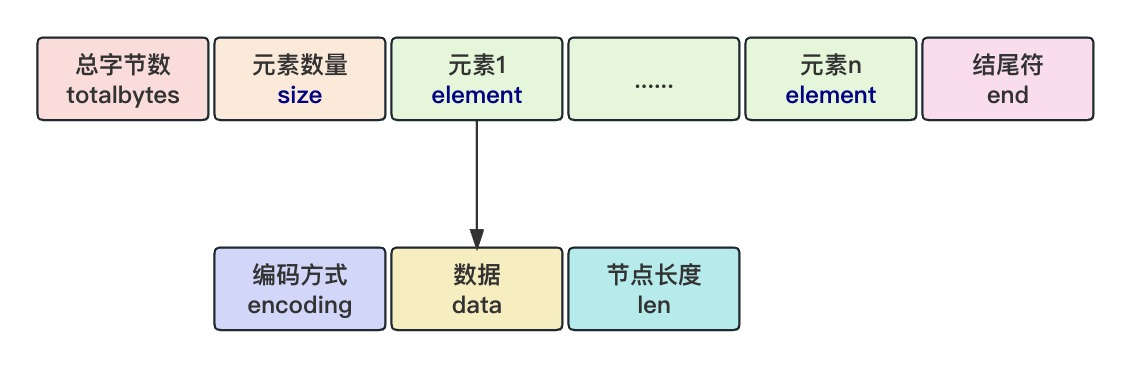
注:笔者是在centos云服务器环境下安装的Elasticsearch
目录
1.安装前准备
2.下载Elasticsearch
3.启动Elasticsearch 非常容易出问题
第一次运行时,可能出现如下错误:
一、内存不足原因启动失败
二、使用root用户启动问题
三、启动ES自动被killed
四、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
五、the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
后续在使用中遇到问题也会持续更新……
1.安装前准备
至少需要jdk版本8以上的java环境,笔者安装的elasticsearch需要jdk11及以上的java环境。大家可以去Oracle官网下载合适的环境
Java Downloads | Oracle![]() https://www.oracle.com/java/technologies/downloads/#java17jdk安装教程可以查看这篇文章,笔者也是按照这篇文章的第二个方法安装的
https://www.oracle.com/java/technologies/downloads/#java17jdk安装教程可以查看这篇文章,笔者也是按照这篇文章的第二个方法安装的
Linux系统下安装Java环境(史上最简单没有之一)_linux下载java-CSDN博客![]() https://blog.csdn.net/qq_43329216/article/details/118385502
https://blog.csdn.net/qq_43329216/article/details/118385502
2.下载Elasticsearch
推荐在 /usr/local 路径下 运行以下命令,来下载Elasticsearch压缩包
# 下载
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.11.1-linux-x86_64.tar.gz
# 解压
tar -xvf elasticsearch-7.11.1-linux-x86_64.tar.gz3.启动Elasticsearch 非常容易出问题
cd elasticsearch-7.11.1/bin
./elasticsearch第一次运行时,可能出现如下错误:
一、内存不足原因启动失败
Exception in thread "main" java.lang.RuntimeException: starting java failed with [1] output:
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 899678208 bytes for committing reserved memory.
# An error report file with more information is saved as:
# logs/hs_err_pid653.log error: Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000ca600000, 899678208, 0) failed; error='Not enough space'(errno=12)
at org.elasticsearch.tools.launchers.JvmOption.flagsFinal(JvmOption.java:119)
at org.elasticsearch.tools.launchers.JvmOption.findFinalOptions(JvmOption.java:81)
at org.elasticsearch.tools.launchers.JvmErgonomics.choose(JvmErgonomics.java:38)
at org.elasticsearch.tools.launchers.JvmOptionsParser.jvmOptions(JvmOptionsParser.java:135)
at org.elasticsearch.tools.launchers.JvmOptionsParser.main(JvmOptionsParser.java:86)原因:ES默认的分配内存超出了空闲内存的大小,所以出现内存不足无法启动的现象。
解决方案:先查看系统内容情况,根据需要修改内存大小
使用 free -h 命令,查看系统内容情况
[es@FrankZhang bin]$ free -h
total used free shared buff/cache available
Mem: 1.8G 982M 393M 696K 462M 706M
Swap: 0B 0B 0B
查看 available 大小修改配置文件里的参数大小
vim config/jvm.options
里面有两个参数
## -Xms2g
## -Xmx2g
将这两个参数修改为合适的大小即可,如果修改完后运行还不行,那就需要继续调整。推荐512m或128m即可
-Xmx128m二、使用root用户启动问题
[2018-12-11T12:53:33,473][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:127) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:114) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:67) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:122) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.Command.main(Command.java:88) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:91) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:84) ~[elasticsearch-5.5.1.jar:5.5.1]
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:106) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:194) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:351) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:123) ~[elasticsearch-5.5.1.jar:5.5.1]
... 6 more原因:ElasticSearch不允许直接通过 root 来登录
解决方案:需要另外设置一个账户来启动
adduser es
passwd es
# 赋予es用户权限
chown -R es:es elasticsearch-7.11.1/
chmod 770 elasticsearch-7.11.1/
# root 用户切换到 es 用户
su es使用这个 es 用户去启动,就可以解决上面的问题。
三、启动ES自动被killed
[es@FrankZhang bin]$ ./elasticsearch
Killed原因:服务器可用内存没有达到ES虚拟机所需内存的默认值或者是目前系统缓存占用很大
解决方案:超过默认值就是上面第一个问题,目前系统缓存占用大可以用下面的命令来回收buffer/cache
echo 1 > /proc/sys/vm/drop_caches # 仅清除页面缓存
echo 2 > /proc/sys/vm/drop_caches # 清除目录项和inode
echo 3 > /proc/sys/vm/drop_caches # 清除页面缓存、目录项以及inode四、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]

注:这个和上面的内存不足不是同一种问题
原因:elasticsearch 用户拥有的内存权限太小。至少需要262144
解决方案:编辑 /etc/sysctl.conf 文件
# 在最后添加一行
vm.max_map_count=262144
# 保存退出后需要让配置生效
sysctl -p五、the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
原因:缺少默认配置
解决方案:
至少需要配置三个中的一个参数
- discovery.seed_hosts:集群主机列表
- discovery.seed_providers: 基于配置文件配置集群主机列表
- cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填