创建es索引并学习分析器、过滤器、分词器的作用和配置
- 一、基础概念
- Elasticsearch与MySQL的类比
- 1. ES与MySQL的结构类比图
- 2. ES与MySQL的类比示意表格
- 3. 索引中重要概念
- 索引(Index)
- 文档(Document)
- 字段(Field)
- 映射(Mapping)
- 二、定义索引
- 索引的组成
- 索引示例
- 三、索引分析
- 四、官方文档(参考)
- 分析器配置
- 配置内置分析器(Configuring built-in analyzers)
- 指定分析器(Specify an analyzer)
- 内置分析器参考
- 分词器参考
- 面向单词的分词器
- 面向部分单词的分词器
- 结构化文本分词器
- 分词过滤器参考(Token filter reference)
- 字符过滤器参考(Character filters reference)
- 标准化器(Normalizers)
一、基础概念
Elasticsearch 是一个分布式搜索和分析引擎,它使用JSON文档来存储数据。索引是Elasticsearch中数据的基本组织单元之一,下面是Elasticsearch索引相关的基本概念:
Elasticsearch与MySQL的类比
1. ES与MySQL的结构类比图
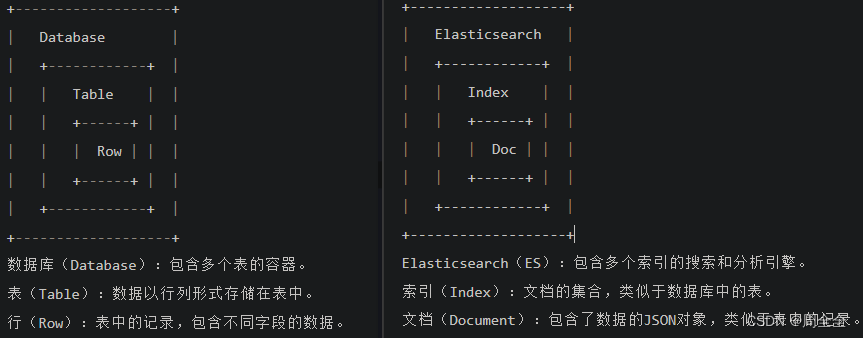
2. ES与MySQL的类比示意表格
| 结构元素 | Elasticsearch | MySQL |
|---|---|---|
| 数据库 | 索引(Index) | 数据库(Database) |
| 表格 | 类型(Type)* | 表(Table) |
| 记录/行 | 文档(Document) | 记录(Row) |
| 列/字段 | 字段(Field) | 列(Column) |
| 主键 | _id 字段 | 主键(Primary Key) |
| 查询语言 | Query DSL | SQL |
注意:在Elasticsearch 7.x版本之后,不再使用类型(Type)的概念,每个索引只包含文档。所以在新版本中,没有类型,只有索引和文档。因此es的索引我们也可以类比为mysql中的数据表
3. 索引中重要概念
索引(Index)
- 索引是Elasticsearch中的主要
数据存储单元。它类似于传统数据库中的表,但更加灵活。 - 索引用于存储相关文档,这些文档可能属于不同的数据类型,但具有共同的查询需求。
- 一个索引可以包含许多文档,每个文档都是一个JSON对象。
文档(Document)
文档是索引中的基本数据单元。每个文档都是一个JSON对象,它包含了数据字段和对应的值。- 例如,在一个名为"books"的索引中,每个文档可能表示一本书,包含书名、作者、出版日期等字段。
字段(Field)
- 字段(Field)是文档(Document)中包含数据的单个元素。字段可以包含不同类型的数据,如文本、数字、日期等
映射(Mapping)
映射定义索引中每个字段的数据类型和属性。它告诉Elasticsearch如何解释和处理每个字段的数据。- 映射可以自动创建,也可以手动定义以更精确地控制字段的处理。
二、定义索引
在开发中es的index我们可以预先定义好,包括索引的别名(alias)、设置(settings)、映射(mappings)等。如果直接用默认的设置,添加文档时es会自动帮我们创建索引,但默认的不一定符合我们的需求
索引的组成
创建Elasticsearch索引的过程通常包括三个关键部分:别名(Aliases)、设置(Settings)、和映射(Mappings),每个部分的作用如下:
-
别名(Aliases):
- 别名是索引的可选名称,允许您将一个或多个索引关联到一个别名上。
- 别名用于简化查询和索引维护,可以用于切换索引版本、滚动索引、分离索引等操作。
- 通过别名可以在不更改查询的情况下轻松切换索引,这对于数据版本管理非常有用
-
设置(Settings):
- 设置包括了索引的配置参数,它们会影响索引的行为和性能。
- 设置可以包括索引的分片和副本配置、刷新间隔、合并策略、搜索相关配置等。
- 通过设置可以调整索引以满足特定需求。例如,可以设置分片的数量、副本的数量、自定义分析器等。
-
映射(Mappings):
- 映射定义了索引中每个字段的数据类型和属性。它告诉Elasticsearch如何解释和处理文档中的数据。
- 可以选择让Elasticsearch自动创建映射(Dynamic Mapping),或者可以显式定义映射以更精确地控制字段的处理(
推荐显式定义)。 - 映射定义通常包括字段名称、数据类型(如文本、整数、日期等)、分析器(用于文本字段的文本分词)等信息。
