精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Rank-DETR for High Quality Object Detection
-
论文地址:https://arxiv.org//pdf/2310.08854
-
开源代码(即将开源):https://github.com/LeapLabTHU/Rank-DETR

2.【语义分割】SSG2: A new modelling paradigm for semantic segmentation
-
论文地址:https://arxiv.org//pdf/2310.08671
-
开源代码(即将开源):GitHub - feevos/ssg2: Official code repository for the publication "SSG2: A New Modelling Paradigm for Semantic Segmentation"
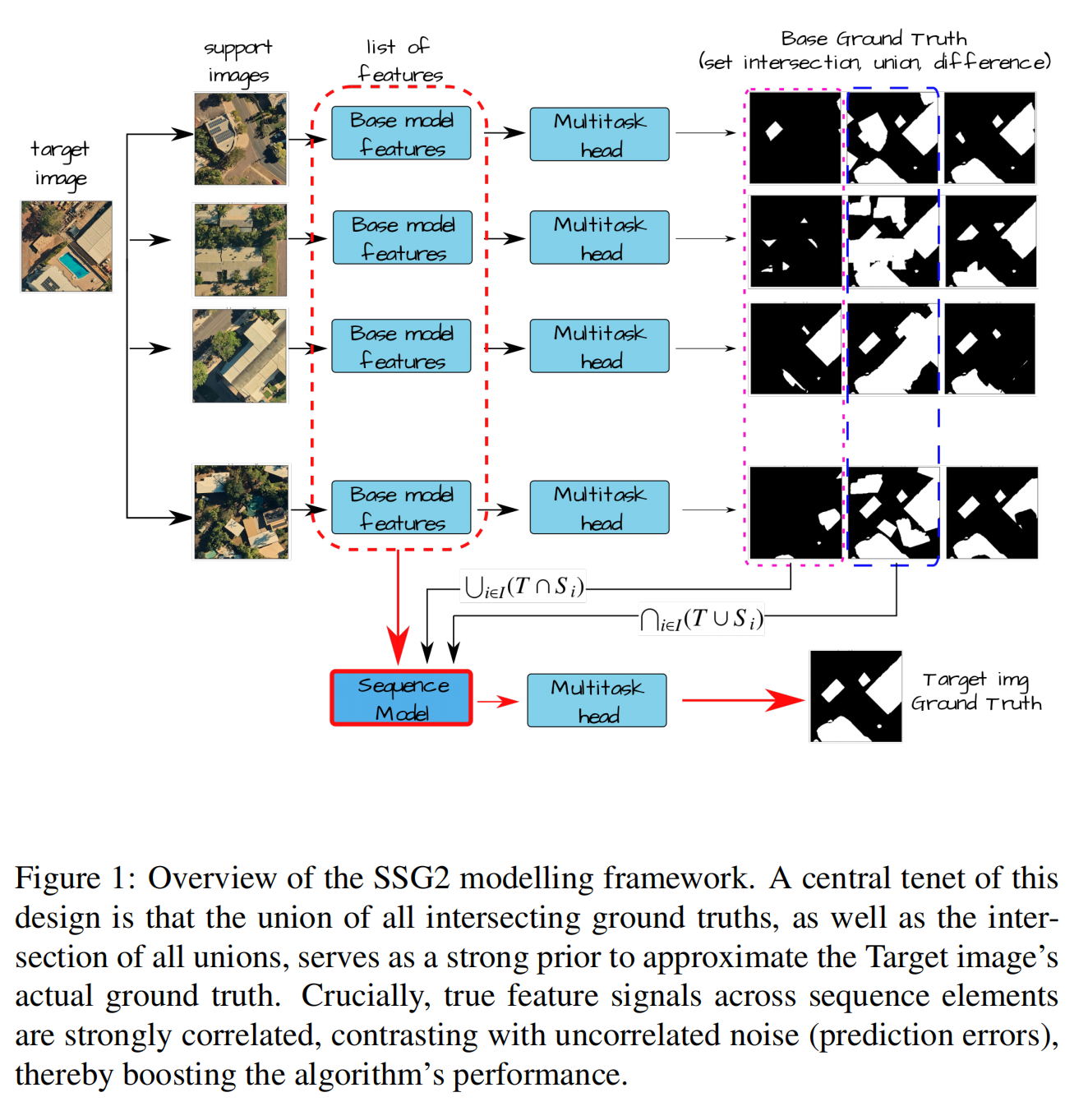
