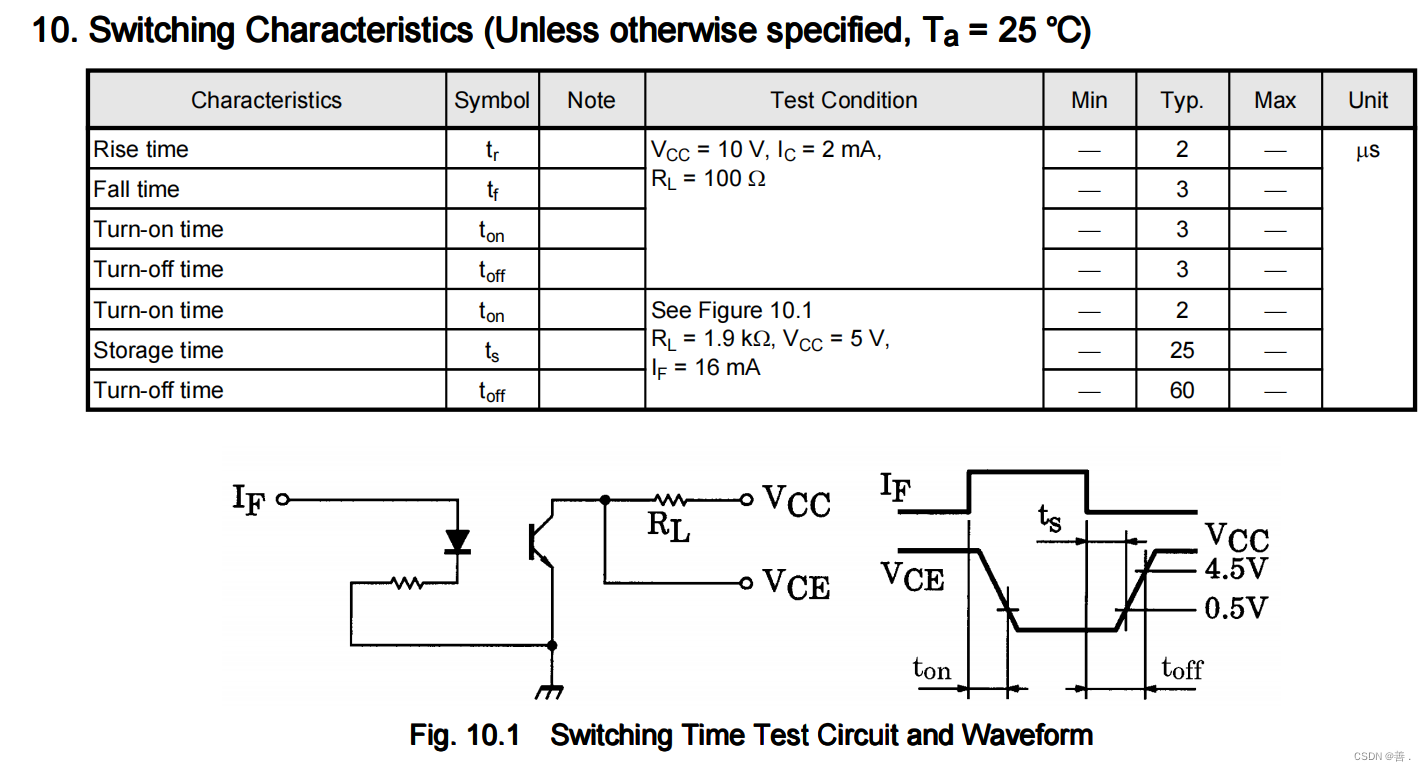
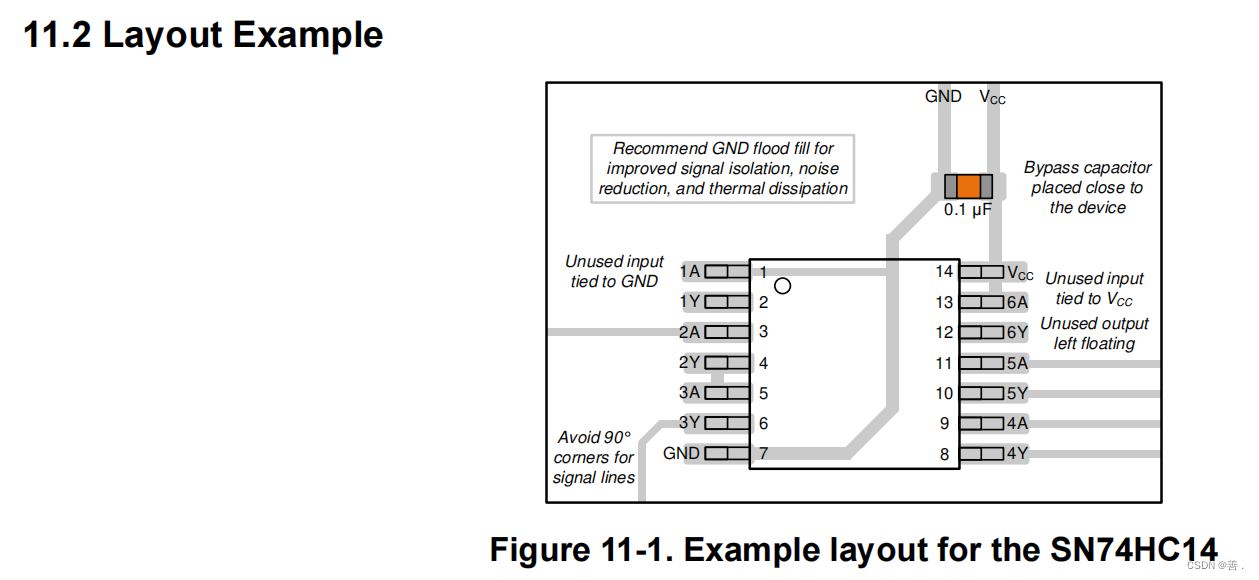
1. PyTorch 神经网络基础
1.1 模型构造
1. 块和层
首先,回顾一下多层感知机
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20) # 生成随机输入(批量大小=2, 输入维度=20)
net(X) # 输出(批量大小=2, 输出维度=10)

2. 自定义块
自定义MLP实现上一节的功能
class MLP(nn.Module): # 定义nn.Mudule的子类
def __init__(self):
super().__init__() # 调用父类
self.hidden = nn.Linear(20, 256) # 定义隐藏层
self.out = nn.Linear(256, 10) # 定义输出层
def forward(self, X): # 定义前向函数
return self.out(F.relu(self.hidden(X))) # X-> hidden-> relu-> out
实例化MLP的层,然后再每次调用正向传播函数时调用这些层
net = MLP()
net(X)

3. 实现Sequential类
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for block in args:
self._modules[block] = block
def forward(self, X):
for block in self._modules.values():
X = block(X)
return X
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
net(X)

4. 在正向传播中执行代码
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
self.rand_weight = torch.rand((20, 20), requires_grad=False) # 加入随机权重
self.linear = nn.Linear(20, 20)
def forward(self, X):
X = self.linear(X)
X = F.relu(torch.mm(X, self.rand_weight) + 1) # 输入和随机权重做矩阵乘法 + 1(偏移)-》激活函数
X = self.linear(X)
while X.abs().sum() > 1: # 控制X小于1
X /= 2
return X.sum() # 返回一个标量
net = FixedHiddenMLP()
net(X)
5. 混合搭配各种组合块的方法
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(20, 64), nn