目录
一、协程定义
二、协程发展史
(一)协程的基本发展史说明
(二)Java协程发展说明
三、JDK 19 协程的原理细节
(一)Thread.ofVirtual().start()
(二)SocketChannel.write()
(三)Continuation
(四)写事件到达时唤醒协程
四、原理总结
五、备注:JDK 19 协程是 Project Loom 项目的延续
一、协程定义
"协程" 是一个通用的概念,在不同的编程语言和上下文中可以有多种不同的称呼和实现方式,包括 "虚拟线程"、"纤程"、"用户态线程"、"轻量级线程" 以及 "Coroutines" 等等。这些术语有时用于描述协程在不同编程环境中的特定实现和特性。以下是对这些术语的简要理解:
-
协程 (Coroutine):这是通用术语,表示一种在程序中执行的可以暂停和恢复的子例程。协程通常是协作性的,可以用于实现异步编程、多任务处理和事件驱动编程等。
-
虚拟线程 (Virtual Threads):这个术语通常用于描述一种轻量级线程或协程的实现,其行为类似于传统操作系统线程,但不需要底层操作系统的线程支持。虚拟线程可以在用户空间实现,提供更高效的多任务并发。
-
纤程 (Fiber):纤程是一种轻量级线程或协程,与虚拟线程概念类似。它们通常在用户空间中实现,允许程序员自己管理线程的创建和调度,而不依赖于操作系统线程。
-
用户态线程 (User-level Threads):这是指在用户空间内创建和管理的线程,与操作系统线程(内核态线程)相对。协程和虚拟线程通常是用户态线程的一种实现方式。
-
轻量级线程 (Lightweight Threads):这通常指的是线程的一种轻量级实现,它们的创建和切换成本较低,适合用于大规模并发的应用。协程和纤程常常是轻量级线程的一种。
-
Coroutines:这是协程的另一种常见称呼,通常与编程语言的特定实现和语法相关。编程语言如Python、JavaScript、C#等提供了用于创建和管理协程的语法元素,通常被称为 "coroutines" 或 "async/await"。
总的来说,这些术语都指的是一种在编程中用于处理并发任务的概念,它们允许程序在不同的点上暂停和恢复执行,提高了程序的效率和性能。具体术语的使用可能取决于编程语言、编程模型和上下文。
协程相对于传统的线程具有一些显著的优势,这些优势使得协程在某些情况下更适合处理并发任务和异步编程。以下是协程相对于线程的主要优势:
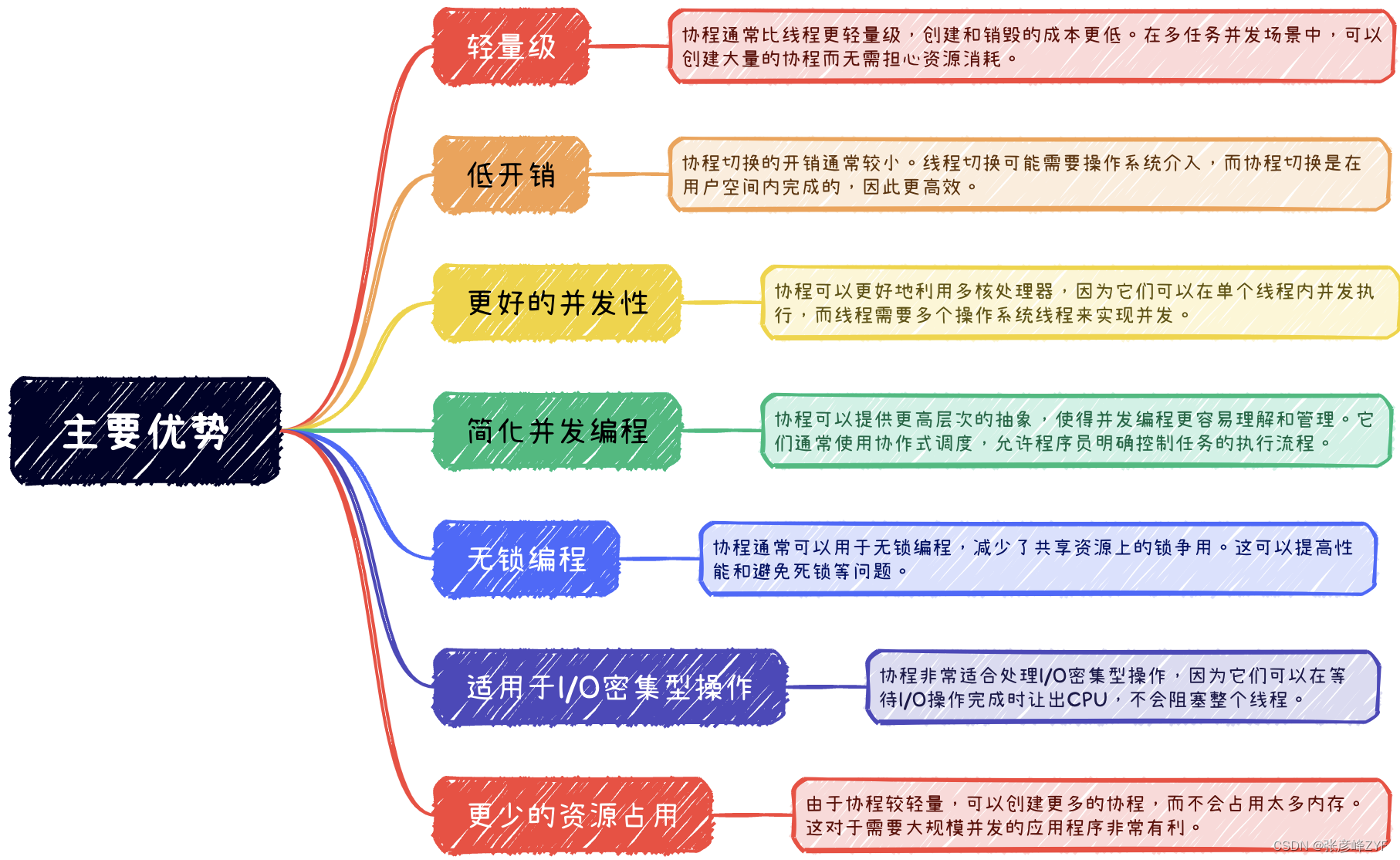
总的来说,协程是一种更高效和抽象的方式来处理并发编程和异步任务,它们在许多情况下能够提供比传统线程更好的性能和编程体验。然而,需要注意的是,协程并不是在所有情况下都比线程更好,具体选择要根据应用程序的需求和编程语言的支持来确定。
二、协程发展史
(一)协程的基本发展史说明
协程的发展历史可以大致分为以下几个阶段,每个阶段都有独特的成果和里程碑:
早期概念和Simula语言
- 1950s - 1960s:协程的概念最早可以追溯到计算机科学的早期。在那个时代,程序员通常使用汇编语言和低级语言编写程序,手动控制程序的执行流。虽然没有明确的协程实现,但程序员需要管理程序的状态。
- 1960s:Simula语言(Simula 67)引入了"协作过程"(coroutines)的概念,这是协程术语的早期使用之一。Simula是一种早期的面向对象编程语言,协作过程的概念在其中有所体现。
生成器和协程的初步引入
- 1980s - 1990s:生成器的概念逐渐引入编程语言。生成器允许函数产生多次值,并能够暂停和恢复执行。这为协程的发展提供了基础。
C#的协程(Coroutines)
- 2000s:C#编程语言引入了协程的概念,提供了异步编程的支持。
async/await关键字的引入使得编写异步代码更加容易,这在Web开发和服务器编程中非常有用。
Go语言的Goroutines
- 2000s - 2010s:Go语言发布,引入了Goroutines的概念,这是一种轻量级线程或协程。Go语言的并发模型使用Goroutines和Channels,使得并发编程变得非常容易。
Java的Loom项目和Virtual Threads
- 2020s:在JDK 19中,Java引入了Loom项目,其中的一部分是"Virtual Threads"的概念。这将使Java支持协程,提供更高效的并发编程工具,从而改善Java的并发编程模型。
其他语言的协程支持
- 2000s - 至今:除了上述语言,许多其他编程语言也提供了协程的支持或第三方库来实现协程。这些语言包括JavaScript(通过async/await)、Kotlin、Rust等。
每个阶段的成果和里程碑都有助于协程概念的发展和普及。协程的使用不断扩展,使得并发编程和异步任务处理变得更加容易和高效。它已经成为现代编程中不可或缺的一部分,用于处理多任务并发、事件驱动编程和异步操作。
(二)Java协程发展说明
