文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 V11》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Canal高可用集群
canal [kə’næl],译意为水道/管道/沟渠.
canal 主要用途是基于 MySQL 数据库增量日志解析,提供增量数据 订阅 和 消费。
canal 应该是阿里云DTS(Data Transfer Service)的开源版本,开源地址:
https://github.com/alibaba/canal。
伪装的mysqlslave, dump协议,接收 bin log 日志数据
Canal和 mysql 客户端的回放线程不一样,Canal 对 binlog 进行转发,可以 socket,也可以发送rocketmq,等等多种方式
比如,把canal.serverMode选项修改为rocketMQ类型:
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rocketMQ
先看看,Canal使用场景:
- 场景1 高并发系统的三大守护神
- 场景2 100W qps 三级缓存组件
- 其他场景
Canal使用场景1: 高并发系统的三大守护神
在很多高并发系统的三大,我们都会在系统中加入 三大守护神 :
-
redis高速缓存,
-
es 做全文检索 ,
-
hbase /mongdb做海量存储。
如果数据库数据发生更新,这时候就需要在业务代码中写一段同步更新 三大守护神 的代码。
这种数据同步的代码跟业务代码糅合在一起会不太优雅,能不能把这些数据同步的代码抽出来形成一个独立的模块呢,答案是可以的。
canal即可作为MySQL binlog增量订阅消费组件+MQ消息队列将增量数据更新到:
-
redis高速缓存,
-
es 做全文检索 ,
-
hbase /mongdb做海量存储。
当然是可以的,而且架构上也非常漂亮:

图中的 redis 缓存操作服务、 es 索引操作服务、 hbase 海量存储操作服务, 都扮演了 bin log 适配器 adapter 的角色。
Canal使用场景2: 100W qps 三级缓存组件
在100W qps 三级缓存组件 的架构中,也需要通过 Canal 进行 binlog 的 订阅, 进行无入侵的 缓存数据维护
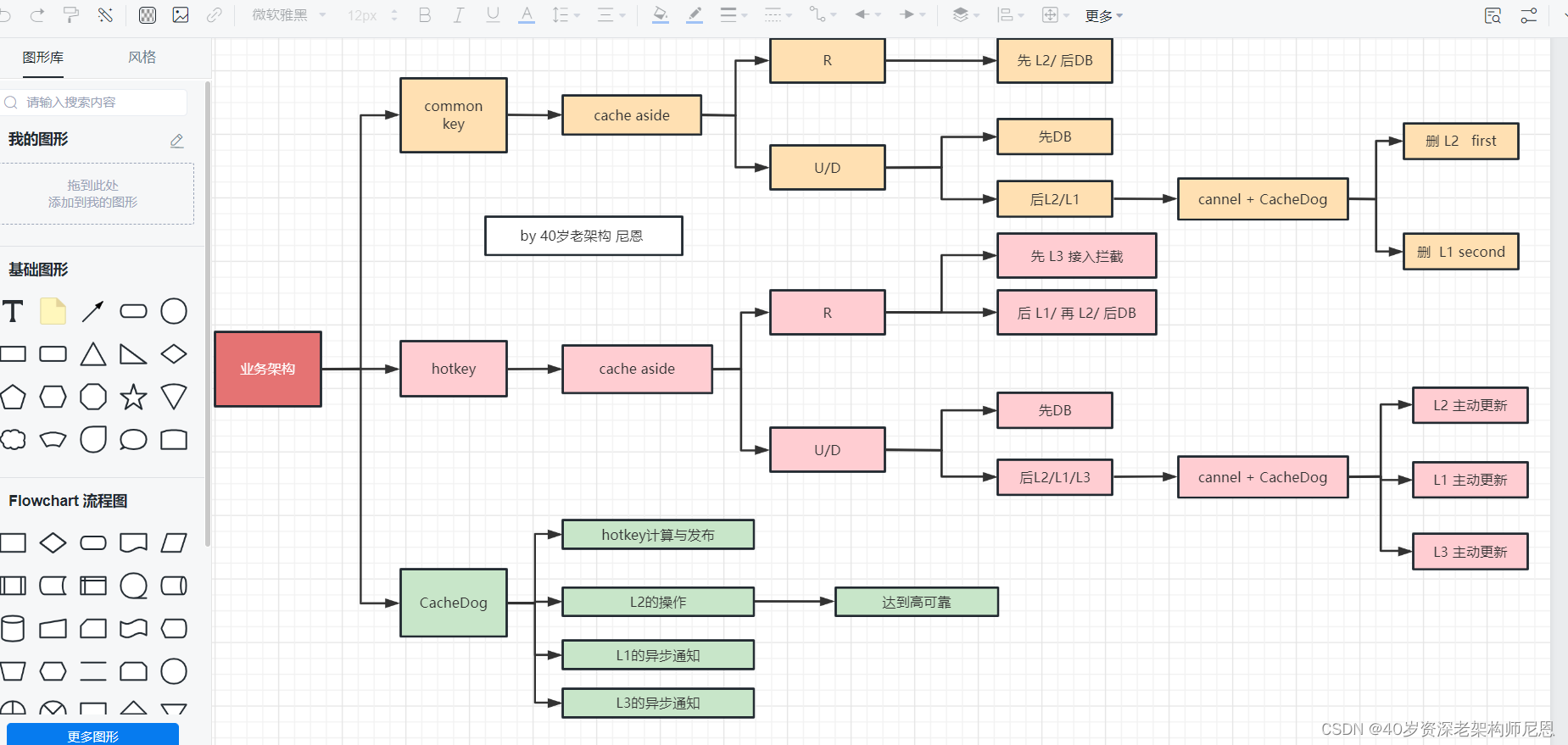
图中的 redis 缓存操作服务、 或者 caffeine 本地缓存操作服务、或者 nginx share dict 本地缓存操作服务,都扮演者缓存 看门狗 watch dog的角色。
缓存 看门狗 watch dog的角色,类似于上面的 adapter 角色。
缓存 看门狗 watch dog的角色,这里简称为 cacheDog 服务。
Canal高可用架构
使用Cannel,为了保证系统 达到 4个9、甚至 5个9 的高可用性,
Canal 服务不能是单节点的,一定是高可用集群的形式存在。
为什么呢?
如果cannel 保存数据不成功,就会导致数据库跟三大高并发守护神 (比如ES、比如redis)数据不一致。
Canal 单节点用于学习、用于测试是OK的
但是Canal 单节点用于生产,会严重影响系统健壮性,稳定性,所以把canal部署成高可用集群。
Canal部署成高可用集群的架构如下:
Canal Server HA架构原理:
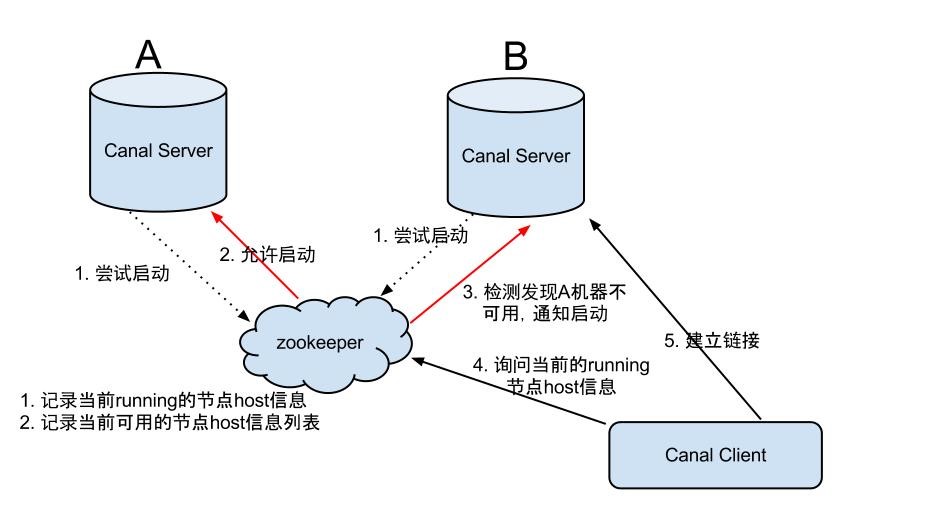
**Canal的ha(双机集群)**分为两部分,canal server和canal client分别有对应的ha实现:
Canal server:
为了减少对mysql dump的请求,不同server上的实例(instance)要求同一时间只能有一个处于running,其他的处于standby状态。
或者说,由于instance 由 Canal server 负责执行,所以 同一个 集群里边的 Canal server, 同一时间只能有一个处于running,其他的处于standby状态
Canal client:
为了保证有序性,一份实例(instance)同一时间只能由一个canal client 进行get/ack/rollback等远程操作,否则客户端接收无法保证有序。
Zookeeper 负责协调:
整个HA机制的控制主要是依赖了zookeeper的几个特性,watcher和EPHEMERAL节点(和session生命周期绑定),
同一个 集群里边的 Canal server, 需要去创建和监听属于Server的唯一的 znode节点,成功则running,失败则 standby
同一个 集群里边的 Canal Client, 需要去创建和监听属于Client的唯一的 znode节点,成功则running,失败则 standby。
standby 的空闲角色,一直监听 唯一的 znode节点 过期状态,随时准备去 争抢转正 机会。
关于Zookeeper 、Znode 、发布订阅等这些基础知识,请大家参阅 [《Java 高并发核心编程 卷1 加强版》](尼恩Java高并发三部曲,极致经典+入大厂必备+面试必备+高薪必备 - 疯狂创客圈 - 博客园 (cnblogs.com))
尼恩Java高并发三部曲,极致经典+入大厂必备+面试必备+高薪必备 - 疯狂创客圈 - 博客园 (cnblogs.com)
Canal高可用Server的协作流程:
1.canal server要启动某个canal instance时, 都先向zookeeper进行一次尝试启动判断(实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)。
2.创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态。
3.一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance。
4.canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect。
**注:**canal client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制。
Canal的三大核心角色
在实操 Canal之前,需要理解一下 Canal的三大核心角色,否则,容易云里雾里,不知所处。
角色1: canal server
可以简单地把canal理解为一个用来同步增量数据的一个工具。
我们看一张官网提供的示意图:

canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
-
因为在 TCP 模式下,一个 instance 只能有一个 canal client 订阅,
即使同时有多个 canal client 订阅相同的 instance, 也只会有一个 canal client 成功获取 binlog,
所以 canal server 写死 clientId = 1001.
