- 本文基于上一篇博客:[爬虫练手]整理学校招生信息
文章目录
- 一.改进上一篇的代码
- 二,嵌套爬虫,提取院系和专业信息
- 目前完整代码
- 三.让AI润色一下代码
- 完整代码
- 代码学习
- 加入print语句,方便理解
- 其他
一.改进上一篇的代码
上一篇那个页面没有反爬措施😂
为了让代码逻辑更清晰些,之后思路可复用,找了一个模板,套进去
import requests
from bs4 import BeautifulSoup
# Step 1: 访问网页并获取响应内容
def get_html_content(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
html_content = response.text
return html_content
except Exception as e:
print(f"网络请求异常:{e}")
return None
# Step 2: 解析网页并提取目标数据
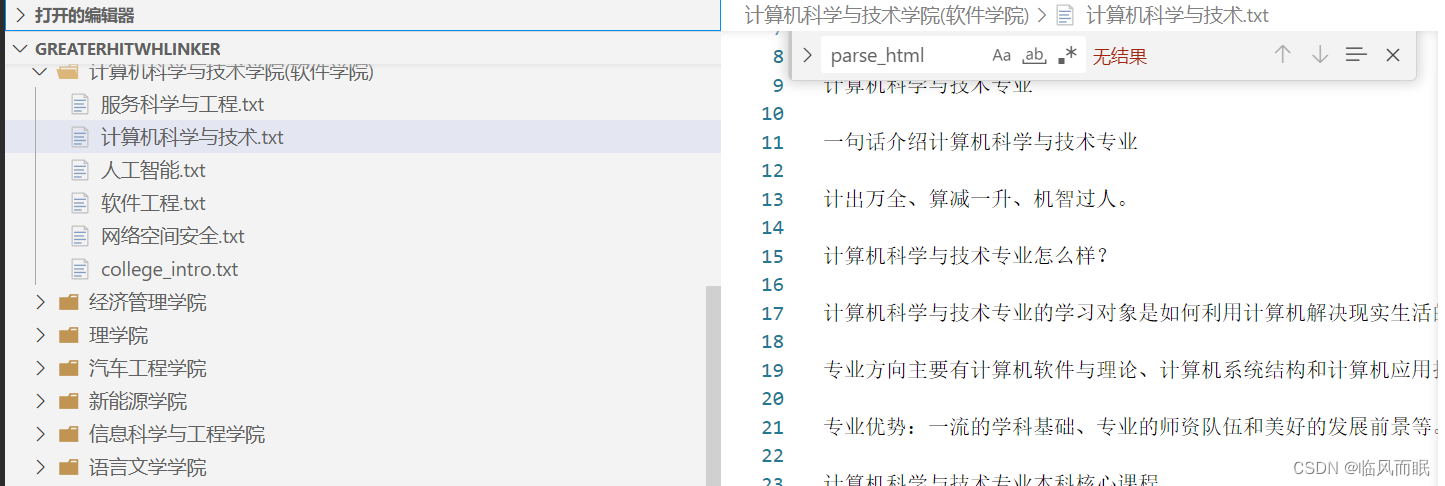
def parse_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
rows = soup.select('tbody tr')
# Variables to hold rowspan data
remaining_rows_major_name = 0
current_major_name = None
remaining_rows_category = 0
current_category = None
remaining_rows_subjects = 0
current_subjects = None
remaining_rows_college_detail = 0
current_college_name = None
current_college_link = None
data_list = []
for row in rows:
# ... 此处省略,见上一篇blog
data_list.append({
"Major Name": major_name,
"Category": category,
"Subject Requirements": subject_req,
"College Name": college_name,
"College Link": college_link,
"Major Detail Name": major_detail_name,
"Major Detail Link": major_detail_link
})
return data_list
# Step 3: 存储数据到本地或其他持久化存储服务器中
def store_data(result_list):
# TODO:编写存储代码,将数据结果保存到本地或其他服务器中
pass
# Step 4: 控制流程,调用上述函数完成数据抓取任务
if __name__ == '__main__':
target_url = "http://www.example.com"
html_content = get_html_content(target_url)
if html_content:
result_list = parse_html(html_content)
store_data(result_list)
else:
print("网页访问失败")
二,嵌套爬虫,提取院系和专业信息
- 那个网站里面,院系和专业点击之后都会跳转

- 那么去看看他们的页面是咋样的

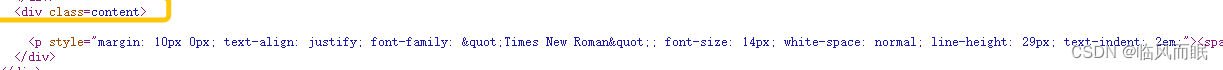
而且这个class是唯一的
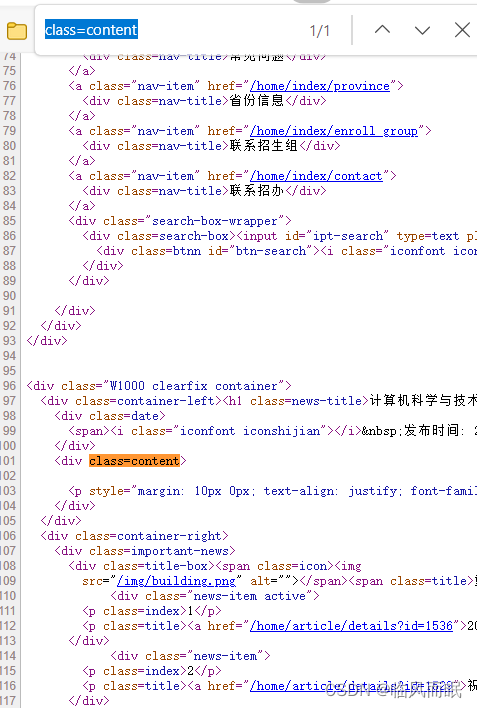
-
这样的话就不难了
-
我希望能通过一次爬取,建立院系的文件夹,然后把该院系的所有专业介绍存入该文件夹下
-
同时需要注意一个问题,爬取出来的txt,不希望是那么多文字都在一行,希望原文分段,我的txt里面也分段
def store_data(item): # 获取学院链接和专业详情链接 college_link = item['College Link'] major_detail_link = item['Major Detail Link'] # 如果学院链接存在,则进行以下处理 if college_link: college_name = item['College Name'] # 获取学院的HTML内容 college_html = get_html_content(f"http://zsb.hitwh.edu.cn{college_link}") if college_html: # 使用BeautifulSoup解析HTML内容 college_soup = BeautifulSoup(college_html, 'html.parser') # 从解析后的内容中查找class为"content"的部分 college_content = college_soup.select_one('.content') if college_content: # 为学院创建一个目录,以保存相关文件 college_dir = f"{college_name}" # 如果目录不存在,则创建 if not os.path.exists(college_dir): os.makedirs(college_dir) # 定义文件名并打开文件,准备写入数据 filename = f"{college_dir}/{college_name}.txt" with open(filename, mode='w', encoding='utf-8') as file: # 查找所有段落,并逐一写入文件 paragraphs = college_content.find_all('p') for paragraph in paragraphs: file.write(paragraph.get_text() + '\n\n') # 如果专业详情链接存在,则进行以下处理 if major_detail_link: major_detail_name = item['Major Detail Name'] # 获取专业详情的HTML内容 major_detail_html = get_html_content( f"http://zsb.hitwh.edu.cn{major_detail_link}") if major_detail_html: # 使用BeautifulSoup解析HTML内容 major_detail_soup = BeautifulSoup(major_detail_html, 'html.parser') # 从解析后的内容中查找class为"content"的部分 major_detail_content = major_detail_soup.select_one('.content') if major_detail_content: college_name = item['College Name'] # 使用学院的名称作为目录 major_dir = f"{college_name}" # 如果目录不存在,则创建 if not os.path.exists(major_dir): os.makedirs(major_dir) # 定义文件名并打开文件,准备写入数据 filename = f"{major_dir}/{major_detail_name}.txt" with open(filename, mode='w', encoding='utf-8') as file: # 查找所有段落,并逐一写入文件 paragraphs = major_detail_content.find_all('p') for paragraph in paragraphs: file.write(paragraph.get_text() + '\n\n')
目前完整代码
import os
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
