文章目录
- 一、open系统调用
- 1.1 简介
- 1.2 files_struct
- 1.2.1 简介
- 1.2.2 init_files
- 1.2.2 CLONE_FILES
- 1.3 源码分析
- 1.3.1 get_unused_fd_flags
- 1.3.2 do_filp_open
- 1.3.3 fd_install
- 二、struct file简介
- 三、其他
- 参考资料
一、open系统调用
1.1 简介
NAME
open, creat - open and possibly create a file or device
SYNOPSIS
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int creat(const char *pathname, mode_t mode);
DESCRIPTION
Given a pathname for a file, open() returns a file descriptor, a small, nonnegative integer for use in subsequent system calls (read(2), write(2), lseek(2), fcntl(2),
etc.). The file descriptor returned by a successful call will be the lowest-numbered file descriptor not currently open for the process.
open()函数接收一个文件路径名作为参数,并返回一个文件描述符,即fd(file descriptor)。文件描述符是一个小的非负整数,用于后续的系统调用(如read()、write()、lseek()、fcntl()等)。成功调用open()后返回的文件描述符将是进程当前未使用的最低编号的文件描述符。
调用open()会创建一个新的打开文件描述符,即系统范围的打开文件表中的一个条目。该条目记录了文件的偏移量和文件状态标志(可以通过fcntl()的F_SETFL操作进行修改)。文件描述符是对这些条目的引用;如果后续对路径名进行删除或修改以引用不同的文件,该引用不受影响。新的打开文件描述符最初不与任何其他进程共享,但可能通过fork()进行共享。
从数值上看,文件描述符是一个非负整数,其本质就是一个句柄,所以也可以认为文件描述符就是一个文件句柄。那么何为句柄呢?一切对于用户透明的返回值,即可视为句柄。用户空间利用文件描述符与内核进行交互;而内核拿到文件描述符后,可以通过它得到用于管理文件的真正的数据结构。
使用文件描述符即句柄,有两个好处:一是增加了安全性,句柄类型对用户完全透明,用户无法通过任何hacking的方式,更改句柄对应的内部结果,比如Linux内核的文件描述符,只有内核才能通过该值得到对应的文件结构;二是增加了可扩展性,用户的代码只依赖于句柄的值,这样实际结构的类型就可以随时发生变化,与句柄的映射关系也可以随时改变,这些变化都不会影响任何现有的用户代码。
文件描述符fd的取值范围:文件描述符的取值范围通常是从0到系统定义的最大文件描述符值。
当Linux新建一个进程时,会自动创建3个文件描述符0、1和2,分别对应标准输入、标准输出和错误输出。C库中与文件描述符对应的是文件指针,与文件描述符0、1和2类似,我们可以直接使用文件指针stdin、stdout和stderr。意味着stdin、stdout和stderr是“自动打开”的文件指针。
在Linux系统中,文件描述符0、1和2分别有以下含义:
文件描述符0(STDIN_FILENO):它是标准输入文件描述符,通常与进程的标准输入流(stdin)相关联。它用于接收来自用户或其他进程的输入数据。默认情况下,它通常与终端或控制台的键盘输入相关联。
文件描述符1(STDOUT_FILENO):它是标准输出文件描述符,通常与进程的标准输出流(stdout)相关联。它用于向终端或控制台输出数据,例如程序的正常输出、结果和信息。
文件描述符2(STDERR_FILENO):它是标准错误文件描述符,通常与进程的标准错误流(stderr)相关联。它用于输出错误消息、警告和异常信息到终端或控制台。与标准输出不同,标准错误通常用于输出与程序执行相关的错误和调试信息。
这些文件描述符是在进程创建时自动打开的,并且可以在程序运行期间使用。它们是程序与用户、终端和操作系统之间进行输入和输出交互的重要通道。通过合理地使用这些文件描述符,程序可以接收输入、输出结果,并提供错误和调试信息,以实现与用户的交互和数据处理。
C库源码如下:
/* Standard streams. */
extern struct _IO_FILE *stdin; /* Standard input stream. */
extern struct _IO_FILE *stdout; /* Standard output stream. */
extern struct _IO_FILE *stderr; /* Standard error output stream. */
/* C89/C99 say they're macros. Make them happy. */
#define stdin stdin
#define stdout stdout
#define stderr stderr
从上面的源码可以看出,stdin、stdout和stderr确实是文件指针。而C标准要求stdin、stdout和stderr是宏定义,所以在C库的代码中又定义了同名宏。
typedef struct _IO_FILE FILE;
FILE *stdin = (FILE *) &_IO_2_1_stdin_;
FILE *stdout = (FILE *) &_IO_2_1_stdout_;
FILE *stderr = (FILE *) &_IO_2_1_stderr_;
DEF_STDFILE(_IO_2_1_stdin_, 0, 0, _IO_NO_WRITES);
DEF_STDFILE(_IO_2_1_stdout_, 1, &_IO_2_1_stdin_, _IO_NO_READS);
DEF_STDFILE(_IO_2_1_stderr_, 2, &_IO_2_1_stdout_, _IO_NO_READS+_IO_UNBUFFERED);