也正是因为一个 instance 只有一个 canal client, 所以 canal server 将 binlog 位点信息维护在了 instance 级别,即 conf/content/meta.dat 文件中
-
在 TCP 模式下,如果 canal client 想重新获取以前的 binlog,只能通过修改 canal server 的 initial position 配置并重启服务来达到目的
-
在 TCP 模式下 canal server 主要提供了两个功能
(1) 维护 mysql binlog position 信息,目的是作为 dump 的请求参数,这也是 canal server 唯一保存的数据
(2) 对客户端提供接口以查询 binlog
canal.serverMode 的服务模式有:tcp, kafka, rocketMQ, rabbitMQ
可以把选项修改为rocketMQ类型:
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rocketMQ
这时候,就是 canal server 把收到的 binlog ,按照 instance的过滤要求完成处理后,写入到 rocketMQ。
canal server 负责 canal instance的启动。
canal server 启动过程中的关键信息如下:
-
确定 binlog first position
(1) 先从 conf/content/meta.dat 文件中查找 last position, 也就是最后一次成功 dump binlog 的位点(2) 如果不存在 last position, 则从 conf/content/instance.properties 配置文件中查找 initial position, 这是我们人为配置的初始化位点
(3) 如果不存在 initial position, 则执行 show master status 命令获取 mysql binlog lastest position
通过以上三步就可以确定 canal server 启动之后 binlog 初始位点 -
将 first position 赋值给 last position 保存在内存中
-
将 schema 缓存到 conf/content/h2.mv.db 文件中
角色2:canal client
canal.serverMode 的服务模式有:tcp, kafka, rocketMQ, rabbitMQ。 默认情况下,是tcp, 就是 开启一个Netty服务,发送 binlog 到 Client。
canal client 需要自己开发 TCP客户端,可以参考官方的 canal client 实现。
-
canal client 的 java demo 可以去官方 GitHub 上找一下,记得将 destination 等配置信息改正确。
请参考 https://github.com/alibaba/canal/wiki/ClientExample
-
canal client connect
-
canal client describe
(1) 在收到客户端订阅请求之后,logs/content/content.log 文件会打印出相关日志
(2) conf/content/meta.dat 文件记录了客户端的订阅信息,包括 clientId, destination, filter 等 -
canal client getWithoutAck
(1) canal server 在收到 canal client 查询请求之后,以内存中的 last position 作为参数向 mysql server 发送 dump 请求
(2) 如果存在比 last position 更新的 binlog, canal server 会收到 mysql server 的返回数据,然后将其转换为 Message 数据结构返回给 canal client -
canal client ack
canal client 收到 canal server 的数据之后,可以发送 ack确认 last position的同步位置。
canal server 在收到 canal client 确认请求之后,更新内存中的 last position 并同步保存到 conf/content/meta.dat 文件中,在 logs/content/meta.log 文件中打印日志
角色3:什么是 canal instance?
canal server 仅仅是保姆角色,真正完成 解析 binlog日志、 binlog日志过滤、 binlog日志转储、位点元数据管理等等 核心功能,是由canal instance 角色完成。
Canal Instance 的架构图如下图所示:
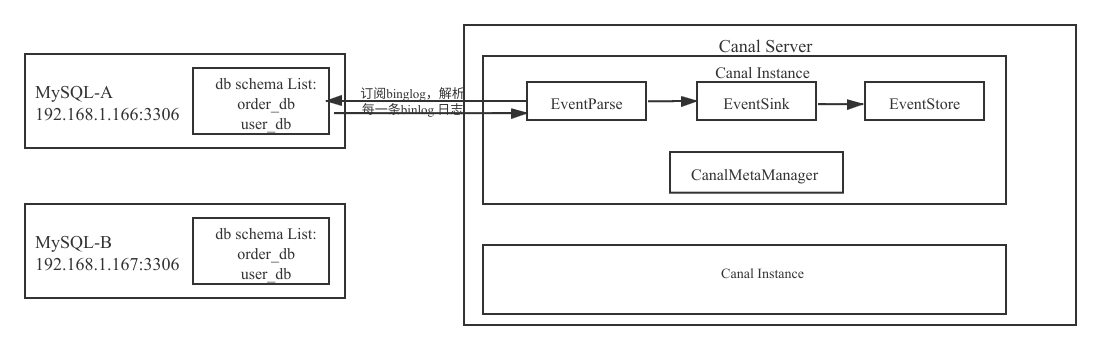
Canal 中数据的同步是由 CanalInstance 组件负责,
一个 Canal Server 实例中可以创建多个 CanalInstance 实例。
每一个 CanalInstance 可以看成是对应一个 MySQL 实例,即案例中需要同步两个数据库实例,故最终需要创建两个 Canal Instance。
其实也不难理解,因为 MySQL 的 binlog 就是以实例为维度进行存储的。
Canal Instance 包含了 4个 核心组件 :EventParse、EventSink、EventStore、CanaMetaManager,
在这里主要是阐明其作用,以便更好的指导实践。
-
EventParse 组件
负责解析 binlog日志,其职责就是根据 binlog 的存储格式将有效数据提取出来,
这个不难理解,我们也可以通过该模块,进一步了解一下 binglog 的存储格式。
-
EventSink 组件
在一个数据库实例上通常会创建多个 Schema,但通常并不是所有的 schema 都需要被同步,
如果直接将 EventParse 解析出来的数据全部传入EventStore 组件,将对 EventStore 带来不必要的性能消耗;
另外本例中使用了分库分表,需要将多个库的数据同步到单一源,可能需要涉及到合并、归并等策略。
以上等等等需求就是 EventSink 需要解决的问题域。
-
EventStore 组件
用来存储经 canal 转换的数据,被 Canal Client 进行消费的数据,目前 Canal 只提供了基于内存的存储实现。
-
CanalMetaManager 组件
元数据存储管理器。
在 Canal 中最基本的元数据至少应该包含 EventParse 组件解析的位点与消费端的消费位点。
Canal Server 重启后要能从上一次未同步位置开始同步,否则会丢失数据。
角色4:什么是 canal cluster集群?
多个 cannel server,可以在创建的时候,归属到一个 集群cluster下边。
一个 集群cluster下边,同时只有一个 cannel server running,其他的standby,实现高可用。
这里文字有点说不清楚,具体请参见视频: 第26章 100qps 三级缓存组件 实操
角色5:什么是 canal admin?
