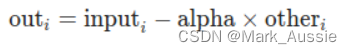前言
上次已经学习了open AI的 DDPM(DDPM原理与代码剖析)和 IDDPM(IDDPM原理和代码剖析), 以及 斯坦福的 DDIM DDIM原理及代码(Denoising diffusion implicit models). 这次来看openAI的另一个作品 Diffusion Models Beat GANs on Image Synthesis
github: https://github.com/openai/guided-diffusion
该博客主要参考 66、Classifier Guided Diffusion条件扩散模型论文与PyTorch代码详细解读
先挖个坑…
理论
前置
(1) 作者先在uncondition 的扩散模型上做了很多消融实验,得到了一些结论,并用这些结论设计结构
(2) 一种straightforward的condition 扩散模型方法是将label信息进行embedding后加到time embedding中,但是效果不是很好。所以本文加上了分类器指导的方法(并没有把上述的常规的condition生成方法丢弃)。
具体的做法是在分类器中获取图片X的梯度,从而辅助模型进行采样生成图像。
Introduction
(1) diffusion模型是一个似然模型。
(2) 模型借鉴了improve-ddpm中预测方差的range(即公式中的v)
Σ
θ
(
X
t
,
t
)
=
e
x
p
(
v
l
o
g
β
t
+
(
1
−
v
)
l
o
g
β
~
t
)
\Sigma_{\theta}(X_t, t)=exp(vlog\beta_t + (1-v)log \widetilde{\beta}_t)
Σθ(Xt,t)=exp(vlogβt+(1−v)logβ
t)
(3) 更改unet结构:
We explore the following architectural changes:
• Increasing depth versus width, holding model size relatively constant.
• Increasing the number of attention heads.
• Using attention at 32×32, 16×16, and 8×8 resolutions rather than only at 16×16.
• Using the BigGAN residual block for upsampling and downsampling the activations,
following.
• Rescaling residual connections with
1
2
\frac{1}{\sqrt{2}}
21, following [60, 27, 28].
Adaptive Group Normalization
用time embedding和label embedding 去生成
y
s
y_s
ys 和
y
b
y_b
yb
A
d
a
G
N
(
h
,
y
)
=
y
s
G
r
o
u
p
N
o
r
m
(
h
)
+
y
b
AdaGN(h, y) = y_s GroupNorm(h)+y_b
AdaGN(h,y)=ysGroupNorm(h)+yb
以下部分在附录H (P25-26)