# Step 1: 访问网页并获取响应内容
def get_html_content(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
html_content = response.text
return html_content
except Exception as e:
print(f"网络请求异常:{e}")
return None
# Step 2: 解析网页并提取目标数据
def parse_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
rows = soup.select('tbody tr')
data = []
# Variables for handling rowspan attributes
remaining_rows_major_name = 0
current_major_name = None
remaining_rows_category = 0
current_category = None
remaining_rows_subjects = 0
current_subjects = None
remaining_rows_college_detail = 0
current_college_name = None
current_college_link = None
for row in rows:
# Handling major_name
if remaining_rows_major_name > 0:
major_name = current_major_name
remaining_rows_major_name -= 1
else:
major_name_ele = row.select_one('.left-td')
if major_name_ele:
major_name = major_name_ele.get_text(strip=True)
current_major_name = major_name
if 'rowspan' in major_name_ele.attrs:
remaining_rows_major_name = int(
major_name_ele['rowspan']) - 1
# Handling category
if remaining_rows_category > 0:
category = current_category
remaining_rows_category -= 1
else:
category_ele = row.select_one('.text-center')
if category_ele:
category = category_ele.get_text(strip=True)
current_category = category
if 'rowspan' in category_ele.attrs:
remaining_rows_category = int(category_ele['rowspan']) - 1
# Handling subjects
if remaining_rows_subjects > 0:
subject_req = current_subjects
remaining_rows_subjects -= 1
else:
subjects = row.select('td.text-center')
subject_req = [subj.get_text(strip=True) for subj in subjects[1:]] if len(
subjects) > 1 else []
current_subjects = subject_req
if subjects and 'rowspan' in subjects[0].attrs:
remaining_rows_subjects = int(subjects[0]['rowspan']) - 1
# Handling college_detail
if remaining_rows_college_detail > 0:
college_name = current_college_name
college_link = current_college_link
remaining_rows_college_detail -= 1
else:
college_detail = row.select_one('td[rowspan] > a')
if college_detail:
college_name = college_detail.get_text(strip=True)
college_link = college_detail['href']
current_college_name = college_name
current_college_link = college_link
if 'rowspan' in college_detail.find_parent().attrs:
remaining_rows_college_detail = int(
college_detail.find_parent()['rowspan']) - 1
# Handling major_detail
major_detail = row.select_one('.right-td > a')
major_detail_name = major_detail.get_text(
strip=True) if major_detail else None
major_detail_link = major_detail['href'] if major_detail else None
# Appending data to the list
data.append({
"Major Name": major_name,
"Category": category,
"Subject Requirements": subject_req,
"College Name": college_name,
"College Link": college_link,
"Major Detail Name": major_detail_name,
"Major Detail Link": major_detail_link
})
return data
# Step 3: 存储数据到本地或其他持久化存储服务器中
def store_data(item):
college_link = item['College Link']
major_detail_link = item['Major Detail Link']
if college_link:
college_name = item['College Name']
college_html = get_html_content(
f"http://zsb.hitwh.edu.cn{college_link}")
if college_html:
college_soup = BeautifulSoup(college_html, 'html.parser')
college_content = college_soup.select_one('.content') #.content 的意思是 class="content"
if college_content:
college_dir = f"{college_name}"
if not os.path.exists(college_dir):
os.makedirs(college_dir)
filename = f"{college_dir}/{college_name}.txt"
with open(filename, mode='w', encoding='utf-8') as file:
paragraphs = college_content.find_all('p')
for paragraph in paragraphs:
file.write(paragraph.get_text() + '\n\n')
if major_detail_link:
major_detail_name = item['Major Detail Name']
major_detail_html = get_html_content(
