前言
Redis 的 RDB 持久化机制简单直接,把某一时刻的所有键值对以二进制的方式写入到磁盘,特点是恢复速度快,尤其适合数据备份、主从复制场景。但如果你的目的是要保证数据可靠性,RDB 就不太适合了,因为 RDB 持久化不宜频繁触发,如果 Redis 触发 RDB 后又有新的数据写入,且还没来得及触发下一次 RDB 就宕机了,中间的数据就会丢失。
在这种场景下,我们就急需一种增量备份的方式,只记录上一次 RDB 到现在为止所有的变更记录就好了,相较于全量备份,增量备份的数据量就小得多了。所以,Redis 还提供了 AOF 持久化机制。
| 特性 | RDB | AOF |
|---|---|---|
| 文件格式 | 二进制 | 文本 |
| 内存效率 | 高 | 较低 |
| 恢复速度 | 快 | 慢 |
| 文件大小 | 小 | 大 |
| 运行效率 | 高 | 低 |
Redis 会把服务端执行的所有写命令,以 RESP 协议的方式追加到 AOF 日志文件中,数据恢复时只要读取 AOF 文件,重放所有的日志即可。

开启AOF
开启 AOF 你需要关心下面几个参数:
appendonly yes #开启AOF
appendfilename "appendonly.aof" #AOF文件名
#AOF文件刷盘策略
appendfsync always
# appendfsync everysec
# appendfsync no
#AOF触发机制
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
#是否开启RDB前导 混合持久化
aof-use-rdb-preamble yes
appendfsync 配置 AOF 文件刷盘策略:
- always:每个写命令执行完都立即同步到磁盘,可靠性高、效率低
- everysec:AOF 日志先写入内存缓冲区,再由定时任务每秒刷一次盘
- no:AOF 日志只写入操作系统文件缓存,由操作系统决定刷盘时机
建议设置为 everysec,兼顾性能和可靠性,最多丢失一秒的数据;always 虽然足够可靠,但是会严重拉低性能;no 会让 AOF 文件刷盘的时机脱离 Redis 的控制,并不推荐。
开启 AOF 不代表就可以高枕无忧了,因为 AOF 是日志追加的形式,意味着随着不断运行,AOF 日志会越来越大。AOF 日志文件膨胀会带来两个问题:
- AOF 文件大小超过文件系统的限制会发生错误
- AOF 文件太大会影响数据恢复效率
所以,Redis 会对 AOF 文件重写,你可以通过bgrewriteaof命令手动触发重写,也可以配置当条件满足时自动触发重写。
- auto-aof-rewrite-percentage:AOF 文件的增长比例,默认增长为原来的一倍大小就开始重写
- auto-aof-rewrite-min-size:允许 AOF 重写的文件最小值
为什么重写可以缩小 AOF 文件呢?因为可以把多条命令合并成一条命令,AOF 只需要记录 Key 最新的 Value 即可,而不用记录修改的历史记录。
最后是aof-use-rdb-preamble参数,它是 Redis4 才开始支持的混合持久化机制,开启后 AOF 重写时将会在 AOF 文件的前半部分先写入全量的 RDB 数据,再把增量 AOF 日志追加在后半部分,同时兼顾了性能和可靠性,建议开启。
AOF机制
先测试下,开启 AOF 后,我们写入数据:
127.0.0.1:6379> set name Jackson
OK
127.0.0.1:6379> lpush names Lisa
(integer) 1
