1、 seaborn
作用:更高效地绘图
#安装
pip3 install seaborn
#导入
import seaborn as sns
单变量:直方图或核密度曲线
双变量:散点图、二维直方图、
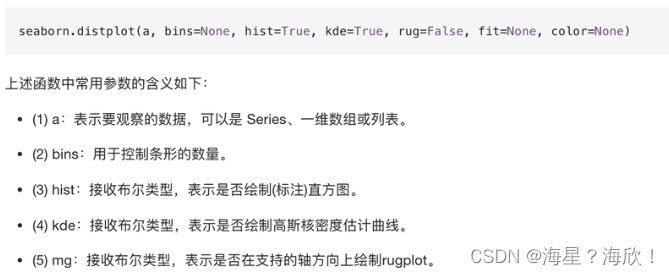
主要函数:distplot()与joinplot()函数
1.1 单变量绘图
API
import seaborn as sns
import numpy as np
np.random.seed(0) #确定随机数种子
arr = np.random.rand(100)
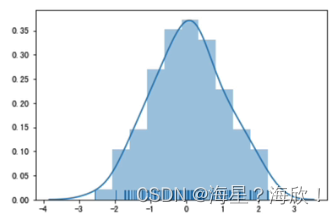
sns.distplot(arr,bins=10,hist=True,kde=True,rug=True)
1.2 双变量绘图
散点图-kind = ‘scatter’
import pandas as pd
df = pd.DataFrame({'x':np.random.randn(500),'y':np.random.randn(500)})
df.head()
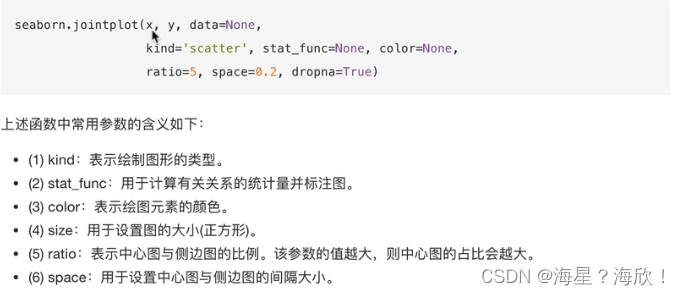
sns.joinplot('x','y',data = df)
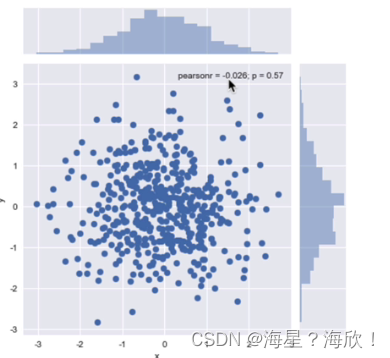
核密度估计曲形-kind = ‘kde’
sns.joinplot('x','y',data = df,kind = 'kde')
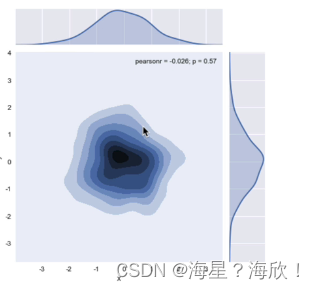
颜色越深,表示数据越密集
二维直方图-kind = ‘hex’
sns.joinplot('x','y',data = df,kind = 'hex')
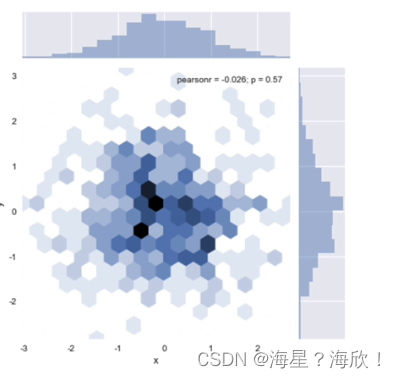
多个成对的双变量分布
dataset = sns.load_dataset('iris')
sns.pairplot(dataset)
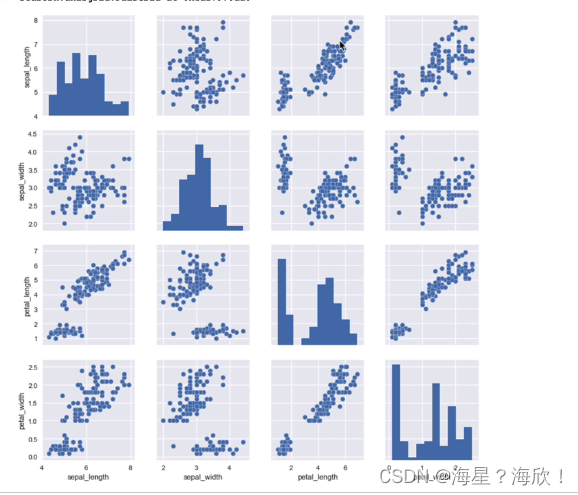
1.3 总结
- 绘制单变量分布图像:seaborn.distplot()
- 绘制双变量分布图像:seaborn.jointplot()