DEF_STDFILE是一个宏定义,用于初始化C库中的FILE结构。这里_IO_2_1_stdin、_IO_2_1_stdout和_IO_2_1_stderr这三个FILE结构分别用于文件描述符0、1和2的初始化,这样C库的文件指针就与系统的文件描述符互相关联起来了。大家注意最后的标志位,stdin是不可写的,stdout是不可读的,而stderr不仅不可读,且没有缓存。
通过上面的分析,可以得到一个结论:stdin、stdout和stderr都是FILE类型的文件指针,是由C库静态定义的,直接与文件描述符0、1和2相关联,所以应用程序可以直接使用它们。
因此一个进程打开一个文件,fd最新从整数3开始,即fd=3。
在早期的Linux内核中,文件描述符的最大值由系统常量NR_OPEN定义,通常为1024或者更小。然而,现代的Linux内核已经采用了更高效的文件描述符管理方式,使用了更大的取值范围。最大值可根据系统配置、内核版本和系统设置而异。
我目前接触到几台机器配置都是1024,这个值可以配置:
centos7:
# uname -r
3.10.0-1160.el7.x86_64
# ulimit -n
1024
$ uname -r
5.19.0-46-generic
$ ulimit -n
1024
1.2 files_struct
1.2.1 简介
Linux的每个进程都有自己的一组打开的文件,内核会打开的文件维护一个文件表,以便维护该进程打开文件的信息,包括打开的文件个数、每个打开文件的偏移量等信息。
内核中进程对应的结构是task_struct,进程的文件表保存在task_struct->files中。
struct task_struct {
......
/* Open file information: */
struct files_struct *files;
.....
}
/*
* Open file table structure
*/
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct files_struct 是 Linux 内核中用于管理进程文件相关操作和信息的数据结构。以下是成员说明:
(1)atomic_t count:原子计数器,用于记录对该结构体的引用计数,多线程会共享files_struct 结构体,fork父子进程不共享同一个files_struct 结构体,子进程赋值拷贝和父进程一样的files_struct 结构体。进程进行fork时,父子进程的fd会指向同一个struct file。
即每个进程有唯一一个files_struct 结构体,但在线程间共享,struct file在父子进程间共享。
(2)struct fdtable __rcu *fdt:指向当前文件描述符表的指针。是一个指向 struct fdtable 结构体的指针,用于跟踪进程的文件描述符。
(3)struct fdtable fdtab:文件描述符表的副本,用于读取操作。
struct fdtable {
unsigned int max_fds;
struct file __rcu **fd; /* current fd array */
unsigned long *close_on_exec;
unsigned long *open_fds;
unsigned long *full_fds_bits;
struct rcu_head rcu;
};
struct fdtable的结构体,用于表示文件描述符表的数据结构:
unsigned int max_fds:表示文件描述符表的最大文件描述符数量。
struct file __rcu **fd:指向当前文件描述符数组的指针。每个元素是一个指向struct file结构体的指针,表示打开的文件。
unsigned long *close_on_exec:指向一个位图数组的指针,用于记录在进程执行时自动关闭的文件描述符。每个位表示一个文件描述符,如果对应位为1,则表示该文件描述符在执行时会自动关闭。
unsigned long *open_fds:指向一个位图数组的指针,用于记录当前打开的文件描述符。每个位表示一个文件描述符,如果对应位为1,则表示该文件描述符是打开状态。
unsigned long *full_fds_bits:指向一个位图数组的指针,用于记录已使用的文件描述符。每个位表示一个文件描述符,如果对应位为1,则表示该文件描述符已被使用。
struct rcu_head rcu:用于实现RCU(Read-Copy-Update)机制的头部,用于在释放结构体时进行资源回收。
其中struct file __rcu **fd就是指向 fdtable.fd 是一个指针字段,指向的内存地址还是存储指针的(元素指针类型为 struct file * )。换句话说,fdtable.fd 指向一个数组,数组元素为指针(指针类型为 struct file *)。
其中 max_fds 指明数组边界。
这个struct fdtable结构体是Linux内核中用于管理进程的文件描述符表的关键数据结构之一。它记录了文件描述符的打开状态、关闭状态和相关的文件信息。通过操作这些成员,内核能够有效地管理进程的文件描述符。
(4)unsigned int next_fd:下一个可用的文件描述符值。
(5)unsigned long close_on_exec_init[1]:初始化的位图数组,表示进程初始状态下需要在执行时自动关闭的文件描述符。
(6)unsigned long open_fds_init[1]:初始化的位图数组,表示进程初始状态下已打开的文件描述符。
(7)unsigned long full_fds_bits_init[1]:初始化的位图数组,表示进程初始状态下已使用的文件描述符。
(8)struct file __rcu * fd_array[NR_OPEN_DEFAULT]:当前打开文件的数组。是一个指向 struct file 结构体的指针数组,表示打开的文件列表。
#ifdef CONFIG_64BIT
#define BITS_PER_LONG 64
/*
* The default fd array needs to be at least BITS_PER_LONG,
* as this is the granularity returned by copy_fdset().