- Java 1.0 - Java 6:早期版本的Java主要依赖于线程(Thread)来实现并发编程。Java提供了多线程支持,但线程的创建和管理成本较高,因此并发编程相对复杂。
- Java 7 - 引入Fork/Join框架:Java 7引入了Fork/Join框架,用于并行计算任务的分解和合并。虽然不是严格意义上的协程,但它是Java中一种更高级的并发编程模型。
- Java 8 - 引入CompletableFuture:Java 8引入了CompletableFuture类,它提供了异步编程的支持,使得可以更容易地编写异步代码。尽管不是协程的严格实现,但它对异步编程有所帮助。
- Java 9 - 引入Flow API:Java 9引入了Flow API,用于处理反应式流(Reactive Streams),这有助于异步数据处理。Flow API提供了一种更高级的异步编程模型,但仍不是严格的协程。
- Java 19 - Loom项目和Virtual Threads:在JDK 19中,引入了Loom项目,其中的一部分是"Virtual Threads"的概念。这是一种协程的实现方式,允许在Java中更轻松地编写异步和并发代码,而无需手动创建线程池和管理线程。虚拟线程的引入改进了Java的并发编程模型,提供了更多处理并发任务的选项。
Java协程的支持是在JDK 19中引入的,通过Loom项目和Virtual Threads的概念,提供了更强大的并发编程工具。虚拟线程的引入标志着Java对于异步编程和协程的支持取得了重要的进展。
三、JDK 19 协程的原理细节
协程的实现原理涉及编程语言和运行时环境的内部机制,具体细节可能因语言和环境而异。然而,协程的基本原理通常涉及以下几个关键概念:
-
栈(Stack)管理:每个协程都有自己的栈,用于保存函数的局部变量、状态和执行上下文。当协程被暂停时,栈的状态被保存。当协程恢复执行时,栈的状态被还原。这使得协程能够在暂停和恢复之间保持执行状态。
-
调度器(Scheduler):协程的调度和执行通常由一个称为调度器的组件管理。调度器决定哪个协程可以运行,何时暂停和恢复协程的执行。它可以基于优先级、时间片轮转或其他策略来决定执行顺序。
-
异步/非阻塞I/O:协程通常与异步和非阻塞I/O 操作一起使用,以避免阻塞整个程序。当协程执行I/O操作时,它可以将自己挂起,而不会阻止其他协程的执行。当I/O操作完成时,协程可以被恢复。
-
生成器和状态机:一些编程语言使用生成器和状态机来实现协程。生成器函数可以在yield语句处暂停执行并返回一个值,状态机负责跟踪函数的执行状态。
-
栈切换(Stack Switching):在某些情况下,实现协程可能需要进行栈切换。这是一种更复杂的操作,它允许一个协程在不同的栈上运行,以提高并发性能。栈切换通常由语言的运行时或编译器来管理。
-
协程上下文保存和恢复:在协程暂停和恢复时,必须保存和恢复执行上下文,包括寄存器状态、栈指针和程序计数器。这些操作通常由编程语言的运行时环境来完成。
需要注意的是,不同编程语言和运行时环境的实现方式会有所不同。例如,Python的生成器协程、Go语言的Goroutines和Java 19的Virtual Threads在实现上都有各自的差异。聚焦协程(JDK 19 中的协程)原理重点:Continuation + Scheduler + 阻塞操作的改造。还是从“Hello Word”开始分析,使用Thread.ofVirtual().start() 启动协程:
public class VirtualThreadTest {
public static void main(String[] args) {
ServerSocketChannel ssc = ServerSocketChannel.open().bind(new InetSocketAddress(8080));
Thread thread = Thread.ofVirtual().start(() ->
{
try {
final SocketChannel sc = ssc.accept();
sc.write(ByteBuffer.wrap("Hello World".getBytes()));
} catch (Exception e) {
e.printStackTrace();
}
});
}
}(一)Thread.ofVirtual().start()
首先先看下VirtualThread的源码如下:
final class VirtualThread extends BaseVirtualThread {
private final Executor scheduler;
private final Continuation cont;
private final Runnable runContinuation;
@Override
public void start() {
start(ThreadContainers.root());
}
@Override
void start(ThreadContainer container) {
...