f"http://zsb.hitwh.edu.cn{major_detail_link}")
if major_detail_html:
major_detail_soup = BeautifulSoup(major_detail_html, 'html.parser')
major_detail_content = major_detail_soup.select_one('.content')
if major_detail_content:
college_name = item['College Name']
major_dir = f"{college_name}"
if not os.path.exists(major_dir):
os.makedirs(major_dir)
filename = f"{major_dir}/{major_detail_name}.txt"
with open(filename, mode='w', encoding='utf-8') as file:
paragraphs = major_detail_content.find_all('p')
for paragraph in paragraphs:
file.write(paragraph.get_text() + '\n\n')
# Step 4: 控制流程,调用上述函数完成数据抓取任务
if __name__ == '__main__':
url = "http://zsb.hitwh.edu.cn/home/major/index"
html_content = get_html_content(url)
if html_content:
data_list = parse_html(html_content)
with ThreadPoolExecutor(max_workers=10) as executor: # ThreadPoolExecutor是一个线程池,max_workers是最大线程数
for item in data_list:
executor.submit(store_data, item)
else:
print("网页访问失败")
三.让AI润色一下代码
我让copilot和chatgpt让代码更高效些,然后引入了多线程和异步
完整代码
import os
import aiohttp
import aiofiles
from bs4 import BeautifulSoup
import asyncio
async def get_html_content(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as response:
if response.status == 200:
return await response.text()
return None
# Step 2: 解析网页并提取目标数据
def parse_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
rows = soup.select('tbody tr')
data = []
# Variables for handling rowspan attributes
remaining_rows_major_name = 0
current_major_name = None
remaining_rows_category = 0
current_category = None
remaining_rows_subjects = 0
current_subjects = None
remaining_rows_college_detail = 0
current_college_name = None
current_college_link = None
for row in rows:
# Handling major_name
if remaining_rows_major_name > 0:
major_name = current_major_name
remaining_rows_major_name -= 1
else:
major_name_ele = row.select_one('.left-td')
if major_name_ele:
major_name = major_name_ele.get_text(strip=True)
current_major_name = major_name
if 'rowspan' in major_name_ele.attrs:
remaining_rows_major_name = int(
major_name_ele['rowspan']) - 1
# Handling category
if remaining_rows_category > 0:
category = current_category
remaining_rows_category -= 1
else:
category_ele = row.select_one('.text-center')
if category_ele:
category = category_ele.get_text(strip=True)
current_category = category
if 'rowspan' in category_ele.attrs:
remaining_rows_category = int(category_ele['rowspan']) - 1
# Handling subjects
if remaining_rows_subjects > 0:
subject_req = current_subjects
remaining_rows_subjects -= 1
else:
subjects = row.select('td.text-center')
subject_req = [subj.get_text(strip=True) for subj in subjects[1:]] if len(
subjects) > 1 else []
current_subjects = subject_req
if subjects and 'rowspan' in subjects[0].attrs:
remaining_rows_subjects = int(subjects[0]['rowspan']) - 1
# Handling college_detail
if remaining_rows_college_detail > 0:
college_name = current_college_name
college_link = current_college_link
remaining_rows_college_detail -= 1
else:
college_detail = row.select_one('td[rowspan] > a')
if college_detail:
college_name = college_detail.get_text(strip=True)
college_link = college_detail['href']
current_college_name = college_name
current_college_link = college_link
if 'rowspan' in college_detail.find_parent().attrs:
remaining_rows_college_detail = int(
college_detail.find_parent()['rowspan']) - 1
# Handling major_detail
major_detail = row.select_one('.right-td > a')
major_detail_name = major_detail.get_text(
strip=True) if major_detail else None
major_detail_link = major_detail['href'] if major_detail else None
# Appending data to the list
data.append({