主要的作用
-
通过图形化界面管理配置参数。
-
动态启停
Server和Instance -
查看日志信息
这里文字有点说不清楚,具体请参见视频: 第26章 100qps 三级缓存组件 实操
前期准备
前期准备1:安装zookeeper
可以参考我这篇”疯狂创客圈总目录 一键打造地表最强环境” 文章或者百度教程安装。。集群部署如下:
| 服务名称 | IP/域名 | 端口 |
|---|---|---|
| zookeeper(slave) | cdh1 | 2181 |
| zookeeper(master) | cdh1 | 2182 |
| zookeeper(slave) | cdh1 | 2183 |
前期准备2:安装mysql
可以参考我这篇”疯狂创客圈总目录 一键打造地表最强环境” 文章或者百度教程安装。
MySQL我只部署单台:
| 服务名称 | IP/域名 | 端口 |
|---|---|---|
| mysql | cdh1 | 3306 |
**用户名:**root,**密码:**123456
前期准备3:MySQL开启binlog
查看 mysql 的配置文件路径:
[root@cdh1 canal-ha]# mysql --help|grep 'my.cnf'
order of preference, my.cnf, $MYSQL_TCP_PORT,
/etc/my.cnf /etc/mysql/my.cnf /usr/etc/my.cnf ~/.my.cnf
查看原始的配置
[root@cdh1 canal-ha]# cat /etc/my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
skip-name-resolve
character_set_server=utf8
init_connect='SET NAMES utf8'
lower_case_table_names=1
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
MySQL的 my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
完整的master配置文件my.cnf
[mysqld]
# [必须]服务器唯一ID,默认是1,一般取IP最后一段
server-id=1
# [必须]启用二进制日志
log-bin=mysql-bin
# 复制过滤:也就是指定哪个数据库不用同步(mysql库一般不同步)
binlog-ignore-db=mysql
# 设置需要同步的数据库 binlog_do_db = 数据库名;
# 如果是多个同步库,就以此格式另写几行即可。
# 如果不指明对某个具体库同步,表示同步所有库。除了binlog-ignore-db设置的忽略的库
# binlog_do_db = test #需要同步test数据库。
# 确保binlog日志写入后与硬盘同步
sync_binlog = 1
# 跳过所有的错误,继续执行复制操作
slave-skip-errors = all
温馨提示:在主服务器上最重要的二进制日志设置是sync_binlog,这使得mysql在每次提交事务的时候把二进制日志的内容同步到磁盘上,即使服务器崩溃也会把事件写入日志中。
sync_binlog这个参数是对于MySQL系统来说是至关重要的,他不仅影响到Binlog对MySQL所带来的性能损耗,而且还影响到MySQL中数据的完整性。对于``"sync_binlog"``参数的各种设置的说明如下:
sync_binlog=0,当事务提交之后,MySQL不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁盘,而让Filesystem自行决定什么时候来做同步,或者cache满了之后才同步到磁盘。
sync_binlog=n,当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
在MySQL中系统默认的设置是sync_binlog=0,也就是不做任何强制性的磁盘刷新指令,这时候的性能是最好的,但是风险也是最大的。因为一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。而当设置为“1”的时候,是最安全但是性能损耗最大的设置。因为当设置为1的时候,即使系统Crash,也最多丢失binlog_cache中未完成的一个事务,对实际数据没有任何实质性影响。
从以往经验和相关测试来看,对于高并发事务的系统来说,“sync_binlog”设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。
「注意」:如果订阅的是mysql的从库,需要增加配置让从库日志也写到binlog里面
log_slave_updates=1
修改之后的配置
[root@cdh1 canal-ha]# cat /etc/my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
skip-name-resolve
character_set_server=utf8
init_connect='SET NAMES utf8'
lower_case_table_names=1
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
判断配置是否生效
重启myql
[root@cdh1 canal-ha]# service mysqld restart
Redirecting to /bin/systemctl restart mysqld.service
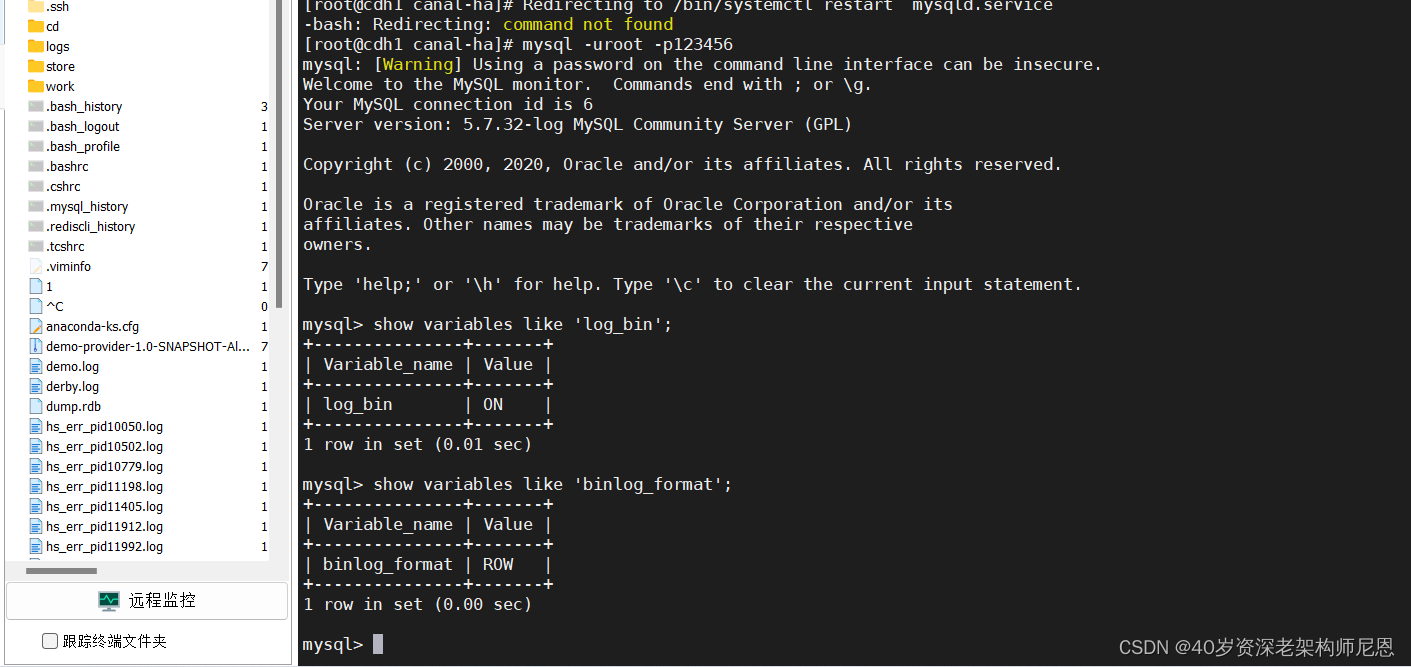
可以通过在 mysql 终端中执行以下命令判断配置是否生效:
mysql -uroot -p123456
show variables like 'log_bin';