submitRunContinuation();
...
}
private void submitRunContinuation(boolean lazySubmit) {
...
scheduler.execute(runContinuation);
...
}
private void runContinuation() {
...
try {
cont.run();
} finally {
cont.isDone();
...
}
...
}
private static class VThreadContinuation extends Continuation {
VThreadContinuation(VirtualThread vthread, Runnable task) {
super(VTHREAD_SCOPE, () -> vthread.run(task));
}
...
}
}然后进入 vThread.run 里面来看:
/**
* Runs a task in the context of this virtual thread. The virtual thread is
* mounted on the current (carrier) thread before the task runs. It unmounts
* from its carrier thread when the task completes.
*/
@ChangesCurrentThread
private void run(Runnable task) {
mount();
task.run();
unmount();
}
@ChangesCurrentThread
private void mount() {
// sets the carrier thread
Thread carrier = Thread.currentCarrierThread();
setCarrierThread(carrier);
}
@ChangesCurrentThread
private void unmount() {
// set Thread.currentThread() to return the platform thread
Thread carrier = this.carrierThread;
carrier.setCurrentThread(carrier);
}可以看到,虚拟线程的 start 方法与传统线程的启动方式有着显著的不同。
在虚拟线程的实现中,它确实不会直接创建操作系统级的线程(OS Thread),而是通过 Continuation(继续)来实现协程的控制流。虚拟线程内部封装了 Continuation 对象,将其作为一个任务封装成 Runnable,然后交给调度器(Scheduler)来管理。
虚拟线程的工作方式允许我们创建许多轻量级的执行单元(协程),而不会创建大量的操作系统线程,因为创建和销毁操作系统线程会带来较大的开销。虚拟线程的任务由调度器分配到底层的线程池中,这使得它们可以有效地利用系统资源。
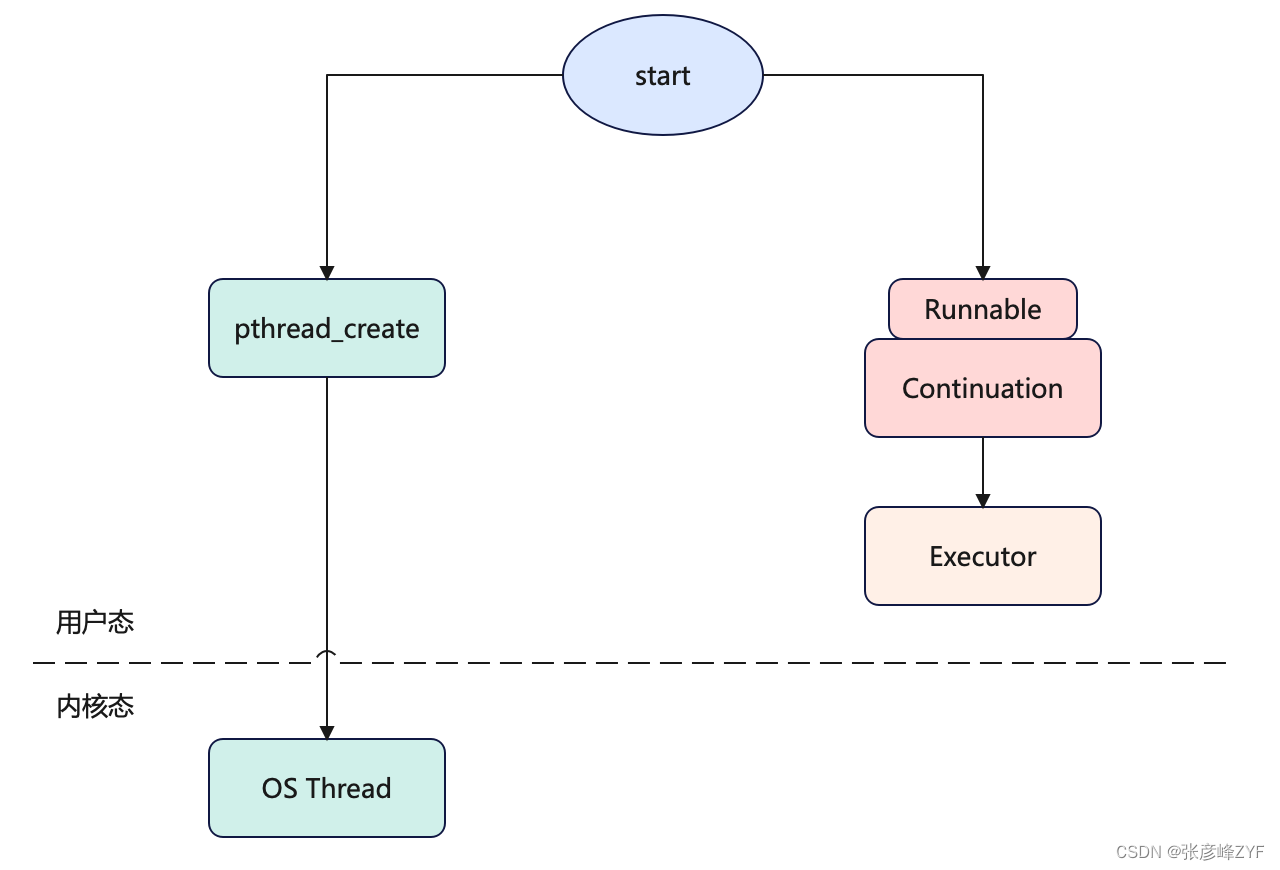
默认情况下,Java 19 使用 ForkJoinPool 作为调度器,但您也可以根据需要自定义调度器,以满足特定的应用程序需求。这种方式使得虚拟线程能够更灵活地适应各种并发编程场景,从而提高了 Java 的并发性能和编程模型的灵活性。
(二)SocketChannel.write()
简单看下SocketChannel 类的 write 方法源码:
class SocketChannelImpl extends SocketChannel implements SelChImpl {
@Override
public int write(ByteBuffer buf) throws IOException {
