文章目录
- 1.Spring Data `Elasticsearch`
- 2.案例准备
- 2.1 在 Elasticsearch 中创建 students 索引
- 2.2 案例测试说明
- 3.创建项目
- 3.1 新建工程
- 3.2 新建 springboot module,添加 spring data elasticsearch 依赖
- 3.3 pom.xml 文件
- 3.4 application.yml 配置
- 4.Student 实体类
- 5.通过 ElasticsearchRepository 实现 CRUD 操作
- 5.1 StudentRepository接口
- 5.2 业务类 StudentService
- 5.3 测试学生数据的 CRUD 操作
- 6.使用 Repository 构建查询
- 6.1 Repository 方法命名规范
- 6.2 Repository API查询案例
- 6.3 创建测试方法进行测试
- 7.分页操作
- 7.1 Pageable
- 7.2 修改 StudentService
- 7.3 在测试类中添加测试方法
- 8.查询结果的高亮显示
- 8.1 接口方法
- 8.2 测试类方法
- 9.使用 Criteria 构建查询
- 9.1 StudentSearcher
- 9.2 在测试类中测试
1.Spring Data Elasticsearch
可以访问spring官网查看其API的具体使用方式:https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/#reference
Spring Data Elasticsearch 是 Elasticsearch 搜索引擎开发的解决方案。它提供了模板对象,用于存储、搜索、排序文档和构建聚合的高级API。
例如,Repository 使开发者能够通过定义具有自定义方法名称的接口来表达查询。
2.案例准备
在 Elasticsearch 中存储学生数据,并对学生数据进行搜索测试。
数据结构:
| 学号 | 姓名 | 性别 | 出生日期 |
|---|---|---|---|
| 27 | 张三 | 男 | 2020-12-4 |
案例测试以下数据操作:
2.1 在 Elasticsearch 中创建 students 索引
在开始运行测试之前,在 Elasticsearch 中先创建 students 索引:
PUT /students
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2,
"index.max_ngram_diff":30,
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 30,
"token_chars": [
"letter",
"digit"
]
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ngram_analyzer"
},
"gender": {
"type": "keyword"
},
"birthDate": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
}
创建索引之后,kibana容器就不用使用了,因为其占用了比较多的内容,所以可以使用docker rm -f kibana删除kibana容器;

2.2 案例测试说明
通过对学生数据的CRUD操作,来使用Spring Data ElasticsearchAPI:
- C - 创建学生数据
- R - 访问学生数据
- U - 修改学生数据
- D - 删除学生数据
- 使用 Repository 和 Criteria 搜索学生数据
3.创建项目
3.1 新建工程
我们新建一个新的elasticsearchEmpty Project工程:
3.2 新建 springboot module,添加 spring data elasticsearch 依赖

3.3 pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>cn.study</groupId>
<artifactId>spring-data-es</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3.4 application.yml 配置
#logging.level.tracer=TRACE 作用是在控制台中显示底层的查询日志
spring:
elasticsearch:
rest:
uris:
- http://192.168.64.181:9200
- http://192.168.64.181:9201
- http://192.168.64.181:9202
# REST API调用的http协议数据日志
logging:
level:
tracer: TRACE
4.Student 实体类
package cn.study.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
/**
* spring data es API 可以根据这里的设置,
* 在服务器上自动创建索引,
* 一般索引需要自己手动创建,不应依赖于客户端API自动创建
* indexName:索引名,我们这里对应的是students
* shards:可选属性,分片数量
* replicas:可选属性,副本数量
*/
@Document(indexName = "students",shards = 3,replicas = 2)
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
// 使用学生的学号,作为索引id(_id字段)
@Id
private Long id;
private String name;