- 绘制成对的双变量分布图像:seaborn.pairplot()
2、分类数据绘图
2.1 类别散点图

data = sns.load_dataset('tips')
data.load()
sns.stripplot(x='day',y='total_bill',data=data)
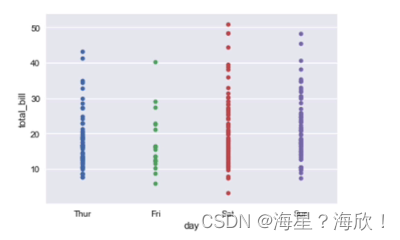
sns.stripplot(x='day',y='total_bill',data=data,hue='time')
#hue='time'按time类别分颜色,这里只有两类

sns.stripplot(x='day',y='total_bill',data=data,hue='time',jitter=True)
#jitter=True不让数据重叠起来
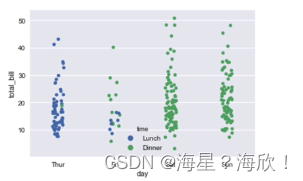
sns.swarmplot('day','total_bill',data=data)
#swarmplot-完全没有重叠
2.2 类别内的数据发布
箱线图、小提琴图
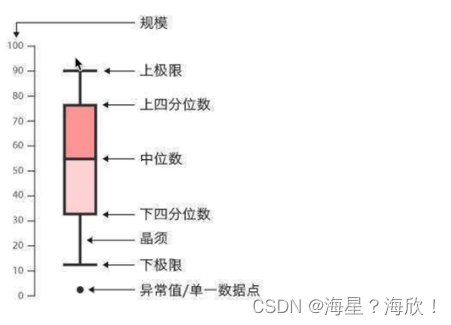
小提琴图结合了箱线图和密度图的特征,主要用来显示数据的分布
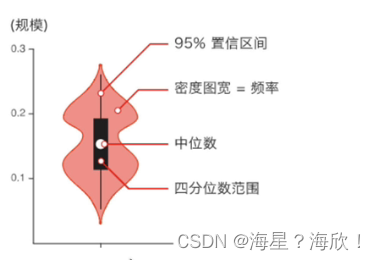
箱线图API
seaborn.boxplot(x=None,y=None,hue=None,data=None,orient=None,color=None,saturation=0.9)
#hue--分组
#palette=['g','b','y',''b]设置颜色,是对hue分组类别的颜色
#saturation颜色设置的饱和度
#举例
sns.boxplot('day','total_bill',data=data)
小提琴图
#API
seaborn.violinplot(x=None,y=None,hue=None,data=None)
#举例
sns.violinplot('day','total_bill',data=data)
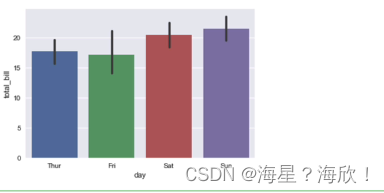
条形图sns.barplot与点图sns.pointplot
#条形图(及其置信区间)
sns.barplot(x='day',y='total_bill',data=tips)