// 获取当前是否是阻塞模式
boolean blocking = isBlocking();
// 在虚拟线程模式下,将套接字通道配置为非阻塞
configureSocketNonBlockingIfVirtualThread();
// 执行套接字通道的写入操作,将结果存储在 'n' 中
n = IOUtil.write(fd, buf, -1, nd);
// 如果套接字通道是阻塞模式
if (blocking) {
// 在 Net.POLLOUT 事件发生之前挂起当前线程
park(Net.POLLOUT);
// 这里可以包含等待后的处理逻辑,例如处理写入完成后的情况
}
// 返回写入的字节数
return n;
}
}
上面的configureSocketNonBlockingIfVirtualThread() 方法的插入表明这段代码是为了支持协程而进行的改造。
在协程的背景下,通常希望避免线程的阻塞,因为线程的创建和切换开销很大。相反,协程允许任务在需要时暂停和恢复,而不会阻塞整个线程。configureSocketNonBlockingIfVirtualThread() 方法的名称表明它的目的是在虚拟线程模式下将套接字通道配置为非阻塞模式,以支持协程的高效执行。
这种改造是为了让套接字通道在协程中的使用更加高效,允许协程在等待写入完成时暂停,而不会阻塞底层线程。这有助于提高并发性能和编程的灵活性,特别是在需要处理大量并发任务时。虚拟线程和协程是 Java 19 中的新特性,旨在改进并发编程模型。
class SocketChannelImpl extends SocketChannel implements SelChImpl {
// 配置套接字通道为非阻塞模式(如果当前线程是虚拟线程)
private void configureSocketNonBlockingIfVirtualThread() throws IOException {
// ...
// 检查是否已经强制设置为非阻塞模式
if (!forcedNonBlocking && Thread.currentThread().isVirtual()) {
// 如果未强制设置为非阻塞并且当前线程是虚拟线程
// 则执行以下操作
// ...
// 使用 IOUtil 工具类将文件描述符(fd)的套接字通道配置为非阻塞模式
IOUtil.configureBlocking(fd, false);
// 非阻塞模式的套接字通道允许读写操作非阻塞地进行,即不会等待数据的到来
// 非阻塞模式对协程的高效执行非常有用
// ...
// 其他可能的操作,这里没有提供具体的代码
}
}
}
-
forcedNonBlocking是一个标志,用于表示是否已经强制将套接字通道设置为非阻塞模式。如果已经强制设置为非阻塞模式,就不需要再次配置。 -
Thread.currentThread().isVirtual()用于检查当前线程是否是虚拟线程。如果是虚拟线程,就可以考虑将套接字通道配置为非阻塞模式,以支持协程的高效执行。 -
如果条件满足,即当前线程是虚拟线程并且未强制设置为非阻塞模式,则使用
IOUtil.configureBlocking方法将文件描述符fd的套接字通道配置为非阻塞模式。这允许套接字通道在非阻塞模式下进行读写操作。 -
非阻塞模式的套接字通道不会等待数据的到来,而是立即返回,这对于协程的高效执行非常有用。
请注意,代码片段中还有一些未提供的操作,这些操作可能包括错误处理、资源管理等方面的内容。这段代码的主要目的是确保在虚拟线程中以非阻塞模式运行套接字通道,以支持协程的高效执行。
协程的一个重要特性之一是将原本的阻塞操作转换为非阻塞操作,从而提高程序的并发性和效率。这是协程实现的关键之一,允许在协程中执行I/O操作、等待事件等操作,而不会阻塞整个线程。
