文章来源于极客时间前google工程师−王争专栏。
有序数据集合的查找算法:二分查找(Binary Search)算法,也叫折半查找算法。二分查找的思想非常简单,但是难掌握好,灵活运用更加困难。
问题:假设有1000万个整数数据,每个数据占8个字节,如何设计数据结构和算法,快速判断某个整数是否出现在这1000万数据中?这个功能不能占用太多的内存空间,最多不超过100MB,如何解决?
无处不在的二分思想
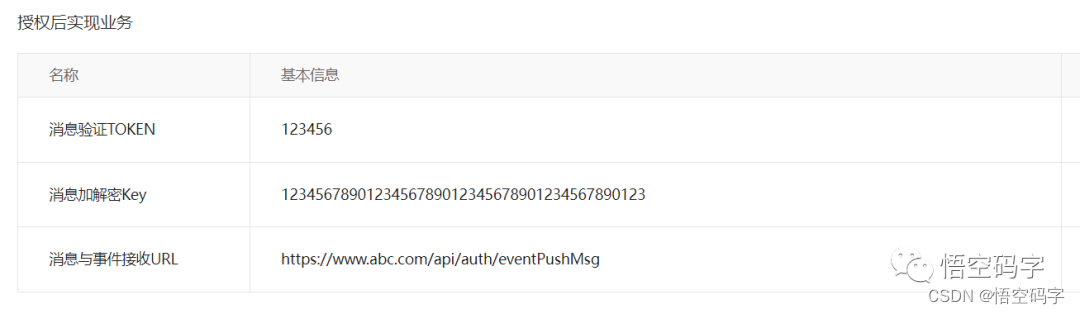
随机写一个0~99之间的数字,猜数字。(如果猜测范围的数字有偶数个,中间数有两个,就选择较小的那个)
0~999的数字,最多也只要10次就能猜中。
开发场景:假设有1000条订单数据,已经按照订单金额从小到大排序,每个订单金额都不同,并且最小单位是元。我们现在想知道是否存在金额等于19元的订单。如果存在,则返回订单数据,如果不存在则返回null。
最简单的办法是从第一个开始,一个一个遍历。最坏情况下需要1000次。用二分查找能不能更快速地解决呢?
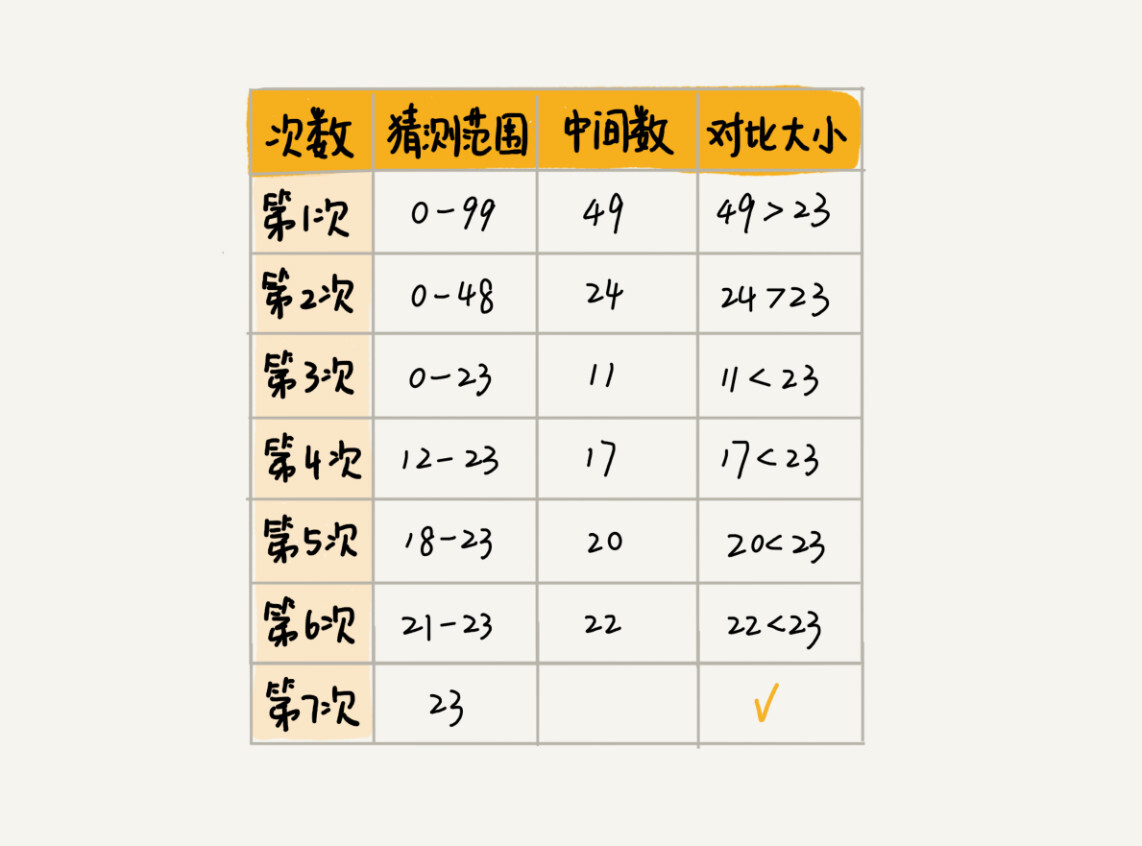
假设只有10个订单,订单金额分别是:8,11,19,23,27,33,45,55,67,98。
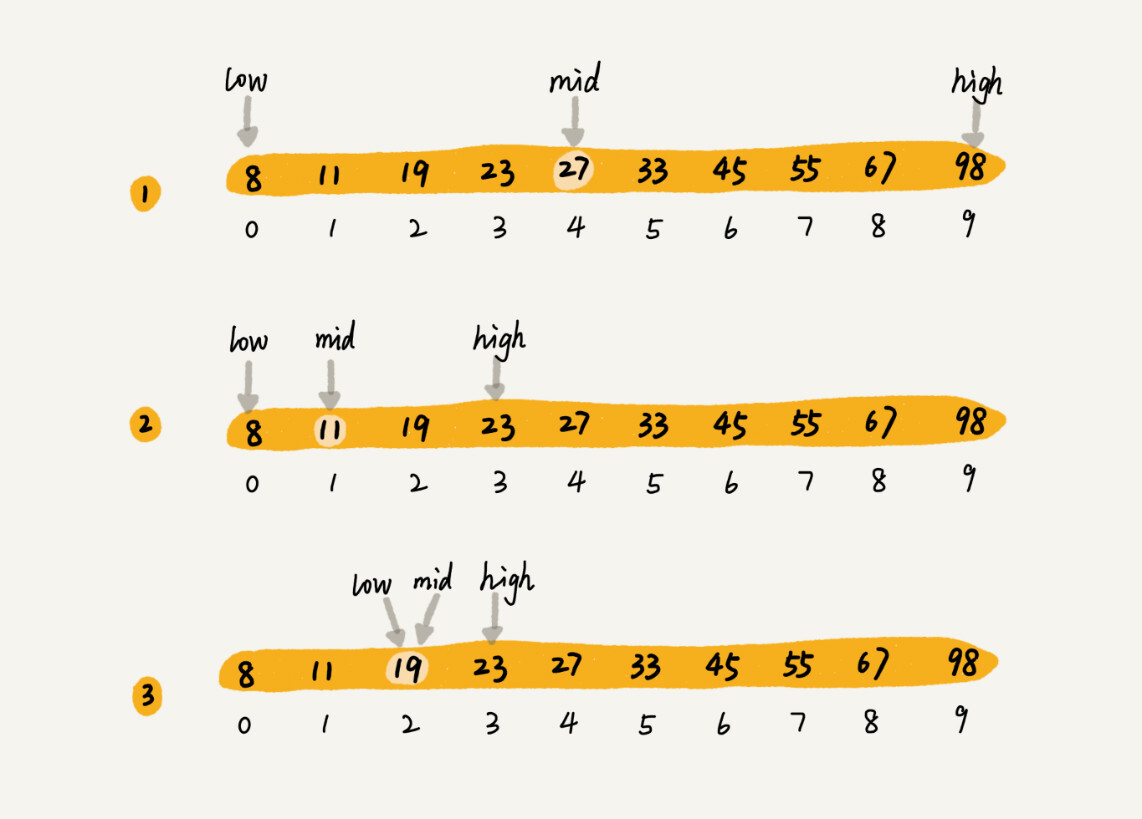
二分查找针对的是一个有序的数据集合,查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,知道找到要查找的元素,或者区间被缩小为0。
O(logn)惊人的查找速度
二分查找是一种非常高效的查找算法,我们来分析一下它的时间复杂度。
假设数据大小为n,每次查找数据都会缩小为原来的一半,也就是会除以2。最坏情况下,直到查找区间被缩小为空,才停止。

可以看出来,这是一个等比数列。其中n/2k=1时,k的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了 k 次区间缩小操作,时间复杂度就是O(k)。通过n/2k=1,我们可以求得 k=log2n,所以时间复杂度就是 O(logn)。
二分查找是目前为止遇到的第一个时间复杂度为O(logn)的算法。后面的堆、二叉树等操作,它们的时间复杂度也是O(logn)。O(logn)这种对数时间复杂度,是一种及其高效的时间复杂度,有的时候甚至比时间复杂度是常量级O(1)的算法还要高效。
logn是一个非常“恐怖”的数量级,即便n非常非常大,对应的logn也很小。比如n等于2的32次方,这个数很大,大约是42亿。也就是说,如果在42亿个数据中用二分查找一个数据,最多需要比较32次。