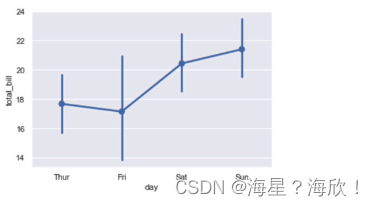
#点图(点估计及其置信区间)
sns.pointplot(x='day',y='total_bill',data=tips)
3、案例:NBA球员数据分析
NBA数据
3.1获取数据且初识数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#获取数据且初识数据
data = pd.read_csv('F:/人工智能/nba_2017_nba_players_with_salary.csv')
data.head()
data.shape
data.describe()
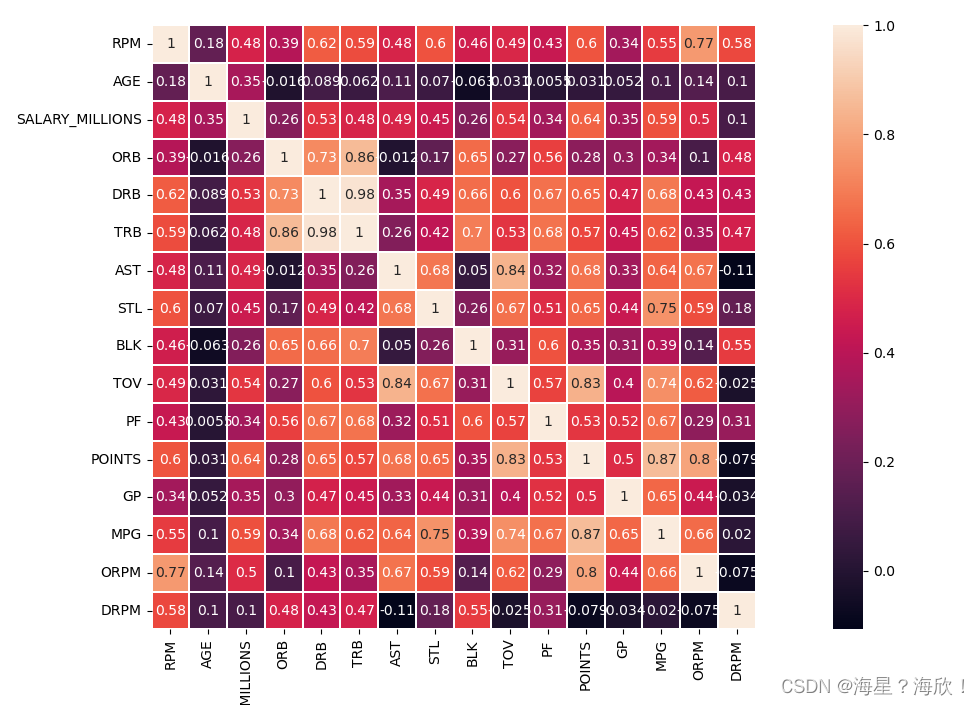
3.2 热力图
#数据分析
##数据相关性
data_cor = data.loc[:,['RPM','AGE','SALARY_MILLIONS','ORB','DRB','TRB','AST','STL','BLK','TOV','PF','POINTS','GP','MPG','ORPM','DRPM']]
data_cor.head()
#列名太多,只对部分列求一下相关性
corr = data_cor.corr()
corr.head()
###热力图
plt.figure(figsize=(20,8),dpi=100)#设置图大小
sns.heatmap(corr,square=True,linewidths=0.1,annot=True)
#square=True调至方形,linewidths=0.1中间加宽度为0.1的线,annot=True显示数据
3.3数据排名分析
#基本数据排名分析
data.loc[:,['PLAYER','RPM','AGE']].sort_values(by='RPM',ascending=False).head()
#按照RPM降序排名
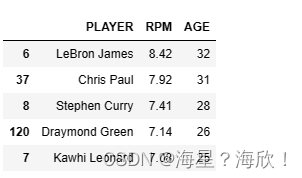
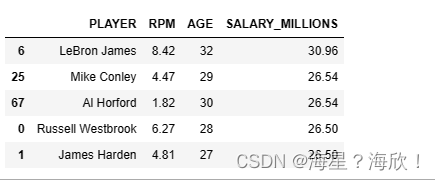
#按照球员薪资排名
data.loc[:,['PLAYER','RPM','AGE','SALARY_MILLIONS']].sort_values(by='SALARY_MILLIONS',ascending=False).head()
