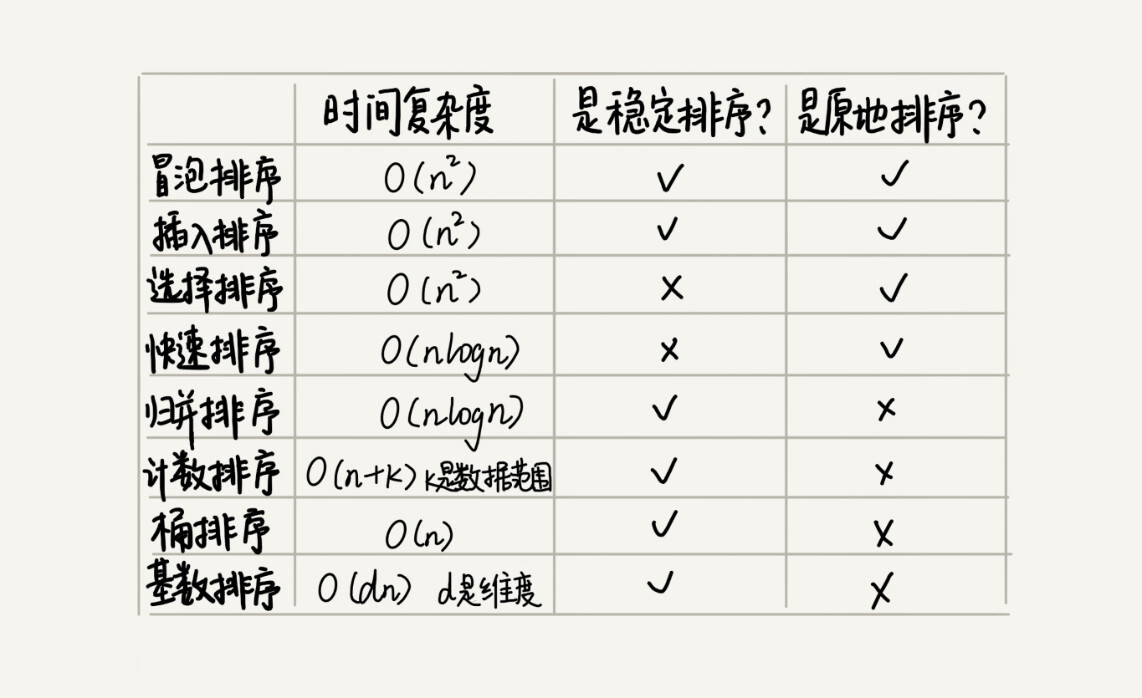
给定训练集,将每个样本
输入给前馈神经网络,得到网络输出为
,其在数据集
上的结构化风险为
首先简单解释一下这堆话,结构化风险=经验风险+正则化项,经验风险为,对于
函数我们大多数采取的为交叉熵函数,
,正则化项为
,首先神经网络的学习目的是减小损失函数的值,并且防止训练集的过拟合,这时,例如为损失函数加上
范数,也就是我们所说的正则化项。这样一来,就可以抑制权重变大。 用符号表示的话,如果将权重记为
,
范数的权值衰减就是
,然 后将这个
加到损失函数上。这里,
是控制正则化强度的超参数。
设置得越大,对大的权重施加的惩罚就越重。此外,
开头的
是用于将
的求导结果变成
的调整用常量。
对于所有权重,权值衰减方法都会为损失函数加上。因此,在求权重梯度的计算中,要为之前的误差反向传播法的结果加上正则化项的导数
,这样就可以用来防止过拟合.