闲鱼商品结构化和淘宝/天猫最大的区别在于闲鱼卖家都是个人用户,无论是专业程度还是行动力远不及淘宝卖家。为了不阻碍商品发布,闲鱼一直倡导轻发布,理想状况用户拍完照片输入一段描述即可完成发布。但是这和商品结构化相悖:卖家输入信息越多,越有利于商品结构化,但是用户发布商品的意愿就会越低。 我们要做的就是在不阻碍用户发布商品的前提下提高商品结构化程度。
结构化历程
闲鱼商品结构化的探索一直没有停过。目前为止,可以划分出四个阶段

- 2016年及以前:利用文本挖掘算法,从用户输入的标题/描述中提取出结构化信息。
- 2017年:文本属性依赖用户输入。遗憾的是大部分闲鱼用户输入相当"简洁"。于是我们把目光转向图片:1)从商品图片中提取结构化信息。2)根据商品图片预测商品类目。
- 2018年:2018年以前闲鱼类目处于刀耕火种的原始状态,发布时需要选择商品应该在哪个类目之下。所以我们建立了闲鱼渠道类目,将类目映射到渠道类目。另一个尝试就是将闲鱼商品直接与天猫的SPU(Standar Product Unit,标准产品单元)映射。
- 2019年:启动了哥伦布项目,进一步挖掘图像潜力。通过图像相似度识别,直接将闲鱼商品和淘宝/天猫商品进行关联,通过对淘宝同款的结构化信息清洗得到闲鱼商品的结构化信息。
当前结构化策略
目前围绕着算法,我们在商品发布的各个环节都提供了同款关联的入口:从智能发布到发布完成之后的算法识别以及售卖体系。

现阶段闲鱼商品结构化围绕着算法,在商品发布的各个环节都提供了同款关联的入口:从智能发布到发布完成之后的算法识别以及售卖体系。
- 端侧智能发布。商品发布过程中,充分利用端侧计算能力,将商品结构化的产品问题,转变成同款商品匹配这样的技术问题。模糊检测,相似度检测,主体识别这些算法都是在端侧实现的。
- 算法图像识别。商品发布完成后,借助图像识别算法,对于精度较高的识别结果直接和商品建立映射关系。
- 售卖项目。当图像识别算法只能缩小范围而无法精确给出结果时,借助于售卖任务体系,可以让用户选择完成同款关联。
通过同款关联,闲鱼商品结构化往前走了一大步,使得闲鱼商品结构化的比例有将近47%的提升。尽管如此闲鱼商品结构化现状仍不容乐观,主要体现在
- 同款覆盖率。覆盖虽然提升比例较大,但离目标还有一定的距离。
- 同款精度。1)部分类目精度低,比如手机和手机壳在图像上相似,但实际是不同的商品。2)整体精度离目标仍有较大gap。
- 结构化信息应用。目前只应用在了搜索场景的商品扩招回,结构化信息的应用仍有待充分挖掘。
未来的打法
当前结构化策略面临着一个问题:当算法能力达到上限后,如何继续推进结构化覆盖&精度提升?目前为止起码有三种手段
- 算法多模态。集团有着众多在各自领域深耕的图像算法团队,比如在女装等垂直类目上沉淀深厚的专家系统。融合多算法团队能在一定程度上提升算法能力的天花板。
- 文本识别。在下面的case中,单纯凭借图片无法识别是否是同款,因为图像确实非常相似,这个时候就需要文本的辅助。

- 输入辅助。文本识别模型依赖用户的输入。输入辅助引导用户输入更多高质量文本的同时降低用户描述成本。另一方面输入辅助也可以承担部分属性补全的能力。
然而在现阶段以算法为中心的工程体系中,上面的策略应用上会面临很多痛点
- 如何定义结构化。本质上是结构化标准的问题,一方面相同的商品算法识别出来的结果千差万别,相同的商品不同算法识别出来的结果最终如何归一化成相同的同款。另一方面对于算法覆盖不到的领域如何通过其他手段来完成结构化。
- 算法多模态接入成本飙升。如何抹平多算法之间的差异,算法对大盘的贡献,各个算法之间的效果快速上线对比?
- 输入辅助。输入辅助需要解决2个问题:1)输入联想素材池来源。2)用户体验,输入辅助对实时响应有着非常高的要求。
这些问题大部分本质还是工程问题(结构化定义,多算法融合,输入辅助等)。所以转换一下结构化思路:以算法为中心转向以工程为中心,把算法当作能力补齐插件。结构化围绕着属性补齐做如下抽象

总体策略

总结起来做这几件事
- 闲鱼vid体系重新定义结构化标准。
- 算法多模态接入,提升覆盖&精度。
- 引入规则引擎,服务于输入辅助等场景。
- 结构化数据持久化&特征计算,提升搜索推荐等导购场景的匹配效率。
重新定义结构化
定义结构化的标准,一方面可以抹平多算法接入带来的差异,另一方面对于拓展算法边界也有重要意义。所以重新给商品结构化下一个定义:如果一个商品的关键属性都有,那我们认为这个商品就是结构化的。