127.0.0.1:6379> lpush names Tom
(integer) 2
因为 AOF 文件是文本形式的,所以我们可以直接查看。AOF 日志是按照 RESP 协议写入的,所以你需要先了解一下 RESP 协议,这个协议很简单。如下:
*代表数组,后面跟着数组长度$代表字符串,后面跟着长度
我们来解读一下这段日志,首先是SELECT 0代表后续操作的是 0 号数据库,紧接着就是各个命令和对应的参数了。
*2
$6
SELECT
$1
0
*3
$3
set
$4
name
$7
Jackson
*3
$5
lpush
$5
names
$4
Lisa
*3
$5
lpush
$5
names
$3
Tom
注意:读命令不会对数据有影响,是不会记录到 AOF 文件的。
此时我们执行bgrewriteaof命令重写 AOF 文件,再次查看发现 AOF 文件确实变小了,两次lpush合并为一次RPUSH了。
*2
$6
SELECT
$1
0
*3
$3
SET
$4
name
$7
Jackson
*4
$5
RPUSH
$5
names
$3
Tom
$4
Lisa
如果开启了混合持久化,我们再执行bgrewriteaof命令重写 AOF 文件,会发现 AOF 文件不可读了,因为此时里面的内容是二进制的 RDB 数据。
REDIS0009� redis-ver6.2.13�
redis-bits�@�ctime·�"eused-mem�`�
aof-preamble���nameJacksonnamesTomLisa��=O{�v�*2
再执行写命令:
127.0.0.1:6379> del name
(integer) 1
再查看 AOF 文件会发现,前半段是不可读的 RDB 数据,后半段是可读的 AOF 日志,这就是混合持久化。
REDIS0009� redis-ver6.2.13�
redis-bits�@�ctime·�"eused-mem�`�
aof-preamble���nameJacksonnamesTomLisa��=O{�v�*2
$6
SELECT
$1
0
*2
$3
del
$4
name
AOF流程
Redis 服务端在执行完写命令后,还会有一套命令传播机制,用于追加 AOF 日志和主从数据复制。命令被传播到 AOF 后会,Redis 会根据命令生成对应的 RESP 协议的文本字符串,然后追加到缓冲区,最后根据刷盘策略来把缓冲区的日志刷新到磁盘。
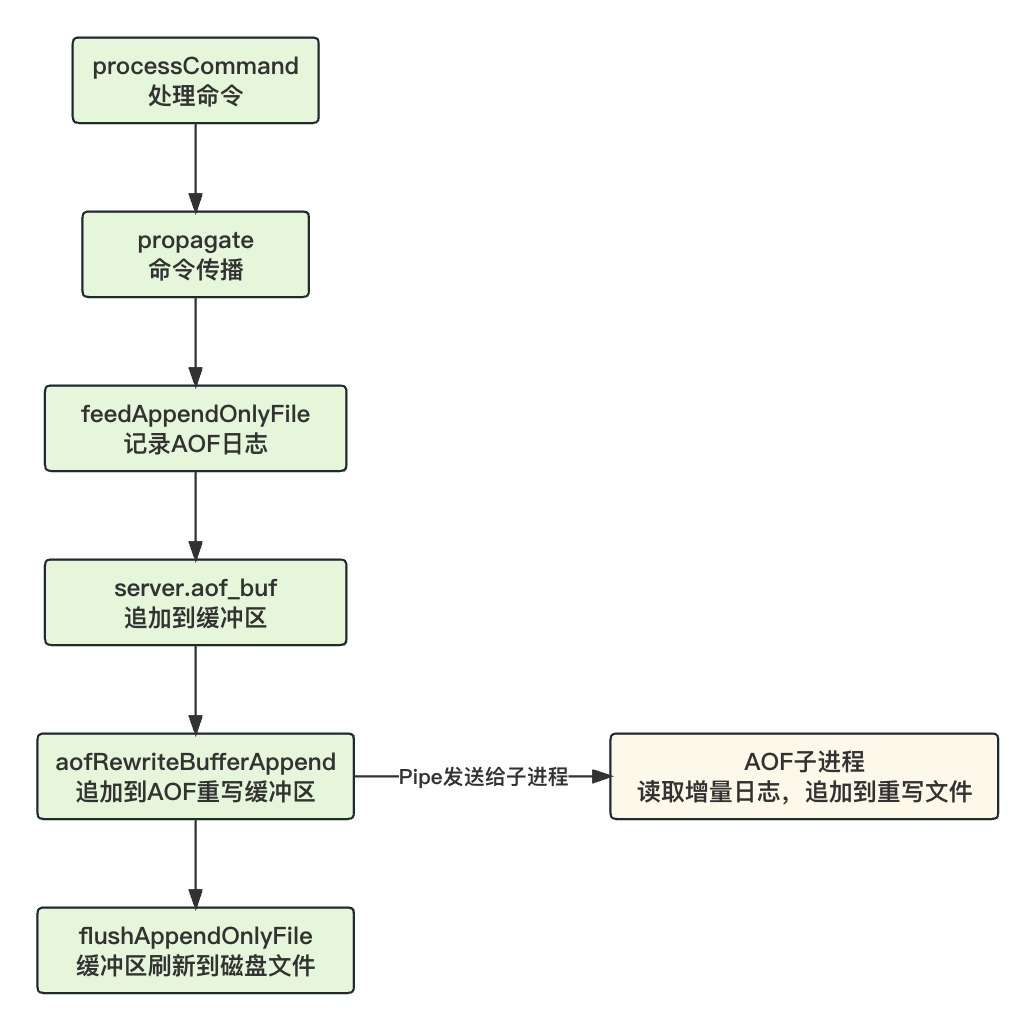
源码中,Redis 在处理命令时,如果开启了 AOF 或有主从数据复制,命令就需要传播,此时会调用propagate()
if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE))
propagate(c->cmd,c->db->id,c->argv,c->argc,propagate_flags);
传播命令时会进一步调用feedAppendOnlyFile()来追加 AOF 日志:
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,int flags)
{
// AOF开启 要追加AOF日志
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc);
if (flags & PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}
有了写命令,怎么生成 AOF 日志呢?是把命令直接记录下来吗?
