论文原文链接
文章目录
- 摘要
- 一、背景、动机和主要贡献
- 背景
- 动机
- 主要问题
- 研究挑战
- 主要贡献
- 二、实验分析
- 数据漂移对准确性的影响
- 推理的早期退出结构
- 最优请求批处理大小
- GPU内存通信
- 三、AdaInf系统设计
- 概览
- 数据漂移感知再训练-推理DAG生成
- 决定数据漂移影响
- 生成再训练推理DAG
- 数据漂移感知GPU时空分配
- GPU space division among applications
- 应用程序的DAG顶点之间的GPU时间划分
阅读笔记是本人在阅读时对要点进行的翻译+个人总结的一些问题(荧光黄标注)和论文不足,如果有对问题解答的回答将非常感谢!
摘要
音视频推断依赖于边缘上的毫秒级SLOs,为了避免数据漂移导致的精度下降,需要不断地进行再训练。然而,满足严格的slo,同时保持在这种情况下的高精度,这对GPU资源分配提出了挑战。
目前还没有专门针对这个问题的研究。在本文中,我们对这一特定场景进行了trace-based实验分析,结果表明不同的模型受数据漂移、增量再训练(我们提出在推理之前对某些样本进行再训练)和早期退出模型结构有助于提高准确性有不同程度的影响,任务之间的相互依赖可能导致CPU-GPU内存通信。
提出了一个数据漂移自适应调度器(AdaInf),用于在边缘服务器上提供准确和SLO保证的推断。AdaInf采用增量式再训练,并根据应用程序的slo分配GPU数量。对于每个应用程序,它将GPU时间划分为再训练和推理,以满足其SLO,然后根据再训练任务的影响程度对GPU时间进行重新定位
Q:确定增量的过程是怎么样的?确定这个增量的过程计算资源开销大吗?(论文第三部分有详细说明)
我们的实际跟踪驱动实验评估表明,与现有方法相比,AdaInf可以将准确率提高高达21%,并减少高达54%的SLO违规。为了达到与AdaInf相似的精度,现有方法需要在边缘服务器上增加4倍GPU资源。
一、背景、动机和主要贡献
背景
音视频推断依赖于边缘提供的毫秒级SLO。一个多模型应用程序由多个DNN模型组成一个有向无环图(DAG)。
问题:放在边缘上训练,但是DNN对于GPU有很强的需求,而边缘上的资源是有限的。模型压缩能够一定程度上解决这个问题,但是由于数据漂移,压缩模型的准确性会显著下降,其中实时视频与音频与训练数据明显偏移。由于压缩DNN具有更浅的架构和更少的权重,因此它们无法推广到新的数据分布或变化的条件,这可能会影响准确性。
解决方式:在线搜集新的样本,进行重训练,重新练数据的标签从在云端托管的黄金模型中获取。
Q:是否还是需要等待云端托管模型产生结果,这个通信时间会比较长吗?(因为要传输新的音视频到云)
论文的实验部分指出通信时间为0,很奇怪,与文中提到的黄金模型获得标签矛盾
动机
主要问题
解决方案存在不足:在本地边缘服务器上进行再训练会对推理的准确性和延迟产生负面影响,因为GPU资源有限,并且与推理执行的资源竞争。
- 推理不会从重训练模型中获得收益
- 由于重训练过程,推理还会被延迟
为了减少再训练过程的延迟,我们可以为它分配更多的资源。然而,这将为推理任务留下更少的资源,这可能导致它们错过它们的SLO。因此,在边缘服务器上对多模型应用进行再训练和推理服务,对GPU资源分配任务提出了挑战,以满足推理延迟slo,同时最大限度地提高所有应用的平均准确率。
研究挑战
在多模型应用环境下,资源分配的挑战变得更加严峻。首先,与单模型应用程序相比,每个应用程序需要更多的计算资源来进行再训练和推理。
其次,在考虑推理任务对再训练任务的依赖关系以及推理任务本身之间的相互依赖关系的同时,解决这一挑战是非平凡的。
最后,当为多个DGA调度资源时,可能会有大量的潜在解决方案,如何在满足时延的要求下寻找到最优解是一个挑战。
(关于写作方法:相对于组里的写挑战的形式,写的很简洁)
主要贡献
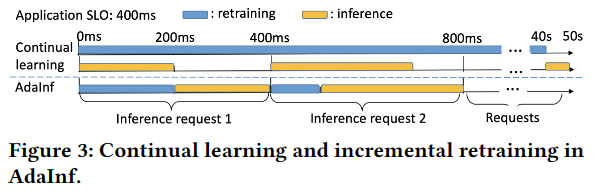
提出方法:提出**增量再训练(incremental retraining)**的方法【图3即为其增量再训练的说明】
具体实现:首先对每个模型同时运行推理和再训练任务的多模型应用场景进行了真实的跟踪驱动实验分析(2)。是该类研究的第一次,主要发现包括:
-
并非应用程序的所有模型都受到数据漂移的影响,不同的模型受到不同程度的影响。
-
增量再训练可以显著提高准确性
-
早期退出结构可以通过节省更多的再培训时间来帮助提高准确性。
SLO要求指的是400ms,是否有实验验证直接放到云上去跑出结果需要多久,准确性多个。这个结果在准确性是一定是比在边缘上高的,但是时延上可能不够;所以本质上这个方法还是在纯边缘压缩模型上串行训练+推理与纯云推理两种方法上实现的权衡?