索引示例
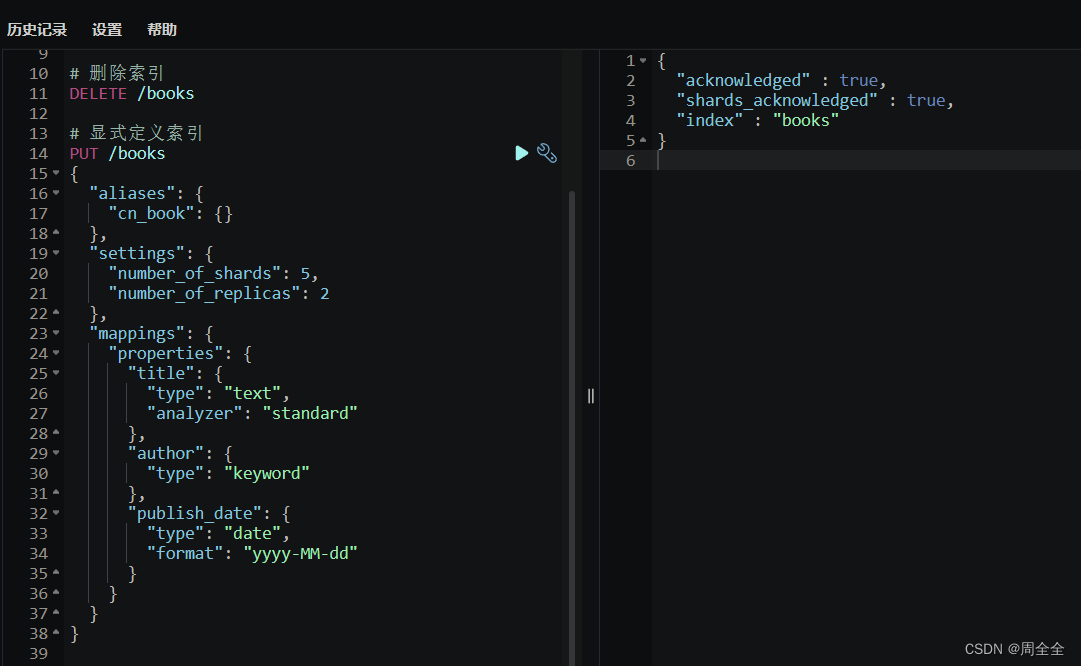
使用Elasticsearch的REST API来创建一个名为"books"的索引 :
PUT /books
{
"aliases": {
"cn_book": {}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
},
"author": {
"type": "keyword"
},
"publish_date": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
}
以下是每个部分的说明:
aliases(别名):
- 别名是一个可选项,允许您为索引定义一个或多个别名,以便更容易引用该索引。在示例中,索引被命名为"cn_book",并且有一个空的别名对象。
settings(设置):
- 在设置部分,您可以配置索引的全局设置。
number_of_shards:指定索引分成的主分片数量。在示例中,索引分成了5个主分片。number_of_replicas:指定每个主分片的副本数量。在示例中,每个主分片有2个副本,用于提高数据冗余和可用性。
mappings(映射):
- 映射定义了索引中的字段及其数据类型和属性。
- 在示例中,有三个字段定义:
title:类型为"text",使用"standard"分析器。这是一个文本字段,通常用于全文搜索。author:类型为"keyword"。这是一个关键字字段,通常用于精确匹配和聚合。publish_date:类型为"date",使用"yyyy-MM-dd"日期格式。这是一个日期字段,用于存储日期信息。
三、索引分析
{
"aliases": {
"data": {},
"book": {}
},
"settings": {
"index": {
"refresh_interval": "5s",
"max_inner_result_window": "10000",
"max_result_window": "20000",
"analysis": {
"analyzer": {
"pinyin_analyzer": {
"tokenizer": "my_pinyin"
}
},
"tokenizer": {
"my_pinyin": {
"type": "pinyin",
"keep_separate_first_letter": false,
"keep_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"lowercase": true,
"remove_duplicated_term": true
}
},
"char_filter": {
"pinyin_multi": {
"type": "mapping",
"mappings": [
"重庆 => 从庆"
]
},
"pinyin_first": {
"type": "mapping",
"mappings_path": "pinyin_first.txt"
},
"remove_space": {
"type": "pattern_replace",
"pattern": "[\\s「」﹝﹞·,。/《》?;‘’、:“”\\|【】\\{\\}\\~\\·\\!\\@\\#\\¥\\%\\……\\&\\*()\\—\\+\\-\\=\\,\\.\\/\\<\\>\\?\\;'\\\\,\"\\|\\[\\]\\{\\}\\`\\~\\!\\@\\#\\$\\%\\^\\&\\*\\(\\)\\-\\=\\_\\+]*",
"replacement": ""
}
},
"normalizer": {
"sort_normalizer": {
"type": "custom",
"char_filter": [
"remove_space",
"pinyin_multi",
"pinyin_first"
],
"filter": [
"cjk_width",
"asciifolding"
]
}
}
}
}
},
"mappings": {
"dynamic": "false"
}
}
-
别名(Aliases):
- “navy_data”: 这是一个名为"data"的索引别名。
- “book”: 这是一个名为"book"的索引别名。
-
索引设置(Settings):
- “index”: 这是索引的根配置。
- “refresh_interval”: 索引的刷新间隔设置为"5s",表示每5秒进行一次刷新。
- “max_inner_result_window”: 设置内部结果窗口的最大大小为"10000"。