private Character gender;
//@Field设置类中的属性对应索引中的字段名的关系,如果同名可以省略
@Field("birthDate") //索引中的字段名
private String birthDate; //对应类中的属性
}
- @Document 注解
- @Documnet注解对索引的参数进行设置。
- 上面代码中,把 students 索引的分片数设置为3,副本数设置为2。
- @Id 注解
- 在 Elasticsearch 中创建文档时,使用 @Id 注解的字段作为文档的 _id 值
- @Field 注解
- 通过 @Field 注解设置字段的数据类型和其他属性。
- 文本类型 text 和 keyword
- text 类型会进行分词。
- keyword 不会分词。
- analyzer 指定分词器
- 通过 analyzer 设置可以指定分词器,例如 ik_smart、ik_max_word 等。
我们这个例子中,对学生姓名字段使用的分词器是 ngram 分词器,其分词效果如下面例子所示:
| 字符串 | 分词结果 |
|---|---|
| 刘德华 | 刘 |
| 刘德 | |
| 刘德华 | |
| 德 | |
| 德华 | |
| 华 |
5.通过 ElasticsearchRepository 实现 CRUD 操作
Spring Data 的 Repository 接口提供了一种声明式的数据操作规范,无序编写任何代码,只需遵循 Spring Data 的方法定义规范即可完成数据的 CRUD 操作。
ElasticsearchRepository 继承自 Repository,其中已经预定义了基本的 CURD 方法,我们可以通过继承 ElasticsearchRepository,添加自定义的数据操作方法。
5.1 StudentRepository接口
package cn.study.es;
import cn.study.entity.Student;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
/**
* 我们这里基于Spring Data API 的Repository数据访问规范进行业务测试
* 这种规范不需要我们自己完成相关代码,只需要定义抽象类,抽象方法就可以访问数据库的数据
*
* 接口中已经定义了基础的增删改查方法
* 继承的接口中需要传入俩个参数(访问学生数据,ID是Long类型)
*/
public interface StudentRepository extends ElasticsearchRepository<Student,Long> {
}
5.2 业务类 StudentService
package cn.tedu.esspringboot.es;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class StudentService {
@Autowired
private StudentRepository studentRepo;
public void save(Student student) {
studentRepo.save(student);
}
public void delete(Long id) {
studentRepo.deleteById(id);
}
public void update(Student student) {
save(student);
}
public List<Student> findByName(String name) {
return studentRepo.findByName(name);
}
public List<Student> findByNameOrBirthDate(String name, String birthDate) {
return studentRepo.findByNameOrBirthDate(name, birthDate);
}
}
5.3 测试学生数据的 CRUD 操作
添加测试类,对学生数据进行 CRUD 测试
package cn.study;
import cn.study.entity.Student;
import cn.study.es.StudentRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Optional;
@SpringBootTest
public class Test1 {
@Autowired
private StudentRepository studentRepository;
//调用API提供的save方法将数据存储到索引中
@Test
public void test1(){
studentRepository.save(new Student(9527L,"卡布达",'男',"2023-10-11"));
studentRepository.save(new Student(9528L,"蜻蜓队长",'男',"2023-10-12"));
studentRepository.save(new Student(9529L,"鲨鱼辣椒",'男',"2023-10-13"));
studentRepository.save(new Student(9530L,"蟑螂恶霸",'男',"2023-10-14"));
studentRepository.save(new Student(9531L,"丸子滚滚",'男',"2023-10-15"));
studentRepository.save(new Student(9532L,"蝎子莱莱",'男',"2023-10-16"));
studentRepository.save(new Student(9533L,"金贵次郎",'男',"2023-10-17"));
studentRepository.save(new Student(9534L,"呱呱蛙",'男',"2023-10-18"));
