INDEX
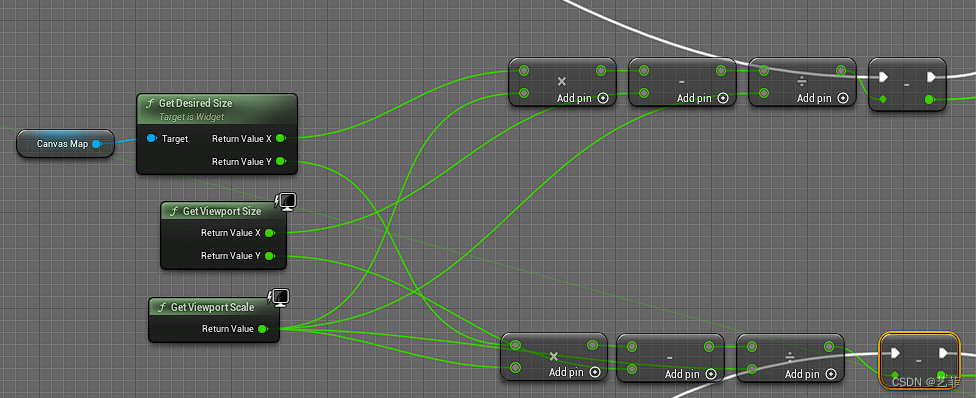
- LSA 级别与全年停机时间速查表
- LSA 级别实战
- TP 性能
- 超时时间设计原则
LSA 级别与全年停机时间速查表
计算公式:60 * 60 * 24 * 365 * (1-LSA) = 31,536,000 * (1-LSA)
| 系统级别 | LSA级别 | 全年停机时间 |
|---|---|---|
| 0+ | 99.999% | 5分钟 |
| 0 | 99.99% | 52分钟 |
| 1 | 99.9% | 8.8小时 |
| 2 | 99% | 3.65 天 |
LSA 级别实战
0+ 级系统是目前业界的普遍努力方向,已有实现了 99.995% 的案例
0 级系统是 涉及核心资金交易的基础服务,需要不间断运行,长时间不可用可能影响名誉、品牌、战略等
1 级系统是 不涉及资金的核心基础服务,需要不间断运行,长时间不可用会影响用户使用产品的核心功能或用户体验
2 级系统是 其他服务、内部服务,长时间不可用只会影响服务自身,或不会对用户产生影响
TP 性能
常见的 TP 性能有 TP99、TP999、TP9999
TP 性能是指,一段时间内,满足 99%、99.9%、99.99% 忘了请求的最小时间。
即:某次统计,服务的 TP99 = 100ms,则意味着 此服务 99% 的网络请求可以在 100 ms 的时间内完成响应。
通常计算方式为,统计单位时间内的所有请求,按其相应时间进行排序,计算处于 x 位置的请求,返回其相应时间,如下图
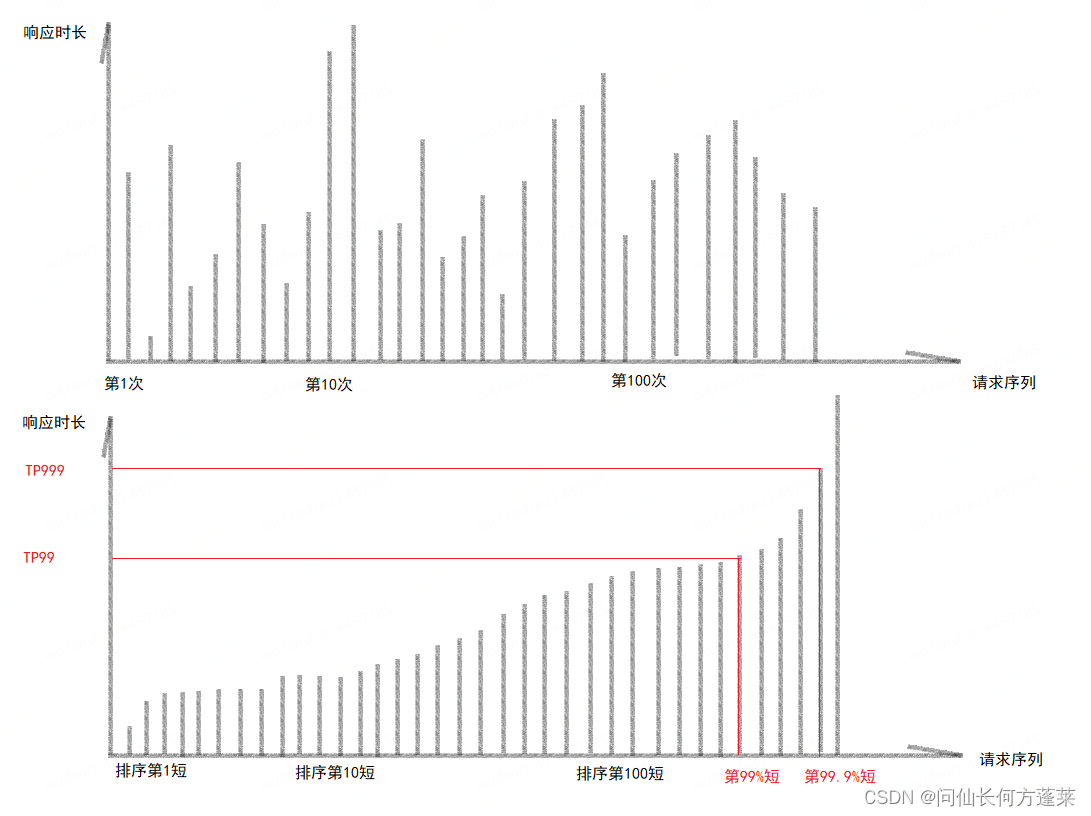
TP 时间在统计时:
- 忽略异常毛刺,毛刺大概率是偶发现象,比如网络抖动等,不能用来说明问题