-
CPU-GPU内存通信构成了推理延迟的重要部分,不同的数据类型具有不同的重用时间延迟
通过利用这些观察结果,我们提出了一种数据漂移自适应调度器,用于多模型应用程序的边缘服务器(AdaInf)上的精确和低速度保证推理。AdaInf采用增量式再培训。具体来说,它包括以下主要方法:
-
数据漂移感知再训练推理DAG生成(3.2)。AdaInf定期(例如,50次)识别受数据漂移影响的每个应用程序的DNN模型及其影响程度,用于确定再训练样本的数量,以在保持准确性的同时加快再训练。它构建了一个DAG,为每个应用程序合并了再训练任务和推理任务,以促进GPU资源分配和任务执行。
如何确定定期这个周期的频率?启发式还是别的方法?有具体设计吗?识别过程计算开销如何?
-
数据漂移感知 GPU 空间和时间分配(3.3)。
- step1 给每个应用拨几个GPU:在每个时隙之前,AdaInf将GPU资源分配给会话中所有应用程序的任务。具体来说,AdaInf根据应用程序的SLO划分了整个GPU计算空间(例如,4个GPU)。
- step2 如何划分再训练时间和推断时间:对于每个应用程序,它在retrainning和inference之间划分GPU时间(即延迟SLO)(基于增量再训练思想)。然后,根据再训练任务的影响程度进一步划分再训练任务的GPU时间,并确定推理任务的最优请求批大小,以最小化推理延迟。此外,AdaInf为每个应用程序选择一个最优的早期退出结构,以便留出更多的时间进行再训练,以提高准确性。
-
CPU-GPU 内存通信最小化。现有的工作[12 17]侧重于最小化CPU-GPU内存通信来训练单模型应用程序,与此相反,AdaInf利用了多模型应用程序的多个再训练和推理任务之间的相互依赖性来实现这一目的。具体来说,它在GPU内存内容被驱逐到CPU内存之前最大限度地利用它们,并首先驱逐GPU内存内容,这些内容将在以后被重用
什么是多个应用程序的多个再训练和推理任务之间的相互依赖?如何理解
实验部分:我们广泛的真实轨迹驱动实验评估(5)表明,与现有方法相比,AdaInf在2ms的调度时间内提高了高达21%的准确率,减少了高达54%的SLO违规。目前的方法需要边缘服务器上四倍的GPU资源才能达到与AdaInf相当的96%的准确率。注意AdaInf也适用于单模型应用程序。这项工作不会引起任何的伦理问题。
这里的伦理问题具体指的是什么?
