AI视野·今日CS.Robotics 机器人学论文速览
Mon, 16 Oct 2023
Totally 27 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚***AcTExplore, 对于未知物体的主动触觉感知。基于强化学习自动探索物体的表面形貌,增量式重建。(from 马里兰大学 )
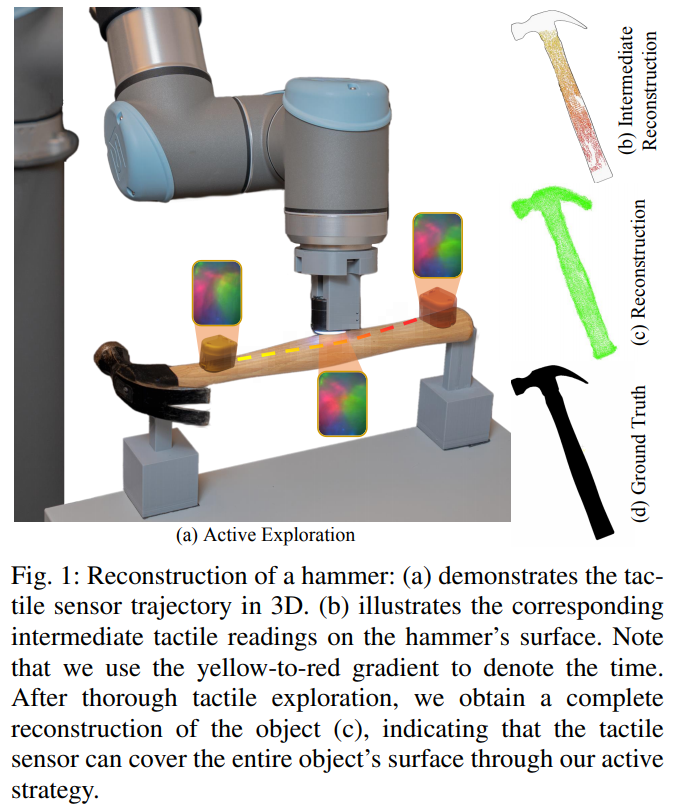
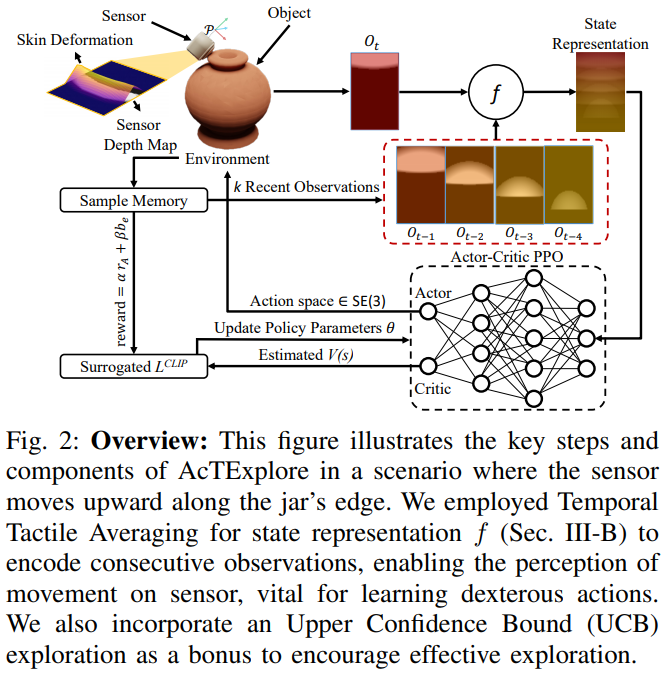
website:http://prg.cs.umd.edu/AcTExplore
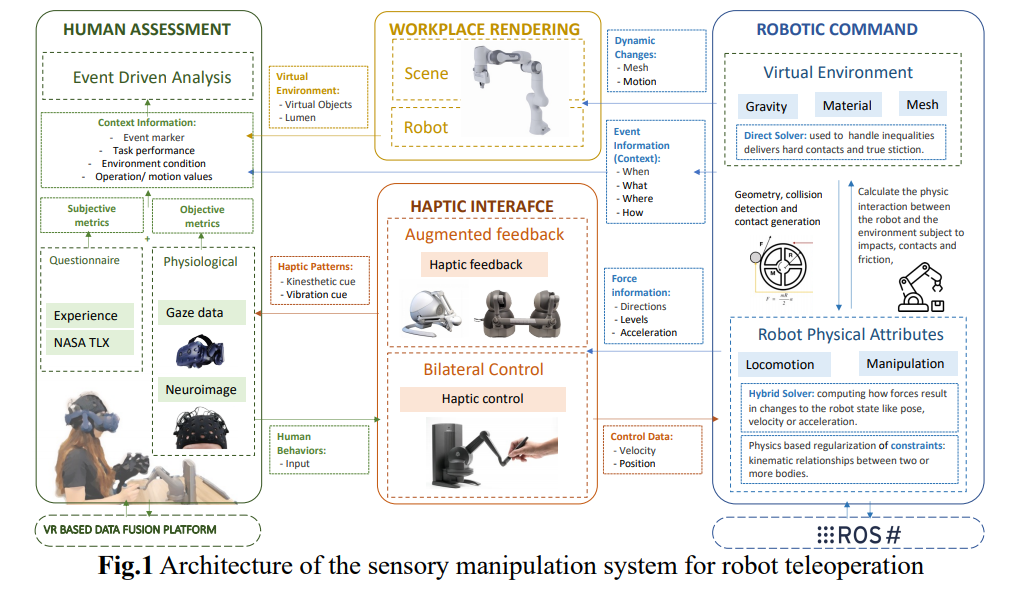
📚机器人遥操作感知设计综述, (from 弗罗里达大学)

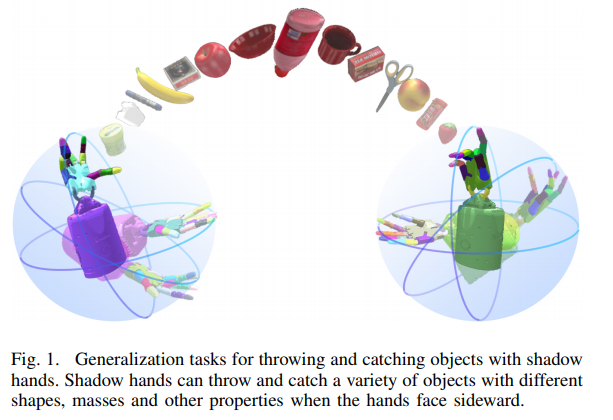
📚DexCatch,通过学习让灵巧手抓取任意物体。 (from 清华)
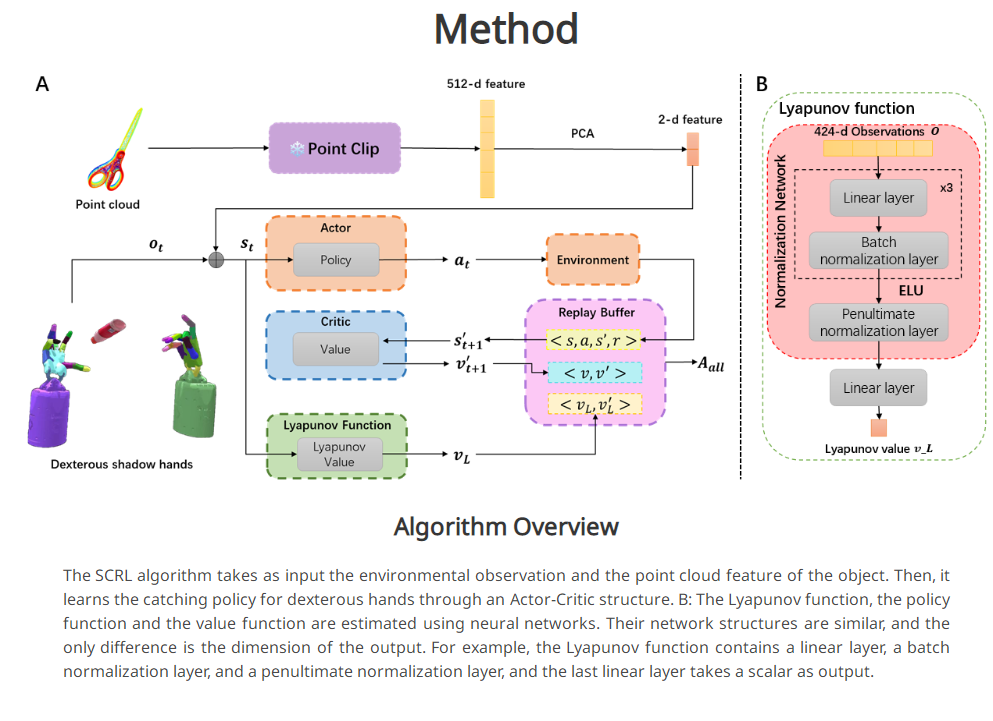
website:https://dexcatch.github.io/
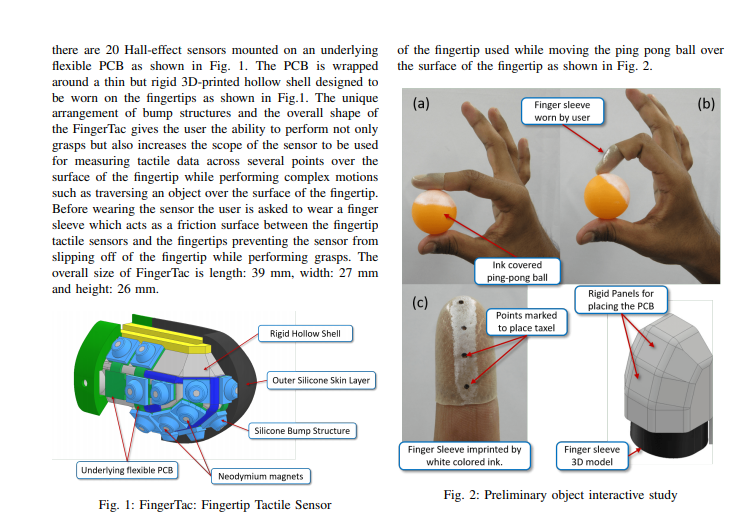
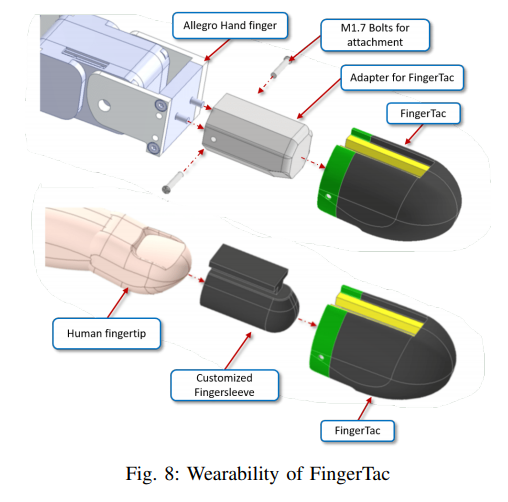
📚FingerTac, 可穿戴的指尖触觉传感器。(from 早稻田)
Daily Robotics Papers
| An Unbiased Look at Datasets for Visuo-Motor Pre-Training Authors Sudeep Dasari, Mohan Kumar Srirama, Unnat Jain, Abhinav Gupta 视觉表示学习为机器人技术带来了巨大的希望,但由于机器人数据集的稀缺性和同质性而受到严重阻碍。最近的工作通过预训练大规模但域外数据的视觉表示来解决这个问题,例如以自我为中心的交互视频,然后将它们转移到目标机器人任务。虽然该领域主要致力于开发更好的预训练算法,但我们发现数据集的选择对于该范式的成功同样重要。毕竟,表示只能学习预训练数据集中存在的结构或先验。为此,我们将重点转向算法,而是对机器人预训练进行以数据集为中心的分析。我们的研究结果对该领域的一些常识提出了质疑。我们观察到,像 ImageNet、Kinetics 和 100 Days of Hands 这样的传统视觉数据集对于视觉运动表征学习而言是极具竞争力的选择,而且预训练数据集的图像分布比其大小更重要。 |
| FingerTac -- An Interchangeable and Wearable Tactile Sensor for the Fingertips of Human and Robot Hands Authors Prathamesh Sathe, Alexander Schmitz, Satoshi Funabashi, Tito Pradhono Tomo, Sophon Somlor, Sugano Shigeki 从人类到机器人的技能转移具有挑战性。目前,许多研究人员专注于仅捕获人类的位置或关节角度数据来训练机器人。尽管这种方法在抓取应用中取得了令人印象深刻的结果,但重建物体处理运动或从人手到机器人手的精细操作的探索却很少。人类使用触觉反馈来调整他们对各种物体的运动,但捕获和再现所施加的力是一个开放的研究问题。在本文中,我们介绍了一种可穿戴指尖触觉传感器,它捕获指尖上分布的 3 轴力矢量。指尖触觉传感器可以在人手和机器人手之间互换,这意味着它也可以组装到机器人手上,例如 Allegro 手。本文介绍了传感器的结构以及用于设计、制造和校准传感器的方法和方法。 |
| AMSwarmX: Safe Swarm Coordination in CompleX Environments via Implicit Non-Convex Decomposition of the Obstacle-Free Space Authors Vivek K. Adajania, Siqi Zhou, Arun Kumar Singh, Angela P. Schoellig 复杂环境下的四旋翼运动规划利用安全飞行走廊SFC的概念来促进静态避障。通常,SFC 是通过将环境的自由空间凸分解为长方体、凸多面体或球体来构建的。然而,在处理四旋翼飞行器群时,此类 SFC 可能过于保守,从而大大限制了四旋翼飞行器协调的可用自由空间。本文提出了一种基于交替最小化的方法,不需要构建保守的自由空间近似。相反,静态和动态碰撞约束都以统一的方式处理。动态碰撞是根据四旋翼飞行器的共享位置轨迹来处理的。静态避障与来自 Octomap 的距离查询相结合,提供自由空间的隐式非凸分解。因此,我们的方法可以扩展到任意复杂的环境。通过模拟中的广泛比较,我们证明与基于 SFC 的方法相比,成功率提高了 60 倍,任务完成时间平均缩短了 1.8 倍,每个代理计算时间平均缩短了 23 倍。我们还在障碍物丰富的环境中使用由多达 12 个四旋翼飞行器组成的 Crazyflie 四旋翼飞行器群对我们的方法进行了实验验证。 |