当然不是,Redis 会把写命令按照 RESP 协议的方式序列化成文本再记录。其次,记录 AOF 日志是一个非常频繁的操作,如果每次都直接写文件,会严重影响 Redis 性能。所以,Redis 会先写到 sds 缓冲区里,变量是aof_buf。
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
// 命令用sds承载
sds buf = sdsempty();
// 命令操作的数据库和上次数据库不同,此时要先写入一个SELECT命令
if (dictid != server.aof_selected_db) {
char seldb[64];
snprintf(seldb,sizeof(seldb),"%d",dictid);
buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n",
(unsigned long)strlen(seldb),seldb);
server.aof_selected_db = dictid;
}
// 再根据命令生成AOF日志
if (cmd->proc == expireCommand || cmd->proc == pexpireCommand ||
cmd->proc == expireatCommand) {
/* Translate EXPIRE/PEXPIRE/EXPIREAT into PEXPIREAT */
buf = catAppendOnlyExpireAtCommand(buf,cmd,argv[1],argv[2]);
}
......
// 追加到AOF缓冲区
if (server.aof_state == AOF_ON)
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
// 如果有AOF子进程在重写,还要把增量部分追加到AOF重写缓冲区
if (server.child_type == CHILD_TYPE_AOF)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
// 释放
sdsfree(buf);
}
光写到内存缓冲区是不安全的,如果宕机数据就丢了。所以接下来还会调用flushAppendOnlyFile()来根据同步策略把缓冲区的日志同步到磁盘。
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
mstime_t latency;
if (sdslen(server.aof_buf) == 0) {
// 即使缓冲区是空的,也要判断是否要刷盘,因为之前可能只是写入文件系统缓存
if (server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.aof_fsync_offset != server.aof_current_size &&
server.unixtime > server.aof_last_fsync &&
!(sync_in_progress = aofFsyncInProgress())) {
goto try_fsync;
} else {
return;
}
}
// 每秒刷盘 判断是否在处理中
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
sync_in_progress = aofFsyncInProgress();
// 每秒刷盘 且不强制刷盘
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) {
if (sync_in_progress) {
if (server.aof_flush_postponed_start == 0) {
// 记录延迟刷盘的开始时间
server.aof_flush_postponed_start = server.unixtime;
return;
} else if (server.unixtime - server.aof_flush_postponed_start < 2) {
// 延迟刷盘时间没超过2秒 也会跳过
return;
}
server.aof_delayed_fsync++;
serverLog(LL_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.");
}
}
// AOF缓冲区写入到文件
latencyStartMonitor(latency);
nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
latencyEndMonitor(latency);
// 写入字节数不等于缓冲区大小 写入异常的处理
if (nwritten != (ssize_t)sdslen(server.aof_buf)) {
......
} else {
// 写入成功
if (server.aof_last_write_status == C_ERR) {
serverLog(LL_WARNING,
"AOF write error looks solved, Redis can write again.");
server.aof_last_write_status = C_OK;
}
}
server.aof_current_size += nwritten;
// 缓冲区小于4K就重用,否则释放申请新的
if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) {
sdsclear(server.aof_buf);
} else {
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
try_fsync: // 尝试刷盘
if (server.aof_no_fsync_on_rewrite && hasActiveChildProcess())
return;
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {// 每次都刷盘
// 刷盘
if (redis_fsync(server.aof_fd) == -1) {
serverLog(LL_WARNING,"Can't persist AOF for fsync error when the "
"AOF fsync policy is 'always': %s. Exiting...", strerror(errno));
exit(1);
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_fsync_offset = server.aof_current_size;
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync)) {
// 每秒刷盘 且时间已到
if (!sync_in_progress) {
aof_background_fsync(server.aof_fd);
server.aof_fsync_offset = server.aof_current_size;
}
server.aof_last_fsync = server.unixtime;
}
}
AOF重写
随着运行,AOF 文件会不断膨胀,AOF 文件过大会影响数据恢复效率,所以 Redis 会不时的重写 AOF 文件。
AOF 重写触发的时机主要有两种:
- 手动执行
bgrewriteaof命令 - AOF 文件增长超过阈值,由定时任务自动触发
AOF 重写不关心键值对的历史修改记录,只需要记录最新的值即可,所以重写后它几乎总是会更小。但是 AOF 重写会面临两个问题:
- AOF 重写要遍历数据库,且需要写磁盘文件,会导致阻塞
- 如果无法容忍阻塞,异步写的话,期间发生的数据变更怎么办?