O(1)有可能表示的是一个非常大的常量值,比如O(1000),O(10000)。所以,常量级时间复杂度的算法有时候可能还没有O(logn)的算法执行效率高。
对数对应的就是指数。“阿基米德与国王下棋的故事”
二分查找的递归与非递归实现
简单的二分查找不难写,二分查找的变体问题,才是真正烧脑的。
最简单的情况就是有序数组中不存在重复元素,代码实现如下:
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = (low + high) / 2;
if (a[mid] == value) {
return mid;
} else if (a[mid] < value) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return -1;
}
容易出错的3个地方:
1.循环退出条件
是low<=high,而不是low<high
2.mid的取值
mid=(low+high)/2这种写法是有问题的。如果low和high比较大,两者之和就有可能溢出。
改进的方法是mid=low+(high-low)/2
如果性能做到极致的话,更进一步可以将除以2转化为位运算mid=((high-low)>>1)。因为相比除法运算来说,计算机处理位运算要快得多。
3.low和high的更新
low=mid+1,high=mid-1。如果写成low=mid或者high=mid就可能发生死循环。
比如high=3,low=3时,如果a[3]不等于value,就会导致一直循环不退出。
实际上,二分查找除了用循环来实现,还可以用递归来实现。
// 二分查找的递归实现
public int bsearch(int[] a, int n, int val) {
return bsearchInternally(a, 0, n - 1, val);
}
private int bsearchInternally(int[] a, int low, int high, int value) {
if (low > high) return -1;
int mid = low + ((high - low) >> 1);
if (a[mid] == value) {
return mid;
} else if (a[mid] < value) {
return bsearchInternally(a, mid+1, high, value);
} else {