- 通常从压测数据来,一般使用分钟级压测数据进行统计
- 通常使用调用方视角,而非服务方视角进行统计
超时时间设计原则
- 基于服务所属系统级别设置
- 基于系统对应的 TP 性能设置
- 符合全链路超时漏斗
常见超时时间设置公式
| 系统级别 | 超时计算 |
|---|---|
| 99.99% | TP9999 * 1.2 + 50ms |
| 99.9% | TP999 * 1.2 + 50ms |
| 99% | TP99 * 1.2 + 50ms |
- 1.2 可以认为是一个 波动系数,通常相对稳定的系统可以稍小,反之可以稍大
- 50ms 是为 GC 准备的时间,通常一次 GC 需要 20-50ms
- 这两个数值常基于对生产环境、准生产环境的监控或压测,若 充分压测,可以认为对应的 TP 性能就是考虑了波动的数值,因此 可以忽略波动系数
- 这两个数值也可以基于架构师团队的预测和调整
超时漏斗
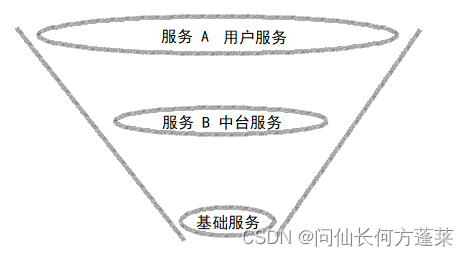
超时漏斗如上图所示:服务 A 调用服务 B,超时时间 A > 超时时间 B
超时漏斗意义/不满足时的问题
首先可以将一个服务的超时时间可以理解为:服务处理单个请求时,承诺的占用系统资源的最大时间
对于一个请求,若如上图所示调用关系,上游服务应该持有系统资源更长时间,才能完整的收到下游服务的反馈
不满足超时漏斗可能导致两个问题
- 资源占用上升:
- 满足漏斗:请求到达服务 B,B 会开辟响应的资源,直到下游返回,服务处理完成,或达到超时时间释放
- 违反漏斗:服务 B 一定等到超时时间再释放(实际处理时间从 ≤ 变为 =超时时间),增加资源占用
- 降级不可靠:
- 满足漏斗:得到基础服务的返回或降级,并继续处理
- 违反漏斗:没得到基础服务的返回或降级,最后按服务 B 的降级返回