show variables like 'binlog_format';
授权账号权限
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant:
set global validate_password_policy=0;
set global validate_password_length=1;
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
前期准备4: 启动RocketMQ
rmqnamesrv:
image: apacherocketmq/rocketmq:4.6.0
container_name: rmqnamesrv
restart: always
ports:
- 9876:9876
environment:
JAVA_OPT_EXT: "-server -Xms256m -Xmx1g"
volumes:
- ./rocketmq-namesrv/logs:/root/logs
command: sh mqnamesrv
networks:
mysql-canal-network:
aliases:
- rmqnamesrv
rmqbroker:
image: apacherocketmq/rocketmq:4.6.0
container_name: rmqbroker
restart: always
depends_on:
- rmqnamesrv
ports:
- 10909:10909
- 10911:10911
volumes:
- ./rocketmq-broker/logs:/root/logs
- ./rocketmq-broker/store:/root/store
- ./rocketmq-broker/conf/broker.conf:/opt/rocketmq-4.4.0/conf/broker.conf
command: sh mqbroker -c /opt/rocketmq-4.4.0/conf/broker.conf
environment:
NAMESRV_ADDR: "rmqnamesrv:9876"
JAVA_OPT_EXT: "-server -Xms256m -Xmx1g"
networks:
mysql-canal-network:
aliases:
- rmqbroker
rmqconsole:
image: styletang/rocketmq-console-ng
container_name: rocketmq-console
restart: always
ports:
- 19001:9001
depends_on:
- rmqnamesrv
volumes:
- /etc/localtime:/etc/localtime:ro
- /home/rocketmq/console/logs:/root/logs
environment:
JAVA_OPTS: "-Drocketmq.namesrv.addr=rmqnamesrv:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false -Dserver.port=9001"
networks:
mysql-canal-network:
aliases:
- rmqconsole
配置和启动canal-admin
通过 尼恩的一键启动脚本,可以完成 高可用 cannel 集群的一键启动
canal-admin 作用
- 通过图形化界面管理配置参数。
- 动态启停
Server和Instance - 查看日志信息
给canal-admin建表
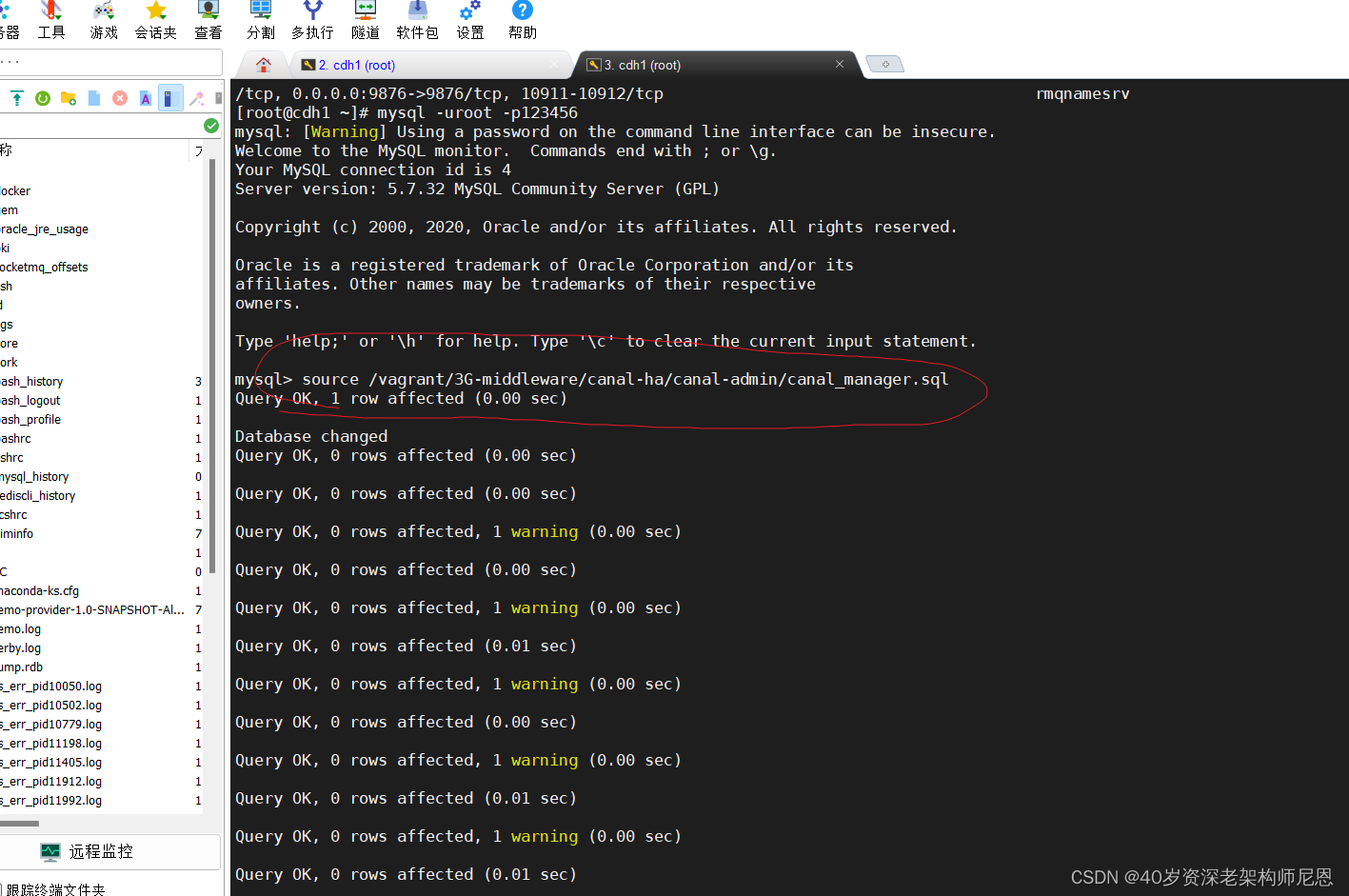
执行数据库脚本
执行 conf 目录下载的 canal_manager.sql 脚步,初始化所需的库表。
初始化SQL脚本里会默认创建canal_manager的数据库,建议使用root等有超级权限的账号进行初始化
mysql -uroot -p123456
source /vagrant/3G-middleware/canal-ha/canal-admin/canal_manager.sql
canal-admin配置修改
执行 vim conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 192.168.56.121:3306
database: canal_manager
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: 123456
修改
address、database、username、password四个参数
访问canal-admin
在浏览器上面输入 hostip:9089 即可进入到管理页面,如果使用的默认的配置信息,用户名入”admin”,密码输入”123456”即可访问首页。
访问canal admin 并且配置实例 / Instance
在浏览器上面输入 hostip:18089 即可进入到管理页面,
如果使用的默认的配置信息,用户名入”admin”,密码输入”123456”即可访问首页。
canal amin 123456
http://cdh1:18089
rocketmq
http://cdh1:19001
访问canal-admin,可以看到自动出现了一个Server,可在此页面进行Server的配置、修改、启动、查看log等操作

集群管理
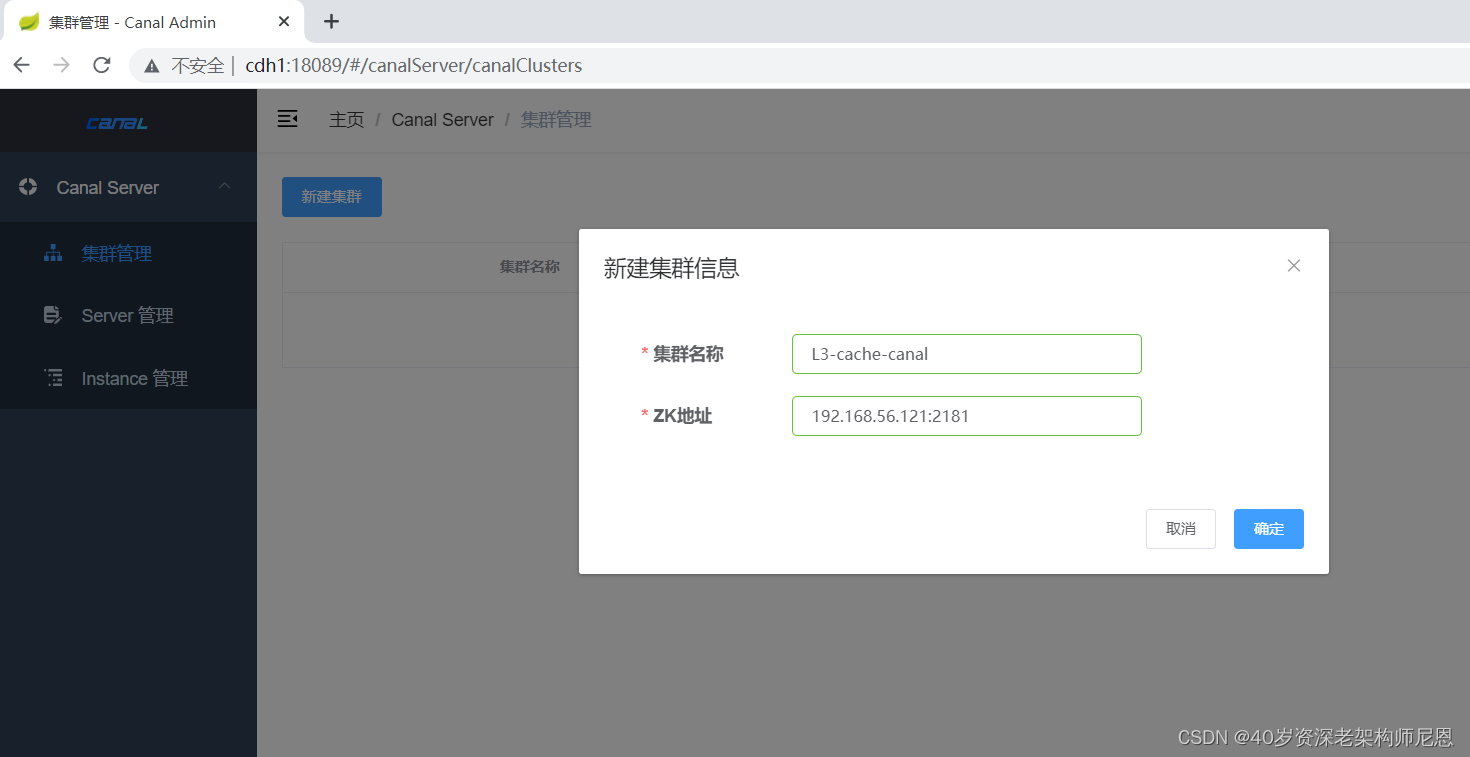
创建集群
配置 「集群名称」 与 「ZK地址」
L3-cache-canal
192.168.56.121:2181
配置 「主配置」,该配置为集群内的所有Server实例共享的
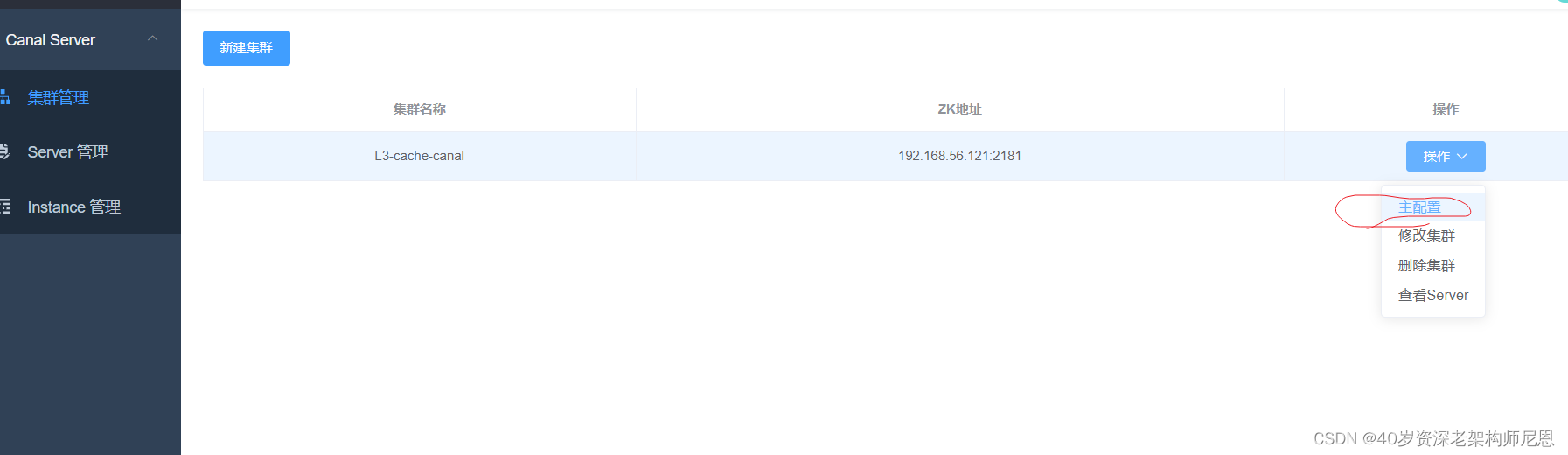
导入集群模板
改 instance 名称
其中有一段代码如下,配置 canal.destinations ,这是 这里定义了 canal server 启动的时候要添加的 instance 名称, 默认是 为空 实例