studentRepository.save(new Student(9535L,"蜘蛛侦探",'男',"2023-10-19"));
studentRepository.save(new Student(9536L,"呱呱蛙",'男',"2023-10-20"));
studentRepository.save(new Student(9537L,"呱呱蛙",'男',"2023-10-21"));
studentRepository.save(new Student(9538L,"呱呱蛙",'男',"2023-10-22"));
studentRepository.save(new Student(9539L,"呱呱蛙",'男',"2023-10-23"));
}
//更新9527数据的名字和时间
@Test
public void test2(){
studentRepository.save(new Student(9527L,"巨人卡布达",'男',"2023-10-19"));
}
/**
* 查询操作:
* java.util.Optinal 防止出现空指针异常
*/
@Test
public void test3(){
Optional<Student> op = studentRepository.findById(9527L);
if(op.isPresent()){//判断内部包含的对象是否存在
Student s = op.get();
System.out.println(s);
}
System.out.println("----------------------------------------------");
Iterable<Student> all = studentRepository.findAll();
for (Student s :
all) {
System.out.println(s);
}
}
//删除操作
@Test
public void test4(){
studentRepository.deleteById(9530L);
}
}
依次运行每个测试方法,并使用 head 观察测试结果
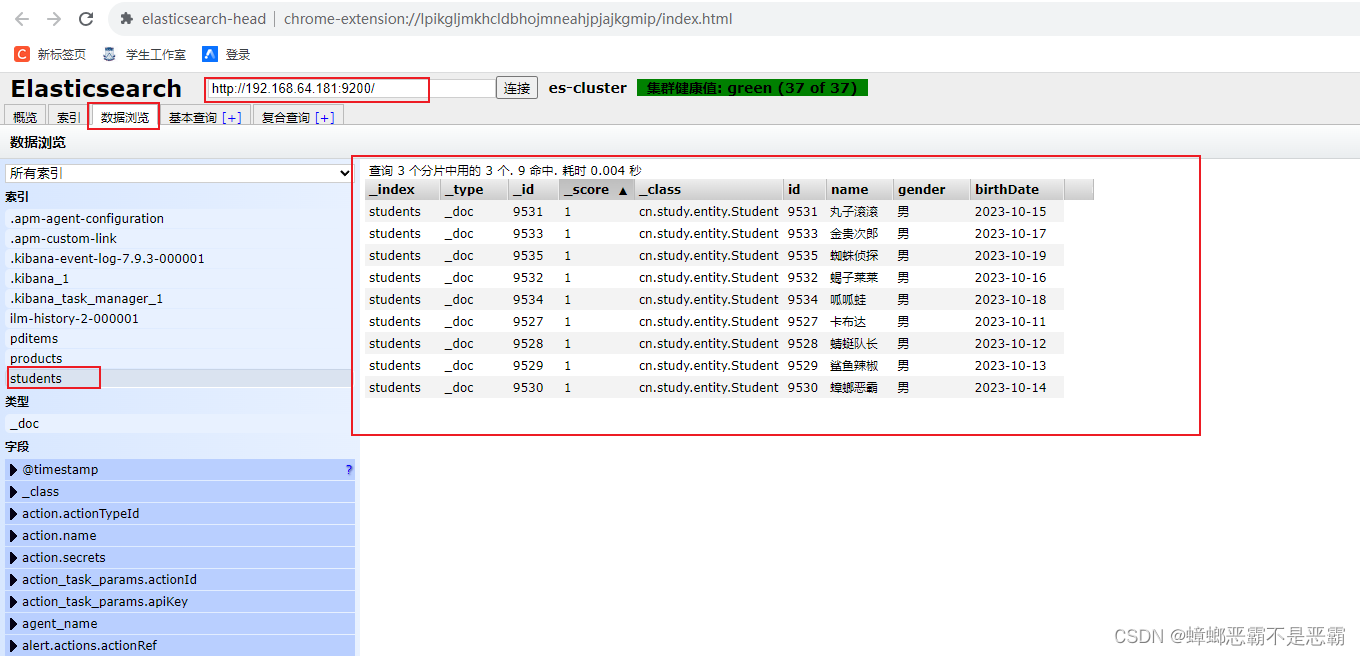
并且通过打印的日志我们可以看到,http请求通过PUT请求添加数据,通过POST请求获取状态标志:
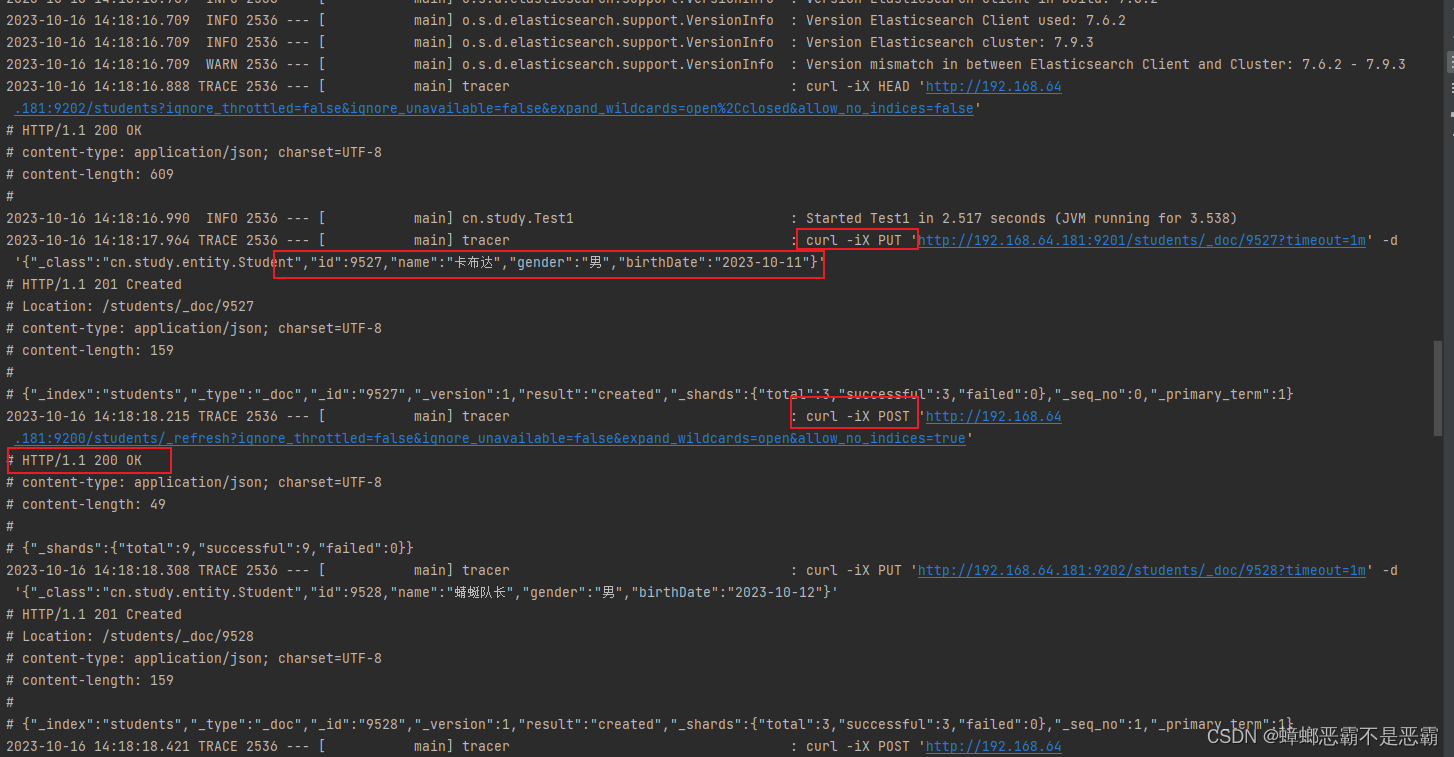
6.使用 Repository 构建查询
Spring Data Elasticsearch 中,可以使用 SearchOperations 工具执行一些更复杂的查询,这些查询操作接收一个 Query 对象封装的查询操作。
Spring Data Elasticsearch 中的 Query 有三种:
- CriteriaQuery
- StringQuery
- NativeSearchQuery
多数情况下,CriteriaQuery 都可以满足我们的查询求。下面来看两个 Criteria 查询示例:
6.1 Repository 方法命名规范
自定义数据操作方法需要遵循 Repository 规范,示例如下:
| 关键词 | 方法名 | es查询 |
|---|---|---|
| And | findByNameAndPrice | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] } }, { “query_string” : { “query” : “?”, “fields” : [ “price” ] } } ] } }} |
| Or | findByNameOrPrice | { “query” : { “bool” : { “should” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] } }, { “query_string” : { “query” : “?”, “fields” : [ “price” ] } } ] } }} |
| Is | findByName | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] } } ] } }} |
| Not | findByNameNot | { “query” : { “bool” : { “must_not” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] } } ] } }} |
| Between | findByPriceBetween | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : ?, “to” : ?, “include_lower” : true, “include_upper” : true } } } ] } }} |
| LessThan | findByPriceLessThan | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : null, “to” : ?, “include_lower” : true, “include_upper” : false } } } ] } }} |
| LessThanEqual | findByPriceLessThanEqual | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : null, “to” : ?, “include_lower” : true, “include_upper” : true } } } ] } }} |