"Major Name": major_name,
"Category": category,
"Subject Requirements": subject_req,
"College Name": college_name,
"College Link": college_link,
"Major Detail Name": major_detail_name,
"Major Detail Link": major_detail_link
})
return data
# Step 3: 存储数据到本地或其他持久化存储服务器中
async def store_data(semaphore, item):
async with semaphore:
college_link = item['College Link']
major_detail_link = item['Major Detail Link']
if college_link:
college_name = item['College Name']
college_html = await get_html_content( # 使用await关键字
f"http://zsb.hitwh.edu.cn{college_link}")
if college_html:
college_soup = BeautifulSoup(college_html, 'html.parser')
college_content = college_soup.select_one('.content')
if college_content:
await write_to_file(college_name, college_content, "college_intro")
if major_detail_link:
major_detail_name = item['Major Detail Name']
major_detail_html = await get_html_content( # 使用await关键字
f"http://zsb.hitwh.edu.cn{major_detail_link}")
if major_detail_html:
major_detail_soup = BeautifulSoup(
major_detail_html, 'html.parser')
major_detail_content = major_detail_soup.select_one('.content')
if major_detail_content:
college_name = item['College Name']
await write_to_file(college_name, major_detail_content, major_detail_name)
async def write_to_file(college_name, content, filename=None):
dir_path = f"{college_name}"
if not os.path.exists(dir_path):
os.makedirs(dir_path)
if not filename:
filename = f"{college_name}.txt"
else:
filename = f"{college_name}/{filename}.txt"
async with aiofiles.open(filename, mode='w', encoding='utf-8') as file:
paragraphs = content.find_all('p')
for paragraph in paragraphs:
await file.write(paragraph.get_text() + '\n\n')
if __name__ == '__main__':
url = "http://zsb.hitwh.edu.cn/home/major/index"
loop = asyncio.get_event_loop()
html_content = loop.run_until_complete(get_html_content(url))
if html_content:
data_list = parse_html(html_content)
semaphore = asyncio.Semaphore(10) # 限制并发数量为10
tasks = [store_data(semaphore, item) for item in data_list]
loop.run_until_complete(asyncio.gather(*tasks))
else:
print("网页访问失败")
代码学习
AI时代很大的好处就是,一个东西可以反复提问深挖,很多想法只要提出,就能很快先看到demo, 而且可以询问AI的思路,相当于不断在向高手学习和请教
- 先让AI给出解释
-
异步编程基础:
异步编程允许你在等待一个操作完成的时候(例如,网络请求、文件读写等)执行其他任务。你可以将其想象为在家做饭。你把米放进电饭煲并开始煮饭,而不是等米饭煮好才开始准备其他食材,你会立刻开始切菜、炒菜。这就是异步:你在等待一个任务(煮饭)完成的时候执行其他任务(切菜、炒菜)。
-
async/await:
- async:定义一个异步函数。此函数在调用时不会立即执行,而是返回一个coroutine对象。
- await:在异步函数中等待另一个异步操作完成并返回结果。在我们的例子中,get_html_content函数是异步的,使用await来等待HTTP请求的响应。
- 考虑上面的做饭例子,async就像是开始煮饭的操作,而await就像是你检查饭是否已经煮好。
-
aiohttp:
传统的HTTP库,例如requests,在发送请求时会阻塞,直到收到响应。而aiohttp是一个异步HTTP客户端/服务器框架,它不会阻塞,可以与asyncio一起使用,实现真正的并发HTTP请求。
-
asyncio.Semaphore:
这是一个基本的同步原语,用于限制并发数量。在我们的代码中,我们使用它来确保同一时间只有10个请求。你可以将其看作餐厅只有10个座位,因此只能同时容纳10位顾客。
-
aiofiles:
文件读写通常是一个阻塞操作,但aiofiles提供了一个异步的方式来处理文件操作,使得你可以在等待文件写入/读取时执行其他任务。 -
BeautifulSoup:
一个用于从HTML和XML文件中提取数据的库。在我们的代码中,我们使用它来解析网页并获取所需的数据。
-
Python的异步事件循环:
asyncio.get_event_loop()获取当前的事件循环,loop.run_until_complete()则运行事件循环,直到指定的任务完成。在这份代码中,我们用它来运行我们的异步任务。
-
加入print语句,方便理解
# ... [其他代码片段不变]
# 定义异步函数用于获取网页内容
async def get_html_content(url):
print(f"开始获取网页内容: {url}")
# ... [其他代码片段不变]
print(f"完成获取网页内容: {url}")
return await response.text()
# ... [其他代码片段不变]
# 异步存储数据到本地或其他持久化存储服务器中
async def store_data(semaphore, item):
print(f"开始存储任务: {item['College Name']} - {item['Major Detail Name']}")
# ... [其他代码片段不变]
print(f"完成存储任务: {item['College Name']} - {item['Major Detail Name']}")
# ... [其他代码片段不变]
# 异步写入文件
async def write_to_file(college_name, content, filename=None):
print(f"开始写入文件: {filename}")
# ... [其他代码片段不变]
print(f"完成写入文件: {filename}")
# ... [其他代码片段不变]
打印结果如下
