Hello,大家好!这里是Token的博客,欢迎您的到来
今天整理的笔记时数据挖掘方向的基础入门,了解数据分析使用的一些基础的Python库,为后面的数据处理做好准备
01-数据分析工具介绍
准备:Python的安装、平台搭建、使用、入门
python的基础使用:运行方式、基本命令、数据结构、库的导入与添加安装
1、数据分析工具介绍
Python本身的数据分析功能不强,需要安装一些第三方扩展库来增强它的能力。本次讲解用到的库有Numpy、Scipy、Matplotlib、Pandas、Scikit-Learn、Keras、Gensim等,下面将对这些库的安装和使用进行简单的介绍。

安装讲解
- pip 安装
pip install 库名
- 下载源码后python setup.py install安装

注:很多库有着依赖需求,在安装目标库之前可能需要安装一些依赖库,注意安装顺序。
1-1 Numpy
-
Python并没有提供数组功能。虽然列表可以完成基本的数组功能,但它不是真正的数组,而且在数据量较大时,使用列表的速度就会慢得难以接受。
-
为此,Numpy提供了真正的数组功能,以及对数据进行快速处理的函数。Numpy还是很多更高级的扩展库的依赖库,我们后面介绍的Scipy、Matplotlib、Pandas等库都依赖于它。值得强调的是,Numpy内置函数处理数据的速度是C语言级别的,因此在编写程序的时候,应当尽量使用它们内置的函数,避免效率瓶颈的现象(尤其是涉及到循环的问题)。
代码演示:
import numpy as np # 一般以np作为Numpy库的别名
a = np.array([2,0,1,5]) # 创建数组
print(a) # 输出数组
print(a[:3])# 引用前三个数字(切片)
print(a.min())# 输出a的最小值
a.sort() # 将a的元素从大到小排序,此操作直接修改a,因此这时候a为[0,1,2,5]
b = np.array([[1,2,3],[4,5,6]]) # 创建二维数组
print(b*b) # 输出数组的平方阵,即[[1,4,9],[16,25,36]]
1-2 Scipy
-
Numpy提供了多维数组功能,但它只是一般的数组,并不是矩阵,比如当两个数组相乘时,只是对应元素相乘,而不是矩阵乘法。Scipy提供了真正的矩阵,以及大量基于矩阵运算的对象与函数。
-
SciPy包含的功能有最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算,显然,这些功能都是挖掘与建模必备的。
注:Scipy依赖于Numpy,因此安装它之前得先安装好Numpy。
代码:
import numpy as np
from scipy.optimize import fsolve
from scipy.integrate import quad
# 定义一个包含非线性方程组的函数
def nonlinear_equations(x):
# 方程组1:x^2 + y^2 - 1 = 0
eq1 = x[0]**2 + x[1]**2 - 1
# 方程组2:x^2 - 2*y = 0
eq2 = x[0]**2 - 2*x[1]
return [eq1, eq2]
# 使用fsolve来解决非线性方程组
initial_guess = [1.0, 1.0] # 初始猜测值
solution = fsolve(nonlinear_equations, initial_guess)
print("非线性方程组的解:", solution)
# 定义一个要积分的函数
def integrand(x):
return x**2
# 使用quad函数进行数值积分
integral_result, error = quad(integrand, 0, 1)
print("数值积分结果:", integral_result)
1-3 Matplotlib
- Matplotlib是最著名的绘图库,它主要用于二维绘图,当然它也可以进行简单的三维绘图。它不仅提供了一整套和Matlab相似但更为丰富的命令,让我们可以非常快捷地用Python可视化数据,而且允许输出达到出版质量的多种图像格式。
注意:Matplotlib的上级依赖库相对较多,手动安装的时候,需要逐一把这些依赖库都安装好。