| Towards Robust UAV Tracking in GNSS-Denied Environments: A Multi-LiDAR Multi-UAV Dataset Authors Iacopo Catalano, Xianjia Yu, Jorge Pena Queralta 随着无人机在各行业中的日益普及,无人机在充满挑战的环境中,特别是 GNSS 无法识别的区域中的导航和跟踪已成为至关重要的问题。为了满足这一需求,我们提出了一种专为无人机跟踪设计的新型多 LiDAR 数据集。我们的数据集包括来自旋转 LiDAR、两个具有不同视场 FoV 和扫描模式的固态 LiDAR 以及 RGB D 相机的数据。 |
| ImageManip: Image-based Robotic Manipulation with Affordance-guided Next View Selection Authors Xiaoqi Li, Yanzi Wang, Yan Shen, Ponomarenko Iaroslav, Haoran Lu, Qianxu Wang, Boshi An, Jiaming Liu, Hao Dong 在未来的家庭助理机器人领域,3D 关节式物体操纵对于机器人与环境的交互至关重要。许多现有研究利用 3D 点云作为操纵策略的主要输入。然而,由于数据稀疏以及与获取点云数据相关的巨大成本,这种方法遇到了挑战,这可能限制其实用性。相比之下,RGB 图像使用经济高效的设备提供高分辨率观测,但缺乏空间 3D 几何信息。为了克服这些限制,我们提出了一种新颖的基于图像的机器人操作框架。该框架旨在捕获目标对象的多个视角并推断深度信息以补充其几何形状。最初,该系统使用手上的 RGB 摄像头来捕获目标物体的整体视图。它预测初始深度图和粗略可供性图。可供性图指示对象上的可操作区域,并用作选择后续视点的约束。基于全局视觉先验,我们自适应地识别最佳的下一个视点,以详细观察潜在的操纵成功区域。我们利用几何一致性来融合视图,从而为机器人操作决策提供精细的深度图和更精确的可供性图。通过与采用点云或 RGB 图像作为输入的先前作品进行比较,我们证明了我们方法的有效性和实用性。 |
| DATT: Deep Adaptive Trajectory Tracking for Quadrotor Control Authors Kevin Huang, Rwik Rana, Alexander Spitzer, Guanya Shi, Byron Boots 由于未知的非线性动力学、轨迹不可行性和驱动限制,四旋翼飞行器的精确任意轨迹跟踪具有挑战性。为了应对这些挑战,我们提出了深度自适应轨迹跟踪 DATT,这是一种基于学习的方法,可以在现实世界存在较大干扰的情况下精确跟踪任意的、可能不可行的轨迹。 DATT 建立在一种新颖的前馈反馈自适应控制结构之上,该结构使用强化学习进行模拟训练。当部署在真实硬件上时,DATT 会通过在闭环中使用 L1 自适应控制的干扰估计器进行增强,无需任何微调。对于不稳定风场中可行的平滑和不可行的轨迹,包括基线完全失效的挑战性场景,DATT 显着优于竞争性自适应非线性和模型预测控制器。 |
| Interactive Navigation in Environments with Traversable Obstacles Using Large Language and Vision-Language Models Authors Zhen Zhang, Anran Lin, Chun Wai Wong, Xiangyu Chu, Qi Dou, K. W. Samuel Au 本文提出了一种使用大语言和视觉语言模型的交互式导航框架,允许机器人在有可穿越障碍的环境中导航。我们利用大型语言模型 GPT 3.5 和开放集视觉语言模型 Grounding DINO 来创建动作感知成本图,无需微调即可执行有效的路径规划。通过大型模型,我们可以实现从文本指令(例如“你能穿过窗帘给我送药吗”)到边界框(例如具有动作感知属性的窗帘)的端到端系统。它们可用于将激光雷达点云分割为可遍历和不可遍历的两部分,然后构建动作感知成本图以生成可行路径。预训练的大型模型具有很强的泛化能力,并且不需要额外的注释数据进行训练,可以在交互式导航任务中快速部署。我们选择使用窗帘、草地等多个可遍历物体,通过指示机器人遍历它们来进行验证。此外,还测试了医疗场景中的穿越窗帘。 |