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/index
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/index
开始存储任务: 信息科学与工程学院 - 自动化
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
开始存储任务: 新能源学院 - 电气工程及其自动化
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=5
开始存储任务: 材料科学与工程学院 - 智能材料与结构
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
开始存储任务: 计算机科学与技术学院(软件学院) - 计算机科学与技术
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
开始存储任务: 计算机科学与技术学院(软件学院) - 人工智能
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
开始存储任务: 计算机科学与技术学院(软件学院) - 网络空间安全
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
开始存储任务: 信息科学与工程学院 - 通信工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
开始存储任务: 信息科学与工程学院 - 海洋信息工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
开始存储任务: 信息科学与工程学院 - 电子信息工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
开始存储任务: 信息科学与工程学院 - 微电子科学与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
开始存储任务: 理学院 - 光电信息科学与工程
开始存储任务: 海洋工程学院 - 机械设计制造及其自动化
开始存储任务: 海洋工程学院 - 机器人工程
开始存储任务: 汽车工程学院 - 车辆工程
开始存储任务: 汽车工程学院 - 智能车辆工程
开始存储任务: 信息科学与工程学院 - 测控技术与仪器
开始存储任务: 新能源学院 - 储能科学与工程
开始存储任务: 材料科学与工程学院 - 材料成型及控制工程
开始存储任务: 材料科学与工程学院 - 焊接技术与工程
开始存储任务: 计算机科学与技术学院(软件学院) - 软件工程
开始存储任务: 计算机科学与技术学院(软件学院) - 服务科学与工程
开始存储任务: 海洋工程学院 - 船舶与海洋工程
开始存储任务: 海洋工程学院 - 土木工程
开始存储任务: 新能源学院 - 储能科学与工程
开始存储任务: 信息科学与工程学院 - 海洋信息工程
开始存储任务: 信息科学与工程学院 - 测控技术与仪器
开始存储任务: 汽车工程学院 - 交通工程
开始存储任务: 汽车工程学院 - 车辆工程
开始存储任务: 海洋科学与技术学院 - 环境工程
开始存储任务: 海洋科学与技术学院 - 生物工程
开始存储任务: 海洋科学与技术学院 - 海洋技术
开始存储任务: 海洋科学与技术学院 - 化学工程与工艺
开始存储任务: 材料科学与工程学院 - 智能材料与结构
开始存储任务: 材料科学与工程学院 - 材料成型及控制工程
开始存储任务: 材料科学与工程学院 - 材料科学与工程
开始存储任务: 材料科学与工程学院 - 焊接技术与工程
开始存储任务: 理学院 - 数学与应用数学
开始存储任务: 理学院 - 信息与计算科学
开始存储任务: 经济管理学院 - 工商管理
开始存储任务: 经济管理学院 - 会计学
开始存储任务: 经济管理学院 - 国际经济与贸易
开始存储任务: 经济管理学院 - 信息管理与信息系统
开始存储任务: 语言文学学院 - 英语
开始存储任务: 语言文学学院 - 朝鲜语
开始存储任务: 海洋工程学院 - 船舶与海洋工程(中外合作)
开始存储任务: 材料科学与工程学院 - None
开始存储任务: 海洋工程学院 - None
开始存储任务: 海洋科学与技术学院 - None
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=5
开始写入文件: college_intro
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
完成写入文件: 材料科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=29
完成写入文件: 信息科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=18
完成写入文件: 新能源学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=20
完成写入文件: 信息科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=17
完成写入文件: 信息科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=16
完成写入文件: 信息科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=15
完成写入文件: 信息科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=13
完成写入文件: 计算机科学与技术学院(软件学院)/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=24
完成写入文件: 计算机科学与技术学院(软件学院)/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=23
完成写入文件: 计算机科学与技术学院(软件学院)/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=47
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=24
开始写入文件: 人工智能
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=15
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=20
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=47
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=16
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=29
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=23
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=13
开始写入文件: 通信工程
开始写入文件: 电气工程及其自动化
开始写入文件: 网络空间安全
开始写入文件: 海洋信息工程
开始写入文件: 智能材料与结构
开始写入文件: 计算机科学与技术
开始写入文件: 自动化
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=17
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=18
开始写入文件: 电子信息工程
开始写入文件: 微电子科学与工程
完成写入文件: 材料科学与工程学院/智能材料与结构.txt
完成存储任务: 材料科学与工程学院 - 智能材料与结构
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=8
完成写入文件: 计算机科学与技术学院(软件学院)/网络空间安全.txt
