嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
很多小伙伴学习Python的初衷就是为了爬取小说,方便又快捷~
辣么今天咱们来分享6个主流小说平台的爬取教程~
一、流程步骤
流程基本都差不多,只是看网站具体加密反爬,咱们再进行解密。
实现爬虫的第一步?
1、去抓包分析,分析数据在什么地方。
-
打开开发者工具
-
刷新网页
-
找数据 --> 通过关键字搜索
2、获取小说内容
-
目标网址
-
获取网页源代码请求小说链接地址,解析出来
-
请求小说内容数据包链接:
-
获取加密内容 --> ChapterContent
-
进行解密 --> 分析加密规则 是通过什么样方式 什么样代码进行加密
3、获取响应数据
response.text 获取文本数据 字符串
response.json() 获取json数据 完整json数据格式
response.content 获取二进制数据 图片 视频 音频 特定格式文件
二、案例
1、书旗
环境使用:
-
Python 3.8
-
Pycharm
模块使用:
- requests
- execjs
- re
源码展示:
# 导入数据请求模块
import requests
# 导入正则模块
import re
import execjs
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.3'
}
# 请求链接 -> 目录页面链接
html = '网址屏蔽了,不然过不了'
# 发送请求
html_ = requests.get(url=html, headers=headers).text
# 小说名字
name = re.findall('<title>(.*?)-书旗网</title>', html_)[0]
# 提取章节名字 / 章节ID
info = re.findall('data-clog="chapter\$\$chapterid=(\d+)&bid=8826245">\d+\.(.*?)</a>', html_, re.S)
print(name)
# for 循环遍历
for chapter_id, index in info:
title = index.strip()
print(chapter_id, title)
# 请求链接
url = f'https://网址屏蔽了,不然过不了/reader?bid=8826245&cid={chapter_id}'
# 发送请求 <Response [200]> 响应对象
response = requests.get(url=url, headers=headers)
# 获取响应数据
html_data = response.text
# 正则匹配数据
data = re.findall('contUrlSuffix":"\?(.*?)","shelf', html_data)[0].replace('amp;', '')
# 构建小说数据包链接地址
link = 'https://c13.网址屏蔽了,不然过不了.com/pcapi/chapter/contentfree/?' + data
# 发送请求
json_data = requests.get(url=link, headers=headers).json()
# 键值对取值, 提取加密内容
ChapterContent = json_data['ChapterContent']
# 解密内容 --> 通过python调用JS代码, 解密
f = open('书旗.js', encoding='utf-8')
# 读取JS代码
text = f.read()
# 编译JS代码
js_code = execjs.compile(text)
# 调用Js代码函数
result = js_code.call('_decodeCont', ChapterContent).replace('<br/><br/>', '\n').replace('<br/>', '')
# 保存数据
with open(f'{name}.txt', mode='a', encoding='utf-8') as v:
v.write(title)
v.write('\n')
v.write(result)
v.write('\n')
print(json_data)
print(ChapterContent)
print(result)
效果展示:

2、塔读
环境使用:
-
Python 3.8
-
Pycharm
模块使用:
- requests --> pip install requests
源码
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 导入数据请求模块
import requests
# 导入正则表达式模块
import re
# 导入读取JS代码
import execjs
# 模拟浏览器
headers = {
'Host': '网址屏蔽了,以免不过',
'Referer': '网址屏蔽了,以免不过',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
}
# 请求链接
link = '网址屏蔽了,以免不过'
# 发送请求
link_data = requests.get(url=link, headers=headers).text
# 小说名字
name = re.findall('book_name" content="(.*?)">', link_data)[0]
# 章节ID 和 章节名字
info = re.findall('href="/book/\d+/(\d+)/" target="_blank">(.*?)</a>', link_data)[9:]
page = 1
# for 循环遍历
for chapter_id, title in info:
print(chapter_id, title)
# 获取广告 data-limit 参数
j = open('塔读.js', encoding='utf-8')
# 读取JS代码
text = j.read()
# 编译JS代码
js_code = execjs.compile(text)
# 调用js代码函数
data_limit = js_code.call('o', chapter_id)
print(data_limit)
# 请求链接
url = f'网址屏蔽了,以免不过/{page}'
# 发送请求 <Response [200]> 响应对象 表示请求成功
response = requests.get(url=url, headers=headers)
