最近工作中经常遇到收到其他人提供的pdf文档,想要编辑修改下或者复制部分内容比较困难,想通过现有的pdf工具软件转换文档格式,基本都要充钱,为了免费实现pdf转换工具,网上查了下相关技术方案,整理了下代码,测试真实有效,分享下。
第一步,安装相关第三方库
pip install PyMuPDF -i https://mirrors.aliyun.com/pypi/simple
pip install pdf2docx -i https://mirrors.aliyun.com/pypi/simple
第二步,编写代码
pdfConverter.py:
import datetime
import os
# fitz就是pip install PyMuPDF
import fitz
# pdf2docx 也是封装 fitz 模块为基础开发的
from pdf2docx import Converter
'''
pdf 转换工具包
pdf 转成 word
pdf 转成 图片
pdf 转成 html
'''
def pdf2word(file_path):
'''
@方法名称: pdf转word
@中文注释: pdf转word
@入参:
@param file_path str pdf文件路径
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param doc_file str word文件名
@作 者: PandaCode辉
@创建时间: 2023-10-16
@使用范例: pdf2word('test.pdf')
'''
try:
if (not type(file_path) is str):
return [0, "111111", "pdf文件路径参数类型错误,不为字符串", [None]]
# 开始时间
startTime = datetime.datetime.now()
# 提取文件名,去除文件后缀
file_name = file_path.split('.')[0]
print(file_name)
# word文件名
doc_file = f'{file_name}.docx'
print(doc_file)
p2w = Converter(file_path)
'''
convert(doc_file,start,end)函数中
doc_file:转化完成后文件名
start:转化开始页面
end:转化结束页面
注意点:
①若不给start,end参数则默认转化全篇
②对于不连续的页面,也可写作convert(doc_file , pages = [2,4,6])
'''
p2w.convert(doc_file, start=0, end=None)
p2w.close()
endTime = datetime.datetime.now() # 结束时间
print('pdf转word耗时: %s 秒' % (endTime - startTime).seconds)
print("pdf转word成功")
# 返回容器
return [1, '000000', 'pdf转word成功', [doc_file]]
except Exception as e:
p2w.close()
print("pdf转word异常," + str(e))
return [0, '999999', "pdf转word异常," + str(e), [None]]
def pdf2image(file_path, image_path):
'''
@方法名称: pdf转图片
@中文注释: pdf转图片
@入参:
@param file_path str pdf文件路径
@param image_path str 输出图片路径
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param image_path str 输出图片路径
@作 者: PandaCode辉
@创建时间: 2023-10-16
@使用范例: pdf2image('test.pdf', './images')
'''
try:
if (not type(file_path) is str):