完成存储任务: 计算机科学与技术学院(软件学院) - 网络空间安全
完成写入文件: 信息科学与工程学院/海洋信息工程.txt
完成存储任务: 信息科学与工程学院 - 海洋信息工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成写入文件: 信息科学与工程学院/微电子科学与工程.txt
完成存储任务: 信息科学与工程学院 - 微电子科学与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=3
完成写入文件: 信息科学与工程学院/电子信息工程.txt
完成存储任务: 信息科学与工程学院 - 电子信息工程
完成写入文件: 信息科学与工程学院/通信工程.txt
完成存储任务: 信息科学与工程学院 - 通信工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=3
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成写入文件: 信息科学与工程学院/自动化.txt
完成存储任务: 信息科学与工程学院 - 自动化
完成写入文件: 计算机科学与技术学院(软件学院)/人工智能.txt
完成存储任务: 计算机科学与技术学院(软件学院) - 人工智能
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=5
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成写入文件: 新能源学院/电气工程及其自动化.txt
完成存储任务: 新能源学院 - 电气工程及其自动化
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成写入文件: 计算机科学与技术学院(软件学院)/计算机科学与技术.txt
完成存储任务: 计算机科学与技术学院(软件学院) - 计算机科学与技术
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=8
开始写入文件: college_intro
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=5
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=3
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=3
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
完成写入文件: 信息科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=72
完成写入文件: 理学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=36
完成写入文件: 新能源学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=21
完成写入文件: 材料科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=32
完成写入文件: 材料科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=31
完成写入文件: 海洋工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=2
完成写入文件: 汽车工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=10
完成写入文件: 海洋工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=1
完成写入文件: 汽车工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=9
完成写入文件: 计算机科学与技术学院(软件学院)/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=26
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=72
开始写入文件: 测控技术与仪器
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=10
开始写入文件: 智能车辆工程
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=31
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=36
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=26
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=9
开始写入文件: 光电信息科学与工程
开始写入文件: 软件工程
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=1
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=21
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=2
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=32
开始写入文件: 材料成型及控制工程
开始写入文件: 车辆工程
开始写入文件: 机械设计制造及其自动化
开始写入文件: 储能科学与工程
开始写入文件: 机器人工程
开始写入文件: 焊接技术与工程
完成写入文件: 海洋工程学院/机器人工程.txt
完成存储任务: 海洋工程学院 - 机器人工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
完成写入文件: 理学院/光电信息科学与工程.txt
完成存储任务: 理学院 - 光电信息科学与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成写入文件: 海洋工程学院/机械设计制造及其自动化.txt
完成存储任务: 海洋工程学院 - 机械设计制造及其自动化
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成写入文件: 汽车工程学院/智能车辆工程.txt
完成存储任务: 汽车工程学院 - 智能车辆工程
完成写入文件: 汽车工程学院/车辆工程.txt
完成存储任务: 汽车工程学院 - 车辆工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=5
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成写入文件: 新能源学院/储能科学与工程.txt
完成存储任务: 新能源学院 - 储能科学与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成写入文件: 信息科学与工程学院/测控技术与仪器.txt
完成存储任务: 信息科学与工程学院 - 测控技术与仪器
完成写入文件: 计算机科学与技术学院(软件学院)/软件工程.txt
完成存储任务: 计算机科学与技术学院(软件学院) - 软件工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=3
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=3
完成写入文件: 材料科学与工程学院/材料成型及控制工程.txt
完成存储任务: 材料科学与工程学院 - 材料成型及控制工程
完成写入文件: 材料科学与工程学院/焊接技术与工程.txt
完成存储任务: 材料科学与工程学院 - 焊接技术与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=6