Redis 给出的解决方案是:一次拷贝、两处日志。
- 一次拷贝:fork 子进程时,需要拷贝父进程的页表
- 日志一:AOF 日志缓冲区正常写,哪怕 AOF 重写失败也不影响现有日志文件
- 日志二:再多写一份 AOF 重写缓冲区日志,用来发送给子进程追加到重写后的 AOF 文件
Redis 在 AOF 重写时,首先会创建三个管道,用于和子进程发送增量日志和ACK;然后 fork 子进程,子进程开始遍历数据库生成新的 AOF 文件;同时,主进程在执行写命令时,会把 AOF 日志同时追加到 AOF 缓冲区和 AOF 重写缓冲区,再通过管道把增量日志发送给子进程;子进程重写好 AOF 日志后再把接收到的父进程发送过来的增量日志也一并追加到新的 AOF 文件,子进程退出;父进程把最后剩余的增量日志追加到新的 AOF 文件,然后替换旧文件,AOF 重写完成。
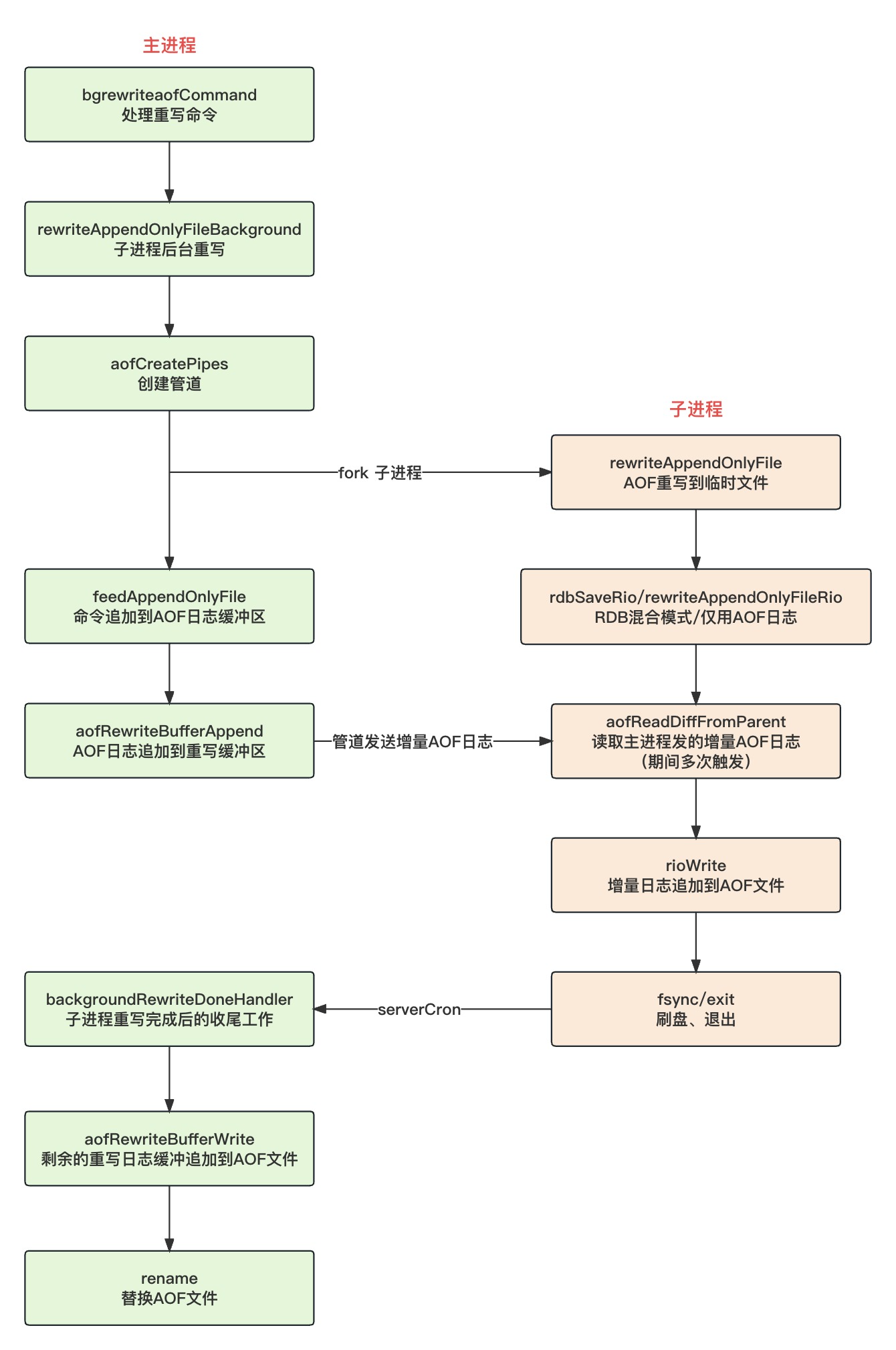
为什么还要用到 Linux 管道???
