分类目录:《深入理解强化学习》总目录
相关文章:
· 强化学习智能体的四要素:策略(Policy)
· 强化学习智能体的四要素:收益信号(Revenue Signal)
· 强化学习智能体的四要素:价值函数(Value Function)
· 强化学习智能体的四要素:模型(Model)
对于一个强化学习智能体,它可能有一个或多个如下的组成成分:
- 策略(Policy):智能体会用策略来选取下一步的动作
- 收益信号(Revenue Signal):在每一步中,环境向强化学习智能体发送一个标量数值,收益信号是改变策略的主要基础
- 价值函数(Value Function):我们用价值函数来对当前状态进行评估,价值函数用于评估智能体进入某个状态后,可以对后面的奖励带来多大的影响。价值函数值越大,说明智能体进入这个状态越有利
- 模型(Model):模型表示智能体对环境的状态进行理解,它决定了环境中世界的运行方式
本文就将探讨强化学习智能体的四要素中的模型。
模型决定了下一步的状态。下一步的状态取决于当前的状态以及当前采取的动作。它由状态转移概率和奖励函数两个部分组成。状态转移概率即:
p
s
s
′
a
=
p
(
s
t
+
1
=
s
∣
s
t
=
s
,
a
t
=
a
)
p_{ss'}^a=p(s_{t+1}=s|s_t=s, a_t=a)
pss′a=p(st+1=s∣st=s,at=a)
奖励函数是指我们在当前状态采取了某个动作,可以得到多大的奖励,即:
R
(
s
,
a
)
=
E
[
r
t
+
1
∣
s
t
=
s
,
a
t
=
a
]
R(s, a)=E[r_{t+1}|s_t=s, a_t=a]
R(s,a)=E[rt+1∣st=s,at=a]
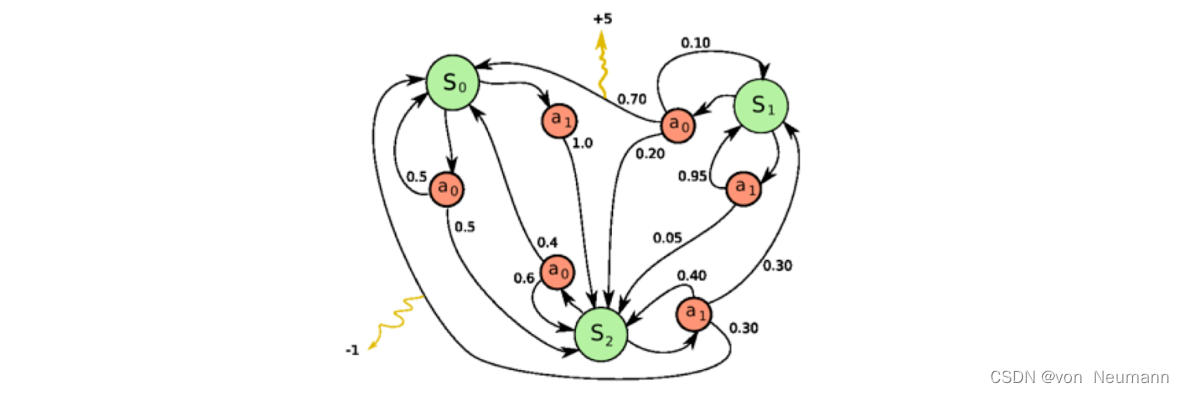
当我们有了策略、价值函数和模型等要素后,就形成了一个马尔可夫决策过程(Markov Decision Process)。如下图所示,这个决策过程可视化了状态之间的转移以及采取的动作。
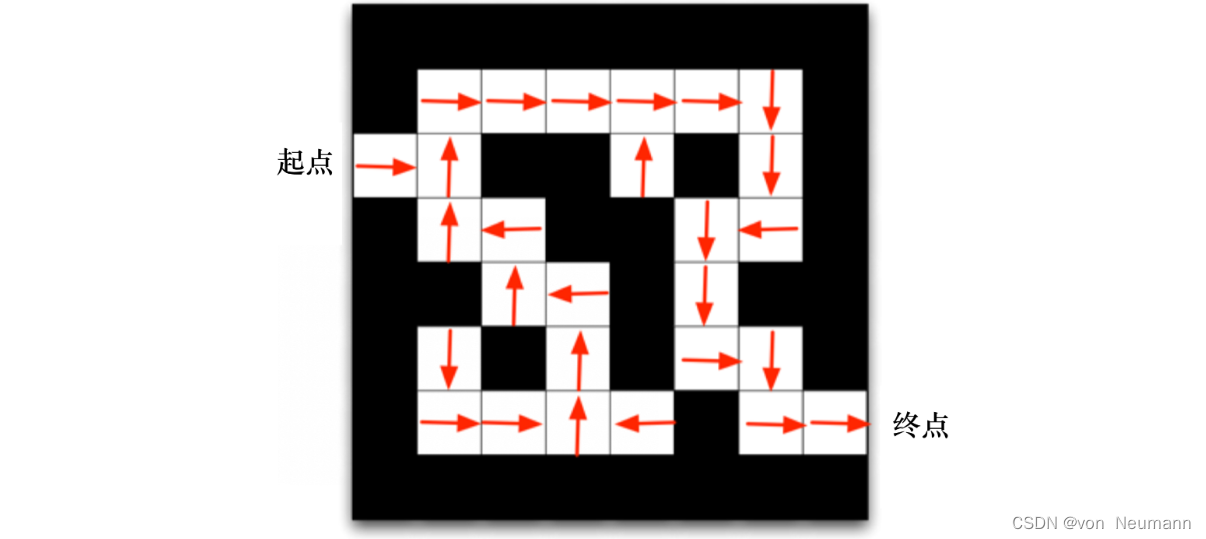