| Open X-Embodiment: Robotic Learning Datasets and RT-X Models Authors Abhishek Padalkar, Acorn Pooley, Ajinkya Jain, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anikait Singh, Anthony Brohan, Antonin Raffin, Ayzaan Wahid, Ben Burgess Limerick, Beomjoon Kim, Bernhard Sch lkopf, Brian Ichter, Cewu Lu, Charles Xu, Chelsea Finn, Chenfeng Xu, Cheng Chi, Chenguang Huang, Christine Chan, Chuer Pan, Chuyuan Fu, Coline Devin, Danny Driess, Deepak Pathak, Dhruv Shah, Dieter B chler, Dmitry Kalashnikov, Dorsa Sadigh, Edward Johns, Federico Ceola, Fei Xia, Freek Stulp, Gaoyue Zhou, Gaurav S. Sukhatme, Gautam Salhotra, Ge Yan, Giulio Schiavi, Gregory Kahn, Hao Su, Hao Shu Fang, Haochen Shi, Heni Ben Amor, Henrik I Christensen, Hiroki Furuta, Homer Walke, Hongjie Fang, Igor Mordatch, Ilija Radosavovic, Isabel Leal, Jacky Liang, Jad Abou Chakra, Jaehyung Kim, Jan Peters, Jan Schneider, Jasmine Hsu, Jeannette Bohg, Jeffrey Bingham, Jiajun Wu, Jialin Wu, Jianlan Luo, Jiayuan Gu, Jie Tan, Jihoon Oh, Jitendra Malik, Jonathan Tompson, Jonathan Yang, Joseph J. Lim, Jo o Silv rio, Junhyek Han, Kanishka Rao, Karl Pertsch, Karol Hausman, Keegan Go, Keerthana Gopalakrishnan, Ken Goldberg, Kendra Byrne, Kenneth Oslund, Kento Kawaharazuka, Kevin Zhang, Krishan Rana, Krishnan Srinivasan, Lawrence Yunliang Chen, Lerrel Pinto, Liam Tan, Lionel Ott, Lisa Lee, Masayoshi Tomizuka, Maximilian Du, Michael Ahn, Mingtong Zhang, Mingyu Ding, Mohan Kumar Srirama, Mohit Sharma, Moo Jin Kim, Naoaki Kanazawa, Nicklas Hansen , Nicolas Heess, Nikhil J Joshi, Niko Suenderhauf, Norman Di Palo, Nur Muhammad Mahi Shafiullah, Oier Mees, Oliver Kroemer, Pannag R Sanketi, Paul Wohlhart, Peng Xu, Pierre Sermanet, Priya Sundaresan, Quan Vuong, Rafael Rafailov, Ran Tian, Ria Doshi, Roberto Mart n Mart n, Russell Mendonca, Rutav Shah, Ryan Hoque, Ryan Julian, Samuel