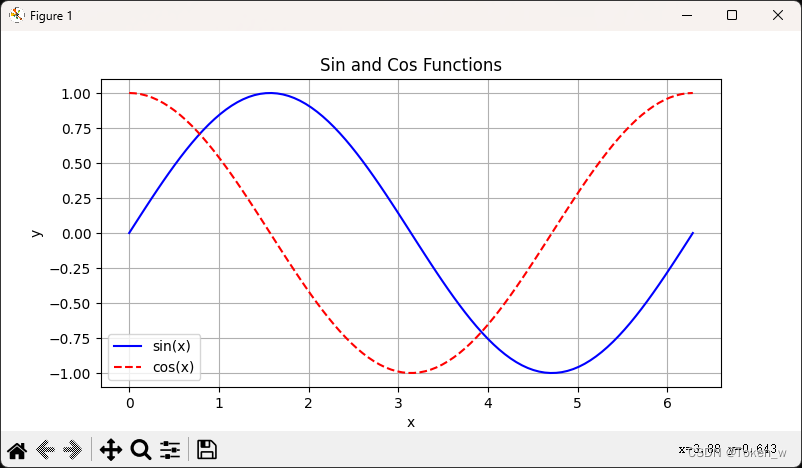
上图是Matplotlib在编程中可能遇见的问题,中文标签无法显示、保存图像时负号无法显示
代码:
import matplotlib.pyplot as plt
import numpy as np
# 生成一些示例数据
x = np.linspace(0, 2 * np.pi, 100) # 生成从0到2π的100个数据点
y1 = np.sin(x) # 计算正弦函数
y2 = np.cos(x) # 计算余弦函数
# 创建一个新的图形
plt.figure(figsize=(8, 4)) # 指定图形的大小
# 绘制正弦函数
plt.plot(x, y1, label='sin(x)', color='blue', linestyle='-')
# 绘制余弦函数
plt.plot(x, y2, label='cos(x)', color='red', linestyle='--')
# 添加标题和标签
plt.title('Sin and Cos Functions')
plt.xlabel('x')
plt.ylabel('y')
# 添加图例
plt.legend()
# 显示网格线
plt.grid(True)
# 显示图形
plt.show()
1-4 Pandas
-
Pandas是Python下最强大的数据分析和探索工具(貌似没有之一)。它包含高级的数据结构和精巧的工具,使得在Python中处理数据非常快速和简单。Pandas建造在NumPy之上,它使得以NumPy为中心的应用很容易使用。Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis),它最初被作为金融数据分析工具而开发出来,由AQR Capital Management于2008年4月开发,并于2009年底开源出来。
-
Pandas的功能非常强大,支持类似SQL的数据增、删、查、改,并且带有丰富的数据处理函数;支持时间序列分析功能;支持灵活处理缺失数据;等等。
-
Pandas的安装相对来说比较容易一些,只要安装好Numpy之后,就可以直接安装了,
-
由于我们频繁用到读取和写入Excel,但默认的Pandas还不能读写Excel文件,需要安装xlrd(读)和xlwt(写)库才能支持Excel的读写:
pip install xlrd #为Python添加读取Excel的功能 pip install xlwt #为Python添加写入Excel的功能pandas的使用,注意基本的数据格式,了解何为serries和dataframe,这两个数据结构在后面数据处理中经常遇见。

代码:
import pandas as pd # 从CSV文件加载数据 df = pd.read_csv('student_scores.csv') # 查看前5行数据 print(df.head()) # 查看数据的基本统计信息 print(df.describe()) # 筛选数学成绩大于等于70的学生 math_pass = df[df['数学成绩'] >= 70] # 筛选英语成绩大于等于70的学生 english_pass = df[df['英语成绩'] >= 70] # 查看数学和英语都及格的学生 math_and_english_pass = pd.merge(math_pass, english_pass, on='姓名', how='inner') # 计算数学和英语都及格的学生人数 num_math_and_english_pass = len(math_and_english_pass) print(f"数学和英语都及格的学生人数:{num_math_and_english_pass}") # 创建一个直方图来可视化数学成绩分布 df['数学成绩'].plot(kind='hist', bins=10, edgecolor='k') plt.title('Math Score Distribution') plt.xlabel('Math Score') plt.ylabel('Frequency') plt.show()
1-5 StatsModels
-
Pandas着眼于数据的读取、处理和探索,而StatsModels则更加注重数据的统计建模分析,它使得Python有了R语言的味道。StatsModels支持与Pandas进行数据交互,因此,它与Pandas结合,成为了Python下强大的数据挖掘组合。
-
安装StatsModels相当简单,既可以通过pip安装,又可以通过源码安装,对于Windows用户来说,官网上甚至已经有编译好的exe文件供下载。如果手动安装的话,需要自行解决好依赖问题,StatModel依赖于Pandas(当然也依赖于Pandas所依赖的),同时还依赖于pasty(一个描述统计的库)。
代码:
import pandas as pd
import numpy as np
import statsmodels.api as sm
# 创建一个示例时间序列
np.random.seed(0)
data = np.random.randn(100) # 随机生成一个长度为100的时间序列
# 将时间序列转换为Pandas DataFrame
df = pd.DataFrame({'Data': data})
# 进行ADF平稳性检验
result = sm.tsa.adfuller(df['Data'])
# 提取ADF检验结果的关键信息
adf_statistic, p_value, used_lag, nobs, critical_values, icbest = result
# 输出ADF检验的结果
print("ADF统计量:", adf_statistic)
print("P值:", p_value)
print("使用的滞后阶数:", used_lag)
print("观测样本数:", nobs)
print("关键值:")
for key, value in critical_values.items():
print(f" {key}: {value}")
# 判断是否平稳
if p_value < 0.05:
print("根据ADF检验,时间序列是平稳的")
else:
print("根据ADF检验,时间序列不是平稳的")
1-6 scikit-learn
-
Scikit-Learn是Python下强大的机器学习工具包,它提供了完善的机器学习工具箱,包括数据预处理、分类、回归、聚类、预测、模型分析等。
-
Scikit-Learn依赖于NumPy、SciPy和 Matplotlib,因此,只需要提前安装好这几个库,然后安装Scikit-Learn就基本上没有什么问题了,要不就是pip install scikit-learn安装,要不就是下载源码自己安装。
代码:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 生成示例数据
np.random.seed(0)
X = 2 * np.random.rand(100, 1) # 特征
y = 4 + 3 * X + np.random.randn(100, 1) # 目标
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
print("均方误差 (MSE):", mse)
上面示例代码中首先生成了一个简单的线性回归问题的示例数据。然后,使用train_test_split将数据分成训练集和测试集。接下来,创建了一个线性回归模型,使用训练数据拟合了模型,然后用测试数据进行了预测。最后,使用均方误差(MSE)来评估模型的性能。
1-7 Keras
-
人工神经网络是功能相当强大的、但是原理又相当简单的模型,在语言处理、图像识别等领域都有重要的作用。近年来逐渐火起来的“深度学习”算法,本质上也就是一种神经网络
-
Keras并非简单的神经网络库,而是一个基于Theano的强大的深度学习库,利用它不仅仅可以搭建普通的神经网络,还可以搭建各种深度学习模型,如自编码器、循环神经网络、递归神经网络、卷积神经网络等等。由于它是基于Theano的,因此速度也相当快。
-
安装Keras之前首先需要安装Numpy、Scipy、Theano。安装Theano首先需要准备一个C++编译器,这在Linux下是自带的。因此,在Linux下安装Theano和Keras都非常简单,只需要下载源代码,然后用python setup.py install安装就行了,具体可以参考官方文档。
注:一般而言是先安装MinGW(Windows下的GCC和G++),然后再安装Theano(提前装好Numpy等依赖库),最后安装Keras,如果要实现GPU加速,还需要安装和配置CUDA(天下没有免费的午餐,想要速度、易用两不误,那么就得花点心思)。值得一提的是,在Windows下的Keras速度会大打折扣,因此,想要在神经网络、深度学习做更深入研究的读者,请在Linux下搭建相应的环境。
- 使用,还是比较简单的