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=5
开始写入文件: college_intro
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=4
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=3
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=3
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
完成写入文件: 新能源学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=21
完成写入文件: 海洋科学与技术学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=46
完成写入文件: 海洋科学与技术学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=5
完成写入文件: 信息科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=72
完成写入文件: 信息科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=16
完成写入文件: 计算机科学与技术学院(软件学院)/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=27
完成写入文件: 海洋工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=3
完成写入文件: 汽车工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=12
完成写入文件: 海洋工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=44
完成写入文件: 汽车工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=9
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=3
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=21
开始写入文件: 储能科学与工程
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=16
开始写入文件: 海洋信息工程
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=9
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=12
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=5
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=46
开始写入文件: 船舶与海洋工程
开始写入文件: 车辆工程
开始写入文件: 交通工程
开始写入文件: 生物工程
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=72
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=27
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=44
开始写入文件: 测控技术与仪器
开始写入文件: 服务科学与工程
开始写入文件: 土木工程
开始写入文件: 环境工程
完成写入文件: 汽车工程学院/交通工程.txt
完成存储任务: 汽车工程学院 - 交通工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
完成写入文件: 计算机科学与技术学院(软件学院)/服务科学与工程.txt
完成存储任务: 计算机科学与技术学院(软件学院) - 服务科学与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
完成写入文件: 汽车工程学院/车辆工程.txt
完成存储任务: 汽车工程学院 - 车辆工程
完成写入文件: 信息科学与工程学院/海洋信息工程.txt
完成存储任务: 信息科学与工程学院 - 海洋信息工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成写入文件: 新能源学院/储能科学与工程.txt
完成存储任务: 新能源学院 - 储能科学与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成写入文件: 海洋科学与技术学院/生物工程.txt
完成存储任务: 海洋科学与技术学院 - 生物工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成写入文件: 海洋工程学院/土木工程.txt
完成存储任务: 海洋工程学院 - 土木工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=8
完成写入文件: 信息科学与工程学院/测控技术与仪器.txt
完成存储任务: 信息科学与工程学院 - 测控技术与仪器
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=8
完成写入文件: 海洋科学与技术学院/环境工程.txt
完成存储任务: 海洋科学与技术学院 - 环境工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=9
完成写入文件: 海洋工程学院/船舶与海洋工程.txt
完成存储任务: 海洋工程学院 - 船舶与海洋工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=9
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
开始写入文件: college_intro
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=8
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=8
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=9
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=9
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
完成写入文件: 材料科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=28
完成写入文件: 海洋科学与技术学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=7
完成写入文件: 海洋科学与技术学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=8
完成写入文件: 材料科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=31
完成写入文件: 材料科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=32
完成写入文件: 材料科学与工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=29
完成写入文件: 理学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=34
完成写入文件: 理学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=35