return bsearchInternally(a, low, mid-1, value);
}
}
二分查找应用场景的局限性
1.二分查找依赖的是顺序表结构,简单点说就是数组
二分查找不能依赖链表这个数据结构。
主要原因是二分查找需要按照下标随机访问元素。链表的随机访问时间复杂度为O(n)。所以如果使用链表存储,二分查找的时间复杂度就会很高。
二分查找只能用在数据是通过顺序表来存储的数据结构上。
2.二分查找针对的是有序数据
要求数据必须有序,如果无序,则需要先排序。排序时间复杂度最低是O(nlogn)。针对一组静态数据,没有频繁插入,删除,可以一次排序,多次二分查找。这样排序的成本可被均摊。
针对动态数据集合,无论哪种方法,维护有序的成本都是很高的。那么针对动态数据集合,如何快速查找某个数据呢?
3.数据量太小不适合二分查找
只有数据量比较大的时候,二分查找的优势才比较明显。
不过有例外:如果数据之间的比较操作非常耗时,不管数据量大小,都推荐使用二分查找。
例如:数组中存储的都是长度超过300的字符串,如此长的两个字符串之间比对大小,会非常耗时。我们要尽量减少比较次数,这个时候二分查找比顺序遍历更有优势。
4.数据量太大也不适合二分查找
二分查找的底层依赖数组这种数据结构,而数组为了支持随机访问的特性,要求内存空间连续,对内存的要求比较苛刻。所以太大的数据用数组存储就比较吃力了,也不能用二分查找。
解答开篇
问题:如何在1000万个整数中快速查找某个整数?
内存限制是100MB,每个数据大小是8字节,最简单的办法就是将数据存储在数组中,内存占用差不多80MB,符合内存限制。
这个问题暗藏了“玄机”,如果用散列表和二叉树实际上是不行的。虽然大部分情况下,用二分查找可以解决的问题,用散列表、二叉树都可以解决,但是它们需要额外的内存空间,100MB的内存肯定存不下。所以最省内存的存储方式,是数组。
思考
1.如何变成实现“求一个数的平方根”,要求精确到小数点后6位。(二分查找)
2.如果使用链表存储,二分查找的时间复杂度是多少?
假设链表长度为n,二分查找每次都要找到中间点(计算中忽略奇偶数差异):
第一次查找中间点,需要移动指针n/2次;
第二次,需要移动指针n/4次;
第三次需要移动指针n/8次;
…
以此类推,一直到1次为值
总共指针移动次数(查找次数) = n/2 + n/4 + n/8 + …+ 1,这显然是个等比数列,根据等比数列求和公式:Sum = n - 1.
最后算法时间复杂度是:O(n-1),忽略常数,记为O(n),时间复杂度和顺序查找时间复杂度相同
但是稍微思考下,在二分查找的时候,由于要进行多余的运算,严格来说,会比顺序查找时间慢