在传统的多线程编程中,阻塞一个线程通常需要等待底层操作完成,这可能会导致线程的资源浪费。而协程允许线程在执行到阻塞点时暂停,将控制权交给其他协程,直到底层操作完成后再恢复执行。这种非阻塞的操作方式可以提高程序的并发性,允许在不增加线程数量的情况下处理更多的并发任务。
协程的实现通常使用底层的事件循环、异步I/O、非阻塞调度等技术,以实现这种非阻塞的操作。这使得开发者可以更容易地编写高效的并发代码,而无需过多考虑线程管理和同步问题。协程在各种编程语言中都有广泛的应用,以提高并发性能和简化异步编程。
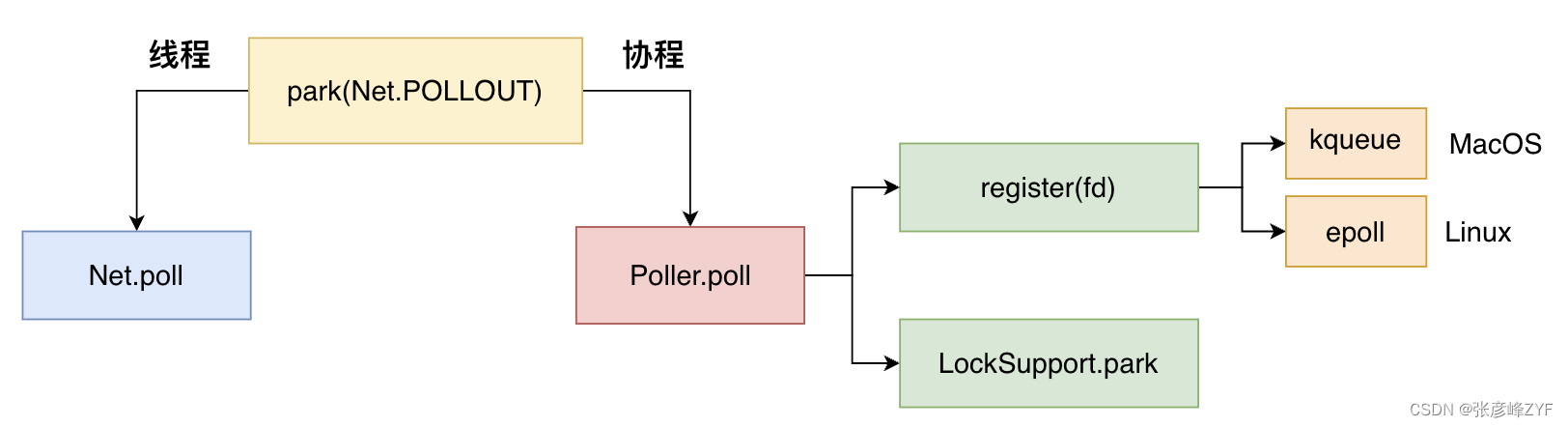
SocketChannel 的 write 方法里的 IO 操作,通过强制修改 fd 的属性,来达到非阻塞。接着我们来继续进入park(Net.POLLOUT) 方法来分析下:
public interface SelChImpl extends Channel {
// 默认的 park 方法,等同于调用 park(event, 0L)
default void park(int event) throws IOException {
park(event, 0L);
}
// park 方法,用于在事件发生前挂起当前线程
default void park(int event, long nanos) throws IOException {
// 检查当前线程是否是虚拟线程
if (Thread.currentThread().isVirtual()) {
// 如果当前线程是虚拟线程,使用 Poller.poll 来等待事件的发生
// 参数包括文件描述符、事件、等待的纳秒数和 isOpen() 方法的回调函数
Poller.poll(getFDVal(), event, nanos, this::isOpen);
} else {
// 如果当前线程不是虚拟线程
long millis;
// 计算等待的毫秒数(由纳秒转换而来)
// 这里可以有其他计算等待时间的逻辑
// 使用 Net.poll 来等待事件的发生
// 参数包括文件描述符、事件和等待的毫秒数
Net.poll(getFD(), event, millis);
}
}
}
代码通过条件语句检查当前上下文是协程还是线程,并选择不同的等待事件发生的方式。现在,深入了解 Poller.poll(...) 方法,因为它是关键部分。
public abstract class Poller {
// 静态方法用于等待事件的发生
public static void poll(int fdVal, int event, long nanos, BooleanSupplier supplier)
throws IOException {
// ...
// 获取适当的 Poller 实例并调用 poll 方法
writePoller(fdVal).poll(fdVal, nanos, supplier);
// ...
}
// poll 方法,用于注册文件描述符并等待事件的发生
private void poll(int fdVal, long nanos, BooleanSupplier supplier) throws IOException {
// ...
// 调用 poll1 方法进一步处理
poll1(fdVal, nanos, supplier);
// ...
}
// poll1 方法,用于注册文件描述符并等待事件的发生
private void poll1(int fdVal, long nanos, BooleanSupplier supplier) throws IOException {
// 注册文件描述符,将其关联到事件监听
register(fdVal);
// ...
// 使用 LockSupport.park() 暂停当前线程,等待事件的发生
// 当事件发生时,线程会被唤醒继续执行
LockSupport.park();
// ...