完成写入文件: 经济管理学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=37
完成写入文件: 经济管理学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=38
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=32
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=7
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=28
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=35
开始写入文件: 海洋技术
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=37
开始写入文件: 焊接技术与工程
开始写入文件: 工商管理
开始写入文件: 信息与计算科学
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=8
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=34
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=31
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=38
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=29
开始写入文件: 材料科学与工程
开始写入文件: 化学工程与工艺
开始写入文件: 数学与应用数学
开始写入文件: 材料成型及控制工程
开始写入文件: 会计学
开始写入文件: 智能材料与结构
完成写入文件: 理学院/信息与计算科学.txt
完成存储任务: 理学院 - 信息与计算科学
完成写入文件: 海洋科学与技术学院/海洋技术.txt
完成存储任务: 海洋科学与技术学院 - 海洋技术
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=9
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=9
完成写入文件: 理学院/数学与应用数学.txt
完成存储任务: 理学院 - 数学与应用数学
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=10
完成写入文件: 材料科学与工程学院/智能材料与结构.txt
完成存储任务: 材料科学与工程学院 - 智能材料与结构
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=10
完成写入文件: 海洋科学与技术学院/化学工程与工艺.txt
完成存储任务: 海洋科学与技术学院 - 化学工程与工艺
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成写入文件: 材料科学与工程学院/材料科学与工程.txt
完成存储任务: 材料科学与工程学院 - 材料科学与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成写入文件: 经济管理学院/会计学.txt
完成存储任务: 经济管理学院 - 会计学
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成写入文件: 材料科学与工程学院/焊接技术与工程.txt
完成存储任务: 材料科学与工程学院 - 焊接技术与工程
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
完成写入文件: 材料科学与工程学院/材料成型及控制工程.txt
完成存储任务: 材料科学与工程学院 - 材料成型及控制工程
完成写入文件: 经济管理学院/工商管理.txt
完成存储任务: 经济管理学院 - 工商管理
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=9
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=10
开始写入文件: college_intro
开始写入文件: college_intro
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=7
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=2
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=10
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=9
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/college?id=1
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
开始写入文件: college_intro
完成写入文件: 语言文学学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=41
完成写入文件: 语言文学学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=42
完成写入文件: 海洋科学与技术学院/college_intro.txt
完成存储任务: 海洋科学与技术学院 - None
完成写入文件: 材料科学与工程学院/college_intro.txt
完成存储任务: 材料科学与工程学院 - None
完成写入文件: 经济管理学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=40
完成写入文件: 经济管理学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=39
完成写入文件: 海洋工程学院/college_intro.txt
完成存储任务: 海洋工程学院 - None
完成写入文件: 海洋工程学院/college_intro.txt
开始获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=45
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=42
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=41
开始写入文件: 朝鲜语
开始写入文件: 英语
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=40
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=39
完成获取网页内容: http://zsb.hitwh.edu.cn/home/major/details?id=45
开始写入文件: 国际经济与贸易
开始写入文件: 信息管理与信息系统
开始写入文件: 船舶与海洋工程(中外合作)
完成写入文件: 经济管理学院/国际经济与贸易.txt
完成存储任务: 经济管理学院 - 国际经济与贸易
完成写入文件: 语言文学学院/朝鲜语.txt
完成存储任务: 语言文学学院 - 朝鲜语
完成写入文件: 海洋工程学院/船舶与海洋工程(中外合作).txt
完成存储任务: 海洋工程学院 - 船舶与海洋工程(中外合作)
完成写入文件: 语言文学学院/英语.txt
完成存储任务: 语言文学学院 - 英语
完成写入文件: 经济管理学院/信息管理与信息系统.txt
完成存储任务: 经济管理学院 - 信息管理与信息系统

其他
-
关于爬虫刷到一篇很不错的blog,现在对爬虫很多概念还是不清晰,之后仔细看看
-
对了前面代码的效果贴个图