如果不用管道,子进程在 AOF 重写期间,父进程会积压很多增量日志,子进程重写完成后,父进程要把这些增量日志追加到新的 AOF 文件后,才算重写完成,这势必会发生阻塞。
有了管道,父进程可以实时的把增量日志发送给子进程,由子进程把增量日志追加到重写后的 AOF 文件里,这样就不会阻塞父进程。最终父进程只需要把最后一点点剩余的增量日志追加到新的 AOF 文件即可,这个阻塞时间就可以忽略不计了,归根结底是为了避免阻塞父进程。
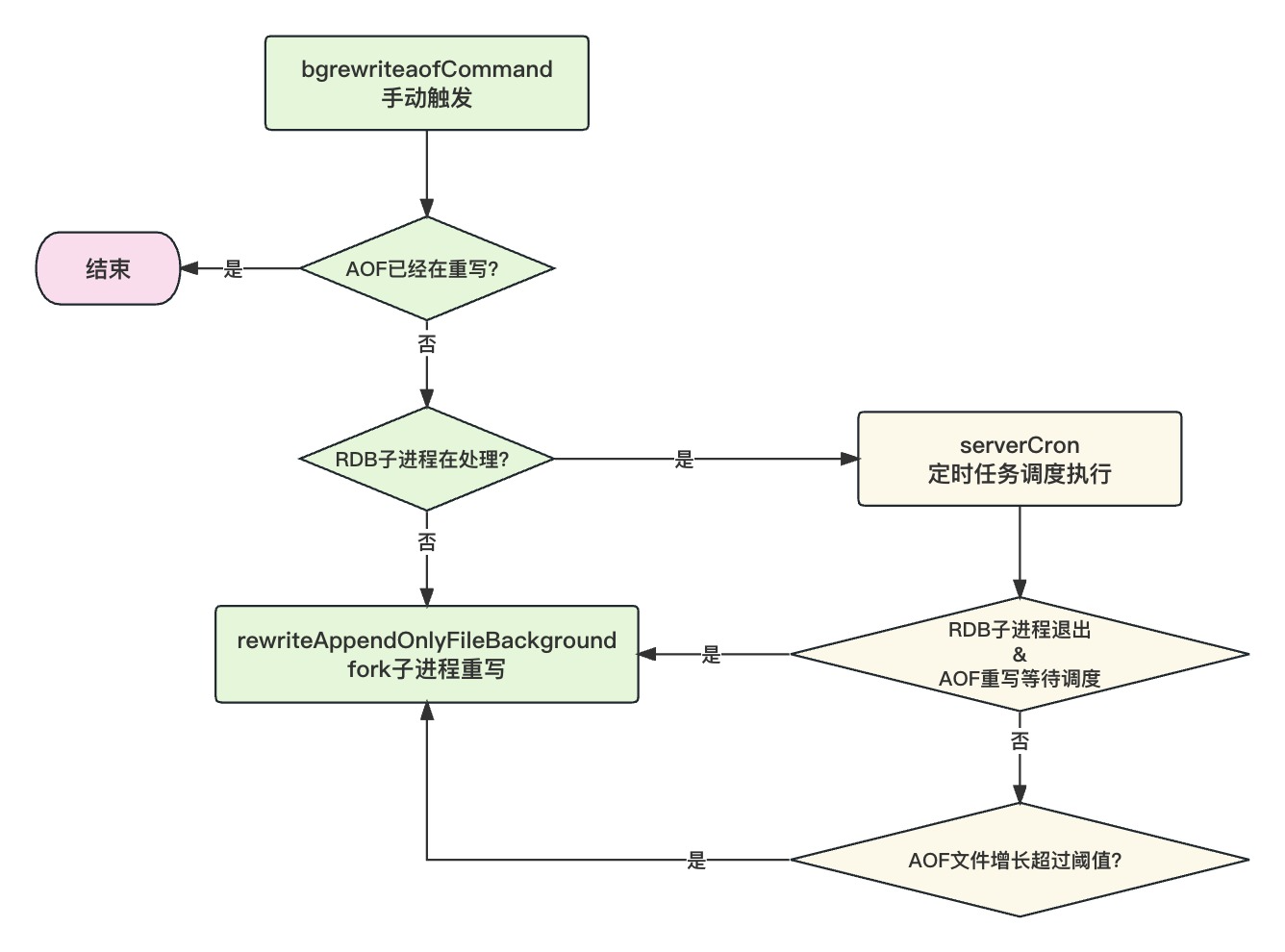
一起看下 AOF 重写的源码吧,bgrewriteaofCommand()方法用来处理bgrewriteaof命令:
- 如果 AOF 已经在重写,这里直接跳过
- 如果在执行 RDB 持久化,AOF 也要等待稍后被调度执行
void bgrewriteaofCommand(client *c) {
if (server.child_type == CHILD_TYPE_AOF) {
// AOF重写子进程处理中
addReplyError(c,"Background append only file rewriting already in progress");
} else if (hasActiveChildProcess()) {
// AOF和RDB子进程不能同时进行,此时把AOF重写任务设为等待调度执行,由定时任务触发
server.aof_rewrite_scheduled = 1;
addReplyStatus(c,"Background append only file rewriting scheduled");
} else if (rewriteAppendOnlyFileBackground() == C_OK) {
// AOF子进程开始启动
addReplyStatus(c,"Background append only file rewriting started");
}
}
rewriteAppendOnlyFileBackground()会在后台 fork 一个子进程来处理 AOF 重写:
- 创建管道
- fork AOF 子进程
- 根据进程 ID 生成临时文件
- AOF重写到临时文件
int rewriteAppendOnlyFileBackground(void) {
pid_t childpid;
// RDB子进程在工作,返回错误
if (hasActiveChildProcess()) return C_ERR;
// 创建三个管道 用于父子进程通信
if (aofCreatePipes() != C_OK) return C_ERR;
// fork子进程
if ((childpid = redisFork(CHILD_TYPE_AOF)) == 0) {
// 子进程
char tmpfile[256];
redisSetProcTitle("redis-aof-rewrite");
redisSetCpuAffinity(server.aof_rewrite_cpulist);
// 进程ID生成临时文件
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid());
// AOF重写到临时文件
if (rewriteAppendOnlyFile(tmpfile) == C_OK) {
sendChildCowInfo(CHILD_INFO_TYPE_AOF_COW_SIZE, "AOF rewrite");
exitFromChild(0);
} else {
exitFromChild(1);
}
} else {
// 父进程
if (childpid == -1) {
serverLog(LL_WARNING,
"Can't rewrite append only file in background: fork: %s",
strerror(errno));
aofClosePipes();
return C_ERR;
}
serverLog(LL_NOTICE,
"Background append only file rewriting started by pid %ld",(long) childpid);
server.aof_rewrite_scheduled = 0;
server.aof_rewrite_time_start = time(NULL);
server.aof_selected_db = -1;
replicationScriptCacheFlush();