*/
#define NR_OPEN_DEFAULT BITS_PER_LONG
其中fdt指向fdtab,fdtab的成员fd指向fd_array。
一个进程打开的文件管理本质上就是数组管理的方式,所有打开的文件结构都在一个数组里。将fd值作为数组的索引值即可找到fd对应的打开的文件结构。
可以看到struct files_struct有两个地方来管理所有打开的文件结构,即有两个数组来管理所有打开的文件结构。
第一个地方struct fdtable里面的二维指针 fd :
struct fdtable {
......
struct file __rcu **fd; /* current fd array */
......
};
其中注释中说明:current fd array。fd 是指向当前文件描述符数组的指针,而 fd_array 则是一个固定大小的数组,当一个进程打开的文件比较少时,用于存储文件描述符。这样的设计使得可以方便地动态分配和替换文件描述符数组,以满足需要扩展文件描述符数组的情况。
/*
* Open file table structure
*/
struct files_struct {
......
struct fdtable fdtab;
......
};
第二个地方数组变量fd_array:
/*
* Open file table structure
*/
struct files_struct {
......
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
采用两种方式来保存一个进程打开的struct file指针,一种是静态数组形式,一种是动态指针形式。
struct file __rcu *fd_array[NR_OPEN_DEFAULT]:这是一个固定大小的文件描述符数组。NR_OPEN_DEFAULT 是一个宏,表示默认的最大文件描述符数,这里等于64。当一个进程打开的文件比较小时,使用静态数组形式即可,那么内核访问打开文件的速度就比较快,因为这是对静态数组的操作。
如果一个进程打开的文件比较多时,内核就要重新建立数组,struct file __rcu **fd指向动态分配的更大的文件描述符数组。
简单来说:当打开的文件比较少时,使用静态数组,当打开的文件比较多时,动态重新分配动态数组。大部分情况下,一个进程打开的文件都小于64,使用静态数组即可,效率比较高。
struct file __rcu **fd初始化时指向的是struct file __rcu *fd_array[NR_OPEN_DEFAULT]的第一个数组成员,即:
.fdtab.fd = &init_files.fd_array[0],
不管是打开文件使用静态数组形式还是动态指针形式,访问一个进程打开的文件时,都用.fdtab.fd 去访问打开的文件。
因为fd始终指向当前文件描述符数组的指针。
用户空间进程根据fd访问内核空间的struct file结构体过程如下:
struct files_struct *files = current->files;
struct file *file;
struct fdtable *fdt;
fdt = files_fdtable(files);
file = fdt->fd[fd];
当用户使用fd与内核交互时,内核可以用fd从fdt->fd[fd]中得到内部管理文件的结构struct file。
简易图如下所示:

1.2.2 init_files
struct task_struct init_task
= {
......
.files = &init_files,
......
}
init_task是Linux的第一个进程,即0号进程,它的文件表是一个全局变量,如下:
struct files_struct init_files = {
.count = ATOMIC_INIT(1),
.fdt = &init_files.fdtab,
.fdtab = {
.max_fds = NR_OPEN_DEFAULT,
.fd = &init_files.fd_array[0],
.close_on_exec = init_files.close_on_exec_init,
.open_fds = init_files.open_fds_init,
.full_fds_bits = init_files.full_fds_bits_init,
},
.file_lock = __SPIN_LOCK_UNLOCKED(init_files.file_lock),
.resize_wait = __WAIT_QUEUE_HEAD_INITIALIZER(init_files.resize_wait),
};
init_files.fdt和init_files.fdtab.fd都分别指向了自己已有的成员变量,并以此作为一个默认值。后面的进程都是从init进程fork出来的。fork的时候会调用dup_fd,而在dup_fd中其代码结构如下:
/* SLAB cache for files_struct structures (tsk->files) */
struct kmem_cache *files_cachep;
/*
* Allocate a new files structure and copy contents from the
* passed in files structure.
* errorp will be valid only when the returned files_struct is NULL.