Bustamante, Sean Kirmani, Sergey Levine, Sherry Moore, Shikhar Bahl, Shivin Dass, Shubham Sonawani, Shuran Song, Sichun Xu, Siddhant Haldar, Simeon Adebola, Simon Guist, Soroush Nasiriany, Stefan Schaal, Stefan Welker, Stephen Tian, Sudeep Dasari, Suneel Belkhale, Takayuki Osa, Tatsuya Harada, Tatsuya Matsushima, Ted Xiao, Tianhe Yu, Tianli Ding, Todor Davchev, Tony Z. Zhao, Travis Armstrong, Trevor Darrell, Vidhi Jain, Vincent Vanhoucke, Wei Zhan, Wenxuan Zhou, Wolfram Burgard, Xi Chen, Xiaolong Wang, Xinghao Zhu, Xuanlin Li, Yao Lu, Yevgen Chebotar, Yifan Zhou, Yifeng Zhu, Ying Xu, Yixuan Wang, Yonatan Bisk, Yoonyoung Cho, Youngwoon Lee, Yuchen Cui, Yueh Hua Wu, Yujin Tang, Yuke Zhu, Yunzhu Li, Yusuke Iwasawa, Yutaka Matsuo, Zhuo Xu, Zichen Jeff Cui et al. 76 additional authors not shown You must enable JavaScript to view entire author list. 在不同数据集上训练的大型高容量模型在有效处理下游应用程序方面取得了显着的成功。在从 NLP 到计算机视觉的领域,这导致了预训练模型的整合,通用预训练主干网成为许多应用程序的起点。这种整合可以在机器人技术中发生吗传统上,机器人学习方法为每个应用程序、每个机器人甚至每个环境训练一个单独的模型。我们是否可以训练通用的 X 机器人策略,使其能够有效地适应新的机器人、任务和环境。在本文中,我们提供标准化数据格式和模型的数据集,以便能够在机器人操作的背景下探索这种可能性,同时实验结果提供了有效的 X 机器人策略的示例。我们通过 21 个机构之间的合作收集了 22 个不同机器人的数据集,展示了 527 项技能和 160266 项任务。 |
| A Framework for Few-Shot Policy Transfer through Observation Mapping and Behavior Cloning Authors Yash Shukla, Bharat Kesari, Shivam Goel, Robert Wright, Jivko Sinapov 尽管机器人应用的强化学习最近取得了进展,但由于昂贵的交互成本,许多任务仍然难以解决。迁移学习通过迁移在源域中学到的知识来帮助减少目标域中的训练时间。 Sim2Real 迁移有助于将知识从模拟机器人域迁移到物理目标域。知识转移减少了在物理世界中训练任务所需的时间,而物理世界中的交互成本很高。然而,大多数现有方法都假设两个域的任务结构和物理属性完全对应。这项工作提出了一个通过观察映射和行为克隆在两个域之间进行少量策略传输的框架。我们使用生成对抗网络 GAN 以及循环一致性损失来映射源域和目标域之间的观察结果,然后使用这种学习到的映射将成功的源任务行为策略克隆到目标域。 |
| Urban Drone Navigation: Autoencoder Learning Fusion for Aerodynamics Authors Jiaohao Wu, Yang Ye, Jing Du 由于在有建筑物和风等障碍物的动态环境中导航面临挑战,无人机对于城市紧急搜救至关重要。本文提出了一种将多目标强化学习 MORL 与卷积自动编码器相结合的方法,以改进城市 SAR 中的无人机导航。该方法使用 MORL 来实现多个目标,并使用自动编码器进行具有成本效益的风模拟。通过利用城市布局的图像数据,无人机可以自主做出导航决策、优化路径并抵消风的影响,而无需传统传感器。 |