return C_OK;
}
return C_OK; /* unreached */
}
父进程首先会调用aofCreatePipes()创建三个管道,用于后续和子进程传输数据:
- pipe1:父给子传输增量日志的管道
- pipe2:子给父发送 ACK 的管道,让父进程停止发送增量日志,自己已经重写完要退出了
- pipe3:父给子发送 ACK 的管道
int aofCreatePipes(void) {
int fds[6] = {-1, -1, -1, -1, -1, -1};
int j;
// 创建三个管道
if (pipe(fds) == -1) goto error; // 父子进程数据传输管道 传输重写期间的增量AOF日志
if (pipe(fds+2) == -1) goto error; // 子父进程ACK管道
if (pipe(fds+4) == -1) goto error; // 父子进程ACK管道
// 父子进程的数据传输管道设为非阻塞
if (anetNonBlock(NULL,fds[0]) != ANET_OK) goto error;
if (anetNonBlock(NULL,fds[1]) != ANET_OK) goto error;
// 注册可读事件监听,子进程重写完成会发送ACK,父进程停止发送增量AOF日志
if (aeCreateFileEvent(server.el, fds[2], AE_READABLE, aofChildPipeReadable, NULL) == AE_ERR) goto error;
server.aof_pipe_write_data_to_child = fds[1];
server.aof_pipe_read_data_from_parent = fds[0];
server.aof_pipe_write_ack_to_parent = fds[3];
server.aof_pipe_read_ack_from_child = fds[2];
server.aof_pipe_write_ack_to_child = fds[5];
server.aof_pipe_read_ack_from_parent = fds[4];
server.aof_stop_sending_diff = 0;
return C_OK;
error:
serverLog(LL_WARNING,"Error opening /setting AOF rewrite IPC pipes: %s",
strerror(errno));
for (j = 0; j < 6; j++) if(fds[j] != -1) close(fds[j]);
return C_ERR;
}
管道创建完开始重写,rewriteAppendOnlyFile()会先打开临时文件,然后判断是否开启混合持久化模式来选择是写 RDB 数据还是 AOF 日志:
if (server.aof_use_rdb_preamble) {
int error;
// RDB二进制全量写入
if (rdbSaveRio(&aof,&error,RDBFLAGS_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
// 仅使用AOF日志
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
rewriteAppendOnlyFileRio()是仅写 AOF 日志,和 RDB 类似也是遍历数据库,再遍历键值对,生成对应的 AOF 日志写入文件。
int rewriteAppendOnlyFileRio(rio *aof) {
dictIterator *di = NULL;
dictEntry *de;
size_t processed = 0;
int j;
long key_count = 0;
long long updated_time = 0;
// 遍历数据库
for (j = 0; j < server.dbnum; j++) {
// 选择数据库的命令
char selectcmd[] = "*2\r\n$6\r\nSELECT\r\n";
redisDb *db = server.db+j;
dict *d = db->dict;
if (dictSize(d) == 0) continue; // 数据库空的,则跳过
// 获取哈希表迭代器
di = dictGetSafeIterator(d);
// 写入选择数据库的命令 例如:*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n