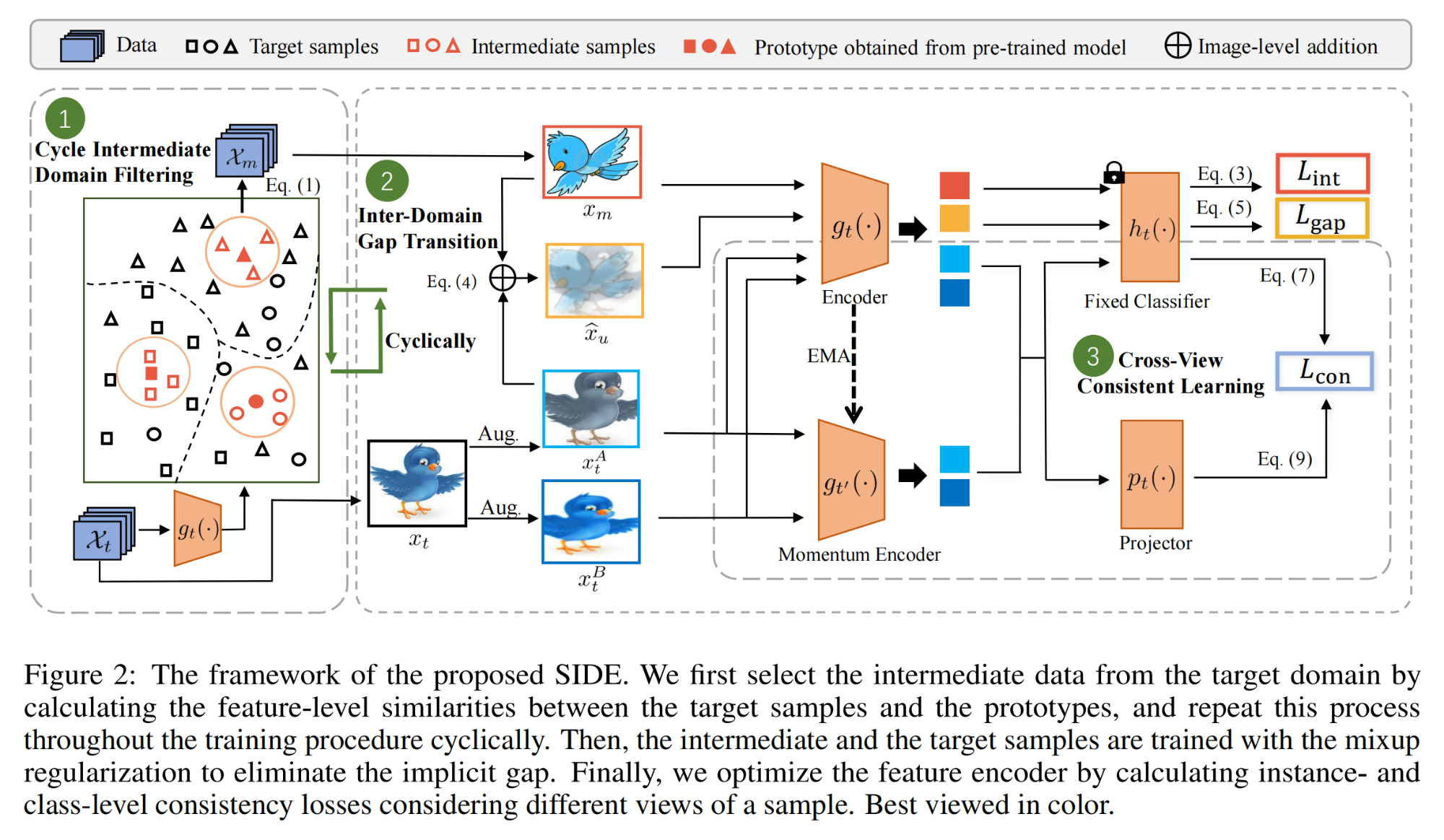
3.【域自适应】SIDE: Self-supervised Intermediate Domain Exploration for Source-free Domain Adaptation
-
论文地址:https://arxiv.org//pdf/2310.08928
-
开源代码:GitHub - se111/SIDE
4.【多模态】Hypernymy Understanding Evaluation of Text-to-Image Models via WordNet Hierarchy
-
论文地址:https://arxiv.org//pdf/2310.09247
-
开源代码:GitHub - yandex-research/text-to-img-hypernymy: Official code for "Hypernymy Understanding Evaluation of Text-to-Image Models via WordNet Hierarchy"