| GreaterThan | findByPriceGreaterThan | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : ?, “to” : null, “include_lower” : false, “include_upper” : true } } } ] } }} |
| GreaterThanEqual | findByPriceGreaterThan | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : ?, “to” : null, “include_lower” : true, “include_upper” : true } } } ] } }} |
| Before | findByPriceBefore | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : null, “to” : ?, “include_lower” : true, “include_upper” : true } } } ] } }} |
| After | findByPriceAfter | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : ?, “to” : null, “include_lower” : true, “include_upper” : true } } } ] } }} |
| Like | findByNameLike | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?*”, “fields” : [ “name” ] }, “analyze_wildcard”: true } ] } }} |
| StartingWith | findByNameStartingWith | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?*”, “fields” : [ “name” ] }, “analyze_wildcard”: true } ] } }} |
| EndingWith | findByNameEndingWith | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “*?”, “fields” : [ “name” ] }, “analyze_wildcard”: true } ] } }} |
| Contains/Containing | findByNameContaining | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] }, “analyze_wildcard”: true } ] } }} |
| In (when annotated as FieldType.Keyword) | findByNameIn(Collectionnames) | { “query” : { “bool” : { “must” : [ {“bool” : {“must” : [ {“terms” : {“name” : [“?”,“?”]}} ] } } ] } }} |
| In | findByNameIn(Collectionnames) | { “query”: {“bool”: {“must”: [{“query_string”:{“query”: “”?" “?”", “fields”: [“name”]}}]}}} |
| NotIn (when annotated as FieldType.Keyword) | findByNameNotIn(Collectionnames) | { “query” : { “bool” : { “must” : [ {“bool” : {“must_not” : [ {“terms” : {“name” : [“?”,“?”]}} ] } } ] } }} |
| NotIn | findByNameNotIn(Collectionnames) | {“query”: {“bool”: {“must”: [{“query_string”: {“query”: “NOT(”?" “?”)", “fields”: [“name”]}}]}}} |
| Near | findByStoreNear | |
| True | findByAvailableTrue | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “true”, “fields” : [ “available” ] } } ] } }} |
| False | findByAvailableFalse | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “false”, “fields” : [ “available” ] } } ] } }} |
| OrderBy | findByAvailableTrueOrderByNameDesc | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “true”, “fields” : [ “available” ] } } ] } }, “sort”:[{“name”:{“order”:“desc”}}] } |
例如上表中的findByName方法,query后面的?是当前方法的搜索关键词,fields字段后面跟着的就是查询的字段;

使用此类查询,一定遵循表格中的方法命名规范;
6.2 Repository API查询案例
我们在StudentRepository接口中构建Repository API提供的查询方法:
package cn.study.es;
import cn.study.entity.Student;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