- “max_result_window”: 设置结果窗口的最大大小为"20000"。
- “analysis”: 这是索引的文本分析配置。
- “analyzer”: 文本分析器的配置。
- “pinyin_analyzer”: 这是一个名为"pinyin_analyzer"的分析器。
- “tokenizer”: 指定了使用的分词器,这里使用了名为"my_pinyin"的自定义分词器。
- “pinyin_analyzer”: 这是一个名为"pinyin_analyzer"的分析器。
- “tokenizer”: 自定义分词器的配置。
- “my_pinyin”: 这是一个名为"my_pinyin"的分词器,类型为"pinyin"。
- “keep_separate_first_letter”: 设置为"false",表示不保留拼音的首字母。
- “keep_full_pinyin”: 设置为"true",表示保留完整拼音。
- “keep_original”: 设置为"true",表示保留原始文本。
- “limit_first_letter_length”: 设置首字母的长度限制为"16"。
- “lowercase”: 设置为"true",表示将拼音转换为小写。
- “remove_duplicated_term”: 设置为"true",表示删除重复的词项。
- “my_pinyin”: 这是一个名为"my_pinyin"的分词器,类型为"pinyin"。
- “char_filter”: 字符过滤器的配置。
- “pinyin_multi”: 这是一个名为"pinyin_multi"的字符过滤器,类型为"mapping",用于将特定字符映射为其他字符。
- “pinyin_first”: 这是一个名为"pinyin_first"的字符过滤器,类型为"mapping",使用了外部文件"pinyin_first.txt"中的映射。
- “remove_space”: 这是一个名为"remove_space"的字符过滤器,类型为"pattern_replace",用于移除指定的空格和标点符号。
- “pattern”: 指定了匹配的正则表达式模式。
- “replacement”: 指定了替换的字符。
- “normalizer”: 规范化器的配置。
- “sort_normalizer”: 这是一个名为"sort_normalizer"的自定义规范化器。
- “char_filter”: 包括了字符过滤器,包括"remove_space"、“pinyin_multi"和"pinyin_first”。
- “filter”: 包括了过滤器,包括"cjk_width"和"asciifolding"。
- “sort_normalizer”: 这是一个名为"sort_normalizer"的自定义规范化器。
- “analyzer”: 文本分析器的配置。
- “index”: 这是索引的根配置。
-
映射(Mappings):
- “dynamic”: 设置为"false",表示禁用动态映射,索引中的字段需要明确定义,不允许自动添加新字段。
四、官方文档(参考)
分析器配置
参考:Configure text analysis
-
默认情况下,Elasticsearch对所有文本分析使用标准分析器。标准分析器为大多数自然语言和用例提供开箱即用的支持。如果选择使用标准分析器,通常不需要进一步的配置。 -
如果标准分析器不满足您的需求,请查看和测试Elasticsearch的其他内置分析器。内置分析器不需要配置,但某些支持选项可用于调整其行为。例如,您可以配置标准分析器,以去除自定义停用词的列表。
-
如果没有内置分析器满足您的需求,您可以测试并创建自定义分析器。自定义分析器涉及选择和组合不同的分析器组件,从而提供更大的控制权。
分析器测试(Test an analyzer)
analyzer API 用于查看由分析器生成的术语。内置分析器可以在请求中内联指定:POST _analyze { "analyzer": "whitespace", "text": "今天 是 周五" }执行结果
{ "tokens" : [ { "token" : "今天", "start_offset" : 0, "end_offset" : 2, "type" : "word", "position" : 0 }, { "token" : "是", "start_offset" : 3, "end_offset" : 4, "type" : "word", "position" : 1 }, { "token" : "周五", "start_offset" : 5, "end_offset" : 7, "type" : "word", "position" : 2 } ] }还可以测试以下组合:
● A tokenizer 分词器
● Zero or more token filters 零个或多个分词过滤器
● Zero or more character filters 零个或多个字符过滤器POST _analyze { "tokenizer": "standard", "filter": [ "lowercase", "asciifolding" ], "text": "Is this déja vu?" }自定义分析器
PUT my-index-000001 { "settings": { "analysis": { "analyzer": { # 自定义分析器 "std_folded": { "type": "custom", "tokenizer": "standard", "filter": [ "lowercase", "asciifolding" ] } } } }, "mappings": { "properties": { "my_text": { "type": "text", "analyzer": "std_folded" } } } } GET my-index-000001/_analyze { "analyzer": "std_folded", "text": "Is this déjà vu?" } GET my-index-000001/_analyze { "field": "my_text", "text": "Is this déjà vu?" }
配置内置分析器(Configuring built-in analyzers)
内置分析器无需任何配置即可直接使用。 然而,其中一些支持配置选项来改变其行为。例如,标准分析器可以配置为支持停用词列表:
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"std_english": {
"type": "standard",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "standard",
"fields": {
"english": {
"type": "text",
"analyzer": "std_english"
}
}
}
}
}
}
POST my-index-000001/_analyze
{
"field": "my_text",
"text": "The old brown cow"
}
POST my-index-000001/_analyze
{
"field": "my_text.english",
"text": "The old brown cow"
}
指定分析器(Specify an analyzer)
Elasticsearch提供了多种指定内置或自定义分析器的方法:
- 通过文本字段、索引或查询
- 用于索引或搜索时
- 在需要时,可以在不同级别和不同时间指定分析器,这是灵活性的体现。
- 在大多数情况下,采用简单的方法最有效:为每个文本字段指定一个分析器,如在“为字段指定分析器”中所述。
- 这种方法与Elasticsearch的默认行为很好地配合,让您可以在索引和搜索时使用相同的分析器。它还让您能够通过使用"get mapping" API快速查看哪个分析器适用于哪个字段。
- 如果您通常不为索引创建映射,您可以使用索引模板来实现类似的效果。
Elasticsearch如何确定索引分析器:
Elasticsearch通过按以下顺序检查以下参数来确定要使用的索引分析器:
- 字段的分析器映射参数。请参阅“为字段指定分析器”。
- analysis.analyzer.default索引设置。请参阅“为索引指定默认分析器”。
- 如果没有指定上述参数,则使用标准分析器。
为字段指定分析器:
在映射索引时,您可以使用分析器映射参数为每个文本字段指定一个分析器。以下是一个创建索引的API请求示例,将空格分析器设置为标题字段的分析器:
PUT my-index-000001
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}
为索引指定默认分析器:
除了字段级分析器,您还可以使用analysis.analyzer.default设置为索引设置一个备用分析器。以下是一个创建索引的API请求示例,将简单分析器设置为my-index-000001的备用分析器:
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
}
}
}
}
}
Elasticsearch如何确定搜索分析器:
在大多数情况下,指定不同的搜索分析器是不必要的。这样做可能会对相关性产生负面影响,导致意外的搜索结果。