我们来看一个走迷宫的例子。如下图所示,要求智能体从起点开始,然后到达终点的位置。每走一步,我们就会得到
−
1
-1
−1的奖励。我们可以采取的动作是往上、下、左、右走。我们用现在智能体所在的位置来描述当前状态。

我们可以用不同的强化学习方法来解这个环境。 如果我们采取基于策略的强化学习(Policy-based RL)方法,当学习好了这个环境后,在每一个状态,我们都会得到一个最佳的动作。如下图所示,比如我们现在在起点位置,我们知道最佳动作是往右走;在第二格的时候,得到的最佳动作是往上走;第三格是往右走…通过最佳的策略,我们可以最快地到达终点。
如果换成基于价值的强化学习(Value-based RL)方法,利用价值函数作为导向,我们就会得到另外一种表征,每一个状态会返回一个价值。如下图所示,比如我们在起点位置的时候,价值是
−
16
−16
−16,因为我们最快可以16步到达终点。因为每走一步会减1,所以这里的价值是
−
16
−16
−16。 当我们快接近终点的时候,这个数字变得越来越大。在拐角的时候,比如现在在第二格,价值是
−
15
−15
−15,智能体会看上、下两格,它看到上面格子的价值变大了,变成
−
14
−14
−14了,下面格子的价值是
−
16
−16
−16,那么智能体就会采取一个往上走的动作。所以通过学习的价值的不同,我们可以抽取出现在最佳的策略。

模型是一种对环境的反应模式的模拟,或者更一般地说,它允许对外部环境的行为进行推断。例如,给定一个状态和动作,模型就可以预测外部环境的下一个状态和下一个收益。环境模型会被用于做规划。规划,就是在真正经历之前,先考虑未来可能发生的各种情境从而预先决定采取何种动作。使用环境模型和规划来解决强化学习问题的方法被称为有模型的方法。而简单的无模型的方法则是直接地试错,这与有目标地进行规划恰好相反。我们将在后续的文章中中探讨强化学习系统,它可以同时通过试错、学习环境模型并使用模型来进行规划现代强化学习已经从低级的、试错式的学习延展到了高级的、深思熟虑的规划。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022