| DexCatch: Learning to Catch Arbitrary Objects with Dexterous Hands Authors Fengbo Lan, Shengjie Wang, Yunzhe Zhang, Haotian Xu, Oluwatosin Oseni, Yang Gao, Tao Zhang 实现像人类一样的灵巧操作仍然是机器人研究的一个重要领域。目前的研究重点是提高拾放任务的成功率。与拾取和放置相比,投掷捕捉行为有可能提高拾取速度,而无需将物体运送到目的地。然而,由于大量的动态接触,动态灵巧操纵对稳定控制提出了重大挑战。在本文中,我们提出了一种稳定性约束强化学习 SCRL 算法来学习用灵巧的双手捕捉不同的物体。 SCRL 算法大幅优于基线,并且学习的策略在不可见的物体上显示出强大的零镜头传输性能。值得注意的是,即使由于缺乏手掌的支撑,侧向手中的物体极其不稳定,我们的方法仍然可以在最具挑战性的任务中取得很高的成功。 |
| Multi-Robot Geometric Task-and-Motion Planning for Collaborative Manipulation Tasks Authors Hejia Zhang, Shao Hung Chan, Jie Zhong, Jiaoyang Li, Peter Kolapo, Sven Koenig, Zach Agioutantis, Steven Schafrik, Stefanos Nikolaidis 我们解决同步、单调设置中的多机器人几何任务和运动规划 MR GTAMP 问题。 MR GTAMP 问题的目标是在存在其他可移动物体的情况下使用多个机器人将物体移动到目标区域。我们专注于协作操纵任务,其中机器人必须采用智能协作策略才能成功且有效,即决定哪个机器人应该将哪些物体移动到哪个位置,并执行协作动作,例如切换。为了赋予机器人这些协作能力,我们建议首先通过调用运动规划算法来收集每个机器人的遮挡和可达性信息。然后,我们提出一种方法,使用收集到的信息构建图形结构,该结构捕获不同对象操作的优先级,并支持混合整数程序的实现,以指导搜索高效的协作任务和运动计划。协作任务和运动计划的搜索过程基于蒙特卡罗树搜索 MCTS 探索策略,以实现探索利用平衡。我们在两个具有挑战性的 MR GTAMP 领域评估了我们的框架,并表明它在规划时间、最终计划长度和移动对象数量方面优于两个最先进的基线。我们还表明,我们的框架可以应用于地下采矿作业,其中机械臂需要与自主顶板锚杆机协调。 |
| Sensory Manipulation as a Countermeasure to Robot Teleoperation Delays: System and Evidence Authors Jing Du, William Vann, Tianyu Zhou, Yang Ye, Qi Zhu 在机器人领域,用于远程或危险环境的机器人远程操作变得越来越重要。一个主要挑战是命令和行动之间的滞后,这会对操作员的意识、表现和精神紧张产生负面影响。即使采用先进的技术,减少这些延迟,尤其是在长途操作中,仍然具有挑战性。当前的解决方案主要集中于基于机器的调整。然而,利用人类感知来改善远程操作体验还存在差距。本文提出了一种独特的感觉操纵方法来帮助人类适应这种延迟。根据运动学习原理,它表明改变感觉刺激可以减少对这些延迟的感知。该方法没有引入新技能,而是使用现有的运动协调知识。目的是最大限度地减少对大量培训或复杂自动化的需求。一项涉及 41 名参与者的研究探讨了触觉提示改变对延迟远程操作的影响。这些线索来自先进的物理引擎和机器人传感器。结果强调了诸如减少任务时间和改善视觉延迟感知等好处。实时触觉反馈显着有助于减轻精神压力并增强信心。 |
| 3D Self-Localization of Drones using a Single Millimeter-Wave Anchor Authors Maisy Lam, Laura Dodds, Aline Eid, Jimmy Hester, Fadel Adib 我们介绍 MiFly 的设计、实现和评估,MiFly 是一种用于自主无人机的自定位系统,可在室内和室外环境中工作,包括低能见度、黑暗和 GPS 拒绝设置。 MiFly 通过利用其附近的单个毫米波 mmWave 锚点来执行 6DoF 自定位,即使该锚点在视觉上被遮挡也是如此。毫米波信号用于雷达和 5G 系统,可以在黑暗中和遮挡情况下运行。 MiFly 推出了新的毫米波锚点设计,并在无人机上安装了轻型高分辨率毫米波雷达。通过联合设计定位算法和新型低功耗毫米波锚定硬件(包括其偏振和调制),无人机能够进行高速 3D 定位。此外,通过智能融合毫米波雷达和 IMU 的位置估计,它可以准确、稳健地跟踪其 6DoF 轨迹。我们在 DJI 无人机上实现并评估了 MiFly。 |