# 获取响应json数据 --> 字典数据类型
json_data = response.json()
# 解析数据 -> 键值对取值 content 获取下来
content = json_data['data']['content']
# 处理小说内容广告 初级版本 --> 后续需要升级
content_1 = re.sub(f'<p data-limit="{data_limit}">.*?</p>', '', content)
# 提取小说内容 -> 1. 正则表达式提取数据 2. css/xpath 提取
result = re.findall('<p data-limit=".*?">(.*?)</p>', content_1)
# 把列表合并成字符串
string = '\n'.join(result)
# 保存数据
with open(f'{name}.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(string)
f.write('\n')
print(string)
page += 1
效果展示

3、飞卢
环境使用:
-
Python 3.8
-
Pycharm
模块使用:
- requests >>> 数据请求模块
parsel >>> 数据解析模块
re 正则表达式
源码展示
# 数据请求模块
import requests
# 数据解析模块
import parsel
# 正则表达式模块
import re
import base64
def get_content(img):
url = "https://aip.网址屏蔽,不然不过审.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": "",
"client_secret": ""
}
access_token = str(requests.post(url, params=params).json().get("access_token"))
content = base64.b64encode(img).decode("utf-8")
url_ = "网址屏蔽,不然不过审" + access_token
data = {
'image': content
}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': 'application/json'
}
response = requests.post(url=url_, headers=headers, data=data)
words = '\n'.join([i['words'] for i in response.json()['words_result']])
return words
# 模拟伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
# 请求链接
link = '网址屏蔽,不然不过审'
# 发送请求
link_response = requests.get(url=link, headers=headers)
# 获取响应文本数据
link_data = link_response.text
# 把html文本数据, 转成可解析对象
link_selector = parsel.Selector(link_data)
# 提取书名
name = link_selector.css('#novelName::text').get()
# 提取链接
href = link_selector.css('.DivTr a::attr(href)').getall()
# for循环遍历
for index in href[58:]:
# 请求链接
url = 'https:' + index
print(url)
# 发送请求 <Response [200]> 响应对象
response = requests.get(url=url, headers=headers)
# 获取响应文本数据
html_data = response.text
# 把html文本数据, 转成可解析对象 <Selector xpath=None data='<html xmlns="http://www.w3.org/1999/x...'>
selector = parsel.Selector(html_data)
# 解析数据, 提取标题
title = selector.css('.c_l_title h1::text').get() # 根据数据对应标签直接复制css语法即可
# 提取内容
content_list = selector.css('div.noveContent p::text').getall() # get提取第一个
# 列表元素大于2 --> 能够得到小说内容
if len(content_list) > 2:
# 把列表合并成字符串
content = '\n'.join(content_list)
# 保存数据
with open(name + '.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
效果展示:
因为这玩意爬下来是图片,所以还要进行文字识别,

'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
else:
# 提取图片内容
info = re.findall("image_do3\((.*?)\)", html_data)[0].split(',')
img = 'https://read.faloo.com/Page4VipImage.aspx'
img_data = {
'num': '0',
'o': '3',
'id': '724903',
'n': info[3],
'ct': '1',
'en': info[4],
't': '0',
'font_size': '16',
'font_color': '666666',
'FontFamilyType': '1',
'backgroundtype': '0',
'u': '15576696742',
'time': '',
'k': info[6].replace("'", ""),
}
img_content = requests.get(url=img, params=img_data, headers=headers).content
# 文字识别, 提取图片中文字内容
content = get_content(img=img_content)
# 保存数据
with open(name + '.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