3.4seaborn常用的三个数据可视化方法
3.4.1单变量
#seaborn常用的三个数据可视化方法
##单变量
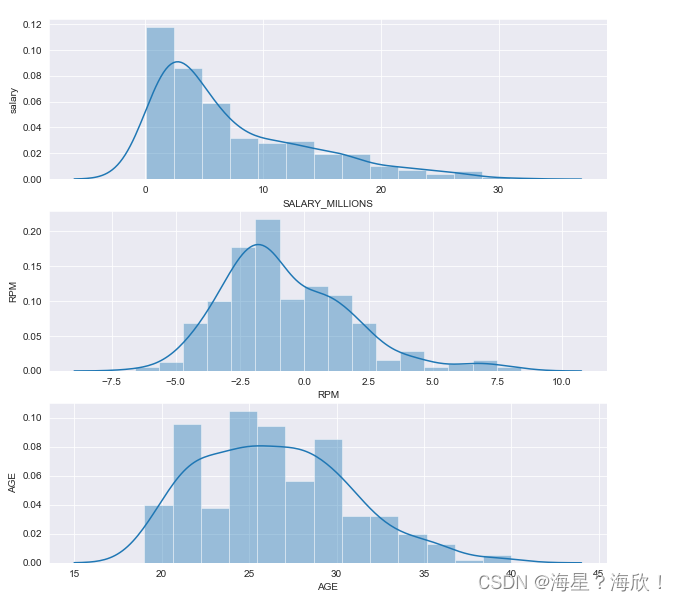
#利用seaborn中的distplot绘图来分别看薪水、效率值、年龄三个信息的分布情况
sns.set_style('darkgrid')#设置基本模式
plt.figure(figsize=(10,10))
plt.subplot(3,1,1)
sns.distplot(data['SALARY_MILLIONS'])
plt.ylabel('salary')
plt.subplot(3,1,2)
sns.distplot(data['RPM'])
plt.ylabel('RPM')
plt.subplot(3,1,3)
sns.distplot(data['AGE'])
plt.ylabel('AGE')
3.4.2双变量-散点图
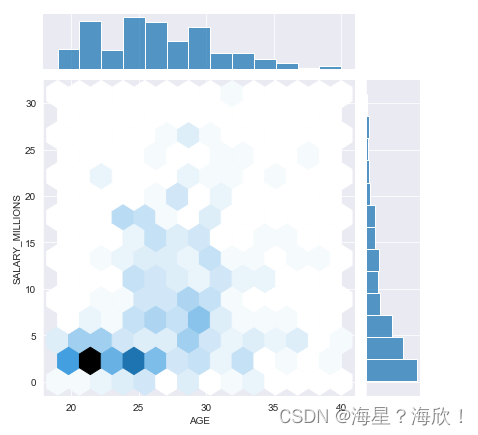
##双变量jointplot
#使用jointplot查看年龄和薪水之间的关系
sns.jointplot(data.AGE,data.SALARY_MILLIONS,kind='hex') #hex显示六边形形式
3.4.3多变量
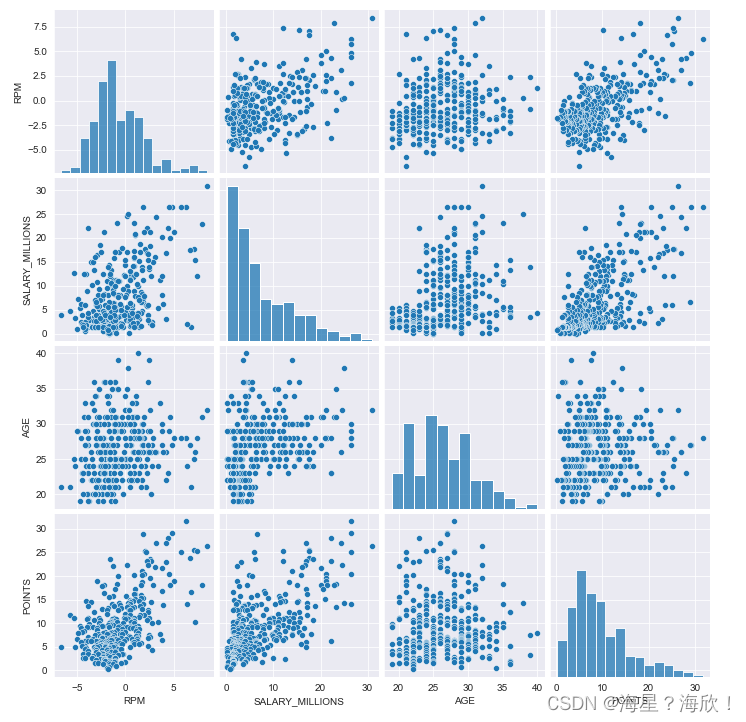
##多变量
multi_data = data.loc[:,['RPM','SALARY_MILLIONS','AGE','POINTS']]
multi_data.head()
sns.pairplot(multi_data)
3.5 衍生变量的一些可视化实践-以年龄为例
自定义了一个年龄分层
#年龄划分
def age_cut(df):
if df.AGE <=24:
return 'young'
elif df.AGE >=30:
return 'old'
else:
return 'best'
#使用apply对年龄进行划分
data['age_cut'] = data.apply(lambda x:age_cut(x),axis=1)
data.head()
分层散点图
#方便计数再加一个cut列
data['cut'] = 1