| AcTExplore: Active Tactile Exploration on Unknown Objects Authors Amir Hossein Shahidzadeh, Seong Jong Yoo, Pavan Mantripragada, Chahat Deep Singh, Cornelia Ferm ller, Yiannis Aloimonos 触觉探索在理解抓取和操纵等基本机器人任务的对象结构方面发挥着至关重要的作用。然而,使用触觉传感器有效地探索此类物体具有挑战性,这主要是由于大规模的未知环境和这些传感器的传感覆盖范围有限。为此,我们提出了 AcTExplore,一种由强化学习驱动的主动触觉探索方法,用于大规模物体重建,可在有限的步骤中自动探索物体表面。通过充分的探索,我们的算法逐渐收集触觉数据并重建对象的 3D 形状,这可以作为更高级别下游任务的表示。 |
| Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research Authors Cole Gulino, Justin Fu, Wenjie Luo, George Tucker, Eli Bronstein, Yiren Lu, Jean Harb, Xinlei Pan, Yan Wang, Xiangyu Chen, John D. Co Reyes, Rishabh Agarwal, Rebecca Roelofs, Yao Lu, Nico Montali, Paul Mougin, Zoey Yang, Brandyn White, Aleksandra Faust, Rowan McAllister, Dragomir Anguelov, Benjamin Sapp 仿真是以安全且具有成本效益的方式开发自动驾驶车辆规划软件并对其进行基准测试的重要工具。然而,真实的模拟需要对细致入微且复杂的多主体交互行为进行精确建模。为了应对这些挑战,我们推出了 Waymax,这是一种新的数据驱动模拟器,用于多代理场景中的自动驾驶,专为大规模模拟和测试而设计。 Waymax 使用公开发布的现实世界驾驶数据(例如 Waymo 开放运动数据集)来初始化或回放一组不同的多代理模拟场景。它完全运行在 TPU GPU 等硬件加速器上,并支持图形模拟训练,使其适合现代大规模分布式机器学习工作流程。为了支持在线培训和评估,Waymax 包含多个学习和硬编码的行为模型,允许在模拟中进行真实的交互。 |
| Multi-Robot IMU Preintegration in the Presence of Bias and Communication Constraints Authors Mohammed Ayman Shalaby, Charles Champagne Cossette, Jerome Le Ny, James Richard Forbes 本文档是标题为“使用无源 UWB 收发器进行多机器人相对位姿估计和 IMU 预积分”的论文的补充,该论文可在 1 获取。 |
| Pay Attention to How You Drive: Safe and Adaptive Model-Based Reinforcement Learning for Off-Road Driving Authors Sean J. Wang, Honghao Zhu, Aaron M. Johnson 自动越野驾驶具有挑战性,因为机器人采取的危险行为可能会导致灾难性的损害。因此,在仿真中开发控制器通常是可取的,因为它提供了更安全、更经济的替代方案。然而,由于非结构化环境中复杂的机器人动力学和地形相互作用,准确地建模机器人动力学是很困难的。域随机化通过随机化模拟动态参数来解决这个问题,但是这种方法牺牲了鲁棒性的性能,导致策略对于任何目标动态来说都是次优的。我们引入了一种基于新模型的强化学习方法,旨在平衡鲁棒性和适应性。我们的方法在各种模拟动态下训练系统识别变压器 SIT 和自适应动态模型 ADM。 SIT 使用注意力机制将目标系统的状态转换观察结果提取到上下文向量中,从而为其目标动态提供抽象。以此为条件,ADM 对系统动态进行概率建模。在网上,我们使用风险感知模型预测路径积分控制器 MPPI 在机器人当前对动力学的理解下安全地控制机器人。我们在模拟以及多个现实世界环境中证明,这种方法可以在初始化时实现更安全的行为,并且随着对目标系统动力学的理解随着更多观察而提高,变得不那么保守,即更快。 |