二、实验分析
推理请求生成长达1000秒,其中每个请求都是来自数据集的图像。实验在一个类型为p3.2xlarge的AWS EC2实例上进行。它拥有1个Nvidia V100 GPU, 5760个计算核,16gb GPU内存,2.3 GHz Intel处理器,8个CPU核,61 GB CPU内存。除非另有说明,在每50个时间段内,我们首先执行所有模型的再训练,然后执行所有推理任务。
由于[18],推理请求率遵循Twitter的轨迹[19],类似于现实世界的推理工作量。
数据漂移对准确性的影响
动机实验:在短时间间隔内执行重新训练以处理数据漂移的重要性。

观察结果1:由于数据漂移,推理精度有相当大的下降,但只有53%-60%的推理请求可以使用重新训练的模型。
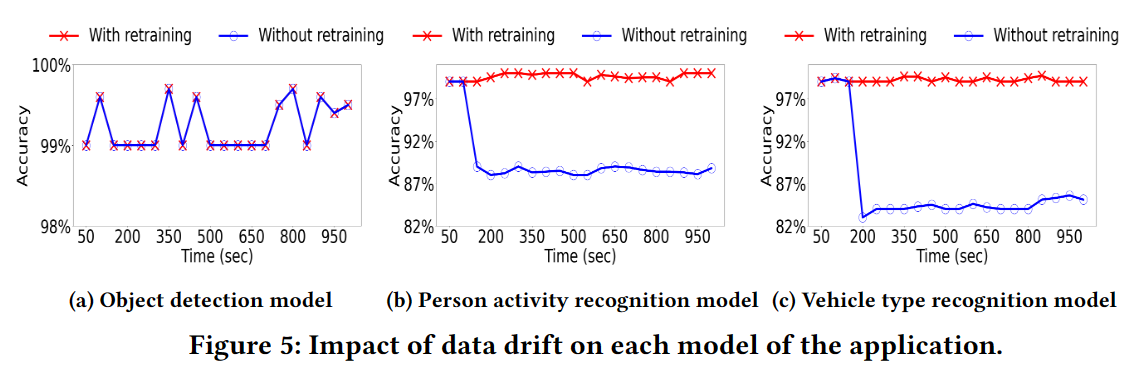
观察结果2:不是所有的模型都会受到数据漂移的影响
观察结果3:在一个应用中,在受数据漂移影响的模型中,不同的模型受到的影响是不同的。
推理的早期退出结构
动机实验:早期退出结构结合增量再训练能为增量再训练提供更多的再训练时间。
在本实验中,我们将在5ms时间会话内收到的应用程序的推理请求视为一个作业[10],该作业具有400ms的SLO。
为什么设置5ms为一个会话?这个时间长度是依据什么确定的?
我们创建了应用程序的所有可能的早期退出结构,其中每个结构都包含应用程序的每个模型的早期退出结构。我们通过选择完整结构每3层之后的一层作为早期退出点来创建模型的早期退出结构,如[22]所示。该应用程序共有81个提前退出结构。
我们测试了三种方法:带增量再培训的早期退出结构(Early-inc)、带增量再训练的完整结构(Full-inc)和不带任何再培训的早期退出结构(Early-w/o)。图7a显示了这些方法在每个时间段的准确性。图7b显示了Early-inc和Ekya在每个时间段用于再训练的总再训练时间和再训练样本的百分比。

增量式再培训使每个作业都可以使用经过一定程度再培训的模型,从而提高了准确性。
Q:Fig7(a)中,早期退出+增量再训练的准确性全面压倒完全训练+增量再训练的准确性,那么是否说明完全训练没有意义,在实践中就应该采取早期退出的策略?还是说其实有些情况是完全训练应该比早期退出要好的,质疑在出现数据偏移前完全重合的数据点。
Early-inc时间段的总再训练时间和再训练样本百分比与Ekya接近。这表明,通过在一段时间内以多个步骤逐步执行再训练,与持续学习相比,增量再训练最终不会获得更少的再训练时间。
观察结果4:增量式再训练提高了准确率,使用最优早期退出结构进行增量式再训练可以显著提高准确率。
最优请求批处理大小
为了使GPU的资源利用率最大化,作业中的请求是分批执行的。最坏延迟[23]是指完成作业中所有批次请求所需的时间。图8显示了不同请求批大小的平均每批延迟和平均最坏情况延迟。该图显示存在一个最佳请求批处理大小为16的情况,它产生最低的最坏情况延迟。
Q:该图只是给出了在测试的数据集、实验环境以及对应的模型结构上存在一个最优的批处理大小为16的情况,但是否其他的测试集、实验环境以及模型上也存在最优的批处理大小呢?如果能够证明存在,那么落实到与之不同的实践环境,应该如何确定批处理大小呢?