/**
* 我们这里基于Spring Data API 的Repository数据访问规范进行业务测试
* 这种规范不需要我们自己完成相关代码,只需要定义抽象类,抽象方法就可以访问数据库的数据
*
* 接口中已经定义了基础的增删改查方法
* 继承的接口中需要传入俩个参数(访问学生数据,ID是Long类型)
*/
public interface StudentRepository extends ElasticsearchRepository<Student,Long> {
//使用name字段搜索关键词
List<Student> findByName(String key);
//使用name字段或者birthdate字段中搜索关键词
List<Student> findByNameOrBirthDate(String name ,String birthdate);
}
一定要注意方法名验证遵循6.1 Repository 方法命名规范中的要求;
6.3 创建测试方法进行测试
package cn.study;
import cn.study.entity.Student;
import cn.study.es.StudentRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
/**
* Repository 构建查询案例
* */
@SpringBootTest
public class Test2 {
@Autowired
private StudentRepository studentRepository;
@Test
public void test1(){
//可以使用单独的关键字进行搜索
List<Student> list1 = studentRepository.findByName("卡");
for (Student s1: list1) {
System.out.println(s1);
}
System.out.println("------------------------");
//但是对于日期是不分词的,无法通过分词进行搜索
List<Student> list2 = studentRepository.findByNameOrBirthDate("呱", "2023-10-18");
for (Student s2: list2) {
System.out.println(s2);
}
}
}
7.分页操作
分页对于搜索来说十分重要,大量数据的操作必须进行分页操作,否则十分影响性能及客户体验;Repository API 同样提供了分页的工具;
7.1 Pageable
Pageable 封装了向服务器提交的分页参数–页数及每页数据 ,第1页数据,提交数据0,第2页数据,提交数据1,以此类推;
并且其提供了一个可选参数 page,封装服务器返回的这一页数据,以及所有的分页属性;
package cn.tedu.esspringboot.es;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.Criteria;
import org.springframework.data.elasticsearch.core.query.CriteriaQuery;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.stream.Collectors;
@Component
public class StudentSearcher {
@Autowired
private ElasticsearchOperations searchOperations;
public List<Student> searchByBirthDate(String birthDate) {
Criteria c = new Criteria("birthDate").is(birthDate);
return criteriaSearch(c);
}
public List<Student> searchByBirthDate(String ge, String le) {
Criteria c = new Criteria("birthDate").between(ge, le);
return criteriaSearch(c);
}
private List<Student> criteriaSearch(Criteria c) {
CriteriaQuery q = new CriteriaQuery(c);
SearchHits<Student> hits = searchOperations.search(q, Student.class);
List<Student> list = hits.stream().map(SearchHit::getContent).collect(Collectors.toList());
return list;
}
}
7.2 修改 StudentService
改造StudentService接口:
package cn.study.es;
import cn.study.entity.Student;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
/**
* 我们这里基于Spring Data API 的Repository数据访问规范进行业务测试
* 这种规范不需要我们自己完成相关代码,只需要定义抽象类,抽象方法就可以访问数据库的数据
*
* 接口中已经定义了基础的增删改查方法
* 继承的接口中需要传入俩个参数(访问学生数据,ID是Long类型)
*/
public interface StudentRepository extends ElasticsearchRepository<Student,Long> {
//使用name字段搜索关键词
List<Student> findByName(String key);
