🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、项目介绍
二、数据集介绍
三、实验过程
3.1导入数据()
3.2数据预处理
3.3数据可视化
3.4词云图分析
3.5情感分析
四、总结
五、文末推荐与福利
源代码
一、项目介绍
在本次实验中,我们采用了先进的文本挖掘和数据分析技术,对京东平台上MatePad11的用户评论进行了全面深入的分析。通过使用Python编程语言,我们首先实现了自动化爬取用户评论的关键信息,并将这些数据进行了预处理。
预处理阶段,我们采用了自然语言处理技术,对文本进行了清洗、分词、词性标注等操作,为后续的数据分析奠定了基础。此外,我们还运用了情感分析算法,对用户评论的情感倾向进行了自动分类,以便更好地把握用户对该产品的态度和感受。
在进行数据预处理之后,我们进一步对用户评论数据进行了可视化分析。通过使用数据可视化工具和技术,我们将用户评论数据呈现为直观的图形和图表,包括条形图、饼图、词云图等。这些图形和图表不仅可以帮助我们快速了解用户评论的整体情况,还能够发现产品特点、用户需求以及口碑趋势等方面的信息。
在词云图分析方面,我们采用了基于文本的词频分析方法,对用户评论中出现的关键词进行了统计和分析。通过构建词云图,我们能够以更加直观的方式展示出用户评论中提及的关键词的分布情况,进而分析出该产品的特点以及用户的关注点。这些信息对于企业制定有针对性的营销策略具有重要意义。
在情感分析方面,我们运用了基于机器学习的文本分类技术,将用户评论按照情感倾向分为正面、负面和中性三类。通过情感分析,我们可以了解到用户对产品的真实感受和态度,从而为企业提供改进产品、优化服务和制定营销策略等方面的依据。
二、数据集介绍
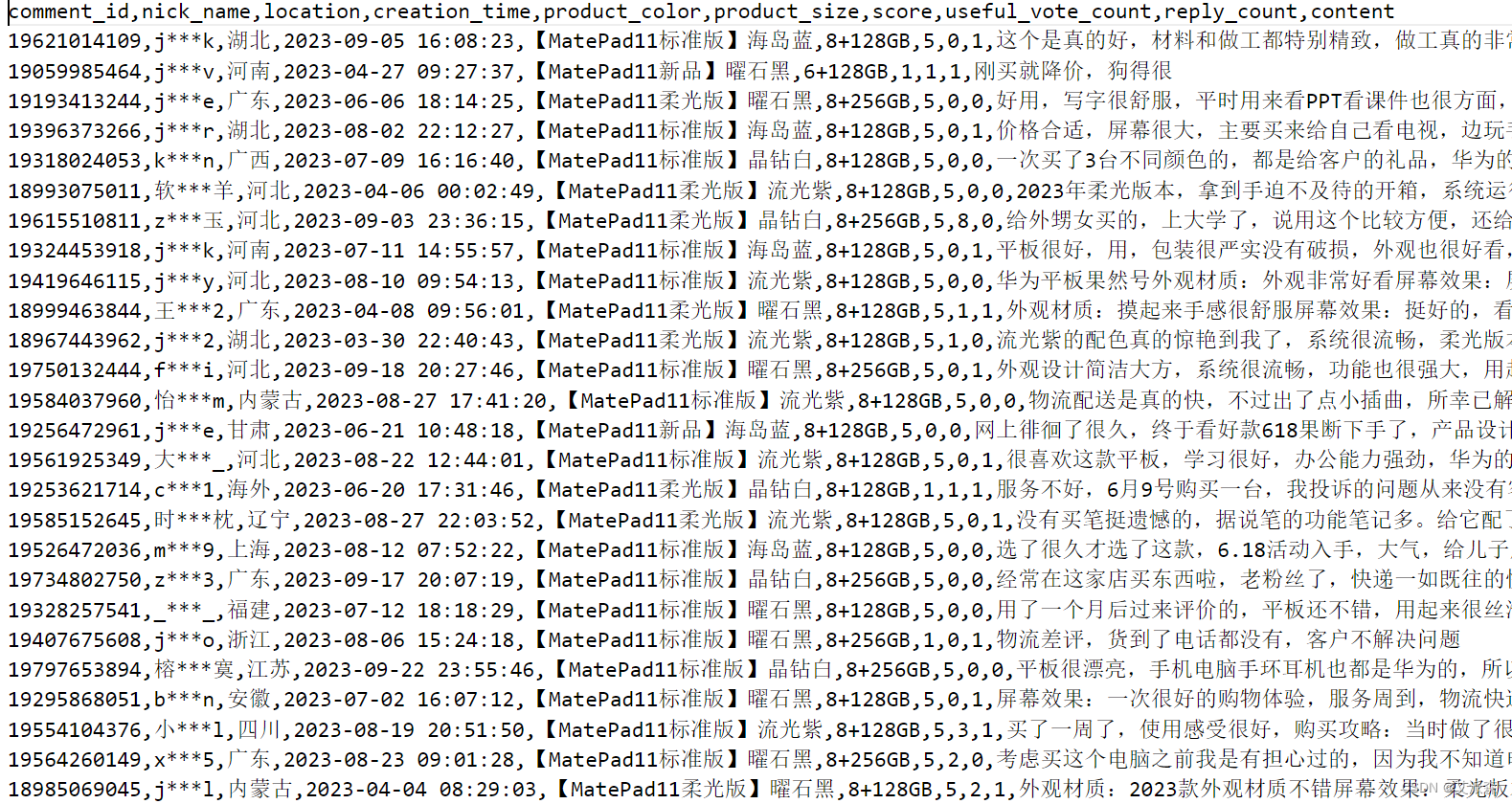
本数据集来源于京东上MatePad11的用户评论数据,共有1300条,10列变量,各变量的含义如下:
comment_id:评论ID
nick_name:用户昵称
location:IP地址
creation_time:评论的时间
product_color:产品的颜色
product_size:产品的内存大小
score:评价分值
useful_vote_count:评论的点赞量
reply_count:评论的回复量
content:评论内容
三、实验过程
3.1导入数据
首先导入本次实验用到的第三方库,并加载数据集,查看前两条数据