#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
如果要一个 example 实例,实例的配置文件为
/conf/example/instance.properties 文件
那么,要这么配置
#################################################
######### destinations #############
#################################################
# 这里定义了 canal server 启动的时候要添加的 instance 名称,默认是 example
canal.destinations = example
# 这里定义了 canal server 查找 instance 配置文件的根路径。
# 举个例子,假如前面配置了 example instance, 那么 canal server 会查找 ../conf/example/instance.properties 文件
canal.conf.dir = ../conf
# 这里控制着 canal server 是否在运行过程中自动扫描 canal.conf.dir 目录以动态添加或删除 instance,默认打开,扫描时间间隔 5s
canal.auto.scan = true
canal.auto.scan.interval = 5
注:**
canal是允许配置多个实例(instance),
假设每个canal.server服务都有相同的两个实例(在conf目录下分别建两个实例文件夹:example1和example2,
同时把默认实例example文件夹里的instance.properties文件拷贝一份过去),
修改两个实例canal.properties配置就能使其生效,
在“destinations”标题下找到canal.destinations选项修改如下:
canal.destinations = example1, example2
编辑vi conf/example/instance.properties文件(如果是多实例,则每个实例目录下该文件都要修改配置,现在以canal.server01服务为例)
# mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一
canal.instance.mysql.slaveId=129
# mysql数据库连接地址和端口
canal.instance.master.address=8.135.110.120:3306
# mysql数据库用户名和密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=qwer1234
# mq配置(如果是没用到MQ,则修改为实例名称即可)
canal.mq.topic= example1
Or
# mq配置(如果是用到MQ,则修改为mq路由key)
canal.mq.topic=canal.routingkey.test
修改 serverMode
然后把canal.serverMode选项修改为rocketMQ类型:
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rocketMQ
同时canal需要MQ进行同步数据,所以在“rocketMQ” 标题下找到rocketMQ配置进行修改:
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = canal_producer
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = rmqnamesrv:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
配置zookeeper
主要修改以下配置:
- 「canal.zkServers」 配置zookeeper集群地址
- 「canal.instance.global.spring.xml」 改为classpath:spring/default-instance.xml
部署完canal.server两个服务后,集群想要生效,还需要同时修改两台服务的配置重新启动才可以,
注意:同时修改两台服务的配置重新启动
具体操作如下:
编辑vi conf/ canal.properties文件
因为canal.server集群需要zookeeper,
所以在“common argument”标题下找到canal.zkServers选项修改为zookeeper集群地址;
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers = 192.168.56.121:2181
# flush data to zk
canal.zookeeper.flush.period = 1000
zk配置多个节点
canal.zkServers = 192.168.142.129:2181,192.168.142.130:2181,192.168.142.131:2181
HA模式是依赖于instance name进行管理,必须都选择default-instance.xml配置。
在“destinations”标题下找到canal.instance.global.spring.xml选项进行启用(其他两个选项注释):
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
完整的server 配置参考
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers = 192.168.56.121:2181
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rocketMQ