//使用name字段或者birthdate字段中搜索关键词
//List<Student> findByNameOrBirthDate(String name ,String birthdate);
//改造findByNameOrBirthDate方法
//List<Student> findByNameOrBirthDate(String name , String birthdate, Pageable pageable);
//也可以改造为使用Page可选参数的方法
Page<Student> findByNameOrBirthDate(String name , String birthdate, Pageable pageable);
}
7.3 在测试类中添加测试方法
package cn.study;
import cn.study.entity.Student;
import cn.study.es.StudentRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import java.util.List;
/**
* Repository 构建查询案例
* */
@SpringBootTest
public class Test2 {
@Autowired
private StudentRepository studentRepository;
@Test
public void test1(){
//可以使用单独的关键字进行搜索
List<Student> list1 = studentRepository.findByName("卡");
for (Student s1: list1) {
System.out.println(s1);
}
System.out.println("------------------------");
//但是对于日期是不分词的,无法通过分词进行搜索
// List<Student> list2 = studentRepository.findByNameOrBirthDate("呱", "2023-10-18");
// for (Student s2: list2) {
// System.out.println(s2);
// }
//改造findByNameOrBirthDate方法
//使用pageable的实现类PageRequest创建pageable对象,第1页,每页3条数据;
Pageable pageable = PageRequest.of(0,3);
Page<Student> list2 = studentRepository.findByNameOrBirthDate("呱", "2023-10-18", pageable );
for (Student s2: list2) {
System.out.println(s2);
}
}
}
8.查询结果的高亮显示
8.1 接口方法
我们在接口中创建新的方法findByNameNot来测试查询结果的高亮显示:
//搜索不包含输入字段的关键词
@Highlight(
//设置parameters参数,通过@HighlightParameters设置前置preTags标签和postTags后置标签
parameters = @HighlightParameters(
preTags = "<em>",
postTags = "</em>"),
//设置fields高亮字段
fields = {@HighlightField(name = "name")}
)
List<SearchHit<Student>> findByNameNot(String key);
查询结果的高亮显示通过 @Highlight注解进行设置,其包含俩个参数:
parameters:需要通过@HighlightParameters注解作为值传入设置parameters高亮参数,@HighlightParameters注解还需要设置标签;- ·preTags·参数:设置前置标签;
postTags参数:设置后置标签
- fields:通过
@HighlightField注解作为值传入设置fields参数设置具体哪些字段高亮,@HighlightField注解还需要给定name参数的值name参数:具体哪些字段高亮,@HighlightField注解中的参数为一个数组,通过数组的形式可以给定多个具体字段;
需要注意的是,此前我们创建的findByNameOrBirthDate不能使用高亮注解,使用高亮注解后,发送消息会同时将高亮注解中设置的相关参数也一起返回给客户端,Page类型与List类型均不可包含此些数据;
我们需要使用springboot封装的SearchHit类型将其与List,Student组成嵌套关系的返回类型,获取高亮结果;SearchHit中封装了高亮类型 的结果,我们Student对象中只包含原始学生数据,所以需要SearchHit来封装高亮字段的相关内容;
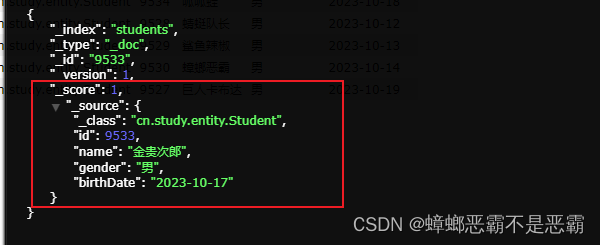
此时SearchHit里会包含高亮属性:name = xxx<em>卡</em>;
8.2 测试类方法
//查询结果高亮显示
@Test
public void test2(){
List<SearchHit<Student>> list1 = studentRepository.findByNameNot("不包含此字段");
List<Student> stuList = new ArrayList<>();
for (SearchHit<Student> sh: list1) {
//取出学生对象
Student stu = sh.getContent();
//取出高亮对象中的name值
List<String> name = sh.getHighlightField("name");
//将高亮对象中的name值拼接好
String hiName = pinjie(name);