查看数据大小

查看数据基本信息

查看数值型变量的描述性统计

查看非数值型变量的描述性统计

3.2数据预处理
首先统一各变量的缺失值情况,发现并不存在缺失值

检测数据是否存在重复值

删除重复值



上面我们发现产品颜色中其实还包括了产品的型号和颜色,于是我们可以将其拆解为两个变量,然后将评论时间转为时间类型数据。

3.3数据可视化
1.不同颜色的产品购买数量

从图中可以看出曜石黑的销量远领先于其他颜色,而海岛蓝的销量最低。
2.不同内存大小的产品购买数量

从图中可看出8+128GB的销量是远远领先于其他两种型号的产品,可见企业在生产产品的时候需进行一个合理的分配,迎合消费市场的需求。
3.最近一段时间内产品的评论数量

4.不同颜色产品的平均得分

5.不同型号产品的平均得分

3.4词云图分析
词云图是一种可视化工具,通过颜色和大小不同的字体来呈现文本数据中出现频率较高的词汇,常用于文本挖掘和数据分析。以下是词云图分析的优点和缺点:
优点:
- 应用范围广:词云图可以应用于各种文本数据,包括报告、演讲稿、新闻报道、会议总结等,同时可以嵌入PPT、论文等文档中,展示文本的主题和重点。
- 制作简单:随着数据可视化技术的不断发展,现在有很多在线制图软件可以制作词云图,如微词云、镝数图表、图表秀等,制作过程简单方便。
- 内容直接:词云图通过不同的颜色和大小来区分不同的词汇,让读者可以快速地了解到文本的主题和重点,并且可以通过颜色和大小的变化来呈现词汇的重要程度。
- 趣味性强:相比于传统的柱状图、折线图等,词云图更加美观、有趣,能够吸引读者的注意力,同时可以根据不同的主题和需求来调整词云形状、用颜色表达情感倾向等,使其更具趣味性。
缺点:
- 信息缺失:虽然词云图可以展示文本中高频词汇的出现情况,但是对于低频词汇的展示不够明显或者遗漏,因此可能会造成信息缺失的问题。
- 缺乏逻辑:词云图通过单个词汇的出现频率来呈现信息,但有时候缺乏逻辑联系,难以表达完整的内容主题。需要读者通过主观理解来给词汇填充合理的叙述逻辑。
这里我们首先定义一个画词云图的函数

接着调用函数,将评论内容传入


3.5情感分析
Snownlp是一个基于Python的自然语言处理库,能够处理中文文本内容。其中,情感分析是Snownlp的一个重要应用。
情感分析是指对文本所表达出的情感进行分析和判断,并从中提取有用信息的过程。Snownlp情感分析的功能包括:针对中文文本进行情感判断,识别出文本的情感极性(正面、负面、中性),以及情感强度的量化(如0~1之间的数值表示情感的强烈程度)。这些功能可以帮助企业和政府决策者了解用户对某个主题、产品或事件的情感态度,从而做出更为精准的决策。
使用Snownlp进行情感分析的过程包括以下步骤:
- 安装Snownlp库:在命令行中使用pip命令安装snownlp库。
- 导入Snownlp库:在Python脚本中导入snownlp模块。
- 准备文本数据:收集需要进行情感分析的文本数据,可以是一段文字、一篇新闻报道等。
- 使用Snownlp进行情感分析:使用snownlp的函数和方法对文本数据进行情感分析,可以得到文本的情感极性以及情感强度的量化值。
- 可视化分析结果:将分析结果以图表或表格的形式呈现,方便决策者快速了解用户的情感态度。
在安装了之后,直接调用sentiments方法即可,然后根据得到的情感分值我们定义0.6以上的为积极,0.2~0.6为中性,0.2以下为消极。

接着将情感分析的结果进行可视化


接着,我们将积极、中性、消极的评论进行词云图可视化




从积极评论词云图中,我们可以发现产品的外观、运行速度得到了消费者的充分肯定;中性和消极评论词云图结果比较相似,重点都是价格的问题,究其原因是消费者在买了产品后,发现产品进行了降价进而导致了不满的情绪。
四、总结
综上所述,本次实验通过使用Python爬取、数据预处理、数据可视化、词云图分析和情感分析等技术手段,全面挖掘了京东平台上MatePad11用户评论的关键信息。这些数据分析结果对于企业及时调整营销策略、了解用户需求以及评估产品的口碑等方面都具有重要的指导意义。同时,这些技术方法不仅适用于本次实验中的MatePad11用户评论分析,还可以广泛应用于其他领域的数据挖掘和分析工作。
通过本次实验的分析结果,企业可以制定更加精准的营销策略,以更好地满足目标客户的需求。例如,针对MatePad11的本次实验结果,企业可以考虑以下营销策略:优化产品的某些特点或功能;推出针对性强的广告宣传;调整价格策略以吸引更多用户购买;加强售后服务以提高用户满意度等。
此外,对于新产品开发的企业来说,通过本次实验的分析结果可以更好地了解用户需求和市场趋势,从而以用户需求为导向设计开发新产品。这将有助于提高新产品的市场竞争力,帮助企业在激烈的市场竞争中获得更大的市场份额。
总之,通过本次实验的应用,企业可以获得宝贵的用户评论数据分析和挖掘经验。这些经验不仅有助于提高企业的营销效果和产品开发能力,还能够帮助企业更好地了解用户需求和市场趋势,从而在激烈的市场竞争中立于不败之地。
五、文末推荐与福利
《Python数据挖掘:入门、进阶与实用案例分析》免费包邮送出3本!