*/
struct files_struct *dup_fd(struct files_struct *oldf, int *errorp)
{
struct files_struct *newf;
struct file **old_fds, **new_fds;
unsigned int open_files, i;
struct fdtable *old_fdt, *new_fdt;
*errorp = -ENOMEM;
newf = kmem_cache_alloc(files_cachep, GFP_KERNEL);
if (!newf)
goto out;
atomic_set(&newf->count, 1);
spin_lock_init(&newf->file_lock);
newf->resize_in_progress = false;
init_waitqueue_head(&newf->resize_wait);
newf->next_fd = 0;
new_fdt = &newf->fdtab;
new_fdt->max_fds = NR_OPEN_DEFAULT;
new_fdt->close_on_exec = newf->close_on_exec_init;
new_fdt->open_fds = newf->open_fds_init;
new_fdt->full_fds_bits = newf->full_fds_bits_init;
new_fdt->fd = &newf->fd_array[0];
spin_lock(&oldf->file_lock);
old_fdt = files_fdtable(oldf);
open_files = count_open_files(old_fdt);
/*
* Check whether we need to allocate a larger fd array and fd set.
*/
while (unlikely(open_files > new_fdt->max_fds)) {
spin_unlock(&oldf->file_lock);
if (new_fdt != &newf->fdtab)
__free_fdtable(new_fdt);
new_fdt = alloc_fdtable(open_files - 1);
if (!new_fdt) {
*errorp = -ENOMEM;
goto out_release;
}
/* beyond sysctl_nr_open; nothing to do */
if (unlikely(new_fdt->max_fds < open_files)) {
__free_fdtable(new_fdt);
*errorp = -EMFILE;
goto out_release;
}
/*
* Reacquire the oldf lock and a pointer to its fd table
* who knows it may have a new bigger fd table. We need
* the latest pointer.
*/
spin_lock(&oldf->file_lock);
old_fdt = files_fdtable(oldf);
open_files = count_open_files(old_fdt);
}
copy_fd_bitmaps(new_fdt, old_fdt, open_files);
old_fds = old_fdt->fd;
new_fds = new_fdt->fd;
for (i = open_files; i != 0; i--) {
struct file *f = *old_fds++;
if (f) {
get_file(f);
} else {
/*
* The fd may be claimed in the fd bitmap but not yet
* instantiated in the files array if a sibling thread
* is partway through open(). So make sure that this
* fd is available to the new process.
*/
__clear_open_fd(open_files - i, new_fdt);
}
rcu_assign_pointer(*new_fds++, f);
}
spin_unlock(&oldf->file_lock);
/* clear the remainder */
memset(new_fds, 0, (new_fdt->max_fds - open_files) * sizeof(struct file *));
rcu_assign_pointer(newf->fdt, new_fdt);
return newf;
out_release:
kmem_cache_free(files_cachep, newf);
out:
return NULL;
}
进程调用fork函数创建子进程,函数 dup_fd使用slub管理器分配一个新的 files_struct 结构体,并从传入的旧 files_struct 复制内容到新的结构体中。
1.2.2 CLONE_FILES
对于多数进程来说,每个进程的struct files_struct *files指向唯一的files_struct 描述符,但是对于多线程来说,files_struct 描述符是共享的:
SYSCALL_DEFINE0(fork)
SYSCALL_DEFINE5(clone) --> CLONE_FILES
-->_do_fork()
-->copy_process()
-->copy_files()
static int copy_files(unsigned long clone_flags, struct task_struct *tsk)
{
struct files_struct *oldf, *newf;
int error = 0;
/*
* A background process may not have any files ...
*/
oldf = current->files;
if (!oldf)
goto out;
//多线程共享files_struct 描述符,对于多线程来说,只是将files_struct 描述符的引用count+1
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
goto out;
}
//进程调用fork创建子进程
newf = dup_fd(oldf, &error);
if (!newf)
goto out;
tsk->files = newf;
error = 0;
out:
return error;
}
/*
* cloning flags:
*/
......
#define CLONE_FILES 0x00000400 /* set if open files shared between processes */
......
