文章目录
- 📚http协议
- 📚requests模块
- 📚re模块
- 🐇 re.I 或 re.IGNORECASE
- 🐇re.M或 re.MULTILINE
- 🐇re.S 或 re.DOTALL
- 🐇 re.A 或 re.ASCII
- 🐇 re.X 或 re.VERBOSE
- 🐇特殊字符类
- 📚xpath模块
- 🐇节点的排序
- 🐇函数用法
- 🐇节点关系
- 🐇补充语法
📚http协议
- 计算机网络|第二章:应用层
- Python爬虫教程(一):基础知识

- 请求行:请求方式(get/post)请求地址
- User-Agent:请求载体的身份标识(不同浏览器不同)
- cookie:本地字符串数据信息(用户登录信息)
- 请求体:放一些请求参数
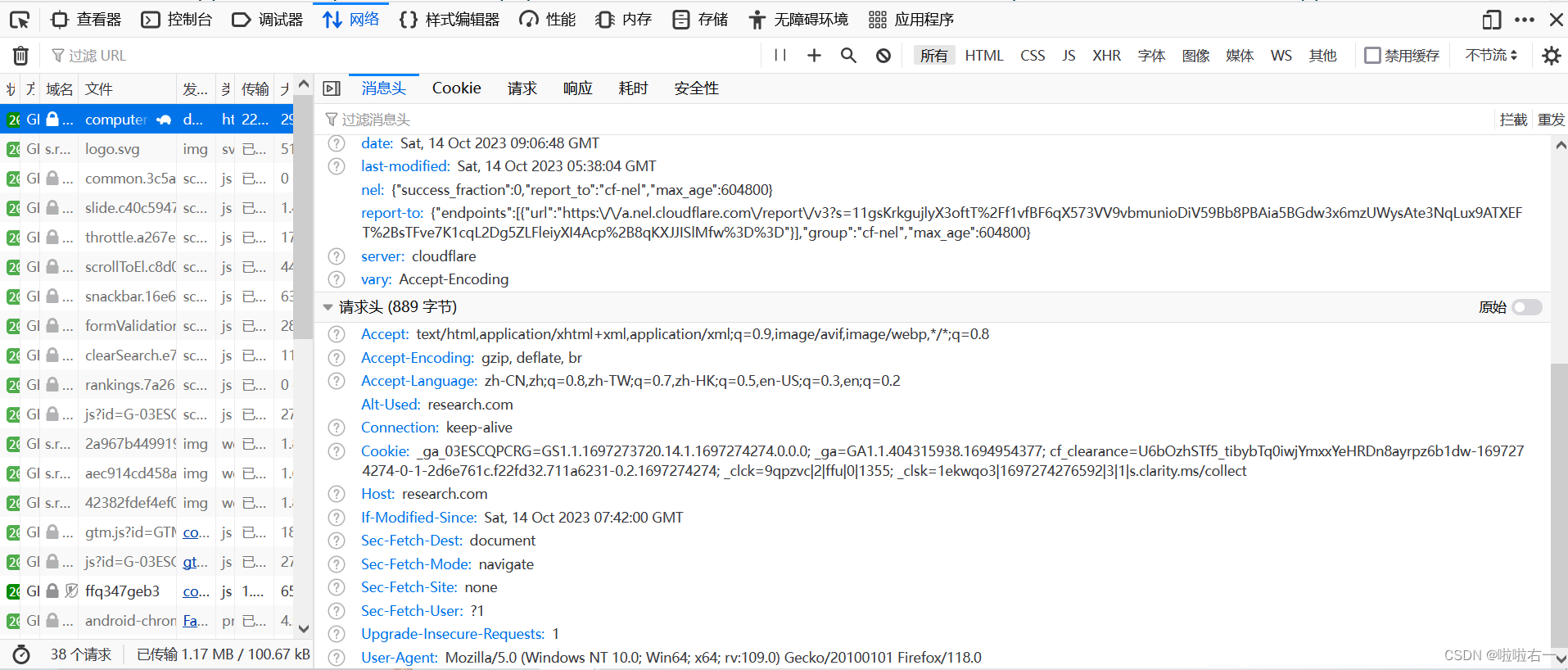
📚requests模块
- 发送HTTP请求:通过调用requests库中的
get()、post()、put()、delete()等函数,可以发送不同类型的HTTP请求。 - 添加请求参数:可以通过传递参数给
get()或post()函数,向请求中添加查询字符串参数、请求头等信息。 - 处理响应:收到服务器的响应后,可以访问返回的响应状态码、头部信息和内容等,并根据需要进行处理。
- 管理会话:使用Session对象可以创建和管理会话,以便在多个请求之间保持一致的会话状态,如使用cookies和身份验证等。
- 处理异常:requests模块具有内置的异常处理机制,可以捕获和处理请求过程中可能出现的异常情况。
import requests
# 发送HTTP GET请求,获取网页内容
url = "https://example.com"
response = requests.get(url)
# 判断请求是否成功
if response.status_code == 200:
# 输出网页内容
print(response.text)
else:
print("请求失败")
- 用requests库发送了一个HTTP GET请求,并指定了要请求的网址。然后,通过访问 response.status_code属性,判断请求是否成功(状态码为200表示成功)。如果请求成功,通过 response.text属性获取到网页内容,并将其打印出来。
import requests
# 创建Session对象
session = requests.Session()
# 发送登录请求,获取cookies
login_url = "https://example.com/login"
payload = {"username": "your_username", "password": "your_password"}
response = session.post(login_url, data=payload)
# 判断登录是否成功
if response.status_code == 200:
# 发送带有cookies的请求,获取其他页面内容
profile_url = "https://example.com/profile"
response = session.get(profile_url)
# 判断请求是否成功
if response.status_code == 200:
# 输出页面内容
print(response.text)
else:
print("登录失败")
- 创建了一个Session对象。Session对象可以保持会话状态,并自动管理cookies。
- 发送一个登录请求(POST请求),传递用户名和密码等表单数据。登录成功后,会话中会自动保存返回的cookies信息。
- 通过使用相同的Session对象发送另一个请求(GET请求),这次访问一个需要登录后才能查看的页面。由于我们使用的是之前的会话,会携带之前登录成功后返回的cookies信息。
- 判断请求是否成功,并输出页面内容。
📚re模块
- 正则表达式匹配:使用re模块的
match()(从字符串的开头开始匹配)、search()(搜索第一个匹配)和findall()(返回所有匹配的结果)等函数,可以根据指定的正则表达式,在字符串中查找匹配的内容。 - 替换字符串:通过使用re模块的
sub()和subn()函数,可以将匹配到的内容替换为指定的字符串。sub()函数会替换所有匹配项,而subn()函数还会返回替换的次数。 - 分割字符串:re模块的
split()函数可以根据指定的正则表达式,将字符串分割为子字符串列表。 - 匹配对象的操作:re模块中的Match对象表示一个匹配项,可以从中获取匹配的内容、位置以及其他相关信息。
- 正则表达式修饰符:re模块提供了一些修饰符,用于控制正则表达式的匹配行为,如忽略大小写、多行匹配、全局匹配等。
🐇 re.I 或 re.IGNORECASE
- 忽略大小写匹配,不论目标字符串的字母是大写还是小写,都可以与正则表达式模式相匹配。
