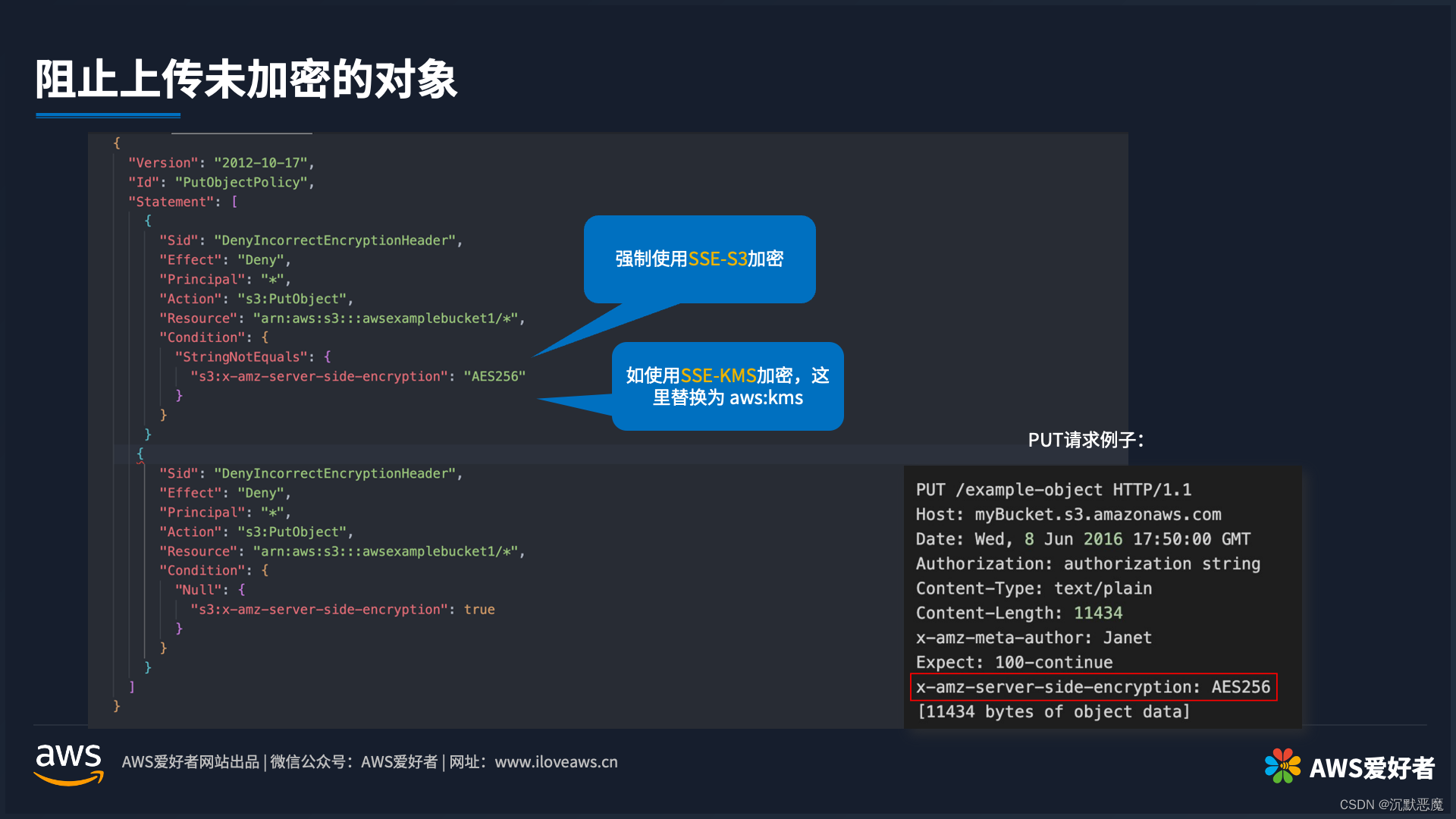
一、常见的数据结构
数组,栈,队列,链表,散列表,二叉树,堆,跳表,图,树。
1. 数组:
数组的元素在内存中存储是连续存放的,占有连续的存储单元(连续的内存空间);且容量固定(定容);只能存储一种类型的数据;添加、删除操作慢,因为要移动其他元素(提供随机访问,但插入删除操作慢)。
访问的时间复杂度:O(1);
插入/删除的时间复杂度:O(n)。
2. 栈:
后进先出,栈顶入栈,栈顶出栈。栈常应用于实现递归功能方面的场景,如斐波那契数列。
栈常由一维数组或链表表示,分别叫做顺序栈和链式栈。
不同的出栈排列个数:

常用的操作有:入栈push,出栈pop。
访问的时间复杂度:O(n)(最坏);
插入/删除的时间复杂度:O(1)。
应用:浏览器的倒退和前进;检查符号是否成对出现(如果是左括号就直接push到stack中,否则将stack的栈顶元素与该括号做比较,不相等就直接返回false);翻转字符串;维护函数调用等。
3. 队列:
先进先出,在多线程阻塞队列管理中非常适用。
队列用数组或链表实现,分别叫做顺序队列和链式队列。
单队列:顺序队列(由数组实现,会出现假溢出现象)和链式队列。
循环队列:解决假溢出和越界问题。循环队列判断队满的常用方法是①设置flag标志位;②使用一个空闲位。
双端队列:元素可以从队头出队和入队,也可以从队尾出队和入队。
优先队列:由堆实现。
访问的时间复杂度:O(n)(最坏);
插入/删除的时间复杂度:O(1)。
4.链表:
物理存储单元上非连续的,非顺序的存储结构;每个元素包含两个节点:数据域和指针域;不需要初始化容量,可以任意加减元素,只需要改变前后2个元素节点的指针域指向地址即可。
5. 散列表(哈希表):
根据键(key)而直接访问在内存存储位置的数据结构。

6. 非线性数据结构——图:
图的存储使用:①邻接矩阵:二维矩阵,如A[i][j]=n(权值)或者A[i][j]=0/1,无线图的邻接矩阵是对称矩阵。邻接矩阵比较浪费空间。
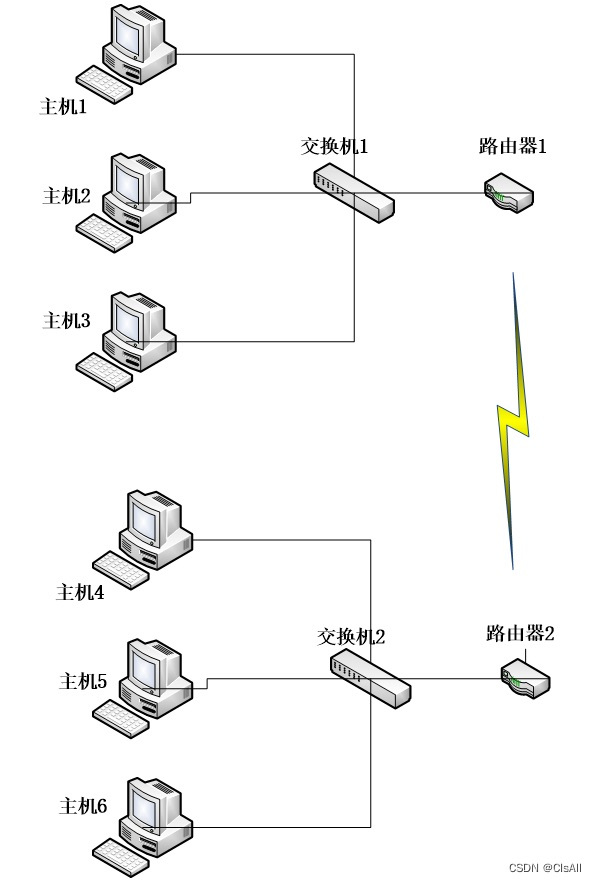
②邻接表:如下图所示,在无向图中,邻接表元素的个数=边的条数*2;在有向图中,邻接表元素的个数=边的条数。

7. 非线性数据结构——堆:
堆不一定是完全二叉树,任意一个节点的值都 ≥(或≤)所有子节点的值,堆通常用数组表示。
堆的插入和删除效率高,时间复杂度是O(logn),初始化的时间复杂度是O(n)。
若根据节点的序号为1,那么树中任意节点 i,其左子节点序号为 2i,右子节点为 2i+1。
①自底向上堆化:会产生“气泡”浪费存储空间,用于插入元素,即先将元素放至数组末尾,上浮。
②自顶向下堆化:用于删除堆顶元素,将末尾元素放至堆顶,再向下堆化,下沉。
8. 非线性数据结构——树:
n个节点,n-1条边。
高度:该节点到叶子节点的最长路径所包含的边数。
深度:根节点到该节点的路径所包含的边数。
层数:节点的深度+1。
二叉树(链式存储或顺序存储):第 i 层至多有 2^(i-1) 个节点,深度为k的二叉树至多共有 2^(k+1)-1 个节点(满二叉树),至少共有 2^k 个节点。
平衡二叉树:空或者左右子树的高度差绝对值不超过1,且左右子树都是一颗平衡二叉树。
红黑树:每个节点非红即黑,根节点是黑色节点,叶节点都是黑色的空节点。
二、常用算法
递归,排序,二分查找,搜索,哈希算法,分治算法,动态规划,字符串匹配算法等。