return [0, "111111", "pdf文件路径参数类型错误,不为字符串", [None]]
if (not type(image_path) is str):
return [0, "111112", "输出图片路径参数类型错误,不为字符串", [None]]
# 开始时间
startTime = datetime.datetime.now()
print("pdfPath=" + file_path)
# 提取文件名,去除文件后缀
file_name = file_path.split('.')[0]
print(file_name)
print("imagePath=" + imagePath)
# 打开pdf文档
pdfDoc = fitz.open(file_path)
# 判断存放图片的文件夹是否存在
if not os.path.exists(image_path):
# 若图片文件夹不存在就创建
os.makedirs(image_path)
# Document.page_count 页数 (int)
# 循环页数
for pg in range(pdfDoc.page_count):
print('=======%s========' % (pg + 1))
'''
页面(Page)处理是MuPDF功能的核心。
您可以将页面呈现为光栅或矢量(SVG)图像,可以选择缩放、旋转、移动或剪切页面。
您可以提取多种格式的页面文本和图像,并搜索文本字符串。
对于PDF文档,可以使用更多的方法向页面添加文本或图像。
'''
page = pdfDoc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为1.3,这将为我们生成分辨率提高2.6的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 1.33333333 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 1.33333333
mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)
'''
pix是一个Pixmap对象,它(在本例中)包含页面的RGB图像,可用于多种用途。
方法Page.get_pixmap()提供了许多用于控制图像的变体:分辨率、颜色空间(例如,生成灰度图像或具有减色方案的图像)、
透明度、旋转、镜像、移位、剪切等。
例如:创建RGBA图像(即,包含alpha通道),指定pix=page.get_pixmap(alpha=True)。
Pixmap包含以下引用的许多方法和属性。其中包括整数宽度、高度(每个像素)和跨距(一个水平图像行的字节数)。
属性示例表示表示图像数据的矩形字节区域(Python字节对象)。
还可以使用page.get_svg_image()创建页面的矢量图像。
'''
pix = page.get_pixmap(matrix=mat, alpha=False)
# 将图片写入指定的文件夹内
pix.save(image_path + '/' + file_name + '_%s.png' % (pg + 1))
endTime = datetime.datetime.now() # 结束时间
print('pdf转图片耗时: %s 秒' % (endTime - startTime).seconds)
print("pdf转图片成功")
# 返回容器
return [1, '000000', '"pdf转图片成功', [image_path]]
except Exception as e:
print("pdf转图片异常," + str(e))
return [0, '999999', "pdf转图片异常," + str(e), [None]]
def pdf2html(file_path):
'''
@方法名称: pdf转html
@中文注释: pdf转html
@入参:
@param file_path str pdf文件路径
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param out_file str html文件名