如果选择指定单独的搜索分析器,我们建议在部署到生产环境之前进行彻底的分析配置测试。
在搜索时,Elasticsearch通过按以下顺序检查以下参数来确定要使用的分析器:
- 查询中的analyzer参数。请参阅“为查询指定搜索分析器”。
- 字段的search_analyzer映射参数。请参阅“为字段指定搜索分析器”。
- analysis.analyzer.default_search索引设置。请参阅“为索引指定默认搜索分析器”。
- 字段的分析器映射参数。请参阅“为字段指定分析器”。
如果没有指定上述参数,则使用标准分析器。
为查询指定搜索分析器:
在编写全文查询时,您可以使用analyzer参数来指定搜索分析器。如果提供了此参数,它将覆盖任何其他搜索分析器。以下是一个示例,为匹配查询设置了停用词分析器作为搜索分析器:
GET my-index-000001/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}
为字段指定搜索分析器:
在映射索引时,您可以使用search_analyzer映射参数为每个文本字段指定搜索分析器。如果提供了搜索分析器,则必须还使用analyzer参数指定索引分析器。以下是一个创建索引的API请求示例,将简单分析器设置为标题字段的搜索分析器:
PUT my-index-000001
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}
为索引指定默认搜索分析器:
在创建索引时,您可以使用analysis.analyzer.default_search设置为索引设置一个默认搜索分析器。如果提供了搜索分析器,则必须使用analysis.analyzer.default设置指定默认索引分析器。以下是一个创建索引的API请求示例,将空格分析器设置为my-index-000001的默认搜索分析器:
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
},
"default_search": {
"type": "whitespace"
}
}
}
}
}
这些设置和指定分析器的方式可根据您的需求和索引映射的复杂程度进行调整。根据具体的需求,您可以选择使用简单或复杂的分析配置。
内置分析器参考
官网参考:Built-in analyzer reference
Elasticsearch内置了各种分析器,可以在不需要进一步配置的情况下用于任何索引:
-
标准分析器(Standard Analyzer)
- 标准分析器根据Unicode文本分割算法在单词边界将文本划分为项(terms)。
- 它移除大多数标点符号、将项转换为小写,并支持移除停用词。
-
简单分析器(Simple Analyzer)
- 简单分析器在遇到非字母字符时将文本划分为项。
- 它将所有项转换为小写。
-
空格分析器(Whitespace Analyzer)
- 空格分析器在遇到任何空格字符时将文本划分为项。
- 它不将项转换为小写。
-
停用词分析器(Stop Analyzer)
- 停用词分析器类似于简单分析器,但还支持停用词的移除。
-
关键字分析器(Keyword Analyzer)
- 关键字分析器是一个“无操作”分析器,接受任何文本并输出与原始文本相同的单个项。
-
模式分析器(Pattern Analyzer)
- 模式分析器使用正则表达式将文本划分为项。
- 它支持小写处理和停用词的移除。
-
语言分析器(Language Analyzers)
- Elasticsearch提供了许多语言特定的分析器,如英语或法语。
-
指纹分析器(Fingerprint Analyzer)
- 指纹分析器是一个专门的分析器,用于创建用于重复检测的指纹。
-
自定义分析器(Custom Analyzers)
- 如果找不到适合您需求的分析器,您可以创建一个自定义分析器,结合适当的字符过滤器、标记器和标记过滤器。
分词器参考
一个分词器接收一系列字符流,将其分解成单独的分词(通常是单个单词),并输出一系列分词。例如,一个空格分词器会在看到任何空格时将文本分成分词。它会将文本 “Quick brown fox!” 转换为词项 [Quick, brown, fox!]。
分词器还负责记录以下信息:
●每个词项的顺序或位置(用于短语和单词接近查询)。
●每个词项表示的原始单词的起始和结束字符偏移量(用于突出显示搜索片段)。
●分词类型,对生成的每个词项进行分类,如 、 或 。更简单的分析器只生成单词分词类型。
Elasticsearch内置了许多分词器,可以用于构建自定义分析器。
面向单词的分词器
以下的分词器通常用于将全文分词成单独的单词:
-
标准分词器(Standard Tokenizer)