}
}
Poller.poll(...) 方法的主要功能是等待指定事件的发生。这个方法通常用于异步编程,其中任务需要等待某种事件,例如套接字可写、可读、连接完成等等。在协程模式下,这种等待通常是非阻塞的,允许协程在等待事件时让出线程(或虚拟线程)的执行,从而执行其他协程。
poll1 方法的主要作用是注册文件描述符(fd)并等待事件的发生。这个过程通常与异步 I/O 和多路复用机制相关。
多路复用是一种 I/O 模型,允许一个进程或线程监视多个文件描述符(通常是套接字、管道等),并在其中任何一个文件描述符上发生可读、可写或异常事件时获得通知。这样的机制非常有用,因为它允许程序有效地等待多个事件,而不必创建多个线程来处理每个事件。
以下是 poll1 方法中涉及的关键部分:
-
register(fdVal):这是一个关键步骤,它用于将文件描述符fdVal注册到事件监听机制中。具体实现会依赖于底层的事件监听机制,通常会使用操作系统提供的多路复用机制,如select、poll、epoll或kqueue。 -
注册后,文件描述符将与期望的事件类型(例如可读、可写等)相关联,以便在事件发生时能够通知程序。
-
一旦文件描述符注册成功,程序会进入等待事件的状态。这时,程序将被挂起,不会继续执行,直到有一个或多个已注册的文件描述符上发生了关注的事件。
-
LockSupport.park():在等待事件的时候,LockSupport.park()用于暂停当前线程,将其置于休眠状态。这个方法通常由事件监听机制触发,当事件发生时,它会唤醒被挂起的线程,以便线程可以继续执行。
总的来说,poll1 方法中的注册文件描述符和等待事件的过程是异步 I/O 和多路复用机制的关键部分。它使程序能够有效地等待多个文件描述符上的事件发生,而不必阻塞线程,从而提高程序的并发性和性能。具体的实现细节会根据操作系统和编程语言库的不同而有所不同。
代码再次展开:
public abstract class Poller {
// 使用 native 方法注册文件描述符到事件监听机制中
static native int register(int kqfd, int fd, int filter, int flags);
// 注册文件描述符并关联到当前线程
private void register(int fdVal) throws IOException {
// 将文件描述符关联到当前线程,以便在事件发生时可以找到相应的线程
map.putIfAbsent(fdVal, Thread.currentThread());
// 调用底层实现的注册方法
implRegister(fdVal);
}
}
class KQueuePoller extends Poller {
@Override
// 实现具体的注册逻辑
void implRegister(int fdVal) throws IOException {
// 使用 KQueue 的注册方法将文件描述符注册到事件监听机制中
int err = KQueue.register(kqfd, fdVal, filter, (EV_ADD|EV_ONESHOT));
// 处理可能的错误
// ...
}
}
park(Net.POLLOUT) 方法的改造如下图所示:
回到 poll1 方法,在通过 kqueue 或 epoll 注册好 fd 后,调用了 LockSupport.park() 方法
public class LockSupport {
// 阻塞当前线程
public static void park() {
// 检查当前线程是否是虚拟线程
if (Thread.currentThread().isVirtual()) {
// 如果当前线程是虚拟线程,使用 VirtualThreads.park() 来阻塞
VirtualThreads.park();
} else {
// 如果当前线程不是虚拟线程,使用 U.park(false, 0L) 来阻塞
// 这通常是传统线程模型的阻塞方式
U.park(false, 0L);
}
}
}
LockSupport.park() 方法根据当前线程的类型(虚拟线程或传统线程)选择适当的阻塞方式。这使得协程和传统线程可以在同一代码中使用,具有不同的阻塞语义,以适应不同的执行模型。
继续分析VirtualThreads 里的 park 方法:
public final class VirtualThreads {
// 阻塞当前虚拟线程
public static void park() {
// 调用 JLA.parkVirtualThread() 来实现虚拟线程的阻塞
JLA.parkVirtualThread();
}
}
public final class System {
// 阻塞当前虚拟线程
public void parkVirtualThread() {
// 获取当前线程
Thread thread = Thread.currentThread();
// 检查当前线程是否是 BaseVirtualThread 的实例
if (thread instanceof BaseVirtualThread vthread) {
// 如果是虚拟线程,调用 vthread.park() 来实现阻塞
vthread.park();
} else {
// 如果不是虚拟线程,抛出 WrongThreadException 异常
throw new WrongThreadException();
}
}
}
final class VirtualThread extends BaseVirtualThread {
// 阻塞当前虚拟线程
@Override
void park() {
// 设置虚拟线程的状态为 PARKING,表示正在等待
setState(PARKING);
// 执行 yieldContinuation(),将控制权交给其他协程
// 这允许虚拟线程在等待事件的同时不占用线程资源,提高并发性能
yieldContinuation();
// ... 在 yieldContinuation 后执行其他操作
}
}
在上面的代码中,当在普通线程上下文中调用 park 时,它会调用 native void park,这将导致线程陷入内核态并阻塞当前线程。然而,在协程中,情况不同。
在协程中,park 不会导致线程阻塞。相反,它会设置一个状态标识位为 PARKING,然后调用 yieldContinuation() 方法。这是协程模型中的关键操作,它会使协程出让调度权,但不会阻塞线程。这意味着协程可以在等待事件的同时不占用线程资源,允许其他协程执行,从而提高了程序的并发性能。yieldContinuation() 方法展示如下:
final class VirtualThread extends BaseVirtualThread {
// 使用 @ChangesCurrentThread 注解标记该方法
@ChangesCurrentThread
private boolean yieldContinuation() {
// ...
// 调用 Continuation.yield(VTHREAD_SCOPE) 来让出调度权
return Continuation.yield(VTHREAD_SCOPE);
}
}
到目前为止,可以看出Continuation 类的 run 和 yield 方法是协程模型中的关键方法,用于实现协程的非阻塞调度和控制指令流的开始和暂停。以下是如何理解它们的关键作用:
-
run方法:run方法用于启动协程的执行。当调用run方法时,协程会开始执行,它会运行直到遇到yield操作或完成协程的任务。与传统线程不同,run方法不会阻塞当前线程。它允许协程在非阻塞的情况下执行,因此不会浪费线程资源。 -
yield方法:yield方法用于暂停当前协程的执行,让出控制权给调度器。当协程执行到yield时,它会停止执行,并将控制权返回给调度器。这意味着其他协程可以继续执行,而当前协程处于暂停状态。yield方法实现了协程的出让和控制指令流的暂停。它是协程非阻塞等待事件的关键。
综合起来,run 方法和 yield 方法协同工作,使协程能够以非阻塞的方式执行,并具有以下特点:
- 协程可以在非阻塞的情况下启动和暂停。
- 协程可以有效地利用线程资源,因为它们不会阻塞线程。
- 协程之间可以通过
yield控制指令流的开始和暂停,以协同执行。 - 调度器可以有效地管理协程的执行,使程序具有更好的并发性能。
总的来说,Continuation 类的 run 和 yield 方法是实现协程模型的关键部分,它们允许协程在非阻塞的情况下执行,提高了程序的并发性能。
(三)Continuation
Continuation 类是 Loom 项目中的一项核心技术,它被合并到了 JDK 19 中。这个类位于 jdk.internal.vm 包下,它的存在为协程提供了底层的支持和实现。Continuation 允许协程在非阻塞的情况下执行,并实现了协程的控制和状态管理。这一技术的引入为 Java 引入了协程模型,使得 Java 可以更好地处理并发和异步编程,提高了代码的可读性和性能。因此,Continuation 类在协程模型的实现中具有重要作用。
public class Continuation {
// 运行协程
public final void run() {
while (true) {
// ...
