一、模型分析和处理:
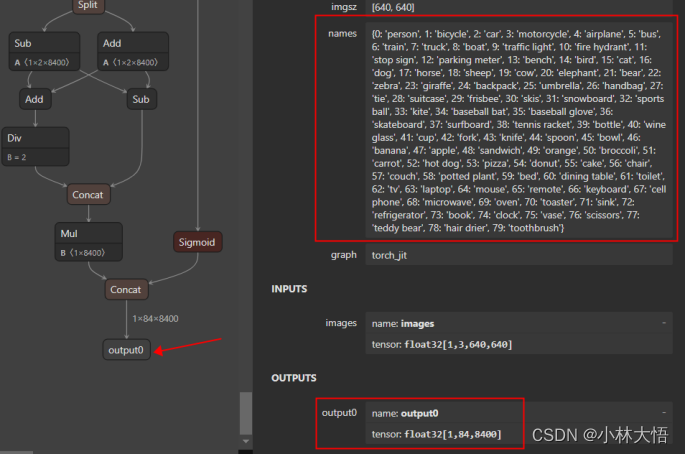
yolov8模型输出格式为84*8400,结合网络资料和上图的网络模型分析,可以得出如下结论:
84 = 边界框预测4 + 数据集类别80
搜索得知yolov8不另外对置信度预测,而是采用类别里面最大的概率作为置信度score,显然8400就是v8模型各尺度输出特征图叠加之后的结果。
综合以上信息v8的数据处理方式按照如下步骤实现:
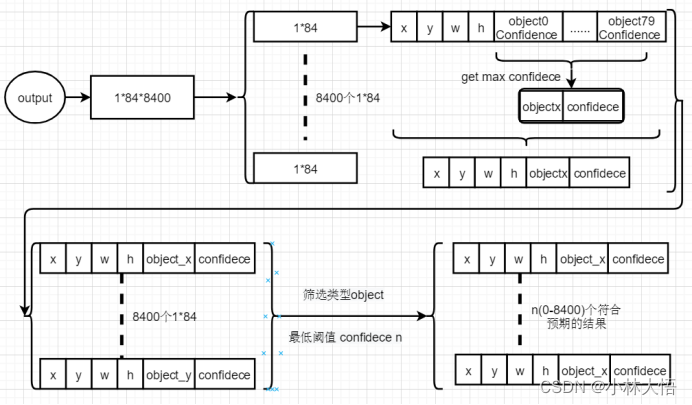
参考网址:https://blog.csdn.net/kuabiku/article/details/132083671
二、数据集
有部分模型输出没有描述自己支持的类型,可以根据矩形的大小来推测。每个网络会有自己输出的一个数据类型集合,该数据集大概率上就是目前比较流行的数据集。可以根据网络输出的类型个数来对比当前比较流行的数据集大小来确认可能得数据集。
coco数据集和yolov8的输出个数一致,内容也是一致的。
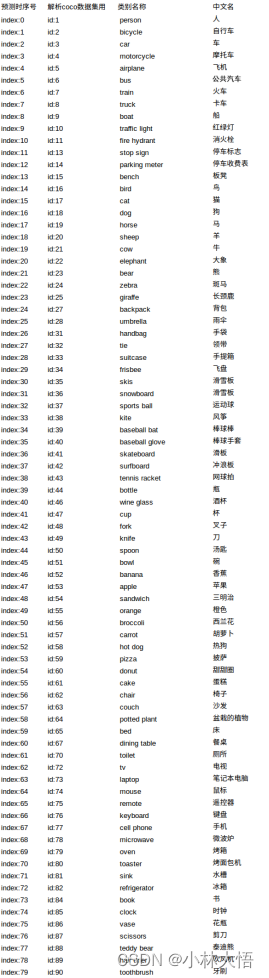
三、数据集平台
目前市场占有率非常大的数据集平台有三个:
Kaggle:爱竞赛的盆友们应该很熟悉了,Kaggle上有各种有趣的数据集,拉面评级、篮球数据、甚至西雅图的宠物许可证。
https://www.kaggle.com/
UCI机器学习库:最古老的数据集源之一,是寻找有趣数据集的第一站。虽然数据集是用户贡献的,因此具有不同的清洁度,但绝大多数都是干净的,可以直接从UCI机器学习库下载,无需注册。
http://mlr.cs.umass.edu/ml/
VisualData:分好类的计算机视觉数据集,可以搜索~
https://www.visualdata.io/