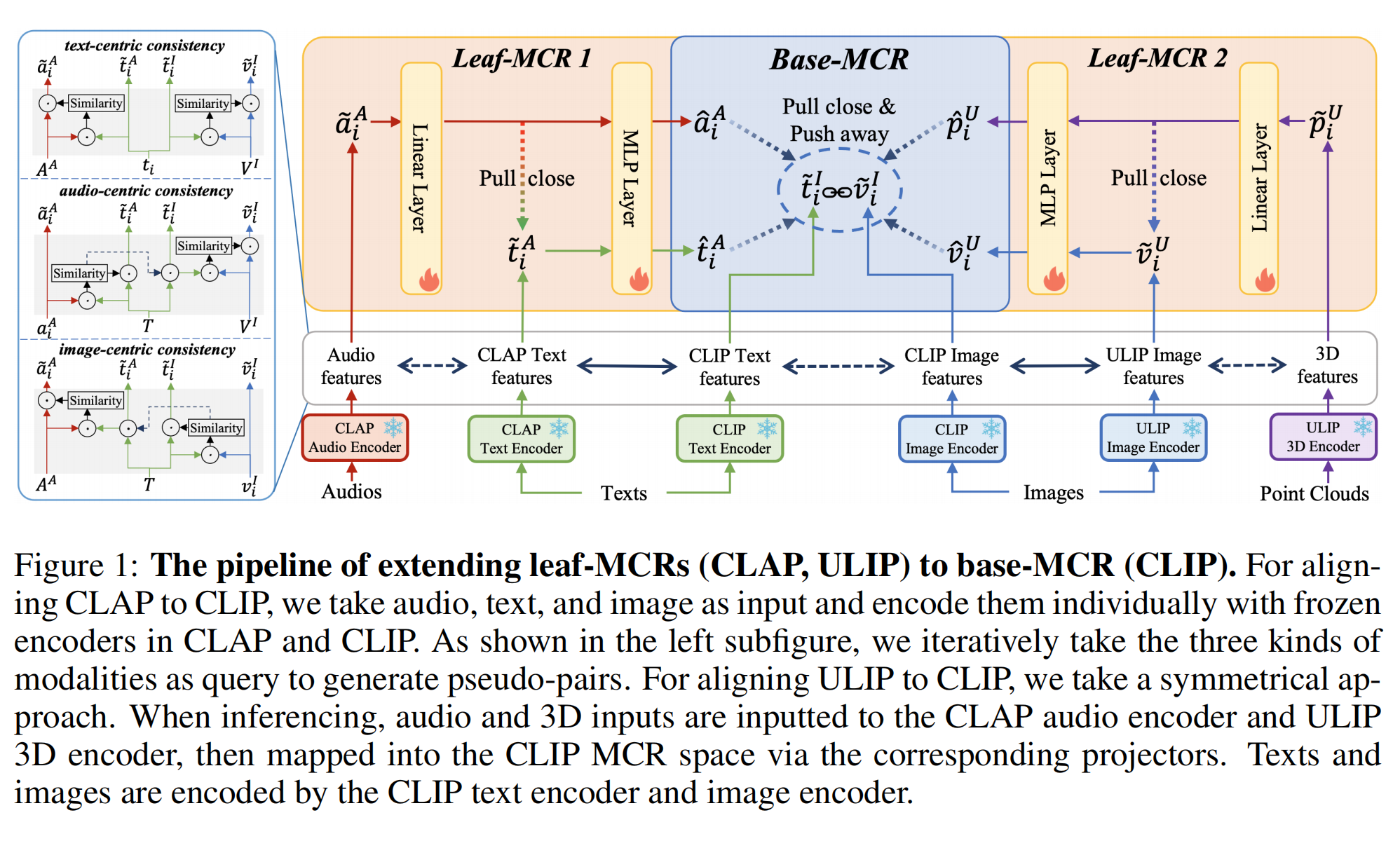
5.【多模态】Extending Multi-modal Contrastive Representations
-
论文地址:https://arxiv.org//pdf/2310.08884
-
开源代码:GitHub - MCR-PEFT/Ex-MCR
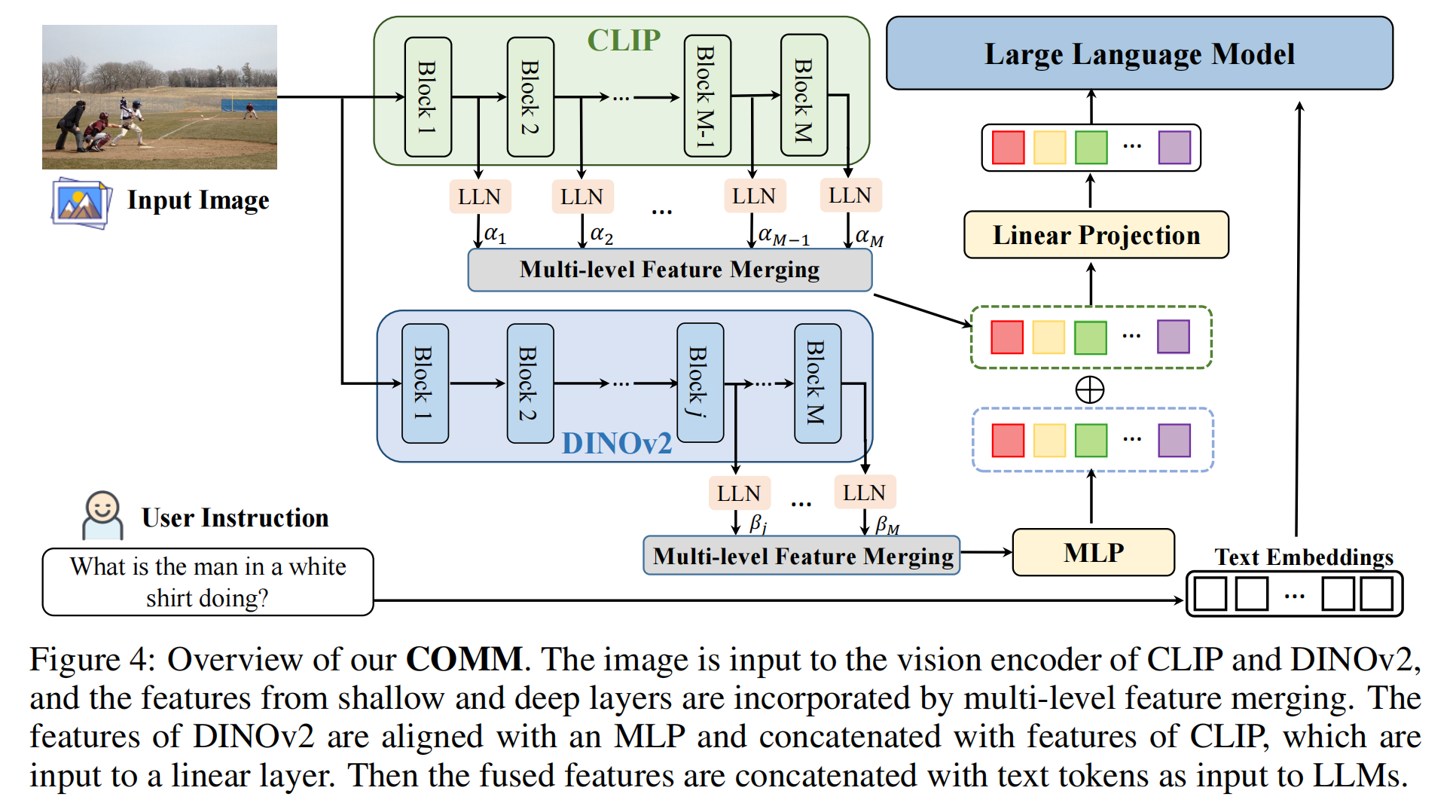
6.【多模态】From CLIP to DINO: Visual Encoders Shout in Multi-modal Large Language Models
-
论文地址:https://arxiv.org//pdf/2310.08825
-
开源代码(即将开源):GitHub - YuchenLiu98/COMM: Pytorch code for paper From CLIP to DINO: Visual Encoders Shout in Multi-modal Large Language Models