// 获取当前线程
Thread t = currentCarrierThread();
// 检查是否有父协程
if (parent != null) {
if (parent != JLA.getContinuation(t))
throw new IllegalStateException();
} else
this.parent = JLA.getContinuation(t);
// 设置当前线程的协程为当前协程
JLA.setContinuation(t, this);
try {
boolean isVirtualThread = (scope == JLA.virtualThreadContinuationScope());
// 检查是否是协程的第一次运行
if (!isStarted()) { // is this the first run? (at this point we know !done)
enterSpecial(this, false, isVirtualThread);
} else {
assert !isEmpty();
enterSpecial(this, true, isVirtualThread);
}
} finally {
// ...
}
// 现在我们在父协程中
assert yieldInfo == null || yieldInfo instanceof ContinuationScope;
// 检查是否需要让出调度
if (yieldInfo == null || yieldInfo == scope) {
this.parent = null;
this.yieldInfo = null;
return;
}
// ...
}
}
}
(四)写事件到达时唤醒协程
Poller 类有个 static 方法,这是循环监听写事件的起点。
public abstract class Poller {
static {
...
// 创建读取和写入 Pollers
Poller[] readPollers = createReadPollers(provider);
Poller[] writePollers = createWritePollers(provider);
...
}
// 创建写入 Pollers
private static Poller[] createWritePollers(PollerProvider provider) throws IOException {
...
// 创建写入 Poller 数组
Poller[] writePollers = new Poller[writePollerCount];
for (int i = 0; i< writePollerCount; i++) {
...
// 启动写入 Poller 并将其保存在数组中
writePollers[i] = poller.start();
}
return writePollers;
}
// 启动 Poller
private Poller start() {
// 根据读取或写入操作选择前缀
String prefix = (read) ? "Read" : "Write";
// 启动线程,运行 pollLoop 方法
startThread(prefix + "-Poller", this::pollLoop);
...
}
// Poller 的主循环
private void pollLoop() {
...
for (;;) {
// 执行 poll 操作
poll();
}
...
}
}
在 macos 中,具体会调用到 kqueue 相关方法,从之前 fd 对应 thread 的 map 中取出 thread,调用 LockSupport.unpark 方法。
class KQueuePoller extends Poller {
// 覆盖 Poller 类的 poll 方法
@Override
int poll(int timeout) throws IOException {
...
// 执行轮询操作并获取结果
polled(fdVal);
...
}
// 在轮询结果中处理事件
final void polled(int fdVal) {
// 唤醒相关线程
wakeup(fdVal);
}
// 唤醒线程的私有方法
private void wakeup(int fdVal) {
// 从映射中获取相关线程
Thread t = map.remove(fdVal);
// 使用 LockSupport.unpark 方法唤醒线程
LockSupport.unpark(t);
}
}
而 LockSupport 的 unpark 同上述的 park 方法一样,也是进行了协程相关的改造。
public class LockSupport {
// 解锁线程
public static void unpark(Thread thread) {
if (thread != null) {
if (thread.isVirtual()) {
// 如果线程是虚拟线程,则使用 VirtualThreads 类的 unpark 方法解锁
VirtualThreads.unpark(thread);
} else {
// 否则,使用 U 类的 unpark 方法解锁
U.unpark(thread);
}
}
}
}
最终同 park 类似,也是调用了 Continuation 的方法来操作协程,具体来说是 run 方法。
final class VirtualThread extends BaseVirtualThread {
// 解锁虚拟线程
void unpark() {
// ...
// 提交运行协程
submitRunContinuation();
// ...
}
// 提交运行协程的私有方法
private void submitRunContinuation(boolean lazySubmit) {
// ...
// 使用调度器执行 runContinuation 方法
scheduler.execute(runContinuation);
// ...
}
// 运行协程的私有方法
private void runContinuation() {
// ...
// 执行协程的 run 方法
cont.run();
// ...