if (rioWrite(aof,selectcmd,sizeof(selectcmd)-1) == 0) goto werr;
if (rioWriteBulkLongLong(aof,j) == 0) goto werr;
// 遍历全局哈希表
while((de = dictNext(di)) != NULL) {
sds keystr;
robj key, *o;
long long expiretime;
// 获取Key、Value
keystr = dictGetKey(de);
o = dictGetVal(de);
initStaticStringObject(key,keystr);
// 获取过期时间
expiretime = getExpire(db,&key);
// 根据不同的数据类型生成对应的AOF日志
.....
// 保存过期时间
if (expiretime != -1) {
char cmd[]="*3\r\n$9\r\nPEXPIREAT\r\n";
if (rioWrite(aof,cmd,sizeof(cmd)-1) == 0) goto werr;
if (rioWriteBulkObject(aof,&key) == 0) goto werr;
if (rioWriteBulkLongLong(aof,expiretime) == 0) goto werr;
}
// AOF重写文件每写入10KB就从尝试管道中读取父进程发送过来的增量AOF日志
if (aof->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES) {
processed = aof->processed_bytes;
aofReadDiffFromParent();
}
}
dictReleaseIterator(di);
di = NULL;
}
return C_OK;
werr:
if (di) dictReleaseIterator(di);
return C_ERR;
}
子进程在 AOF 重写期间会不时地读取父进程通过管道发送过来的增量日志,在 AOF 重写完以后,也会再读取一下增量日志,尽可能地让自己重写的 AOF 文件更全面一些,方法是aofReadDiffFromParent(),读取到的增量日志会先缓存到server.aof_child_diff
ssize_t aofReadDiffFromParent(void) {
char buf[65536]; /* Default pipe buffer size on most Linux systems. */
ssize_t nread, total = 0;
while ((nread =
read(server.aof_pipe_read_data_from_parent,buf,sizeof(buf))) > 0) {
server.aof_child_diff = sdscatlen(server.aof_child_diff,buf,nread);
total += nread;
}
return total;
}
子进程重写完以后,把 AOF 文件刷新到磁盘就可以退出了。父进程的定时任务监听到子进程退出后,会触发backgroundRewriteDoneHandler()方法对 AOF 重写做一个收尾的工作
- 打开重写后的临时文件
- 把最后还剩余的增量日志写入到临时文件
- 替换旧的 AOF 文件
- 清理管道等资源
void backgroundRewriteDoneHandler(int exitcode, int bysignal) {
// 打开子进程重写后的临时文件
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof",(int)server.child_pid);
// 把aof_rewrite_buf_blocks的剩余数据写入AOF文件
if (aofRewriteBufferWrite(newfd) == -1) {
serverLog(LL_WARNING,
"Error trying to flush the parent diff to the rewritten AOF: %s", strerror(errno));
close(newfd);
goto cleanup;
}
......
// 替换AOF文件
rename(tmpfile,server.aof_filename);
......