这段代码的主要目的是根据 clone_flags 的设置,决定是共享还是复制文件表,然后将文件表指针赋值给新进程的 files 成员,完成文件描述符和文件表的复制或共享操作。
如果 clone_flags 中包含 CLONE_FILES 标志,进程调用pthread_creat(clone)创建多线程,表示需要共享文件表,那么函数会增加文件表的引用计数,并跳转到 out 标签处,然后返回错误码。
如果 clone_flags 中不包含 CLONE_FILES 标志,进程执行fork创建子进程,表示需要复制文件表,那么函数调用 dup_fd 函数复制文件表,并将复制得到的新文件表的指针赋值给 newf 变量。如果复制失败,函数跳转到 out 标签处,然后返回错误码。
1.3 源码分析
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
SYSCALL_DEFINE4(openat, int, dfd, const char __user *, filename, int, flags,
umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(dfd, filename, flags, mode);
}
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int fd = build_open_flags(flags, mode, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}
(1)构建打开标志:函数内部调用build_open_flags()函数根据传入的flags和mode参数构建了一个open_flags结构体op。
(2)获取文件名:函数使用getname()函数从用户空间获取文件名,并将结果存储在filename指针tmp中。
(3)获取未使用的文件描述符:使用get_unused_fd_flags()函数获取一个未使用的文件描述符,该描述符将用于打开文件。
(4)打开文件:使用slub管理器分配一个struct file结构体,用来管理打开的文件结构。
(5)文件操作:如果成功打开文件,调用fsnotify_open()函数通知文件系统事件监听器文件已打开,并使用fd_install()函数将文件描述符fd与文件结构体f关联起来。
从do_sys_open可以看出,打开文件时,内核主要使用了两种资源:文件描述符与内核管理文件结构file。即fd 和 strcut file。
打开文件的过程可以简单的概括为:为一个文件申请一个 fd,一个strcut file,并将 fd 与 strcut file 相关联起来。fd可以看成一个索引值,通过这个fd就可以找到该strcut file。这样用户在应用层操作 fd 其实就是在内核态操作strcut file。
1.3.1 get_unused_fd_flags
int get_unused_fd_flags(unsigned flags)
{
return __alloc_fd(current->files, 0, rlimit(RLIMIT_NOFILE), flags);
}
EXPORT_SYMBOL(get_unused_fd_flags);
根据POSIX标准,当获取一个新的文件描述符时,要返回最低的未使用的文件描述符。
/*
* allocate a file descriptor, mark it busy.
*/
int __alloc_fd(struct files_struct *files,
unsigned start, unsigned end, unsigned flags)
{
unsigned int fd;
int error;
struct fdtable *fdt;
spin_lock(&files->file_lock);
repeat:
fdt = files_fdtable(files);
fd = start;
if (fd < files->next_fd)
fd = files->next_fd;
if (fd < fdt->max_fds)
fd = find_next_fd(fdt, fd);
/*
* N.B. For clone tasks sharing a files structure, this test
* will limit the total number of files that can be opened.
*/
error = -EMFILE;
if (fd >= end)
goto out;
error = expand_files(files, fd);
if (error < 0)
goto out;
/*
* If we needed to expand the fs array we
* might have blocked - try again.
*/
if (error)
goto repeat;
if (start <= files->next_fd)
files->next_fd = fd + 1;
__set_open_fd(fd, fdt);
if (flags & O_CLOEXEC)
__set_close_on_exec(fd, fdt);
else
__clear_close_on_exec(fd, fdt);
error = fd;
#if 1
/* Sanity check */
if (rcu_access_pointer(fdt->fd[fd]) != NULL) {
printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd);
rcu_assign_pointer(fdt->fd[fd], NULL);
}
#endif
out:
spin_unlock(&files->file_lock);
return error;
}
这个函数的作用是分配一个文件描述符,并将其标记为已使用。
函数的参数如下:
files:files_struct 结构体指针,表示文件描述符表所属的文件结构。
start:起始的文件描述符fd。
end:最大的文件描述符fd。
flags:标志位,用于指定文件描述符的属性。
函数的执行步骤如下:
(1)使用 files_fdtable 函数获取文件描述符表的指针 fdt。
(2)设置起始文件描述符号码 fd 为 start,如果 fd 小于 files->next_fd,则将其设置为 files->next_fd。
(3)如果 fd 小于文件描述符表的最大文件描述符数 fdt->max_fds,则使用 find_next_fd 函数在文件描述符表中查找下一个可用的文件描述符。
(4)如果 fd 大于等于 end,表示文件描述符已经超出了范围,将 error 设置为 -EMFILE,然后跳转到标签 out 处进行错误处理。
(5)调用 expand_files 函数扩展文件结构中的文件描述符表,以确保能够容纳 fd 号文件描述符。如果扩展文件描述符表时出现错误,将 error 设置为负值,然后跳转到标签 out 处进行错误处理。
(6)如果 error 非零,表示需要再次尝试分配文件描述符,跳转到标签 repeat 处重新执行分配操作。
(7)如果 start 小于等于 files->next_fd,将 files->next_fd 设置为 fd + 1,以确保下一次分配的文件描述符号码递增。
(8)调用 __set_open_fd 函数将文件描述符 fd 标记为已打开。
(9)如果 flags 中包含 O_CLOEXEC 标志位,调用 __set_close_on_exec 函数将文件描述符 fd 标记为在执行 exec 时关闭。如果不包含该标志位,则调用 __clear_close_on_exec 函数取消关闭标记。
(10)将 error 设置为分配的文件描述符号码 fd。
1.3.2 do_filp_open
do_filp_open()
-->path_openat()
-->alloc_empty_file()
-->__alloc_file()
/* SLAB cache for file structures */
static struct kmem_cache *filp_cachep __read_mostly;
static struct file *__alloc_file(int flags, const struct cred *cred)
{
struct file *f;
int error;
f = kmem_cache_zalloc(filp_cachep, GFP_KERNEL);
if (unlikely(!f))
return ERR_PTR(-ENOMEM);
f->f_cred = get_cred(cred);
error = security_file_alloc(f);
......