内容简介:
这是一本以项目实战案例为驱动的数据挖掘著作,它能帮助完全没有Python编程基础和数据挖掘基础的读者快速掌握Python数据挖掘的技术、流程与方法。
在写作方式上,本书与传统的“理论与实践结合”的入门书不同,它以数据挖掘领域的知名赛事“泰迪杯”数据挖掘挑战赛(已举办10届)和“泰迪杯”数据分析技能赛(已举办5届)(累计1500余所高校的10余万师生参赛)为依托,精选了11个经典赛题,将Python编程知识、数据挖掘知识和行业知识三者融合,让读者在实践中快速掌握电商、教育、交通、传媒、电力、旅游、制造等7大行业的数据挖掘方法。本书不仅适用于零基础的读者自学,还适用于教师教学,为了帮助读者更加高效地掌握本书的内容,本书提供了以下10项附加价值:
(1)建模平台:提供一站式大数据挖掘建模平台,免配置,包含大量案例工程,边练边学,告别纸上谈兵
(2)视频讲解:提供不少于600分钟Python编程和数据挖掘相关教学视频,边看边学,快速收获经验值
(3)精选习题:精心挑选不少于60道数据挖掘练习题,并提供详细解答,边学边练,检查知识盲区
(4)作者答疑:学习过程中有任何问题,通过“树洞”小程序,纸书拍照,一键发给作者,边问边学,事半功倍
(5)数据文件:提供各个案例配套的数据文件,与工程实践结合,开箱即用,增强实操性
(6)程序代码:提供书中代码的电子文件及相关工具的安装包,代码导入平台即可运行,学习效果立竿见影
(7)教学课件:提供配套的PPT课件,使用本书作为教材的老师可以申请,节省备课时间
(8)模型服务:提供不少于10个数据挖掘模型,模型提供完整的案例实现过程,助力提升数据挖掘实践能力
(9)教学平台:泰迪科技为本书提供的附加资源提供一站式数据化教学平台,附有详细操作指南,边看边学边练,节省时间
(10)就业推荐:提供大量就业推荐机会,与1500+企业合作,包含华为、京东、美的等知名企业
通过学习本书,读者可以理解数据挖掘的原理,迅速掌握大数据技术的相关操作,为后续数据分析、数据挖掘、深度学习的实践及竞赛打下良好的技术基础。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-10-18 20:00:00
京东购买链接:https://item.jd.com/13814157.html
名单公布时间:2023-10-18 21:00:00
源代码
import pandas as pd
import matplotlib.pylab as plt
import numpy as np
import seaborn as sns
sns.set(font='SimHei')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('MatePad11.csv')
df.head(2)
df.shape
df.info()
df.describe() # 查看数值型变量的描述性统计
df.describe(include='O') # 查看非数值型变量的描述性统计
df.isnull().sum()
any(df.duplicated()) # 检测数据集中是否存在重复数据
df.drop_duplicates(inplace=True) # 删除重复数据
df.shape
plt.figure(figsize=(30,12))
sns.countplot(df['product_color'])
plt.xticks(rotation=90,fontsize=18)
plt.xlabel('产品颜色',fontsize=20)
plt.ylabel('产品数量',fontsize=20)
plt.title('不同产品型号的购买数量',fontsize=20)
plt.show()
df['product_type'] =df['product_color'].apply(lambda x:x.split('11')[1].split('】')[0])
df['product_color'] = df['product_color'].apply(lambda x:x.split('】')[1])
df['creation_time'] = df['creation_time'].astype('datetime64[D]')
可视化分析
sns.countplot(df['product_color'])
plt.xlabel('产品颜色')
plt.ylabel('产品数量')
plt.title('不同颜色的产品购买数量')
plt.show()
sns.countplot(df['product_size'])
plt.xlabel('内存大小')
plt.ylabel('产品数量')
plt.title('不同内存大小的产品购买数量')
plt.show()
plt.figure(figsize=(14,6))
df.groupby(df['creation_time']).count()['content'].plot()
plt.ylabel('评论数量')
plt.title('最近一段时间内产品的评论数量')
plt.show()
df.head(2)
df.groupby('product_color').mean()['score'].plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel('评价得分')
plt.title('不同颜色产品的平均得分')
plt.show()
df.groupby('product_type').mean()['score'].plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel('评价得分')
plt.title('不同型号产品的平均得分')
plt.show()
import re