data.loc[data.age_cut == 'best'].SALARY_MILLIONS.head()
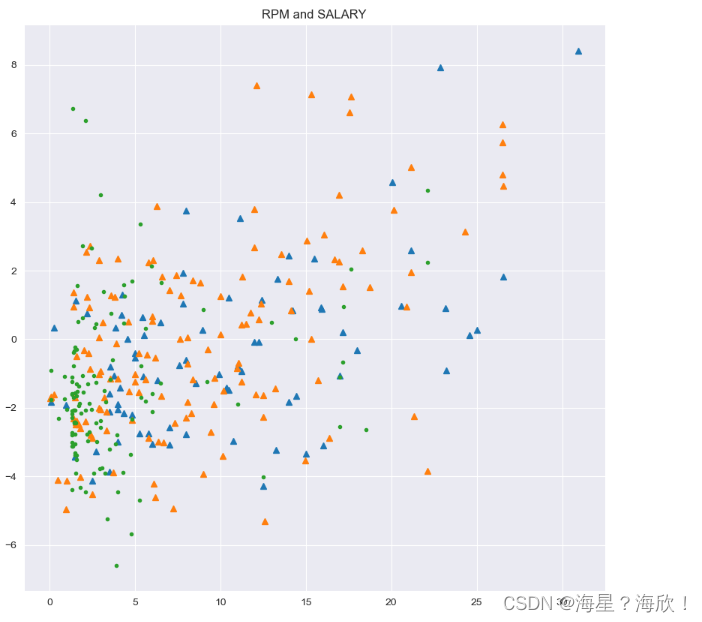
#通过年龄对球员薪水和效率值进行分析
sns.set_style('darkgrid')
plt.figure(figsize=(10,10),dpi=100)
plt.title('RPM and SALARY')
x1 = data.loc[data.age_cut == 'old'].SALARY_MILLIONS
y1 = data.loc[data.age_cut == 'old'].RPM
plt.plot(x1,y1,"^")#"^"上三角形式
x2 = data.loc[data.age_cut == 'best'].SALARY_MILLIONS
y2 = data.loc[data.age_cut == 'best'].RPM
plt.plot(x2,y2,"^")
x3 = data.loc[data.age_cut == 'young'].SALARY_MILLIONS
y3 = data.loc[data.age_cut == 'young'].RPM
plt.plot(x3,y3,".")
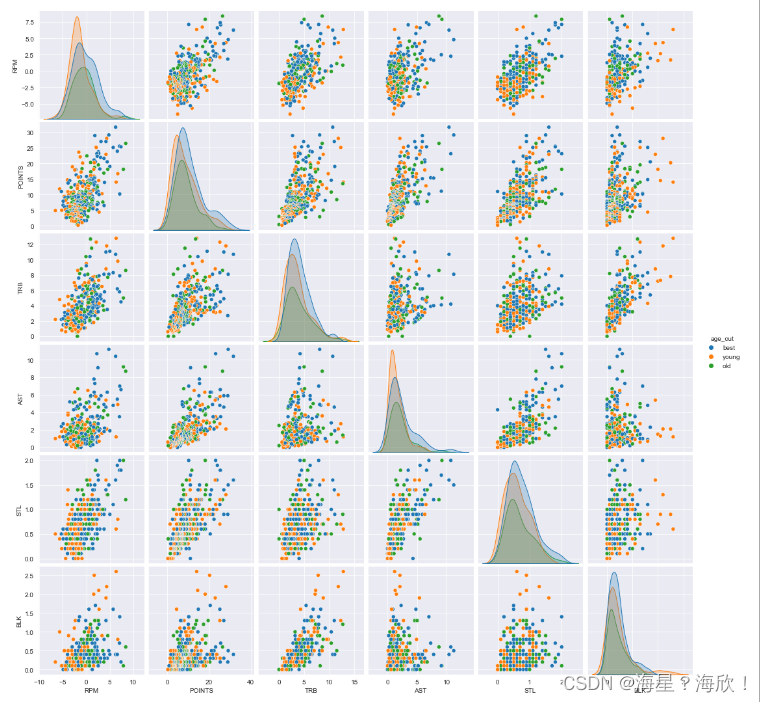
成对双变量绘图pairplot
dat2 = data.loc[:,['RPM','POINTS','TRB','AST','STL','BLK','age_cut']]
sns.pairplot(dat2,hue='age_cut')
3.6 球队数据分析
查看不同类别下的情况,求均值,最值等—agg聚合函数
排名sort_values
data.groupby(by='age_cut').agg({"SALARY_MILLIONS":np.mean})
#利用agg函数输出各年龄段的平均薪资
#按照球队分组,平均薪水降序排序
data_team = data.groupby(by='TEAM').agg({"SALARY_MILLIONS":np.mean}) #TEAM球队
data_team.sort_values(by='SALARY_MILLIONS',ascending=False).head(10)
#按照分年龄段分球队,上榜球员数降序排列。若上榜球员数相同,则按效率值降序排列