import re pattern = r"hello" text = "Hello, World!" result = re.search(pattern, text, re.I) print(result.group()) # 输出:Hello
🐇re.M或 re.MULTILINE
-
re.M或re.MULTILINE用于指定多行模式匹配。 -
正则表达式通常按照默认的单行模式进行匹配,也就是只将目标文本视为单个行。在这种模式下,
^表示字符串的开头,$表示字符串的结尾。 -
而使用
re.M标志可以将正则表达式切换到多行模式,即将目标文本视为多个行。在多行模式下,^和$分别表示行的开头和行的结尾,而不再仅限于字符串的开头和结尾。import re text = "Hello\nWorld\nHow are you?" pattern = re.compile("^H", re.M) matches = pattern.findall(text) print(matches) -
由于使用了多行模式,模式中的
^表示行的开头,因此只有以字母H开始的行会与模式进行匹配。所以最终的输出结果是['H', 'How'],分别对应于第一行和第三行匹配成功的结果。
🐇re.S 或 re.DOTALL
re.S或re.DOTALL单行匹配,用于指定点字符(.)匹配任意字符,包括换行符。- 在正则表达式中,
.通常表示匹配除了换行符之外的任意字符。默认情况下,它不匹配换行符,但是使用re.S标志可以使其匹配包括换行符在内的任意字符。import re pattern = r"hello.*world" text = "hello\nworld" # 匹配以 "hello" 开始,并以 "world" 结尾,中间可以有任意数量的任意字符。 result = re.search(pattern, text, re.S) print(result.group()) # 输出:hello\nworld
🐇 re.A 或 re.ASCII
- 限制模式中的字符匹配为ASCII字符集。
import re pattern = r"\w+" text = "你好, World!" result = re.findall(pattern, text, re.A) print(result) # 输出:['World']
🐇 re.X 或 re.VERBOSE
- 冗长模式,忽略正则表达式中的空白和注释。
import re pattern = r""" hello # 匹配 hello \s+ # 匹配一个或多个空格字符 world # 匹配 world """ text = "hello world" result = re.search(pattern, text, re.X) print(result.group()) # 输出:hello world
🐇特殊字符类
\d:匹配任意数字。相当于[0-9]。\D:匹配任意非数字字符。相当于[^0-9]。\s:匹配任意空白字符,包括空格、制表符、换行符等。\S:匹配任意非空白字符。\w:匹配任意字母、数字和下划线字符。相当于[a-zA-Z0-9_]。\W:匹配任意非字母、数字和下划线字符。
-
这些特殊字符类可以在正则表达式中使用,以便更精确地匹配特定类型的字符。需要注意的是,大写形式的特殊字符类(例如
\D、\S、\W)表示相反的意义,即匹配对应类别之外的字符。 -
例如,使用
\d+可以匹配一个或多个连续的数字,而\D+则匹配一个或多个连续的非数字字符。
📚xpath模块
- XPath(XML Path Language)是一种用于在 XML 文档中定位和选择元素的语言。使用 XPath 模块,可以根据指定的 XPath 表达式从 XML 文档中定位和选择节点,提取所需的数据。
- XPath 模块提供了以下主要功能:
- 解析 XML 文档:使用
xml.etree.ElementTree.parse()函数加载 XML 文件,并返回一个表示整个 XML 文档的树结构 - 定位节点:使用 XPath 表达式
tree.xpath(xpath_expr)在 XML 树结构中定位满足条件的节点。XPath 表达式描述了节点的路径或属性等选择条件。 - 选择节点:使用
Element.xpath(xpath_expr)方法在当前节点下选择满足条件的子节点。 - 提取数据:使用
element.text获取节点的文本内容,使用element.attrib获取节点的属性信息。
