NI GPIB-140A 使用缓冲传输技术 边缘人工智能
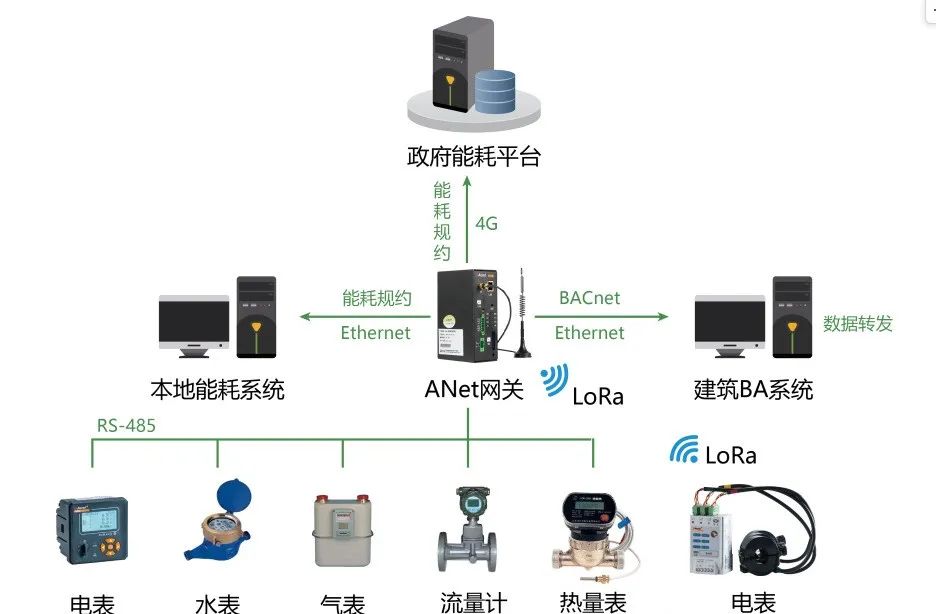
GPIB总线扩展器—GPI b-140 a可以将GPIB系统的电缆长度延长一千米,而不会影响GPIB的完整性,也不需要修改软件。该配件使用缓冲传输技术,以高达1.1 Mb/s (IEEE 488.1)或2.8 Mb/s (HS488)的速率传输数据。GPIB-140A还将GPIB系统中GPIB设备的最大数量从15个扩展到15个以上...
边缘人工智能(AI)解决方案提供商耐能(Kneron)宣布了其面向边缘设备的人工智能处理器耐能NPU IP系列。耐能NPU IP系列包括三款产品:KDP 300低功耗版本、KDP 500标准版本和KDP 700高性能版本,支持智能家居、智能监控、智能手机和物联网设备中的各种人工智能应用。
耐能NPU系列功耗在0.5W以下,智能手机中为面部识别设计的KDP 300甚至不到5mW(注1)。
耐能NPU IP系列允许ResNet、YOLO和其他深度学习网络在离线环境下的边缘设备上运行。耐能NPU IP为edge AI提供完整的硬件解决方案,包括硬件IP、编译器、模型压缩。它支持各种类型的卷积神经网络(CNN)模型,如Resnet-18、Resnet-34、Vgg16、GoogleNet和leNet,以及主流的深度学习框架,包括Caffe、Keras和TensorFlow。
耐能NPU IP系列功耗在0.5W以下,KDP 300版本功耗不到5mW。整个产品线的能效高于1.5 TOPS/W(注2)。通过采用滤波分解技术,可以将一个大规模的卷积计算块分割成若干个较小的卷积计算块进行并行计算。与可重构卷积加速技术一起,来自小块的计算结果将被整合,以实现更好的整体计算性能。通过耐能的模型压缩技术,未优化模型的尺寸可以缩小几十倍。

621-4350
620-0033
51403793-900
620-0045
ICM-4RK
51400187-100
51309136-175
51204156-125
FTA-T-20
620-0053
51304476-100
620-0057
30735974-2
2MLB-M08A-CC
IOM-1020
10100/1/1
900R12-0001
IOM-1010
MX100PT21
51304903-200
621-3500-R