观察结果5:在多模型应用程序场景中,存在最小化最坏情况延迟的最佳请求批处理大小

观察结果6:最优请求批处理大小受分配的GPU空间和应用程序的早期退出结构的影响

GPU内存通信
现有的CPU-GPU通信考虑的事单模型。我们的场景具有多模型应用的独特特点,包括多个模型的再训练和推理任务,这些模型的相互依赖关系由DAG表示。
在我们的场景中,GPU内存更有可能不足以承载稍后需要的任务生成的所有参数和中间输出,从而导致CPU-GPU内存通信。
- 通过模型的再训练更新的参数值将在同一模型的推理过程中使用。
- 最后一层在模型推理过程中产生的中间输出将用于DAG序列中下一个模型的推理。
- 请求批处理中的不同推理请求在DAG中运行相同的模型。
- 应用程序的下一个作业可能重用该应用程序的前一个作业的内容。
这些原因都会导致CPU-GPU通信。
图11将每批推理延迟(如图8所示)分解为不同批大小下CPU内存与GPU内存之间的通信时间和GPU空间内的实际计算时间。通信时间约占延迟的24%。

观察结果7:当在边缘服务器中执行多模型应用程序的再训练和推理任务时,CPU-GPU内存通信时间占总体推理延迟的很大一部分。
主要研究对象:Early-inc方法中的内存内容重用。当GPU重新训练应用程序的模型时,我们选择了一个随机的时间戳,并测量了在该时间戳下GPU内存中的每个内容(即一层的中间输出或参数值)被任何模型重用的时间延迟。当GPU执行模型推断时,我们也做了同样的事情。图12a显示了不同内存内容重用时间的CDF。
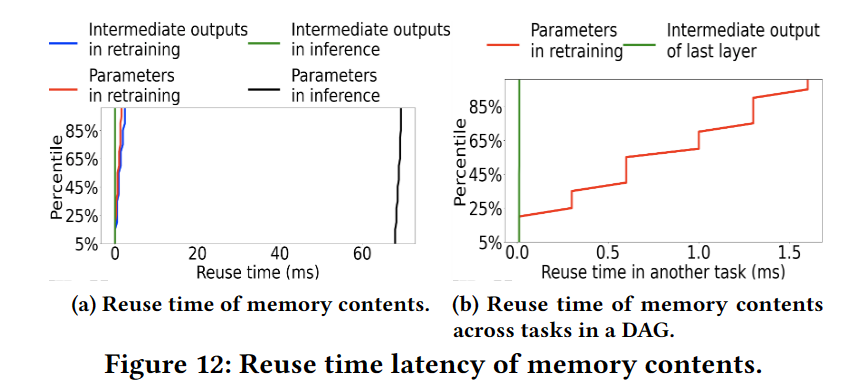
图12b显示了DAG中任务间内存内容重用时间延迟的CDF。车辆识别模型的再训练更新后的参数值被其推理任务重用,最后一层目标检测模型的中间输出被车辆识别模型的推理任务重用。中间输出和更新后的参数分别在0.01ms-0.02ms和0.01ms-1.65ms内重用。
观察结果8:内存内容重用不仅发生在一个模型内(再训练和推断之间),而且发生在DAG中的依赖任务之间。此外,DAG中来自不同任务的不同类型数据的重用时间延迟也不同。

观察结果9:作业中的参数将由下一个作业重用,但中间输出将不被重用。
三、AdaInf系统设计
概览
受观察1的启发,并通过利用其他观察结果,我们提出AdaInf。对于每个应用程序,AdaInf在每个时间段 T(如50s)开始时计算每个模型的影响程度,并生成再训练-推理DAG,以便再训练和推理任务资源的调度和执行,如图14所示。
Q:如何计算每个模型的影响程度,并生成训练-推理应用程序?
如图14所示。在每个时间会话之前(例如,5ms), AdaInf调度资源分配给时间会话中的推理请求(根据[10]中的请求率预测)及其模型再训练。调度大约需要2ms(如5所示),因此在时间戳휏处,AdaInf执行时间会话 [ τ + 2 , τ + 7 ) [\tau+2,\tau+7) [τ+2,τ+7)ms的调度。
没有说明如何确定会话长度。调度的频率决定重训练的频率,该频率是否会影响整体效果,以及在现实中应对众多的应用程序,如何确定这个会话长度呢?启发式?还是基于别的什么方法
Q:根据推理的请求率进行资源分配,依赖于推理结果的准确性,如果不正确,是否有相关的处理措施?
