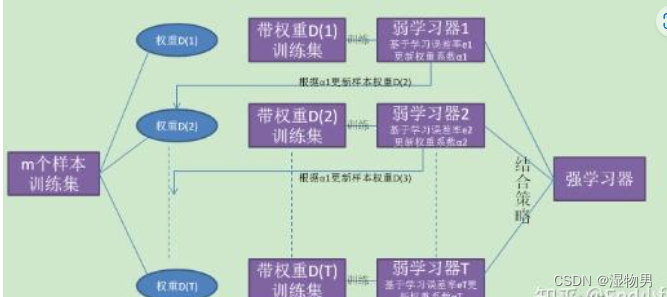
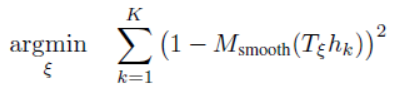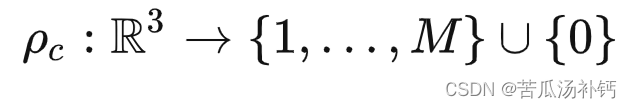文章目录

根据ANSI标准,各国对于各国的文字有自己的编写方法,中国发展的就是gbk编码,国际上有个unicode码,适用于所有语言,依据这个标准出来utf-8标准。像ascii,我们见到的就是8个bit位,总共存放128个,而ANSI标准则是32比特位,4个字节,也就是常见的32个1组成的那种。
对一个字符串,可以用encode函数来转换,参数是"gbk","utf-8"这样的,参数是什么,就用什么标准来表示调用者,decode则是解码函数,也是参数是什么就按照什么解码。
结束。
根据ANSI标准,各国对于各国的文字有自己的编写方法,中国发展的就是gbk编码,国际上有个unicode码,适用于所有语言,依据这个标准出来utf-8标准。像ascii,我们见到的就是8个bit位,总共存放128个,而ANSI标准则是32比特位,4个字节,也就是常见的32个1组成的那种。
对一个字符串,可以用encode函数来转换,参数是"gbk","utf-8"这样的,参数是什么,就用什么标准来表示调用者,decode则是解码函数,也是参数是什么就按照什么解码。
结束。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1093048.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!