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = manager
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:6667
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = canal_producer
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = rmqnamesrv:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
创建Server,关联集群
这里是server 列表,能看到 自动的注册到 canal.admin 的Server
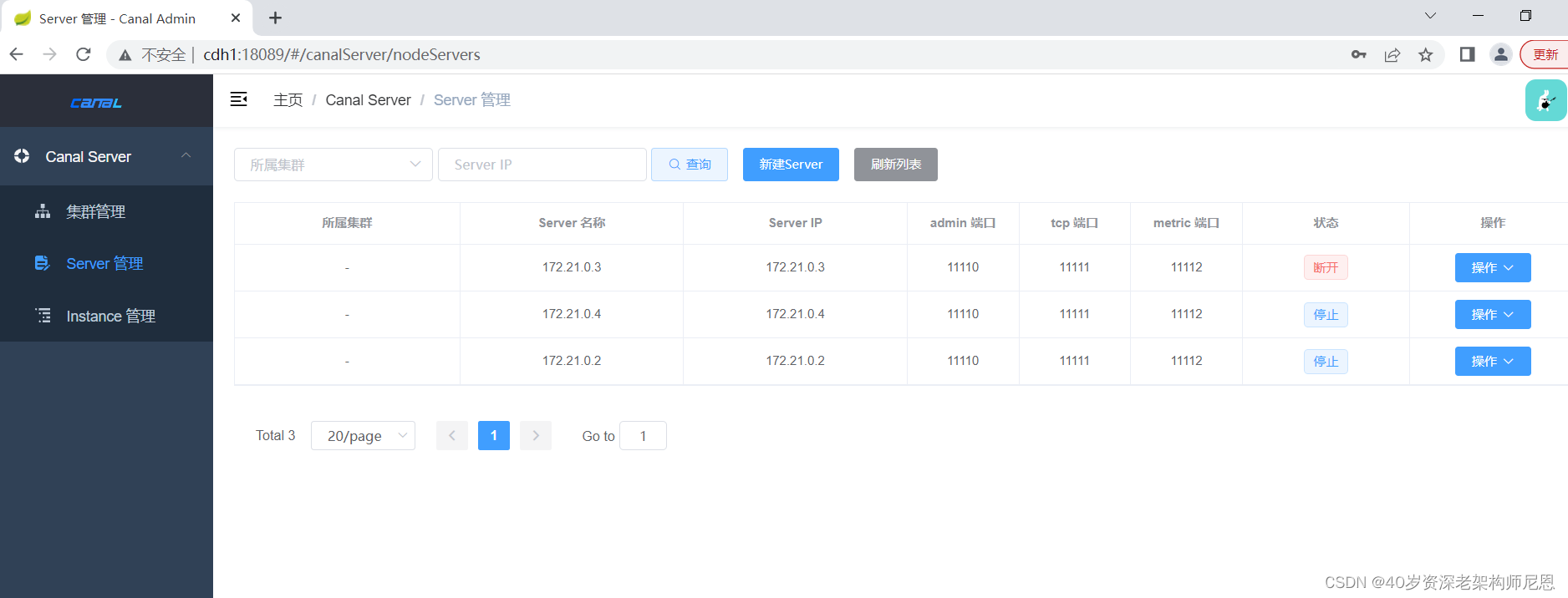
如果 server 配置了 canal.admin 的 管理端口,会自动的注册到 canal.admin
environment: # 设置环境变量,相当于docker run命令中的-e
TZ: Asia/Shanghai
LANG: en_US.UTF-8
canal.admin.manager: canal-admin:8089
canal.admin.port: 11110
canal.admin.user: admin
canal.admin.passwd: 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
# canal.admin.register.cluster: online
如果没有自动注册过来,可以手动添加
手动添加server,关联集群
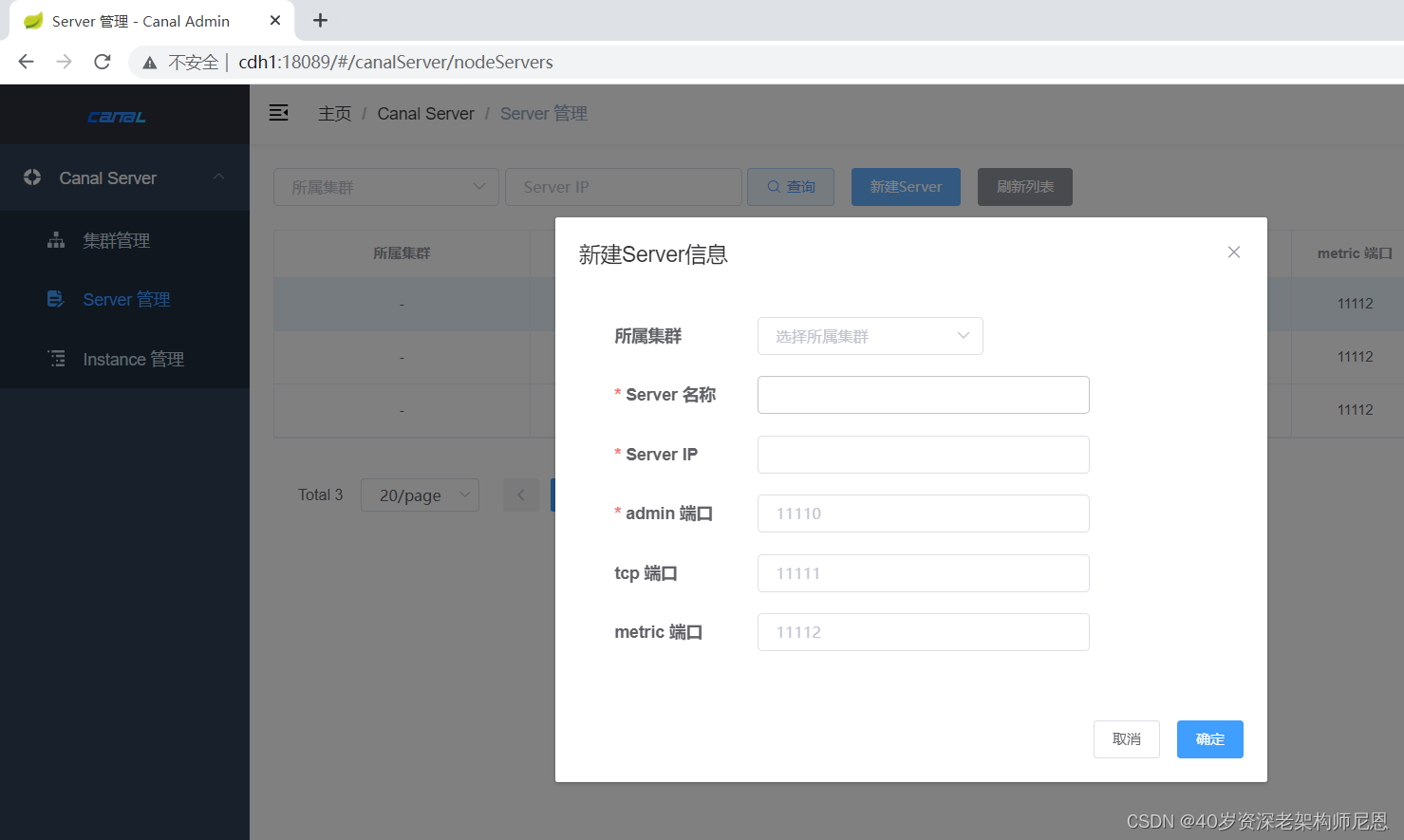
配置项:
-
所属集群,可以选择为单机 或者 集群。
一般单机Server的模式主要用于一次性的任务或者测试任务
-
Server名称,唯一即可,方便自己记忆
-
Server Ip,机器ip
-
admin端口,canal 1.1.4版本新增的能力,会在canal-server上提供远程管理操作,默认值11110
-
tcp端口,canal提供netty数据订阅服务的端口
-
metric端口, promethues的exporter监控数据端口
多台Server关联同一个集群即可形成主备HA架构
配置 canal server
可在此页面进行Server的配置、修改、启动、查看log等操作
配置 canal server 的入口
可以通过 后边的 配置操作,进行server的配置
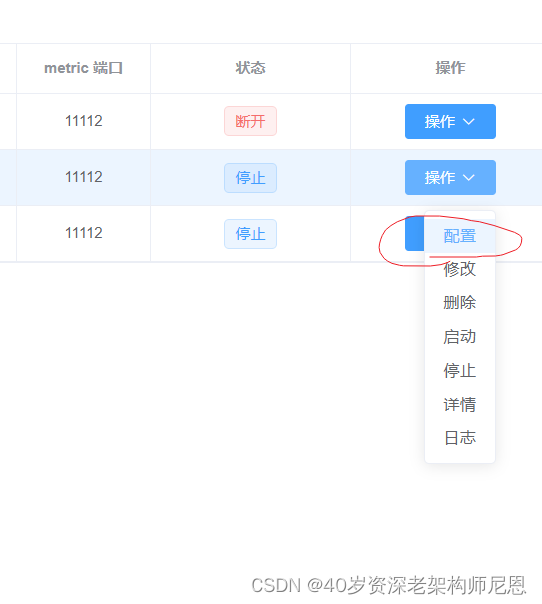
看到的 canal.properties 文件是 canal server 的基础配置文件,
配置实际上就是修改这个文件
改 instance 名称
其中有一段代码如下,配置 canal.destinations ,这是 这里定义了 canal server 启动的时候要添加的 instance 名称, 默认是 为空 实例
#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
如果要一个 example 实例,实例的配置文件为
/conf/example/instance.properties 文件
那么,要这么配置
#################################################
######### destinations #############
#################################################
# 这里定义了 canal server 启动的时候要添加的 instance 名称,默认是 example
canal.destinations = example
# 这里定义了 canal server 查找 instance 配置文件的根路径。
# 举个例子,假如前面配置了 example instance, 那么 canal server 会查找 ../conf/example/instance.properties 文件
canal.conf.dir = ../conf
# 这里控制着 canal server 是否在运行过程中自动扫描 canal.conf.dir 目录以动态添加或删除 instance,默认打开,扫描时间间隔 5s
canal.auto.scan = true
canal.auto.scan.interval = 5
修改 serverMode
然后把canal.serverMode选项修改为rocketMQ类型:
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rocketMQ
同时canal需要MQ进行同步数据,所以在“rocketMQ” 标题下找到rocketMQ配置进行修改:
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = canal_producer
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = rmqnamesrv:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
配置zookeeper
部署完canal.server两个服务后,集群想要生效,还需要同时修改两台服务的配置重新启动才可以,
注意:同时修改两台服务的配置重新启动
具体操作如下:
编辑vi conf/ canal.properties文件
因为canal.server集群需要zookeeper,
所以在“common argument”标题下找到canal.zkServers选项修改为zookeeper集群地址;
