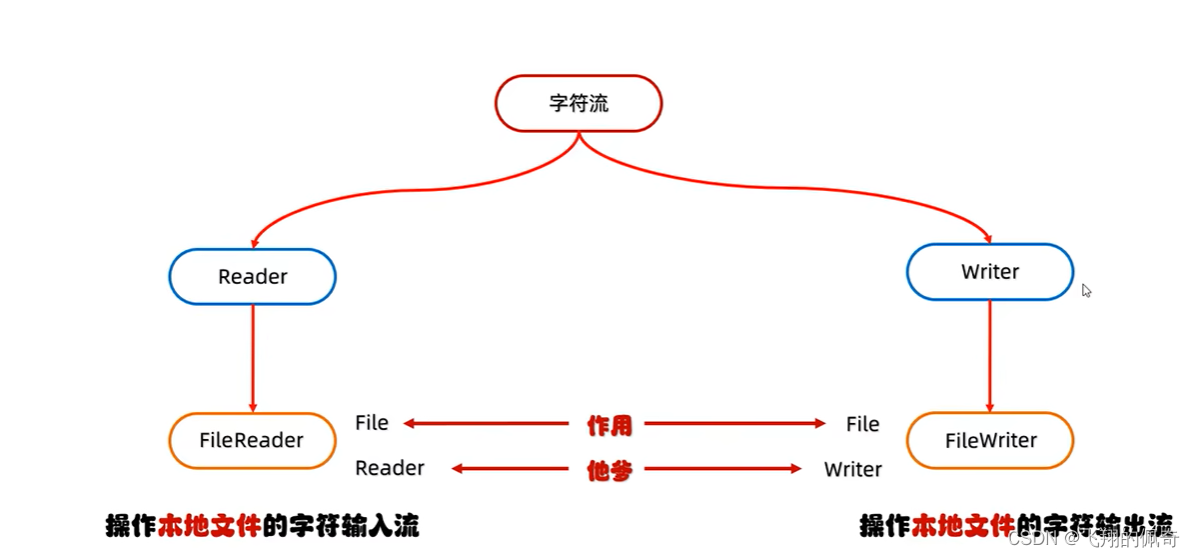
四、Reader继承人:FileReader出场
1、FileReader读取数据的方法
- public int read() 读取数据,读到末尾返回-1
- public int read(char cbuf[]) 读取多个数据,读到末尾返回-1
细节1:按字节进行读取,遇到中文,一次读多个字节,读取后解码,返回一个整数
细节2:读到文件末尾了,read方法返回-1。
2、代码实战
读取单个中文
package com.hidata.devops.paas.demo;
import java.io.FileReader;
import java.io.IOException;
/**
* @Description :
* @Date: 2023-10-18 10:59
*/
public class TestsDemo {
public static void main(String[] args) throws IOException {
FileReader fir = new FileReader("D:\\devops\\paas\\demo\\d.txt");
int ch;
while ((ch = fir.read()) != -1){