| Safe Deep Policy Adaptation Authors Wenli Xiao, Tairan He, John Dolan, Guanya Shi 自主和人工智能的一个关键目标是使自主机器人能够快速适应动态和不确定的环境。经典的自适应控制和安全控制提供稳定性和安全性保证,但仅限于特定的系统类别。相比之下,基于强化学习 RL 的策略适应提供了多功能性和通用性,但也带来了安全性和鲁棒性挑战。我们提出了 SafeDPA,这是一种新颖的强化学习和控制框架,可以同时解决策略适应和安全强化学习的问题。 SafeDPA 在模拟中联合学习自适应策略和动态模型,预测环境配置,并利用少量真实世界数据微调动态模型。引入了基于 RL 策略之上的控制屏障功能 CBF 的安全过滤器,以确保现实世界部署期间的安全。我们提供了 SafeDPA 的理论安全保证,并展示了 SafeDPA 针对学习错误和额外扰动的鲁棒性。对 1 个经典控制问题倒立摆、2 个模拟基准 Safety Gym 和 3 个现实世界敏捷机器人平台 RC Car 的综合实验表明,SafeDPA 在安全性和任务性能方面均优于最先进的基准。 |
| A Survey of Multi-Robot Motion Planning Authors Hoang Dung Bui 多机器人运动规划MRMP是一个活跃的研究领域,多年来受到了人们的关注。 MRMP 在提高多机器人系统的效率和可靠性方面发挥着重要作用,在从交付机器人到协作装配线的广泛应用中。本次调查概述了 MRMP 分类法、最先进的算法以及为多机器人系统开发的方法。本研究还讨论了每种算法的优点和局限性及其在各种场景中的应用。 |
| A Method for Multi-Robot Asynchronous Trajectory Execution in MoveIt2 Authors Pascal Stoop, Tharaka Ratnayake, Giovanni Toffetti 这项工作提出了 MoveIt2 规划库的扩展,支持多机器人多臂机器人设置的异步执行。 |
| Deep Reinforcement Learning for Autonomous Vehicle Intersection Navigation Authors Badr Ben Elallid, Hamza El Alaoui, Nabil Benamar 在本文中,我们探讨了自动驾驶汽车在密集交通场景中导航复杂 T 字路口所面临的挑战。强化学习算法已成为解决这些挑战的一种有前途的方法,它使自动驾驶汽车能够实时做出安全有效的决策。在这里,我们使用基于双延迟深度确定性策略梯度 TD3 强化学习算法的低成本单代理方法解决了高效、安全地导航 T 路口的问题。我们证明,我们基于 TD3 的方法在 CARLA 仿真平台上进行训练和测试时,在各种交通密度下表现出稳定的收敛性和改进的安全性能。我们的结果表明,所提出的方法使自动驾驶汽车能够有效地导航 T 形交叉路口,在行驶延误、碰撞最小化和总体成本方面优于以前的方法。 |
| METRA: Scalable Unsupervised RL with Metric-Aware Abstraction Authors Seohong Park, Oleh Rybkin, Sergey Levine 无监督预训练策略已被证明在自然语言处理和计算机视觉方面非常有效。同样,无监督强化学习 RL 有望发现各种潜在有用的行为,从而加速各种下游任务的学习。以前的无监督强化学习方法主要侧重于纯粹的探索和互信息技能学习。然而,尽管之前有过尝试,使无监督强化学习真正可扩展仍然是一个重大的开放挑战,纯粹的探索方法可能会在具有大状态空间的复杂环境中陷入困境,其中覆盖所有可能的转换是不可行的,并且互信息技能学习方法可能完全无法探索环境缺乏激励。为了使无监督 RL 可扩展到复杂的高维环境,我们提出了一种新颖的无监督 RL 目标,我们将其称为 Metric Aware Abstraction METRA 。我们的主要思想是,不直接覆盖整个状态空间,而是仅覆盖一个紧凑的潜在空间 Z,该潜在空间 Z 通过时间距离在度量上连接到状态空间 S。通过学习在潜在空间中向各个方向移动,METRA 获得了一组易于处理的多样化行为,这些行为大致覆盖了状态空间,可扩展到高维环境。通过在五个运动和操纵环境中的实验,我们证明 METRA 即使在复杂的基于像素的环境中也可以发现各种有用的行为,这是第一个在基于像素的四足动物和人形动物中发现多种运动行为的无监督强化学习方法。 |