return f;
}
这段代码是用于分配文件结构体的函数 __alloc_file。
代码注释如下:
(1)kmem_cache_zalloc 是一个内核函数,用于从内存缓存中分配一块内存,并将其初始化为零。在这里,它用于从 filp_cachep 缓存中分配一个文件结构体对象。
(2)f->f_cred 是一个指向 struct cred 结构体的指针,用于表示文件的访问凭证。get_cred(cred) 是一个函数调用,用于获取传入的 cred 参数的引用计数,并将其赋值给 f->f_cred。
(3)security_file_alloc 是一个安全模块提供的函数,用于在文件对象上执行安全分配操作,以确保文件对象的安全性。
do_filp_open函数使用slub管理器分配一个struct file文件结构体对象。
1.3.3 fd_install
void fd_install(unsigned int fd, struct file *file)
{
__fd_install(current->files, fd, file);
}
EXPORT_SYMBOL(fd_install);
fd_install函数用于将上述分配的fd和struct file组合起来,这样用户空间就可以通过fd在内核态访问struct file。
/*
* Install a file pointer in the fd array.
*
* The VFS is full of places where we drop the files lock between
* setting the open_fds bitmap and installing the file in the file
* array. At any such point, we are vulnerable to a dup2() race
* installing a file in the array before us. We need to detect this and
* fput() the struct file we are about to overwrite in this case.
*
* It should never happen - if we allow dup2() do it, _really_ bad things
* will follow.
*
* NOTE: __fd_install() variant is really, really low-level; don't
* use it unless you are forced to by truly lousy API shoved down
* your throat. 'files' *MUST* be either current->files or obtained
* by get_files_struct(current) done by whoever had given it to you,
* or really bad things will happen. Normally you want to use
* fd_install() instead.
*/
void __fd_install(struct files_struct *files, unsigned int fd,
struct file *file)
{
struct fdtable *fdt;
rcu_read_lock_sched();
if (unlikely(files->resize_in_progress)) {
rcu_read_unlock_sched();
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
BUG_ON(fdt->fd[fd] != NULL);
rcu_assign_pointer(fdt->fd[fd], file);
spin_unlock(&files->file_lock);
return;
}
/* coupled with smp_wmb() in expand_fdtable() */
smp_rmb();
fdt = rcu_dereference_sched(files->fdt);
BUG_ON(fdt->fd[fd] != NULL);
rcu_assign_pointer(fdt->fd[fd], file);
rcu_read_unlock_sched();
}
这个函数用于将文件指针 file 安装到指定的文件描述符位置 fd 上,如下访问fd对应的struct file:
fdt->fd[fd];
二、struct file简介
struct file 是 Linux 内核中的一个重要数据结构,用于表示进程打开的文件,struct file是已经打开的文件在内存中的表示,存储与文件操作和状态相关的信息。
// linux-5.4.18/include/linux/fs.h
struct file {
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
......
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos;
const struct cred *f_cred;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
} __randomize_layout
__attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
下面是对 struct file 中各字段的简要说明:
(1)f_path 字段存储文件的路径信息,包括挂载点和文件名。它用于定位文件在文件系统中的位置。
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
} __randomize_layout;
(2)f_inode 字段是指向与文件关联的 struct inode 的指针。struct inode 包含文件的元数据,如权限、时间戳和文件大小。通过 f_inode 可以访问与文件相关的其他属性和操作。
通过 struct file 获取其 struct inode API:
static inline struct inode *file_inode(const struct file *f)
{
return f->f_inode;
}
(3)f_op 字段是指向文件操作函数表(struct file_operations)的指针。文件操作函数表包含读取、写入、打开、释放等文件操作的函数指针。可以通过 f_op 调用这些函数来执行各种文件操作。
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
......
}
(4)f_count 字段是原子长整型变量,表示文件的引用计数。它跟踪文件的打开引用次数。当计数值为零时,可以安全地关闭和释放文件。
(5)f_flags 字段存储文件的各种属性标志,例如是否可读、可写、可执行等。它是一个无符号整数类型。
#define O_ACCMODE 00000003
#define O_RDONLY 00000000
#define O_WRONLY 00000001
#define O_RDWR 00000002
#ifndef O_CREAT
#define O_CREAT 00000100 /* not fcntl */
#endif
#ifndef O_EXCL
#define O_EXCL 00000200 /* not fcntl */
#endif
#ifndef O_NOCTTY
#define O_NOCTTY 00000400 /* not fcntl */
#endif
#ifndef O_TRUNC
#define O_TRUNC 00001000 /* not fcntl */
#endif
#ifndef O_APPEND
#define O_APPEND 00002000
#endif
......