System.out.print((char) ch);
}
fir.close();
}
}
读取多个数据
package com.hidata.devops.paas.demo;
import java.io.FileReader;
import java.io.IOException;
/**
* @Description :
* @Date: 2023-10-18 10:59
*/
public class TestsDemo {
public static void main(String[] args) throws IOException {
FileReader fir = new FileReader("D:\\devops\\paas\\demo\\d.txt");
int ch;
char[] chars = new char[2];
while ((ch = fir.read(chars)) != -1){
System.out.println(new String(chars,0,ch));
}
fir.close();
}
}
五、字符流原理解析
1、创建字符输入流对象
底层
- 关联文件,并创建缓冲区(长度为8192的字节数组)
2、读取数据
底层
- 1.判断缓冲区中是否有数据可以读取
- 2.缓冲区没有数据:就从文件中获取数据,装到缓冲区中,每次尽可能装满缓冲区;
如果文件中也没有数据了,返回-1 - 3.缓冲区有数据:就从缓冲区中读取。
空参的read方法:一次读取一个字节,遇到中文一次读多个字节,把字节解码并转成十进制返回;
有参的read方法:把读取字节,解码,强转三步合并了,强转之后的字符放到数组中
3、代码验证原理
debug代码,看截图
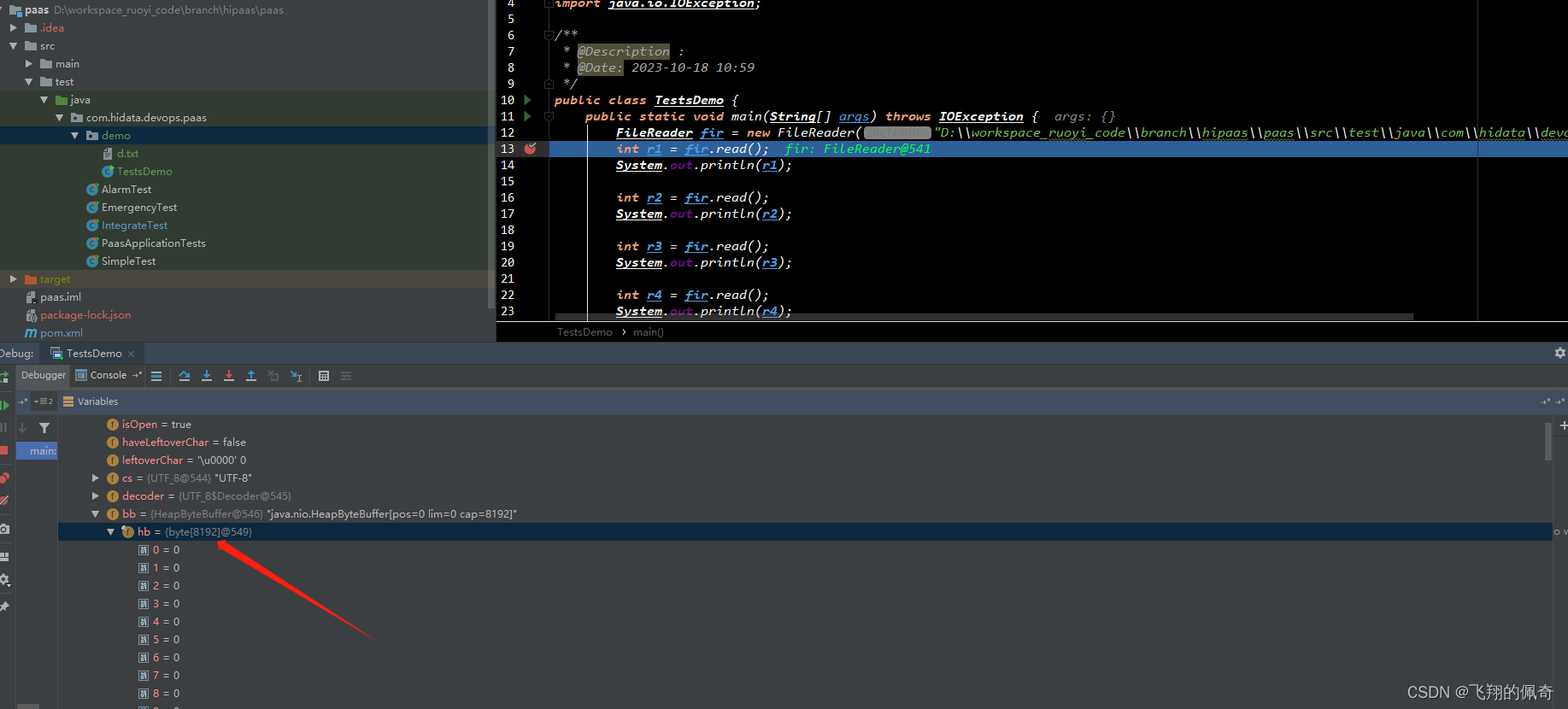
我们发现,一开始就创建了一个缓冲区,长度为8192的字节数组。并且目前缓冲区里面是没有数据的
接下来,我们先往下走一步,
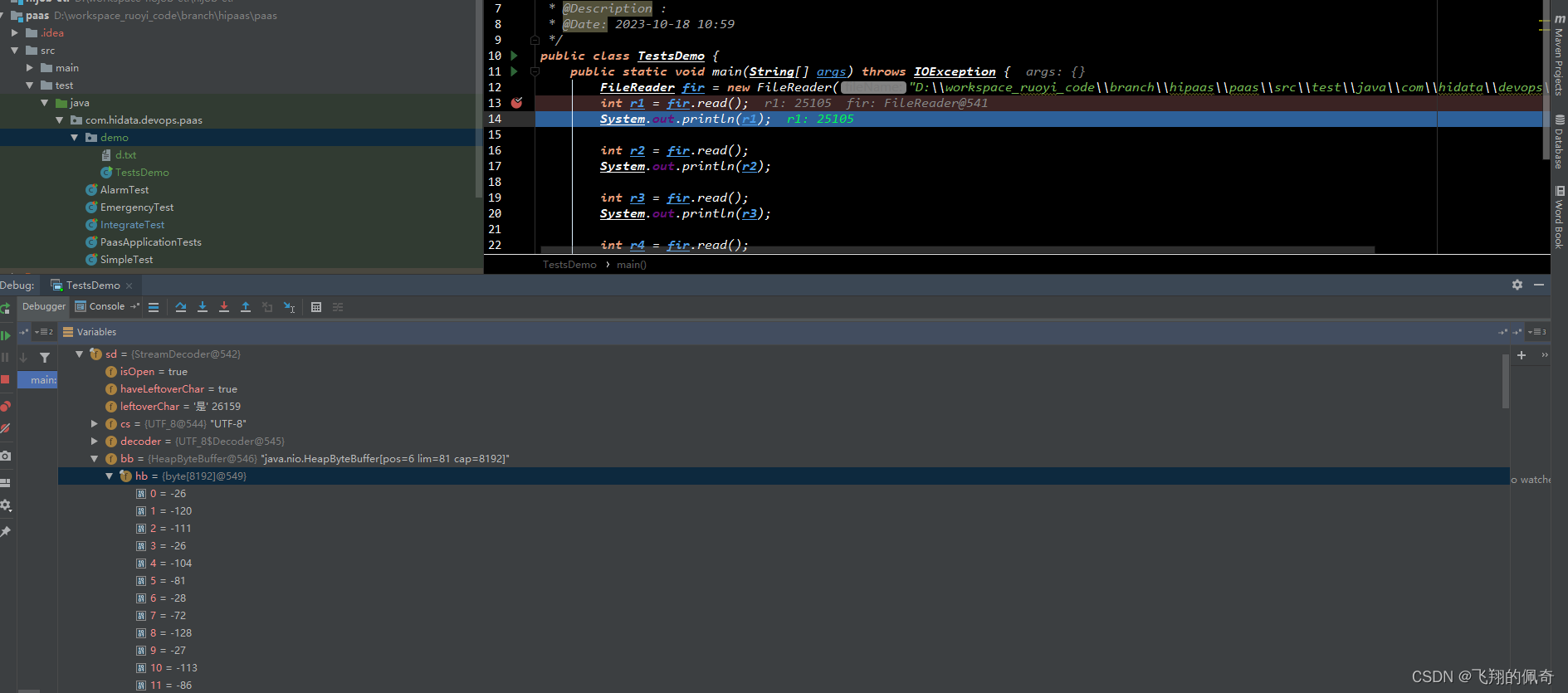
我们发现,第一次读取的时候,他就会把文件里面的所有字节信息都装到缓冲区里面,并且尽可能装满缓冲区。后面再次读取数据的时候,会直接先从缓冲区里面拿,提供效率
4、扩展
文件大小超过缓冲区默认大小(8192)怎么办 ?
- 如果当前文件的字节数超过缓冲区的大小(8192字节),那么会先把文件的一部分,装满到缓冲区,当缓冲区数据读完之后,再将文件里面剩余的数据,继续装到缓冲区,以此类推。






![[计算机提升] 环境变量](https://img-blog.csdnimg.cn/728315a04cc34eecaaf8d1ead088a321.png)