| Leveraging Optimal Transport for Enhanced Offline Reinforcement Learning in Surgical Robotic Environments Authors Maryam Zare, Parham M. Kebria, Abbas Khosravi 大多数强化学习 RL 方法传统上都是在主动学习环境中进行研究,其中代理直接与其环境交互、观察行动结果并通过试错来学习。然而,允许经过部分训练的智能体与真实的物理系统交互带来了巨大的挑战,包括高成本、安全风险以及持续监督的需要。离线强化学习通过利用现有数据集并减少对资源密集型实时交互的需求来解决这些成本和安全问题。然而,一个重大的挑战在于需要对这些数据集进行仔细的奖励注释。在本文中,我们介绍了最佳运输奖励 OTR 标签,这是一种创新算法,旨在使用少量高质量专家演示将奖励分配给离线轨迹。 OTR 的核心原理涉及采用最佳传输 OT 来计算数据集中未标记轨迹与专家演示之间的最佳对齐。这种对齐产生了一个相似性度量,可以有效地解释为奖励信号。然后,离线强化学习算法可以利用这些奖励信号来学习策略。这种方法避免了手工奖励的需要,释放了利用大量数据集进行政策学习的潜力。利用专为手术机器人学习量身定制的 SurRoL 模拟平台,我们生成数据集并利用它们来使用 OTR 算法训练策略。 |
| A Flexible and Efficient Temporal Logic Tool for Python: PyTeLo Authors Gustavo A. Cardona, Kevin Leahy, Makai Mann, Cristian Ioan Vasile 时态逻辑是指定系统复杂行为的重要工具。它可用于定义验证和监控的属性以及综合工具的目标,允许用户指定丰富的任务和任务。一些最流行的时序逻辑包括度量时序逻辑 MTL 、信号时序逻辑 STL 和加权 STL wSTL ,它们也允许定义时序约束。在这项工作中,我们介绍了 PyTeLo,这是一种基于 Python 的模块化多功能软件,有助于使用时态逻辑语言,特别是 MTL、STL 和 wSTL。应用 PyTeLo 仅需要时态逻辑规范的字符串表示,以及感兴趣的系统的动态(可选)。接下来,PyTeLo 使用 ANTLR 生成的解析器读取规范,并生成捕获公式结构的抽象语法树 AST。对于综合,AST 用于将规范递归编码为混合整数线性程序 MILP,并使用商业求解器(例如 Gurobi)进行求解。 |
| ELDEN: Exploration via Local Dependencies Authors Jiaheng Hu, Zizhao Wang, Peter Stone, Roberto Martin Martin 具有大状态空间和稀疏奖励的任务对强化学习提出了长期的挑战。在这些任务中,代理需要有效地探索状态空间,直到找到奖励。为了解决这个问题,社区提出用内在奖励来增强奖励函数,这是一种鼓励智能体访问有趣状态的奖励信号。在这项工作中,我们提出了一种为具有因子状态空间和复杂链式依赖关系的环境定义有趣状态的新方法,其中代理的动作可能会改变一个实体的值,而该实体的值可能会影响另一个实体的值。我们的见解是,在这些环境中,值得探索的有趣状态是代理不确定的状态,而不是代理或对象等实体如何相互影响。我们提出 ELDEN,通过本地依赖进行探索,这是一种新颖的内在奖励,鼓励发现实体之间的新交互。 ELDEN 利用一种新颖的方案(学习动力学的偏导数)来准确且计算高效地对实体之间的局部依赖关系进行建模。然后,预测依赖关系的不确定性被用作内在奖励,以鼓励探索新的交互。我们评估了 ELDEN 在具有复杂依赖性的四个不同领域(从 2D 网格世界到 3D 机器人任务)的性能。 |
| Multimodal Large Language Model for Visual Navigation Authors Yao Hung Hubert Tsai, Vansh Dhar, Jialu Li, Bowen Zhang, Jian Zhang 最近使用大型语言模型实现视觉导航的努力主要集中在开发复杂的提示系统。这些系统将指令、观察结果和历史记录合并到大量文本提示中,然后与预先训练的大型语言模型相结合以促进视觉导航。相比之下,我们的方法旨在微调用于视觉导航的大型语言模型,而无需进行大量的提示工程。我们的设计涉及一个简单的文本提示、当前观察结果和一个历史收集器模型,该模型从以前的观察结果中收集信息作为输入。对于输出,我们的设计提供了代理在导航期间可以采取的可能操作的概率分布。我们使用来自 Habitat Matterport 3D 数据集 HM3D 的人体演示和碰撞信号来训练我们的模型。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com