参数flags必须包含以下访问模式之一:O_RDONLY(只读),O_WRONLY(只写)或O_RDWR(读写)。这些模式分别表示以只读、只写或读写的方式打开文件。
(6)f_mode 字段表示文件的模式或访问模式。它指定了文件的权限和访问权限,例如读、写、执行和其他权限位。fmode_t 是文件模式类型。
#define S_IRWXUGO (S_IRWXU|S_IRWXG|S_IRWXO)
#define S_IALLUGO (S_ISUID|S_ISGID|S_ISVTX|S_IRWXUGO)
#define S_IRUGO (S_IRUSR|S_IRGRP|S_IROTH)
#define S_IWUGO (S_IWUSR|S_IWGRP|S_IWOTH)
#define S_IXUGO (S_IXUSR|S_IXGRP|S_IXOTH)
O_CREAT是一个打开文件时可以使用的标志之一。如果文件不存在,将会创建该文件。文件的所有者(用户ID)将设置为进程的有效用户ID。文件的组所有权(组ID)将设置为进程的有效组ID或父目录的组ID(取决于文件系统类型、挂载选项和父目录的权限模式,参见mount()中描述的bsdgroups和sysvgroups挂载选项)。
mode参数指定了在创建新文件时使用的权限,只在创建文件时需要,用于指定所创建文件的权限位。当flags中指定了O_CREAT时,必须提供该参数;如果没有指定O_CREAT,则mode参数将被忽略。进程的umask按照通常的方式修改有效权限:创建的文件的权限是(mode & ~umask)。请注意,该权限模式仅适用于对新创建文件的未来访问;创建只读文件的open()调用可能会返回一个读/写文件描述符。
为mode提供了以下符号常量:
S_IRWXU 00700 user (file owner) has read, write and execute permission
S_IRUSR 00400 user has read permission
S_IWUSR 00200 user has write permission
S_IXUSR 00100 user has execute permission
S_IRWXG 00070 group has read, write and execute permission
S_IRGRP 00040 group has read permission