data_rpm = data.groupby(by=['TEAM','age_cut']).agg({"SALARY_MILLIONS":np.mean,"RPM":np.mean,"PLAYER":np.size})
data_rpm.sort_values(by=['PLAYER','RPM'],ascending=False).head()
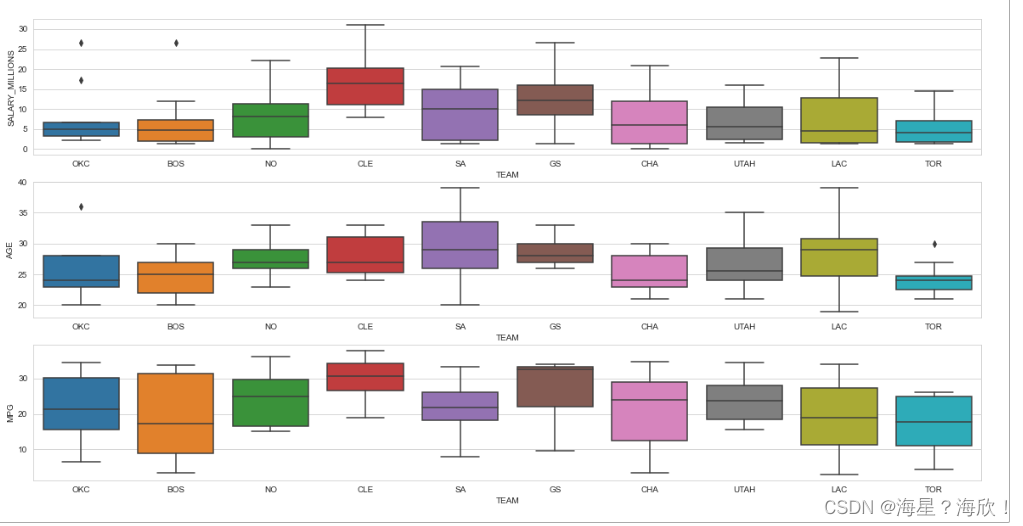
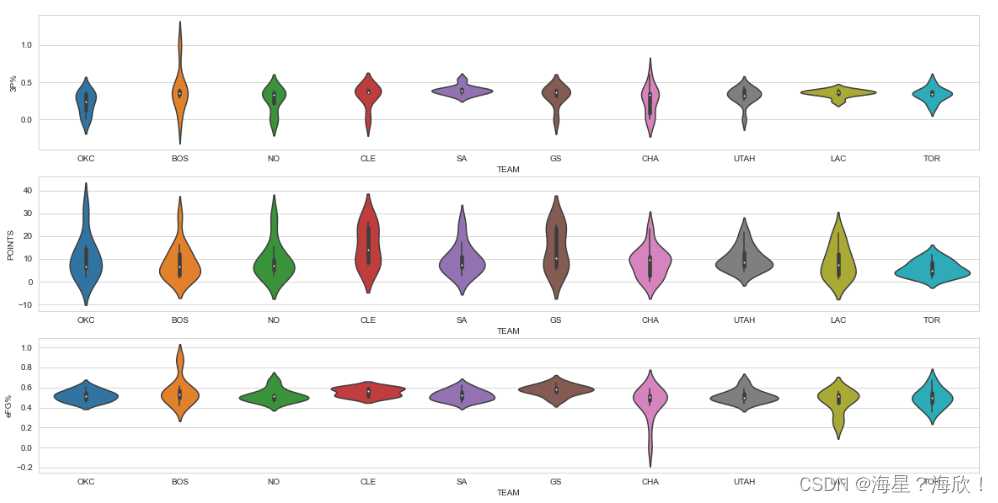
用图像来展示各球队的情况
#利用箱线图和小提琴图进行数据分析
sns.set_style('whitegrid')
plt.figure(figsize=(20,10))
data_team2 = data[data.TEAM.isin(['GS','CLE','SA','LAC','OKC','UTAH','CHA','TOR','NO','BOS'])]#只取了部分球队名
#绘图箱线图
plt.subplot(3,1,1)
sns.boxplot(x='TEAM',y='SALARY_MILLIONS',data =data_team2) #部分球队的薪资分布
plt.subplot(3,1,2)
sns.boxplot(x='TEAM',y='AGE',data =data_team2) #部分球队的年龄分布
plt.subplot(3,1,3)
sns.boxplot(x='TEAM',y='MPG',data =data_team2)#部分球队的出场时间分布
#小提琴图
sns.set_style('whitegrid')
plt.figure(figsize=(20,10))
plt.subplot(3,1,1)
sns.violinplot(x='TEAM',y='3P%',data =data_team2) #部分球队的3分球命中率分布
plt.subplot(3,1,2)
sns.violinplot(x='TEAM',y='POINTS',data =data_team2) #部分球队的得分分布
plt.subplot(3,1,3)
sns.violinplot(x='TEAM',y='eFG%',data =data_team2)#部分球队的真实命中率分布
4、案例:北京租房数据统计分析
需求:

链家北京租房数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
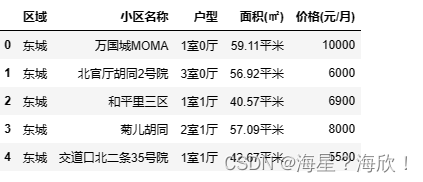
#获取数据
file_data = pd.read_csv('F:/淘宝-人工智能-课件/链家北京租房数据.csv')
file_data
file_data.shape
file_data.info()
file_data.describe()#只计算数值列的
数据基本处理
4.1,重复值和空值处理
file_data = file_data.drop_duplicates()#删除重复值,第一次出现不删除,后面出现重复的会被删除
file_data.shape
#空值处理
file_data = file_data.dropna()#删除空值
file_data.shape
4.2 数据类型转换
想把”面积列“转换成float类型
户型列的表达,有“几房间几厅”的表达,把该列统一为“几室几厅”的表达
#面积列
file_data['面积(㎡)'].values
file_data['面积(㎡)'].values[0][:-2]
#创建一个空的数组,用来存储改格式后的面积列
data_new = np.array([])
data_area = file_data['面积(㎡)'].values
for i in data_area:
data_new = np.append(data_new,np.array(i[:-2]))
data_new
#转换data_new中数据类型
data_new = data_new.astype(np.float64)
data_new
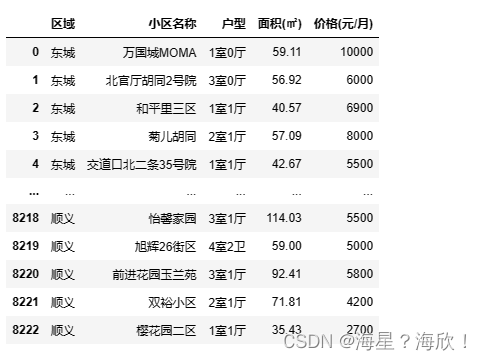
file_data.loc[:,'面积(㎡)'] = data_new #替换
file_data.head()
#户型表达方式替换
house_data = file_data['户型']
temp_list=[]
for i in house_data:
new_info = i.replace('房间','室')
temp_list.append(new_info)
file_data.loc[:,"户型"] = temp_list
file_data
调整后的数据
p0655