}
}
四、原理总结
JDK 中协程的核心原理和工作方式的出色总结:
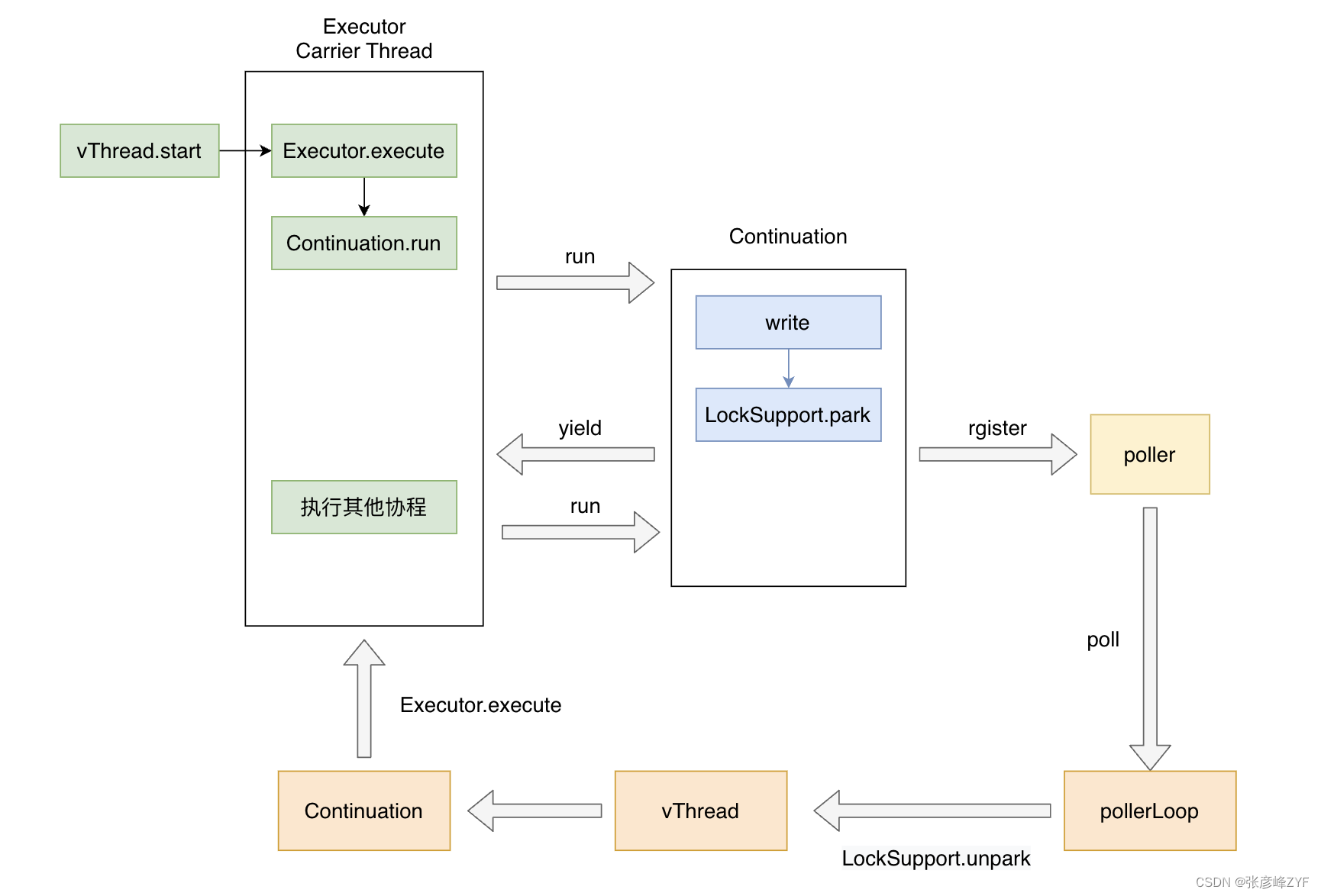
- 协程的本质是 Continuation(协程控制流)、Scheduler(线程调度)、以及对阻塞操作的改造的组合。
- Continuation 允许协程在一段指令流中进行 run 和 yield 操作,从而实现协程的切换和非阻塞执行。
- 阻塞操作的改造使得开发者可以编写易读的同步代码,同时在需要时主动 yield 让出控制权,实现异步执行。
- Scheduler 仅用于提供执行协程的线程,可以是单个线程或线程池,只需实现 Executor 接口即可。
在 JDK 协程中,核心原理是将 IO 操作从原来的阻塞式改为非阻塞式,通过 Continuation.yield() 暂停当前协程,交给调度器 Executor 继续执行其他协程,然后在IO操作完成后,使用 Continuation.run() 方法来恢复等待的协程,继续执行。
五、备注:JDK 19 协程是 Project Loom 项目的延续
JDK 19 中的协程是建立在之前的大量铺垫工作和发展历程之上的。以下是一些关键的历史和铺垫工作:
-
Project Loom:JDK 19 中的协程是 Project Loom 的一部分。Project Loom 是 JDK 的一个项目,旨在提供更轻量级的并发编程模型,使 Java 更容易编写高效的非阻塞和并发代码。这个项目于 JDK 16 时开始,并持续了多个版本。
-
Fiber 和 Virtual Threads:在 Project Loom 中,JDK 引入了 "Fiber"(纤程)的概念,它是一种轻量级的线程。这些 Fibers 可以在一个或多个物理线程上运行,而不需要创建额外的 OS 线程。同时,Virtual Threads(虚拟线程)是 Project Loom 中的一个关键概念,它们是一种特殊类型的 Fiber,用于支持协程。
-
Continuation 和 Stack-Walking API:在 Loom 项目中,引入了 Continuation 和 Stack-Walking API,这是实现协程的底层技术。Continuation 允许控制流的暂停和继续,而 Stack-Walking API 允许协程捕获和管理它们的执行栈。
-
VirtualThread 和 VirtualCallSite:JDK 18 中引入了 VirtualThread 和 VirtualCallSite 这两个关键的 API,它们为协程的实现提供了基础。VirtualThread 允许创建虚拟线程,而 VirtualCallSite 允许捕获和切换协程。
-
调度器 Scheduler 和 Executor:JDK 19 中引入了 Scheduler 和 Executor 接口,用于管理和调度协程。Scheduler 提供了对线程的抽象,可以是单线程或线程池,而 Executor 接口用于执行协程。
-
改造阻塞操作:JDK 19 对阻塞操作进行了改造,以将它们转换为非阻塞操作。这使得协程能够在执行 IO 操作时让出控制权,从而不会阻塞整个线程。
综上所述,JDK 19 的协程是 Project Loom 项目的延续,它建立在之前的 Loom 版本中引入的概念和技术之上。这些概念包括 Fibers、Virtual Threads、Continuations、Stack-Walking API、VirtualThread、VirtualCallSite 等。这个漫长的发展历程和铺垫工作使得 JDK 19 的协程成为可能,为 Java 带来了更灵活的并发编程模型。