一个时间会话有多个作业,每个作业对应一个应用程序。在一个作业中,每个模型都有一个推理任务(由时间会话中的所有请求组成),可能还有一个再训练任务。AdaInf利用推理任务执行后的空闲时间进行增量再训练,同时满足其SLO。
每个调度中,AdaInf所做工作具体如下:
- 每个作业的请求批处理大小
- 在作业的DAG中,每个任务(包括再训练和推理)要使用多少GPU空间分配给每个作业
- 每个推理任务的最优DNN结构,以及分配给每个任务中每个模型的再训练任务和推理任务的GPU时间
- 以及给定分配的GPU空间和时间,每个再训练任务使用的再训练样本数量和样本
数据漂移感知再训练-推理DAG生成
决定数据漂移影响
观察结果2、3:有些模型会受到数据偏移的影响,有些不会;不同模型受数据偏移的影响是不同程度的:
解决方法:
- step1:找到与旧样本余弦距离最大的新样本S,这些新样本易被误分类。
- step2:AdaInf使用模型m的当前完整结构获得这些S样本的预测输出,并计算其精度 I m ′ I_m^{'} Im′。让我们用 I m I_m Im表示模型m的初始训练版本的精度。如果 I m ′ < I m I_m^{'}<I_m Im′<Im,AdaInf认为模型m将受到数据漂移的影响,需要重新训练。
- 为了确保识别需要重新训练的模型的过程的正确性,AdaInf然后每次逐渐增加S的值以重复该过程。当连续n(例如,4)次的结果没有变化时,它停止。最后,对于识别出的模型,AdaInf通过 I m ′ I_m^{'} Im′计算出每个模型m的影响程度
与以往持续学习对所有模型进行再训练,使用所有再训练样本对模型m进行再训练不同,AdaInf不对不受数据漂移影响的模型进行再训练,而是根据其影响程度确定模型m再训练的再训练样本数量,以减少数据漂移对精度的负面影响(详见3.3)。
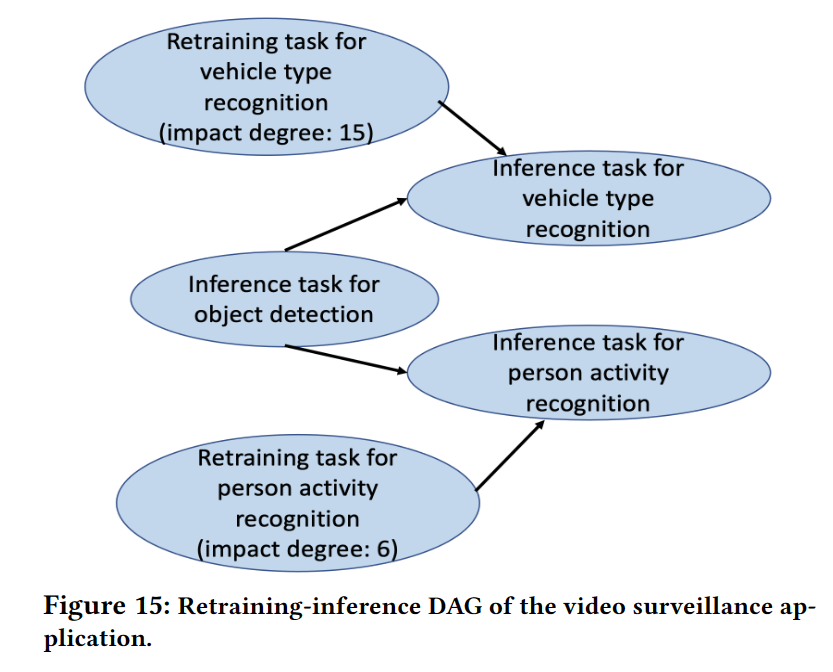
生成再训练推理DAG
与之前的工作[3]不同,许多推理请求不能使用重新训练的模型,AdaInf的目标是在将模型用于下一个推理任务之前尽可能多地重新训练模型,以便在满足SLO的情况下提高推理准确率。
为此,对于每个应用,AdaInf形成一个DAG来表示多个模型的再训练任务和推理任务之间的依赖关系,如图15所示。DAG的每个顶点表示应用程序的DNN模型的再训练任务或推理任务。一个模型的再训练任务总是指向它的推理任务。注意,如果模型m在时间段内不需要再训练,DAG就没有它的再训练任务。
数据漂移感知GPU时空分配
在每个时间会话t之前,AdaInf对预测在时间会话中发生的再训练任务和推理任务进行调度(对于3.1中的(1)-(4))。AdaInf在调度中有两个步骤,如图16所示:

GPU space division among applications
首先,对于时间会话t的作业,AdaInf根据作业(即应用程序)所需的GPU资源空间来划分GPU资源空间,以满足slo。