S_IWGRP 00020 group has write permission
S_IXGRP 00010 group has execute permission
S_IRWXO 00007 others have read, write and execute permission
S_IROTH 00004 others have read permission
S_IWOTH 00002 others have write permission
S_IXOTH 00001 others have execute permission
(7)f_pos 字段跟踪文件中当前的读写位置。随着从文件读取或写入数据,该位置将被更新。
(8)f_cred 字段是指向与文件相关联的凭证(struct cred)的指针。凭证包含与文件访问权限相关的信息,如用户和组的标识。
(9)f_security 字段是指向与文件相关的安全性相关数据的指针。仅在内核配置中启用了安全模块时存在。
三、其他
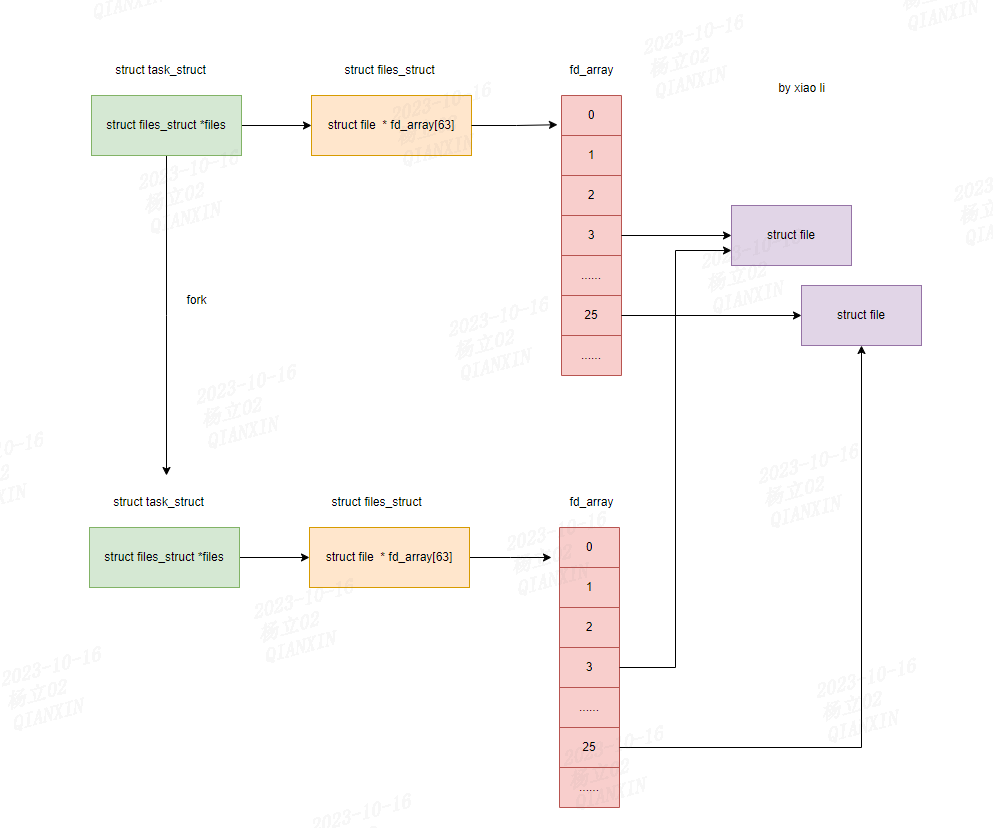
(1)进程fork
进程进行fork时,父子进程不共享struct files_struct,子进程拷贝父进程的struct files_struct,但父子进程共享struct file。
如下所示:
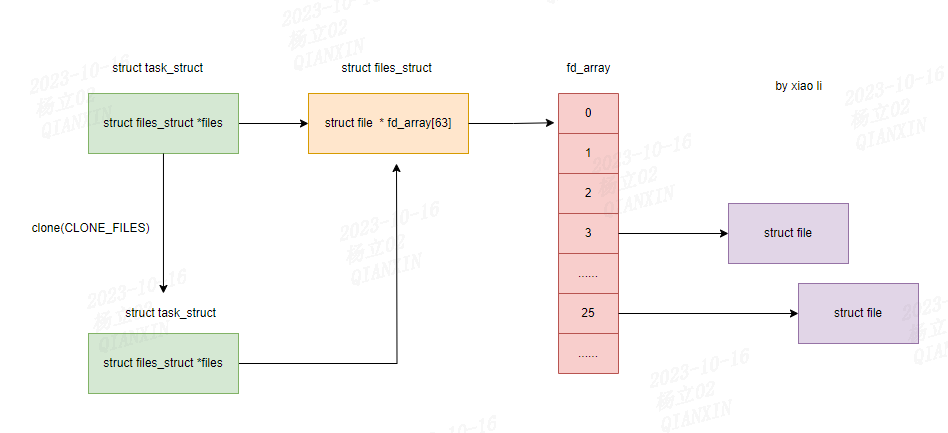
(2)进程创建多线程
进程创建多线程时,共享struct files_struct。
如下图所示:
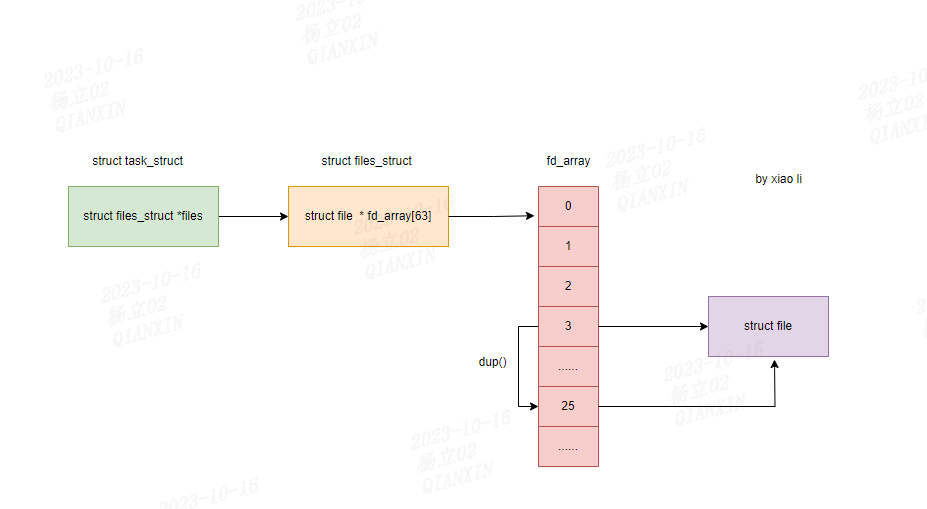
(3)进程调用dup系统调用
一个进程调用dup系统调用时,借助于dup( )、dup2( )和 fcntl( ) 系统调用,两个文件描述符就可以指向同一个打开的文件,也就是说,数组的两个元素可能指向同一个文件对象。当用户使用shell结构(如2>&1)将标准错误文件重定向到标准输出文件上时,用户总能看到这一点。
如下图所示:
参考资料
Linux 5.4.18
Linux环境编程从应用到内核
存储基础 — 文件描述符 fd 究竟是什么?
https://static.lwn.net/kerneldoc/filesystems/vfs.html
https://blog.csdn.net/gmy2016wiw/article/details/72594093