代码:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from sklearn.model_selection import train_test_split
# 生成示例数据
np.random.seed(0)
X = np.random.rand(1000, 10) # 10个特征
y = np.random.randint(2, size=1000) # 二分类标签
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建MLP模型
model = Sequential()
# 添加输入层和隐藏层
model.add(Dense(units=64, input_dim=10, activation='relu'))
# 添加输出层
model.add(Dense(units=1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.001), metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 评估模型性能
loss, accuracy = model.evaluate(X_test, y_test)
print(f"测试集上的损失:{loss}")
print(f"测试集上的准确率:{accuracy}")
首先生成了一个二分类任务的示例数据,然后使用train_test_split将数据分为训练集和测试集。接下来,创建了一个Sequential模型,该模型包含一个输入层、一个隐藏层和一个输出层。然后使用Dense层添加神经元,并指定激活函数。然后使用compile方法编译模型,指定损失函数和优化器。最后,使用fit方法来训练模型,并使用evaluate方法评估模型的性能。
1-8 Gensim
-
Gensim是用来处理语言方面的任务,如文本相似度计算、LDA、Word2Vec等,这些领域的任务往往需要比较多的背景知识。
-
需要一提的是,Gensim把Google在2013年开源的著名的词向量构造工具Word2Vec编译好了,作为它的子库,因此需要用到Word2Vec的读者也可以直接用Gensim而无需自行编译了。据说Gensim的作者对Word2Vec的代码进行了优化,所以它在Gensim下的表现据说比原生的Word2Vec还要快。(为了实现加速,需要准备C++编译器环境,因此,建议用到Gensim的Word2Vec的读者在Linux下环境运行。)
代码:
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
# 示例文本数据
sentences = [
"I like to learn Python programming.",
"Word2Vec is an interesting tool for NLP.",
"Gensim provides Word2Vec implementation.",
"Python is a popular programming language.",
"Natural Language Processing (NLP) is fun.",
]
# 分词并构建训练数据
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
# 训练 Word2Vec 模型
model = Word2Vec(tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# 保存模型
model.save("word2vec.model")
# 加载模型
# model = Word2Vec.load("word2vec.model")
# 获取词向量
vector = model.wv['python']
# 找到与给定词最相似的词
similar_words = model.wv.most_similar('programming', topn=5)
# 输出结果
print("词向量 'python':", vector)
print("与 'programming' 最相似的词:", similar_words)
ec(tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# 保存模型
model.save("word2vec.model")
# 加载模型
# model = Word2Vec.load("word2vec.model")
# 获取词向量
vector = model.wv['python']
# 找到与给定词最相似的词
similar_words = model.wv.most_similar('programming', topn=5)
# 输出结果
print("词向量 'python':", vector)
print("与 'programming' 最相似的词:", similar_words)