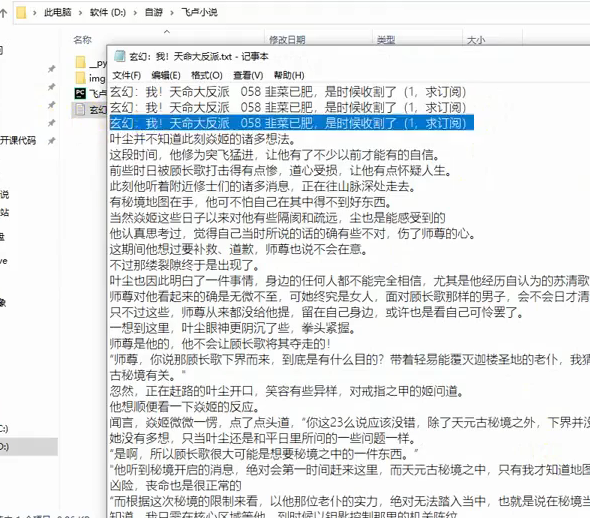
识别效果
4、纵横中文
环境模块
-
解释器: python 3.8
-
编辑器: pycharm 2022.3
-
crypto-js
-
requests
源码展示:
import execjs
import requests
import re
cookies = {
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Referer': '网址屏蔽了,不过审',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
response = requests.get('网址屏蔽了,不过审', cookies=cookies, headers=headers)
html_data = response.text
i = re.findall('<div style="display:none" id="ejccontent">(.*?)</div>', html_data)[0]
f = open('demo.js', mode='r', encoding='utf-8').read()
ctx = execjs.compile(f)
result = ctx.call('sdk', i)
print(result)
5、笔趣阁
相关模块:
<第三方模块>
-
requests >>> pip install requests
-
parsel
<内置模块>
- re
开发环境:
-
环 境: python 3.8
-
编辑器:pycharm 2021.2
源码展示:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import requests # 第三方模块 pip install requests
import parsel # 第三方模块
import re # 内置模块
url = 'https://网址屏蔽/book/88109/'
# 伪装
headers = {
# 键值对 键 --》用户代理 模拟浏览器的基本身份
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# 发送请求 response 响应体
response = requests.get(url=url, headers=headers)
print(response)
selector = parsel.Selector(response.text)
title = selector.css('.zjlist dd a::text').getall()
# 章节链接
link = selector.css('.zjlist dd a::attr(href)').getall()
# print(link)
# replace re.sub()
# zip()
zip_data = zip(title, link)
for name, p in zip_data:
# print(name)
# print(p)
passage_url = '网址屏蔽'+ p
# print(passage_url)
# 发送请求
response_1 = requests.get(url=passage_url, headers=headers)
# print(response_1.text)
# 解析数据 content 二进制 图片 视频
# re
# 查找所有
re_data = re.findall('<div id="content"> (.*?)</div>', response_1.text)[0]
# print(re_data)
# replace 替换
text = re_data.replace('笔趣阁 www.网址屏蔽.net,最快更新<a href="https://网址屏蔽/book/88109/">盗墓笔记 (全本)</a>', '')
text = text.replace('最新章节!<br><br>', '').replace(' ', '')
# print(text)
text = text.replace('<br /><br />', '\n')
print(text)
passage = name + '\n' + text
with open('盗墓笔记.txt',mode='a') as file:
file.write('')
6、起点
环境模块
python3.8 解释器版本
pycharm 代码编辑器
requests 第三方模块
代码展示
import re
import requests # 第三方模块 额外安装
import subprocess
from functools import partial
# 处理execjs编码报错问题, 需在 import execjs之前
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
import execjs
headers = {
'cookie': 用自己的,我的删了
}
ctx = execjs.compile(open('起点.js', mode='r', encoding='utf-8').read())
url = 'https://网址屏蔽/chapter/1035614679/755998264/'
response = requests.get(url=url, headers=headers)
html_data = response.text
arg1 = re.findall('"content":"(.*?)"', html_data)[0]
arg2 = url.split('/')[-2]
arg3 = '0'
arg4 = re.findall('"fkp":"(.*?)"', html_data)[0]
arg5 = '1'
result = ctx.call('sdk', arg1, arg2, arg3, arg4, arg5)
print(result)
text = re.findall('"content":"(.*?)","riskInfo"', html_data)[0]
text = text.replace('\\u003cp>', '\n')
f = open('1.txt', mode='w', encoding='utf-8')
f.write(text)
源码我都打包好了,还有详细视频讲解,文末名片自取,备注【6】快速通过。
尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。