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers = 192.168.56.121:2181
# flush data to zk
canal.zookeeper.flush.period = 1000
zk配置多个节点
canal.zkServers = 192.168.142.129:2181,192.168.142.130:2181,192.168.142.131:2181
HA模式是依赖于instance name进行管理,必须都选择default-instance.xml配置。
在“destinations”标题下找到canal.instance.global.spring.xml选项进行启用(其他两个选项注释):
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
注:
canal是允许配置多个实例(instance),
假设每个canal.server服务都有相同的两个实例(在conf目录下分别建两个实例文件夹:example1和example2,
同时把默认实例example文件夹里的instance.properties文件拷贝一份过去),
修改两个实例canal.properties配置就能使其生效,
在“destinations”标题下找到canal.destinations选项修改如下:
canal.destinations = example1, example2
编辑vi conf/example/instance.properties文件(如果是多实例,则每个实例目录下该文件都要修改配置,现在以canal.server01服务为例)
# mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一
canal.instance.mysql.slaveId=129
# mysql数据库连接地址和端口
canal.instance.master.address=8.135.110.120:3306
# mysql数据库用户名和密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=qwer1234
# mq配置(如果是没用到MQ,则修改为实例名称即可)
canal.mq.topic= example1
Or
# mq配置(如果是用到MQ,则修改为mq路由key)
canal.mq.topic=canal.routingkey.test
完整的server 配置参考
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers = 192.168.56.121:2181
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rocketMQ
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = manager
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:6667
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = canal_producer
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = rmqnamesrv:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
创建Instance
每个 Instance 「实例」 关联一个同步的数据源,
如果有多个数据源需要同步则需要创建多个 Instance 「实例」
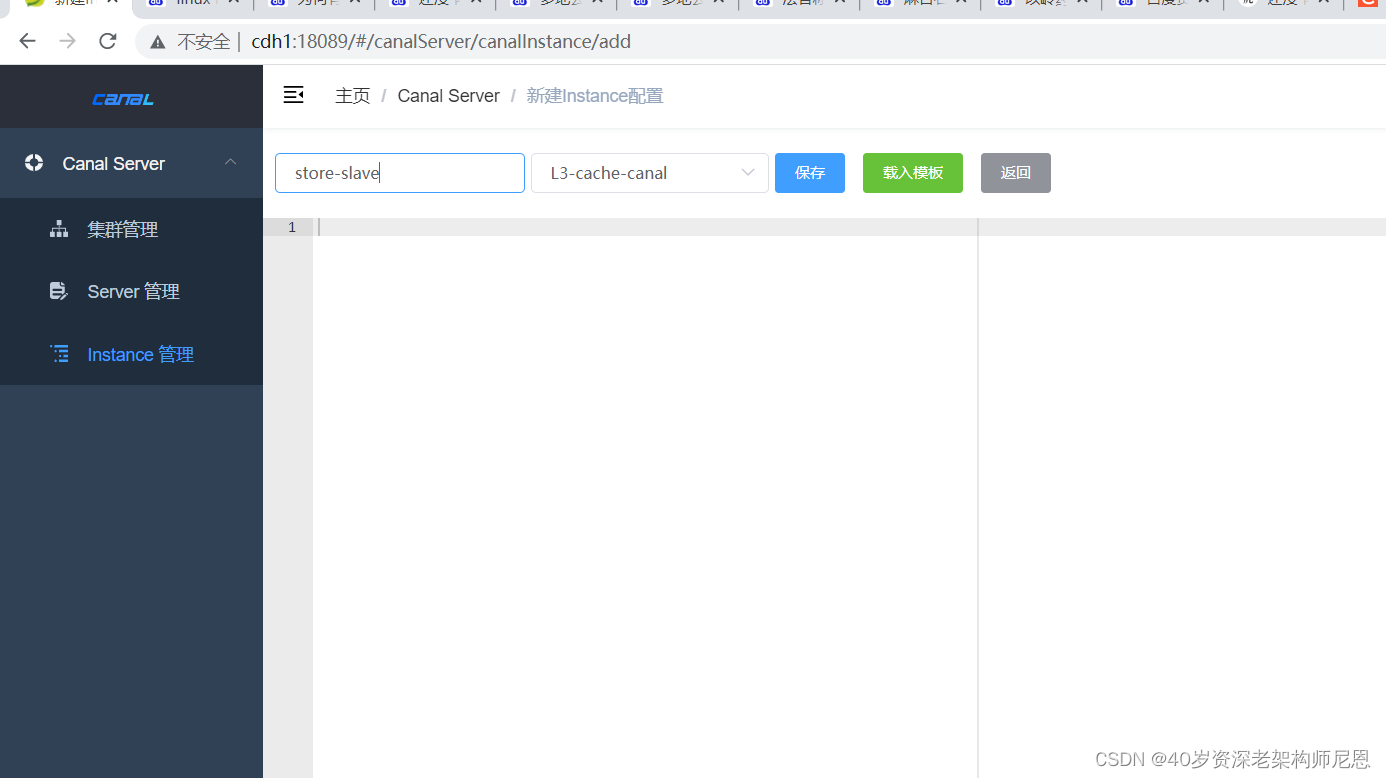
- 先填写实例名
- 选择刚刚创建的集群
- 载入模板配置
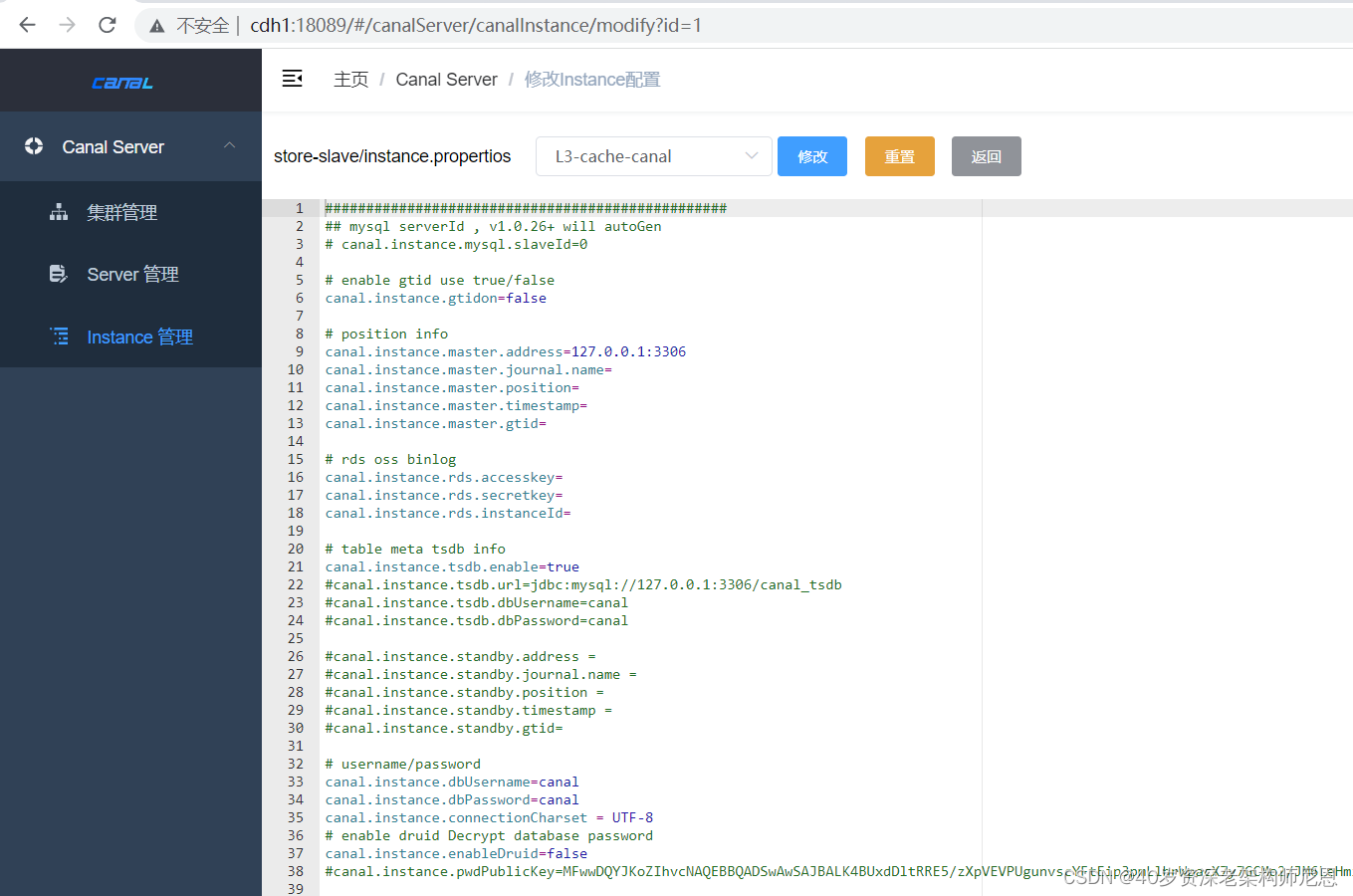
Instance配置
主要修改以下配置:
- 「canal.instance.master.address」 配置要同步的数据库地址
- 「canal.instance.dbUsername」 数据库用户名(需同步权限)
- 「canal.instance.dbPassword」 数据库密码
- 「canal.instance.filter.regex」 mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\)
canal.instance.filter.regex常见例子:
-
所有表:.* or .…
-
canal schema下所有表:canal…*
-
canal下的以canal打头的表:canal.canal.*
-
canal schema下的一张表:canal.test1
-
多个规则组合使用:canal…*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效
为啥呢?
mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤
创建Instance:关联集群,并配置源库信息
canal.instance.master.address=192.168.56.121:3306
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
instance模板
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=192.168.56.121:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://192.168.56.121:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=canal_log