- 标准分词器根据Unicode文本分割算法在单词边界将文本划分为词项。
- 它移除大多数标点符号。
对于大多数语言来说,这是最佳选择。
-
字母分词器(Letter Tokenizer)
- 字母分词器在遇到非字母字符时将文本划分为词项。
-
小写分词器(Lowercase Tokenizer)
- 小写分词器,类似于字母分词器,在遇到非字母字符时将文本划分为词项,但还将所有词项转换为小写。
-
空格分词器(Whitespace Tokenizer)
- 空格分词器在遇到任何空格字符时将文本划分为词项。
-
UAX URL Email 分词器(UAX URL Email Tokenizer)
- uax_url_email 分词器类似于标准分词器,不过它识别URL和电子邮件地址作为单个词项。
-
经典分词器(Classic Tokenizer)
- 经典分词器是一种基于语法的英语语言分词器。
-
泰语分词器(Thai Tokenizer)
- 泰语分词器将泰文文本分割成单词。
面向部分单词的分词器
这些分词器将文本或单词分割成小片段,用于部分单词匹配:
-
N-Gram 分词器(N-Gram Tokenizer)
- ngram 分词器可以在遇到指定字符列表之一(例如空格或标点符号)时将文本分解为词项,然后返回每个词项的n-gram(连续字母的滑动窗口),例如 quick → [qu, ui, ic, ck]。
-
边缘 N-Gram 分词器(Edge N-Gram Tokenizer)
- 边缘 ngram 分词器可以在遇到指定字符列表之一(例如空格或标点符号)时将文本分解为词项,然后返回每个词项的n-gram,这些n-gram锚定在单词的开头,例如 quick → [q, qu, qui, quic, quick]。
结构化文本分词器
以下的分词器通常用于结构化文本,如标识符、电子邮件地址、邮政编码和路径,而不是用于全文:
-
关键字分词器(Keyword Tokenizer)
- 关键字分词器是一个“无操作”分词器,接受任何文本并输出与原始文本相同的单个词项。它可以与分词过滤器(如小写化)结合使用以规范分析后的词项。
-
模式分词器(Pattern Tokenizer)
- 模式分词器使用正则表达式,可以在匹配单词分隔符时将文本分解为词项,或捕获匹配的文本作为词项。
-
简单模式分词器(Simple Pattern Tokenizer)
- 简单模式分词器使用正则表达式捕获匹配的文本作为词项。它使用正则表达式功能的有限子集,通常比模式分词器更快。
-
字符组分词器(Char Group Tokenizer)
- 字符组分词器可通过一组要分割的字符进行配置,通常比运行正则表达式更经济。
-
简单模式拆分分词器(Simple Pattern Split Tokenizer)
- 简单模式拆分分词器使用与简单模式分词器相同的有限正则表达式子集,但在匹配时分割输入,而不是将匹配作为词项返回。
-
路径分词器(Path Tokenizer)
- path_hierarchy 分词器接受分层值,如文件系统路径,按路径分隔符拆分,并为树中的每个组件发出一个词
分词过滤器参考(Token filter reference)
官网参考:Token filter reference
分词过滤器(Token filters)接受来自分词器的分词流(tokens),可以修改分词(例如小写化)、删除分词(例如去除停用词)或添加分词(例如同义词)。Elasticsearch提供了多个内置的分词过滤器,可以用它们来构建自定义分析器。
- Apostrophetokenfilter
- ASCIIfoldingtokenfilter
- CJKbigramtokenfilter
- CJKwidthtokenfilter
- Classictokenfilter
- Commongramstokenfilter
- Conditionaltokenfilter
- Decimaldigittokenfilter
- Delimitedpayloadtokenfilter
- Dictionarydecompoundertokenfilter
- Edgen-gramtokenfilter
- Elisiontokenfilter
- Fingerprinttokenfilter
- Flattengraphtokenfilter
- Hunspelltokenfilter
- Hyphenationdecompoundertokenfilter
- Keeptypestokenfilter
- Keepwordstokenfilter
- Keywordmarkertokenfilter
- Keywordrepeattokenfilter
- KStemtokenfilter