使用 T a T_a Tams 来表示在一个时间会话中完成所有推理请求的平均时间。然后,因为每次会话等于5ms,所以将有 s = T a / 5 s = T_a/5 s=Ta/5时间会话并发运行作业。因此,AdaInf 将总的 GPU 资源(由 G 表示)均匀地分布在 s 会话中。
Q:由于实际中推理任务到达不是均匀或者一定是满足某种分布的,那么 T a T_a Ta的长度是否会发生变化?每次会话中的 T a T_a Ta应该如何确定?
根据每个作业完成所有请求所需的GPU空间的比例,为不同的作业分配GPU空间,以满足其SLO。为了确定作业所需的GPU空间,AdaInf首先找到分配一个GPU的作业的时间延迟,然后扩展GPU空间以满足其SLO。该方法的细节如下所示:
- 基于观察5,对于每个应用程序,AdaInf执行离线分析,以查找应用程序的每批推理延迟,该延迟基于应用程序的初始DAG,该应用程序不包括任何再训练任务(例如,图1中的DAG),用于分配整个GPU时的一组请求批大小。
- 因此,AdaInf在给定分配的GPU空间的情况下调整作业的批处理大小。为此,AdaInf使用[3]中描述的回归模型,在GP U空间从整个GPU变为实际分配的GPU空间时,迭代请求批大小集来缩放最坏情况延迟。回归模型以批大小、实际分配的GPU空间和批大小的最坏情况延迟作为输入,并输出批大小的缩放后的最坏情况延迟。最后,AdaInf选择提供最小值的请求批处理大小
需要先执行离线分析,然后还要使用回归模型迭代请求批大小集,这样的计算无疑是密集的,在SLO较小的情况下(文中的要求是400ms),但是如果更小,是否能够满足实时性需求?
应用程序的DAG顶点之间的GPU时间划分
作业的任务执行遵循其DAG中的顺序,如图15所示,每个任务使用其分配的资源空间 G a i G_a^i Gai。AdaInf在DAG顶点之间分割作业的总SLO延迟。它首先在推理操作和再训练操作之间分割SLO延迟。然后,进一步将分配的保留操作时间分配到再训练任务中,以提高准确率。
缺点和不足:
- 没有充分拓展到多边缘服务器的情况。这里的“增量”是否应该综合考虑所有边缘的增量,从而增加重训练的效率(每个边缘的模型能够使用更多的异常数据进行训练处理)。当然,该拓展中会涉及到边缘之间的通信开销,需要进一步考虑。
- 对于会话长度的确定,论文中只是给与了一个例子:5ms,但是在现实环境中面对异构的设备,不同的应用,如何确定会话的长度,以及会话的长短对增量重训练的影响,论文中并没有提及。显然,如果会话长度过长,那么增量重训练的优势将得不到充分展现;如果会话长度过短,那么频繁地重训练,训练样本过少又会造成系统产生过高的开销。在现实环境中,如何确定会话长度论文并没有给出一个可行方案。



![[发轫之始 百尺竿头] 家多彩居家供应链001号旗舰店正式开业](https://img-blog.csdnimg.cn/img_convert/5227c65f6a345e5954f2e375bffeb9d3.jpeg)







![2023年中国背光模组产业链、竞争格局及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/e586f28f0ee61895e0ed2ee40d7f2c4e.png)