# dynamic topic route by schema or table regex
# canal.mq.dynamicTopic=test.user,student\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
canal.mq.partitionsNum=3
canal.mq.partitionHash=test.users:uid,.*\\..*
##################################################
######### MQ #############
##################################################
canal.mq.servers = 192.168.56.122:9876
#canal.mq.servers = rmqnamesrv:9876
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = canal_producer
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace =
去Instance列表新增Instance,可选择载入模版进行修改,可参考上文中的canal相关配置文件修改
点击侧边栏的Instance管理,选择新建 Instance,选择那个唯一的主机,再点击载入模板,修改下面的一些参数:
实例名称随便填一个就行。
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
# canal.serverMode = tcp
canal.serverMode = RocketMQ
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
rocketmq.producer.group = canal_producers
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
#rocketmq.namesrv.addr = 127.0.0.1:9876
#rocketmq.namesrv.addr = 192.168.56.122:9876
rocketmq.namesrv.addr = rmqnamesrv:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
启动 新实例
创建好的新实例默认是停止状态,将其启动。
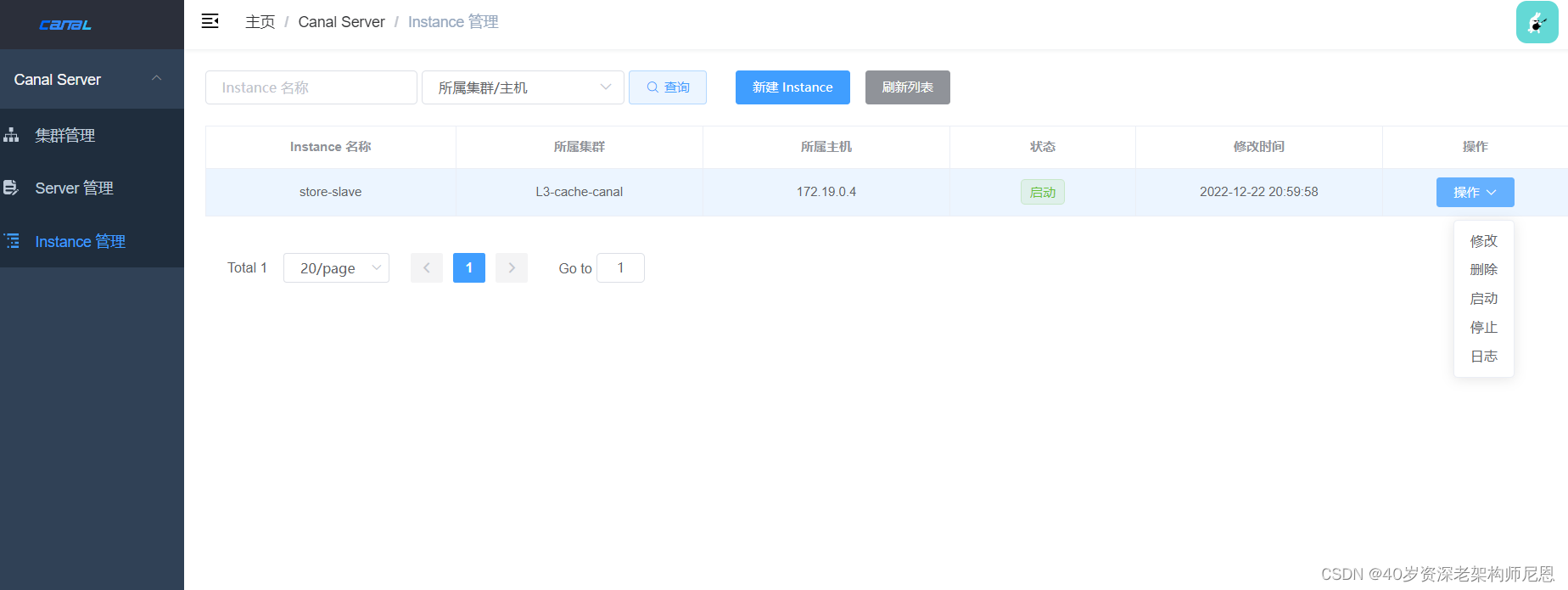
验证:看看canal 集群安装成功
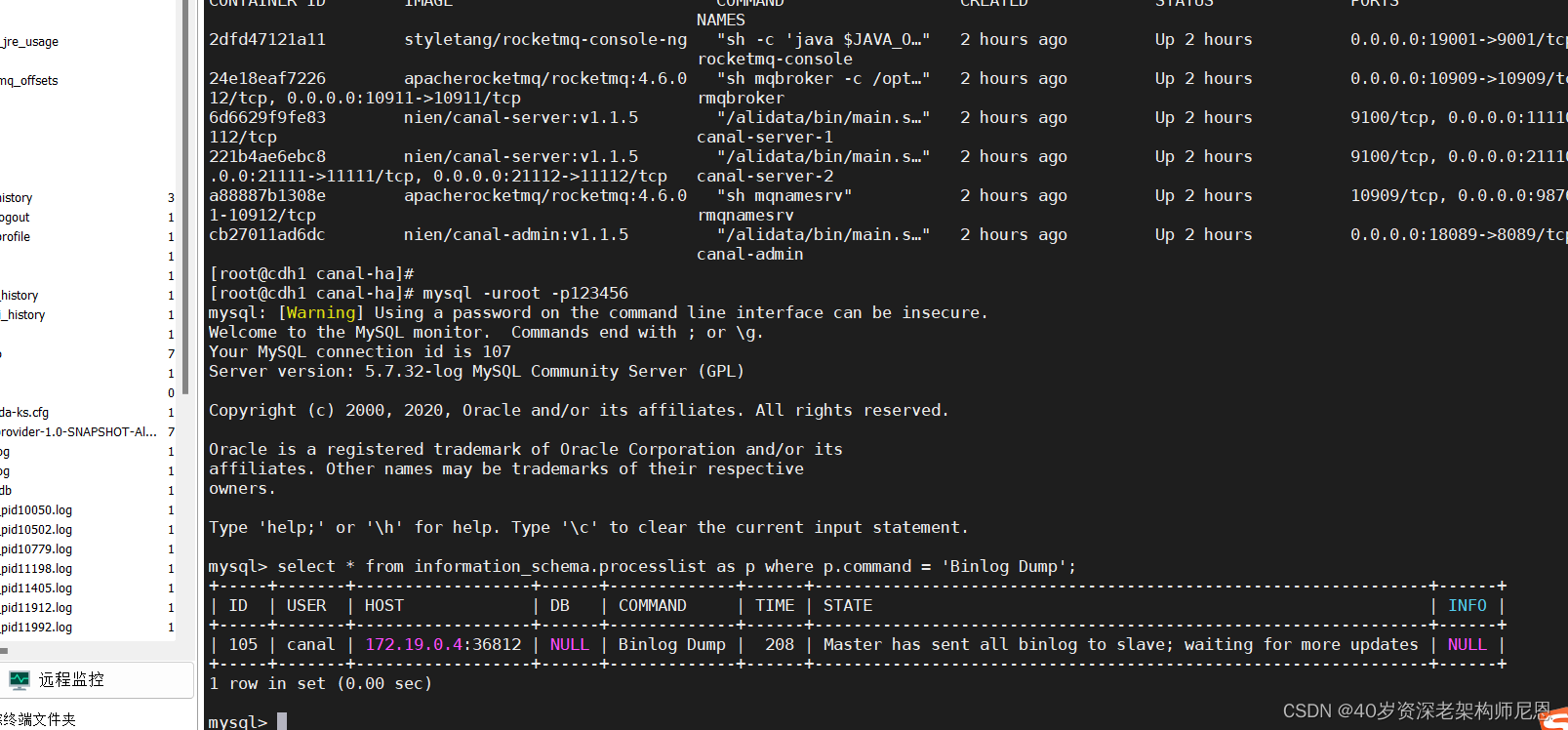
从master 查看从节点
mysql -uroot -p123456
select * from information_schema.processlist as p where p.command = 'Binlog Dump';
数据CRUD操作
登录mysql增删改一条数据
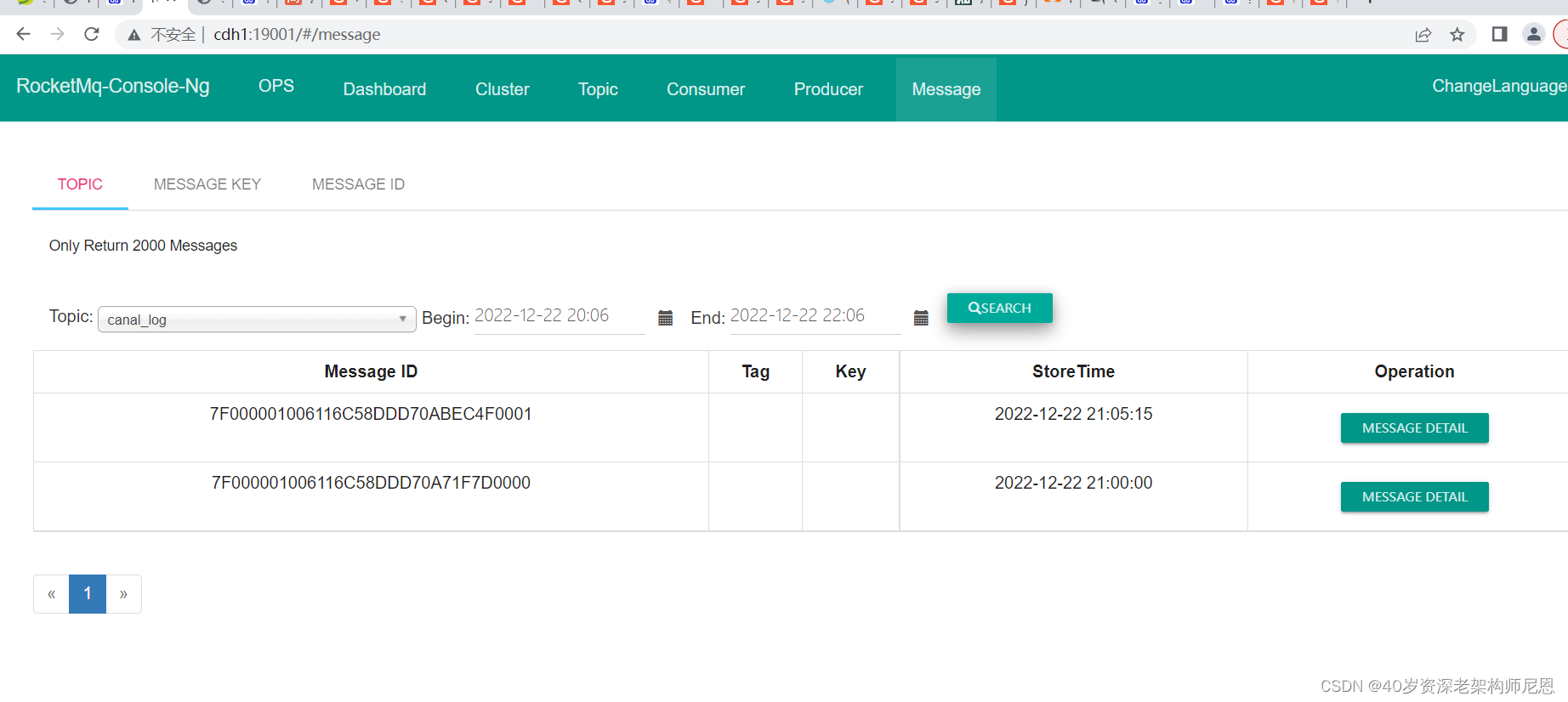
rocketmq 管理后台
在rocketmq 管理后台队列上会看到这两条语句待消费消息:
rocketmq
http://cdh1:19001
参考文献
-
疯狂创客圈 JAVA 高并发 总目录
ThreadLocal 史上最全
-
4000页《尼恩 Java 面试宝典 》的 35个面试专题
-
价值10W的架构师知识图谱
4、尼恩 架构师哲学
5、尼恩 3高架构知识宇宙
https://www.jianshu.com/p/3c6161e5337b
https://blog.csdn.net/weixin_43989347/article/details/124046941
https://github.com/alibaba/canal/wiki
https://blog.csdn.net/prestigeding/article/details/106891211
推荐阅读:
-
《尼恩Java面试宝典》
-
《Springcloud gateway 底层原理、核心实战 (史上最全)》
-
《Flux、Mono、Reactor 实战(史上最全)》
-
《sentinel (史上最全)》
-
《Nacos (史上最全)》
-
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
-
《TCP协议详解 (史上最全)》
-
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
-
《nacos高可用(图解+秒懂+史上最全)》
-
《队列之王: Disruptor 原理、架构、源码 一文穿透》
-
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
-
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)
-
《单例模式(史上最全)
-
《红黑树( 图解 + 秒懂 + 史上最全)》
-
《分布式事务 (秒懂)》
-
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
-
《缓存之王:Caffeine 的使用(史上最全)》
-
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
-
《Docker原理(图解+秒懂+史上最全)》
-
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
-
《Zookeeper 分布式锁 - 图解 - 秒懂》
-
《Zookeeper Curator 事件监听 - 10分钟看懂》
-
《Netty 粘包 拆包 | 史上最全解读》
-
《Netty 100万级高并发服务器配置》
-
《Springcloud 高并发 配置 (一文全懂)》