- Lengthtokenfilter
- Limittokencounttokenfilter
- Lowercasetokenfilter
- MinHashtokenfilter
- Multiplexertokenfilter
- N-gramtokenfilter
- Normalizationtokenfilters
- Patterncapturetokenfilter
- Patternreplacetokenfilter
- Phonetictokenfilter
- Porterstemtokenfilter
- Predicatescripttokenfilter
- Removeduplicatestokenfilter
- Reversetokenfilter
- Shingletokenfilter
- Snowballtokenfilter
- Stemmertokenfilter
- Stemmeroverridetokenfilter
- Stoptokenfilter
- Synonymtokenfilter
- Synonymgraphtokenfilter
- Trimtokenfilter
- Truncatetokenfilter
- Uniquetokenfilter
- Uppercasetokenfilter
- Worddelimitertokenfilter
- Worddelimitergraphtokenfilter
字符过滤器参考(Character filters reference)
官网参考:Character filters reference
-
字符过滤器(Character filters)用于在字符流传递给分词器之前对其进行预处理。
-
字符过滤器接收原始文本作为字符流,并可以通过添加、删除或更改字符来转换字符流。例如,字符过滤器可以用于将印度-阿拉伯数字(٠١٢٣٤٥٦٧٨٩)转换为其阿拉伯-拉丁等效形式(0123456789),或者从流中剥离 HTML 元素,如 。
Elasticsearch 提供了多个内置的字符过滤器,可以用它们来构建自定义分析器。
- HTML 剥离字符过滤器(HTML Strip Character Filter):剥离 HTML 元素,如 ,并解码 HTML 实体,如 &。
- 映射字符过滤器(Mapping Character Filter):替换指定字符串的任何出现次数为指定的替代字符串。
- 模式替换字符过滤器(Pattern Replace Character Filter):使用指定的替代字符串替换与正则表达式匹配的任何字符。
标准化器(Normalizers)
规范化器与分析器类似,不同之处在于它们只能发出单个令牌。因此,它们没有标记化器,只接受可用的字符过滤器和标记过滤器的子集。只允许使用按字符工作的筛选器。例如,允许使用小写过滤器,但不允许使用词干过滤器,因为词干过滤器需要将关键字作为一个整体来查看。可在规范化器中使用的过滤器的当前列表如下:阿拉伯规范化、asciifolding、bengali_normalization、cjk_width、decimal_digh、elision、german_normalization、hindi_normalizing、indic_normalization、小写、persian_normalizion、scandinavian_folding、serbian_normalized、sorani_normalize、大写。Elasticsearch附带了一个小写的内置规范器。对于其他形式的规范化,需要自定义配置。
以下是一个示例,演示如何创建一个自定义规范化器:
PUT index
{
"settings": {
"analysis": {
"char_filter": {
"quote": {
"type": "mapping",
"mappings": [
"« => \"",
"» => \""
]
}
},
"normalizer": {
"my_normalizer": {
"type": "custom",
"char_filter": ["quote"],
"filter": ["lowercase", "asciifolding"]
}
}
}
},
"mappings": {
"properties": {
"foo": {
"type": "keyword",
"normalizer": "my_normalizer"
}
}
}
}
在上述示例中,我们创建了一个名为my_normalizer的自定义规范化器,使用了字符过滤器quote和过滤器lowercase、asciifolding。然后,我们将这个规范化器应用于索引中的foo字段。