@作 者: PandaCode辉
@创建时间: 2023-10-16
@使用范例: pdf2html('test.pdf')
'''
try:
if (not type(file_path) is str):
return [0, "111111", "pdf文件路径参数类型错误,不为字符串", [None]]
# 开始时间
startTime = datetime.datetime.now()
print("pdfPath=" + pdfPath)
# 打开pdf文档
pdfDoc = fitz.open(pdfPath)
# 提取文件名,去除文件后缀
file_name = pdfPath.split('.')[0]
print(file_name)
out_file = f'{file_name}.html'
print(out_file)
# 打开文件,首次创建写入
fo = open(out_file, "w+", encoding="utf-8")
# Document.page_count 页数 (int)
# 循环页数
for pg in range(pdfDoc.page_count):
print('=======%s========' % (pg + 1))
'''
页面(Page)处理是MuPDF功能的核心。
您可以将页面呈现为光栅或矢量(SVG)图像,可以选择缩放、旋转、移动或剪切页面。
您可以提取多种格式的页面文本和图像,并搜索文本字符串。
对于PDF文档,可以使用更多的方法向页面添加文本或图像。
'''
page = pdfDoc[pg]
'''
提取文本和图像 page.get_text(opt)
我们还可以以多种不同的形式和细节级别提取页面的所有文本、图像和其他信息:
对opt使用以下字符串之一以获取不同的格式:
"text":(默认)带换行符的纯文本。无格式、无文字位置详细信息、无图像
"blocks":生成文本块(段落)的列表
"words":生成单词列表(不包含空格的字符串)
"html":创建页面的完整视觉版本,包括任何图像。这可以通过internet浏览器显示
"dict" / "json":与HTML相同的信息级别,但作为Python字典或resp.JSON字符串。
"rawdict" / "rawjson":"dict" / "json"
的超级集合。它还提供诸如XML之类的字符详细信息。
"xhtml":文本信息级别与文本版本相同,但包含图像。
"xml":不包含图像,但包含每个文本字符的完整位置和字体信息。使用XML模块进行解释
'''
# html 格式保存原PDF文本和图片样式还行
# text = page.get_text('html')
# xhtml 格式保存原PDF文本和图片样式更好
text = page.get_text('xhtml')
# 写入文件
fo.write(text)
# 关闭文件
fo.close()
endTime = datetime.datetime.now() # 结束时间
print('pdf转html耗时: %s 秒' % (endTime - startTime).seconds)
print("pdf转html成功")
# 返回容器
return [1, '000000', '"pdf转html成功', [out_file]]
except Exception as e:
# 关闭文件
fo.close()
print("pdf转html异常," + str(e))
return [0, '999999', "pdf转html异常," + str(e), [None]]
if __name__ == "__main__":
# PDF地址
pdfPath = 'test.pdf'
# 1,pdf转word
pdf2word(pdfPath)
# 储存图片的目录
imagePath = './images'
# 2,pdf转图片
pdf2image(pdfPath, imagePath)
# 3,pdf转html
pdf2html(pdfPath)
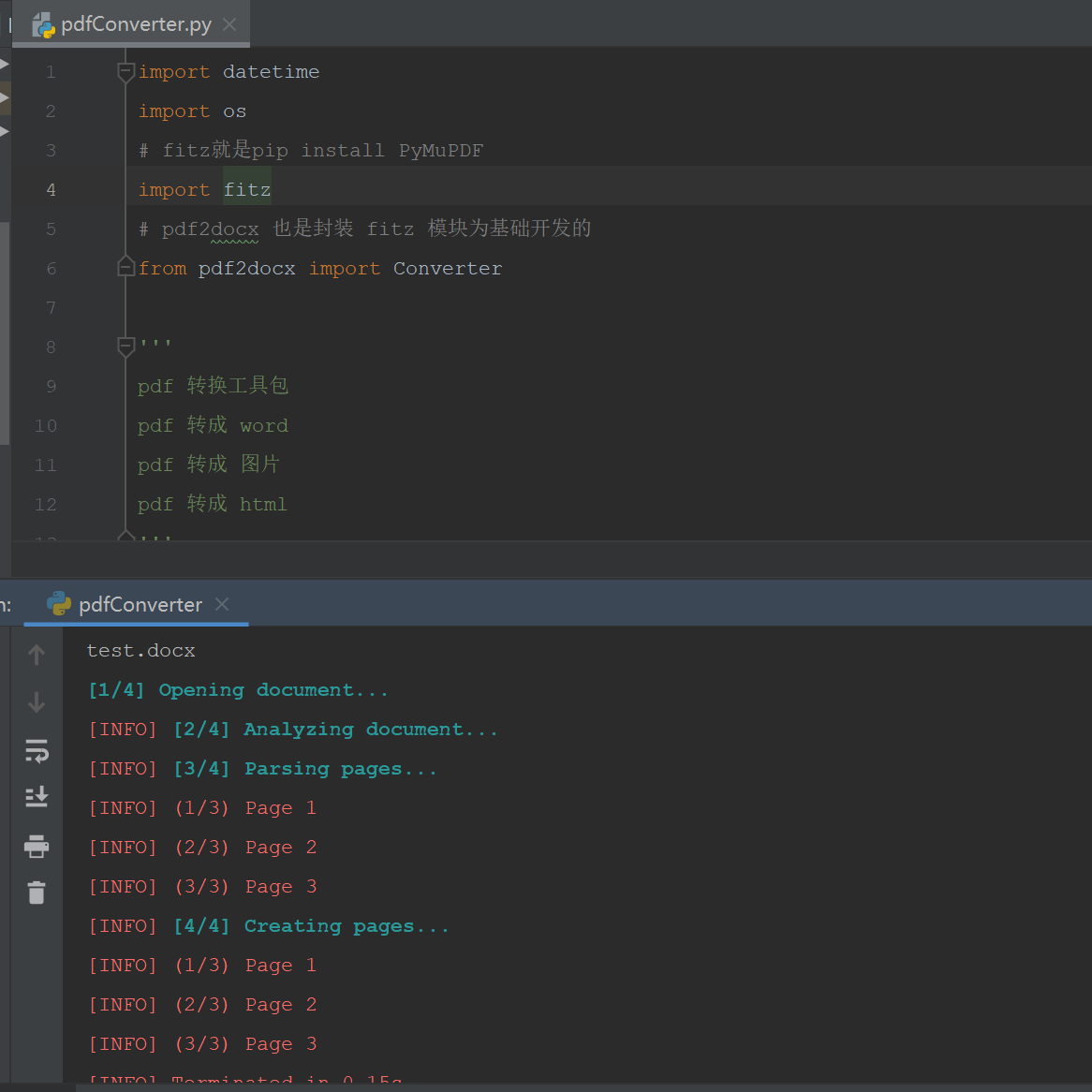
第三步,运行查看效果