//将高亮name值放到学生对象中
stu.setName(hiName);
stuList.add(stu);
}
for (Student s : stuList) {
System.out.println(s);
}
}
private String pinjie(List<String> name){
//name=["xxx","<em>卡</em>,"xxx","<em>卡</em>"]
StringBuilder sbu = new StringBuilder();
for (String sn : name) {
sbu.append(sn);
}
return sbu.toString();
}
9.使用 Criteria 构建查询
Spring Data Elasticsearch 中,除了ElasticsearchRepository外,还提供了CriteriaAPI ;可以使用 SearchOperations 工具执行一些更复杂的查询,这些查询操作接收一个 Query 对象封装的查询条件,然后使用CriteriaQuery封装Criteria对象,分页参数等,最后使用ElasticsearchOperations执行Query 对象;
区别于ElasticsearchRepository严格的方法命名规范,Criteria对方法命名没有任何要求;
Spring Data Elasticsearch 中的 Query 有三种:
- CriteriaQuery
- StringQuery
- NativeSearchQuery
多数情况下,CriteriaQuery 都可以满足我们的查询求。下面来看两个 Criteria 查询示例:
9.1 StudentSearcher
package cn.study.es;
import cn.study.entity.Student;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.Criteria;
import org.springframework.data.elasticsearch.core.query.CriteriaQuery;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
@Component
public class StudentSearche {
//用来执行查询的工具对象
@Autowired
private ElasticsearchOperations elasticsearchOperations;
//按照姓名搜索
public List<Student> findByName(String name){
//创建Criteria对象
Criteria c = new Criteria("name");
//在name字段搜索指定的关键词
c.is(name);
return exec(c,null);
}
//按照日期范围搜索,并添加分页
public List<Student> findByBirthDate(String from, String to, Pageable pageable){
//创建Criteria对象
Criteria c = new Criteria("birthDate");
//在name字段搜索指定的关键词
c.between(from,to);
return exec(c,pageable);
}
private List<Student> exec(Criteria c, Pageable pageable) {
//使用CriteriaQuery封装Criteria对象
CriteriaQuery q = new CriteriaQuery(c);
if(pageable != null){
q.setPageable(pageable);
}
//使用elasticsearchOperations对象进行搜索,并把搜索结果封装成student对象(默认返回是一个json串)
SearchHits<Student> search = elasticsearchOperations.search(q, Student.class);
List<Student> list = new ArrayList<>();
for (SearchHit<Student> sh : search) {
list.add(sh.getContent());
}
return list;
}
}
9.2 在测试类中测试
package cn.study;
import cn.study.entity.Student;
import cn.study.es.StudentSearche;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
public class Test3 {
@Autowired
private StudentSearche studentSearche;
@Test
public void test1(){
List<Student> list = studentSearche.findByName("呱");
System.out.println(list);
}
@Test
public void test2(){
PageRequest p = PageRequest.of(0, 2);
List<Student> list = studentSearche.findByBirthDate("2023-10-15","2023-10-19",p);
System.out.println(list);
}
}











![[Machine Learning][Part 6]Cost Function代价函数和梯度正则化](https://img-blog.csdnimg.cn/a7a14b84cdf746c380d7ed4ced762320.png)