}
至此,AOF 重写就算彻底结束了。
现在还有一个问题,父进程把 AOF 重写期间的增量日志写在哪里呢?
父进程写完 AOF 日志缓冲区后,会继续判断当前是否有子进程在重写 AOF,如果有就把增量日志再写一份到 AOF 重写缓冲区:
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
......
// 追加到AOF缓冲区
if (server.aof_state == AOF_ON)
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
// 如果有AOF子进程在重写,还要把增量部分追加到AOF重写缓冲区
if (server.child_type == CHILD_TYPE_AOF)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
}
aofRewriteBufferAppend()方法会把增量日志写入到 AOF 重写缓冲区,重写缓冲区是由若干个aofrwblock串联成的一条链表,单个 block 容量是 10MB。
typedef struct aofrwblock {
unsigned long used, free; // 已使用空间、空闲空间
char buf[AOF_RW_BUF_BLOCK_SIZE]; // 缓冲区 默认10MB
} aofrwblock;
Redis 会先判断当前 block 是否能容纳增量日志,如果空间不够会申请新的 block 再写入。如果重写期间有大量写入,重写缓冲区会变得很大,占用大量内存。
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
// AOF重写缓冲区由若干个aofrwblock组成,单个block默认10MB
listNode *ln = listLast(server.aof_rewrite_buf_blocks);
aofrwblock *block = ln ? ln->value : NULL;
while(len) {
if (block) {
unsigned long thislen = (block->free < len) ? block->free : len;
if (thislen) {
// 当前已经分配了block,且block可以容纳增量AOF日志,直接写入即可
memcpy(block->buf+block->used, s, thislen);
block->used += thislen;
block->free -= thislen;
s += thislen;
len -= thislen;
}
}
if (len) { // 还没有分配block,或block容量不够,需要分配新的
int numblocks;
// 分配block
block = zmalloc(sizeof(*block));
block->free = AOF_RW_BUF_BLOCK_SIZE;
block->used = 0;
// block加入链表
listAddNodeTail(server.aof_rewrite_buf_blocks,block);
// block数量超过10或100的倍数时记录日志
numblocks = listLength(server.aof_rewrite_buf_blocks);
if (((numblocks+1) % 10) == 0) {
int level = ((numblocks+1) % 100) == 0 ? LL_WARNING :
LL_NOTICE;
serverLog(level,"Background AOF buffer size: %lu MB",
aofRewriteBufferSize()/(1024*1024));
}
}
}
if (!server.aof_stop_sending_diff &&
aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0)
{
aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child,
AE_WRITABLE, aofChildWriteDiffData, NULL);
}
}
注意最后几行代码,Redis 给管道 fd 注册了可写事件。因为父进程光写入重写缓冲区还不够,还要把重写缓冲区里的增量日志发给子进程,让子进程尽可能多的写入日志,自己最后就能少写一点了,监听方法是aofChildWriteDiffData(),父进程发送后,子进程就可以读到了。
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
listNode *ln;
aofrwblock *block;
ssize_t nwritten;
UNUSED(el);
UNUSED(fd);
UNUSED(privdata);
UNUSED(mask);
while(1) {
// 从头开始发
ln = listFirst(server.aof_rewrite_buf_blocks);
block = ln ? ln->value : NULL;
if (server.aof_stop_sending_diff || !block) {
aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child,
AE_WRITABLE);
return;
}
if (block->used > 0) {
// 写入管道
nwritten = write(server.aof_pipe_write_data_to_child,
block->buf,block->used);
if (nwritten <= 0) return;
memmove(block->buf,block->buf+nwritten,block->used-nwritten);
block->used -= nwritten;
block->free += nwritten;
}
if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln);
}
}
尾巴
AOF 主要解决 Redis 数据持久化的实时性问题,现在已经成为了主流的持久化方式。它会把写命令生成 RESP 协议文本的方式追加到 AOF 文件中,为了避免 AOF 文件过度膨胀,Redis 会按照一定的策略对 AOF 文件做重写。重写时为了避免阻塞主线程,Redis 会 fork 子进程处理,同时主进程会记录下重写期间的增量日志,通过管道发送给子进程,让子进程尽可能多的记录日志,子进程重写完毕后会通过管道发送 ACK 要求父进程停止发送增量日志,子进程退出,父进程做最后的收尾工作,把最后剩余的一点增量日志追加到新的 AOF 文件后并完成替换,整个 AOF 重写就结束了。
![2023年中国半导体缺陷检测设备市场规模及发展趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/69b9cb1c63c18cbe7d26fd8148def799.png)