from lxml import etree # 解析 XML 文档 tree = etree.parse("data.xml") # 使用 XPath 表达式定位和选择节点 # 从 XML 或 HTML 文档的根节点 catalog 中选取所有 book 元素下的 title 子元素,并提取它们的文本内容 title = tree.xpath("/catalog/book/title/text()") author = tree.xpath("/catalog/book/author/text()") # 获取节点的文本内容 title_text = title[0] author_text = author[0] # 打印结果 print("Title:", title_text) print("Author:", author_text)-
title = tree.xpath("/catalog/book/title/text()"):选择XML文档中所有 节点的文本内容。 .text()表示获取节点的文本内容,而不是节点本身。
- 解析 XML 文档:使用
🐇节点的排序
# 使用 [下标]来选择指定位置的节点,注意 XPath 下标从 1 开始计数
tree.xpath('//div[@class="root"]/div/p[2]/text()')
# 获取当前层同级节点中的最后一个位置的节点
tree.xpath('//div[@class="root"]/div/p[last()]/text()')
# 获取倒数第二个位置的节点
tree.xpath('//div[@class="root"]/div/p[last()-1]/text()')
# 获取位置小于等于2的节点
tree.xpath('//div[@class="root"]/div/p[position() <= 2]/text()')
🐇函数用法
# 用于筛选嵌套文本长度大于5的嵌套文本
tree.xpath("//ul/li[string-length(text()) > 5]/text()")
# 判断属性是否包含指定的子字符串
tree.xpath("//ul/li[contains(@class, 'price')]/text()")
# 匹配以指定字符开头的节点
tree.xpath("//ul/li[starts-with(text(), '啦啦')]/text()")
# 计算节点数量
tree.xpath("count(//ul/li)")
🐇节点关系
# self::代表当前节点自身
tree.xpath('//div/p/self::p/text()')
# * 代替标签名称,匹配任何标签
tree.xpath('//div/p/self::*/text()')
# following-sibling::选取当前节点之后的同级节点
tree.xpath("//div/p[text()='第三段']/following-sibling::*/text()")
# preceding-sibling::选取当前节点之前的同级节点:
tree.xpath("//div/p[text()='第三段']/preceding-sibling::*/text()")
# 父辈节点:parent::
tree.xpath('//div[@class="self"]/parent::*/@class')
# 先辈节点:`ancestor::` 和 `ancestor-or-self::`
tree.xpath('//div[@class="self"]/ancestor::*/@class')
tree.xpath('//div[@class="self"]/ancestor-or-self::*/@class')
# 后代关系:子节点 `child::`、所有后代节点 `descendant::` 和所有后代节点及自身 `descendant-or-self::`
tree.xpath("//div[@class='uncle']/child::*/@class")
tree.xpath("//div[@class='grandpa']/descendant::*/@class")
tree.xpath("//div[@class='grandpa']/descendant-or-self::*/@class")
🐇补充语法
- 使用
*通配符匹配任何满足条件的节点,不需要考虑父节点tree.xpath("//*[@class='price' or @class='price-item']/text()")
- 使用正则表达式模式匹配节点
tree.xpath("//ul/li[ns:match(text(), '哈哈$')]/text()", namespaces={"ns": "http://exslt.org/regular-expressions"})- 匹配带有以字母 “哈哈” 结尾的文本内容的 li 元素,并返回这些 li 元素的文本内容。同时使用 namespaces 参数来定义命名空间的映射。
参考博客:
- Python爬虫教程(一):基础知识





![[Linux打怪升级之路]-管道](https://img-blog.csdnimg.cn/b8ff56527d19416da31bda4e3b50dbe7.png)