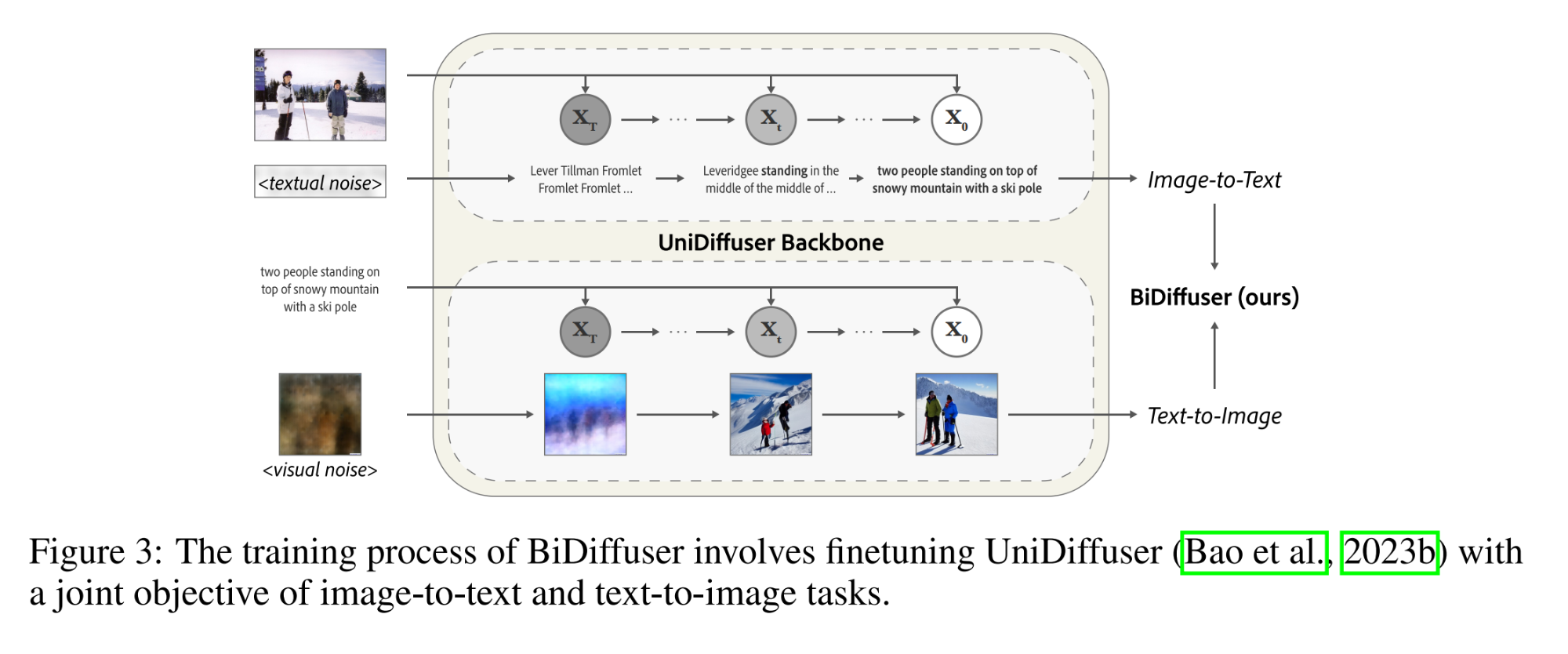
7.【多模态】Making Multimodal Generation Easier: When Diffusion Models Meet LLMs
-
论文地址:https://arxiv.org//pdf/2310.08949
-
开源代码:GitHub - zxy556677/EasyGen: The official code for paper "Making Multimodal Generation Easier: When Diffusion Models Meet LLMs"
8.【GAN】Feature Proliferation -- the "Cancer" in StyleGAN and its Treatments
-
论文地址:https://arxiv.org//pdf/2310.08921
-
开源代码:GitHub - songc42/Feature-proliferation

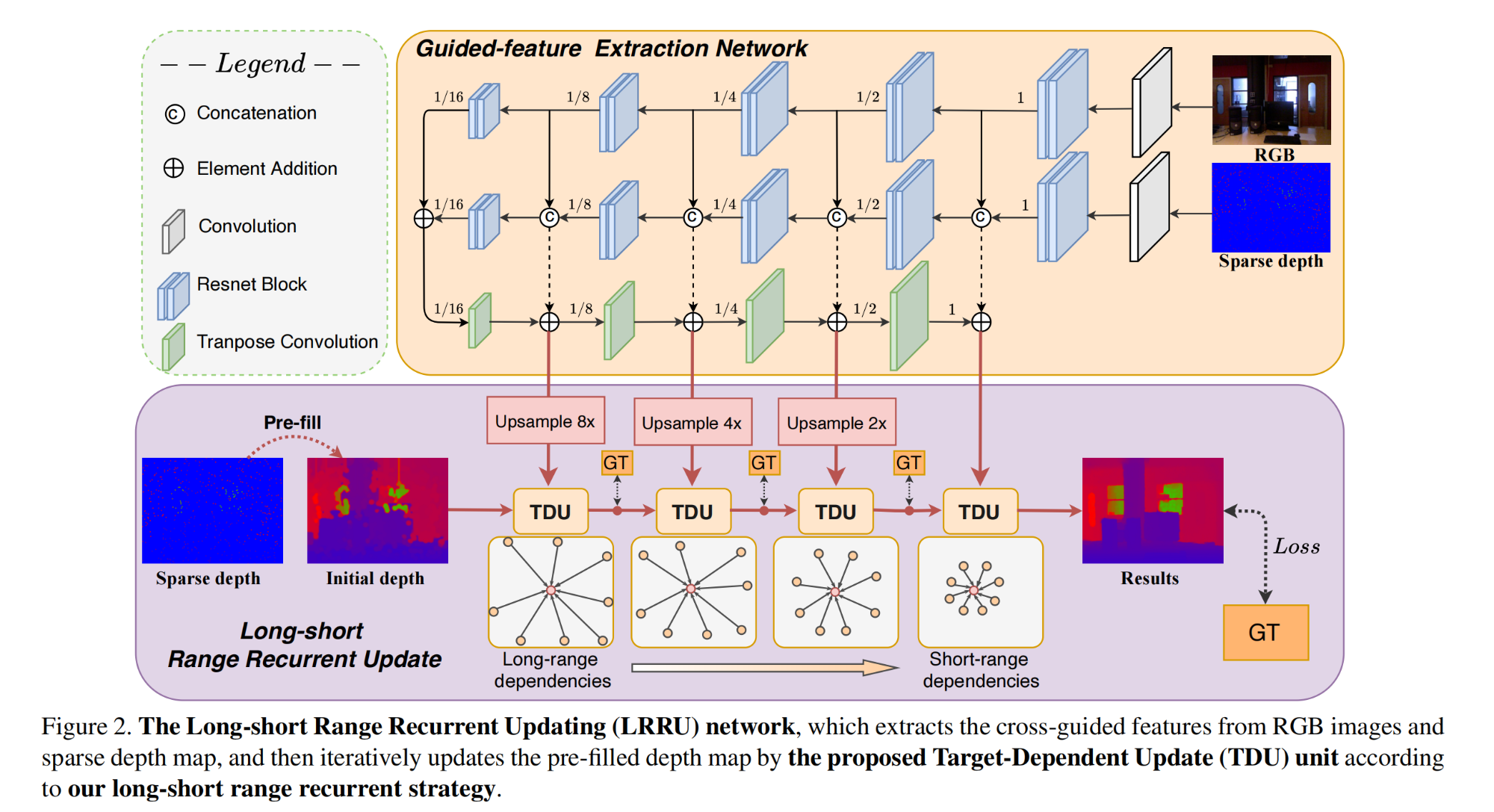
9.【深度补全】LRRU: Long-short Range Recurrent Updating Networks for Depth Completion
-
论文地址:https://arxiv.org//pdf/2310.08956
-
工程主页:LRRU: Long-short Range Recurrent Updating Networks for Depth Completion
-
开源代码(即将开源):GitHub - YufeiWang777/LRRU: Official implementation of ``LRRU: Long-short Range Recurrent Updating Networks for Depth Completion'', ICCV 2023.
论文已打包,点击进入—>下载界面
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
港科大提出适用于夜间场景语义分割的无监督域自适应新方法
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
EViT:借鉴鹰眼视觉结构,南开大学等提出ViT新骨干架构,在多个任务上涨点
如何优雅地读取网络的中间特征?
CV计算机视觉每日开源代码Paper with code速览-2023.10.13
CV计算机视觉每日开源代码Paper with code速览-2023.10.12
CV计算机视觉每日开源代码Paper with code速览-2023.10.11
CV计算机视觉每日开源代码Paper with code速览-2023.10.10






![2023年中国铝压延产量、销售收入及市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/3345b57e70a57a130acb62b47d9a76fc.png)
![2023年中国乳胶制品产量、需求量及市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/e829c59e22c472301c9226ba973f5a2d.png)