import jieba
def chinese_word_cut(mytext):
jieba.load_userdict('dic.txt') # 这里你可以添加jieba库识别不了的网络新词,避免将一些新词拆开
jieba.initialize()
# [^0-9A-Za-z]表示匹配单个非数字和非字母
# 去除评论中类似“外观材质: 屏幕效果: 运行速度:”这样的词语
mytext = re.sub(r'[^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z]:','',mytext)
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', mytext, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: # 可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
return " ".join(result_list)
df['content_cut'] = df['content'].apply(chinese_word_cut)
df['content_cut']
# 分词后的有些词语对于后面分析是没有价值的,比如“平板”,“京东”,所以我们将这些词语加入停用词库中
import collections
import stylecloud
from PIL import Image
def draw_WorldCloud(df,pic_name,color='white'):
data = ''.join([re.sub(r'[^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z]:','',item) for item in df])
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
print(word_counts_top)
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(result_list),
collocations=False, # 是否包括两个单词的搭配(二字组)
font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体,参考位置为 C:\Windows\Fonts\ ,根据里面的字体编号来设置
size=800, # stylecloud 的大小
palette='cartocolors.qualitative.Bold_7', # 调色板
background_color=color, # 背景颜色
icon_name='fas fa-cloud', # 形状的图标名称
gradient='horizontal', # 梯度方向
max_words=2000, # stylecloud 可包含的最大单词数
max_font_size=150, # stylecloud 中的最大字号
stopwords=True, # 布尔值,用于筛除常见禁用词
output_name=f'{pic_name}.png') # 输出图片
# 打开图片展示
img=Image.open(f'{pic_name}.png')
img.show()
draw_WorldCloud(df['content_cut'],'MatePad11用户评论词云图')
#加载情感分析模块
from snownlp import SnowNLP
# 遍历每条评论进行预测
values=[SnowNLP(i).sentiments for i in df['content']]
#输出积极的概率,大于0.5积极的,小于0.5消极的
#myval保存预测值
myval=[]
good=0
mid=0
bad=0
for i in values:
if (i>=0.6):
myval.append("积极")
good=good+1
elif 0.2<i<0.6:
myval.append("中性")
mid+=1
else:
myval.append("消极")
bad=bad+1
df['预测值']=values
df['评价类别']=myval
df.head(3)
rate=good/(good+bad+mid)
print('好评率','%.f%%' % (rate * 100)) #格式化为百分比
#作图
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'评价分值')
plt.xlabel('用户')
plt.ylabel('评价分值')
# 让图例生效
plt.legend()
#添加标题
plt.title('评论情感分析',family='SimHei',size=14,color='blue')
plt.show()
y = df['评价类别'].value_counts().values.tolist()
plt.pie(y,
labels=['积极','中性','消极'], # 设置饼图标签
colors=["#d5695d", "#5d8ca8", "#65a479"], # 设置饼图颜色
autopct='%.2f%%', # 格式化输出百分比
)
plt.show()
draw_WorldCloud(df[df['评价类别']=='消极']['content'],'MatePad消极评价词云图')
draw_WorldCloud(df[df['评价类别']=='积极']['content'],'MatePad积极评价词云图')
draw_WorldCloud(df[df['评价类别']=='中性']['content'],'MatePad中性评价词云图')