这套标准称为闲鱼vid(想好名字前暂且叫vid)体系,基于闲鱼渠道类目+属性组成。这套标准有两种方式生成
- 天猫spu体系。天猫的spu运营到现在,数据体系已经较为完善,标准品类和闲鱼有很大重叠部分,这部分可以直接实现spu互通。
- 对于非标品,从需求侧分析而来。通过搜索推荐等导购场景反向分析可以拿到当前买家关心的品类+属性。这部分可以补齐SPU缺失的数据。
基于这套标准体系,可以很好的解决多算法接入问题:直接以vid体系对应的种子商品集为候选池,实现同款挂靠。除此之外,算法没法覆盖的商品(图文质量较差)如果能确定类目和属性,也能实现vid挂靠。
算法多模态
工程上主要解决算法接入效率问题。当从商品发布到最后的导购主链路搭建完成,算法以插件化的方式运行在主链路之上。

这里多模态主要包括两方面:1)识别能力从图像扩展到文本,图文结合。2)算法模型从单团队拓展到多团队,能力互补。 解决的问题主要包括
- 屏蔽数据差异。不同算法数据产生方式的差异,实时/准实时/离线。
- 数据融合。算法快速上线/数据效果对比/结构化信息入引擎。
- 算法结果对齐。根据定义的结构化标准,抹平算法结果差异。如果识别出的同款商品本质上是同一个商品,那多算法的识别结果最终应当能归一化。
输入辅助
输入辅助需要解决两个问题:
- 联想素材池来源:用户输入具有持续时间很短的特征,所以在较短时间内辅助用户进行有价值的输入很关键。
- 用户体验:严苛的实时性要求。用户输入是一个连续且对时效要求极高的过程,所有数据的交互需在极短时间内完成。
第一个问题很好解决,素材池提炼可以包括:
- 搜索逆向分析产出。根据用户query统计分析,可以得到买家关心的属性。
- 算法产出:算法对动销高的商品进行特征提取得到,并归到对应的渠道类目上。
- 运营行业经验产出。
第二个问题最好的解法肯定是把所有的逻辑全部下放到端上本地执行避免响应问题。然而不可能把所有的逻辑放到端上,比如需要算法介入时,我们不可能把复杂的算法模型运行在端上。所以把素材池分成两部分:
- 需要算法介入的逻辑放在服务端来完成。
- 其余逻辑选择适当时机下发给端上执行,这部分需要保证良好的扩展能力。
通过对输入辅助的执行逻辑进行抽象发现其存在形式类似于规则引擎中的规则。在规则引擎中规则一般包含三要素:事实,规则,模式。

这里的事实对应着用户的输入,module对应着单个判定条件,rule则对应着条件判定以及对应的action。以运营的行业经验产出为例,手机类目下有两个很重要的属性:1)是否维修过。 2)是否过保。那这条经验可以翻译成两条规则:1)IF 类目=手机 AND 属性不包含 是否维修过 THEN 引导用户选择。2)IF 类目=手机 AND 属性不包含 是否过保 THEN 引导用户选择。 当执行逻辑被抽象成若干条规则时,就可以在适当的时机下发到客户端侧本地执行。整个流程抽象如下
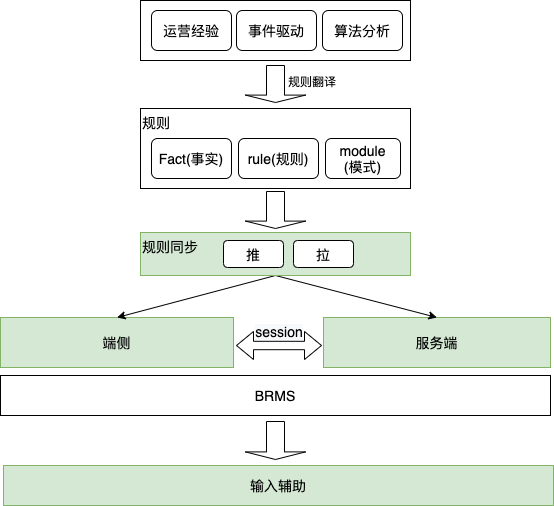
当新的运营经验或者分析数据产生时,通过翻译成规则可以很好的实现辅助输入的扩展性。通过规则的共享,客户端的逻辑可以无感知的在服务端执行。
上线效果
商品结构化的目标围绕着结构化信息的覆盖&精度进行,目前已经上线了部分功能(文本同款以及算法多模态),从数据上看取得了不错的效果:1)算法多模态接入能对结构化覆盖占比8%绝对提升。2)文本同款正在分桶测试中,从分桶数据来看覆盖上涨13%绝对值提升。
展望
结构化的愿景是在不影响发布体验的前提下完成商品结构化工作。理想情况下只需要一张照片,一段描述就能完成商品发布,其余工作统统移交给算法以及工程同学。当图像和文本内容能被充分挖掘理解,标签成色甚至类目这些都可以去掉,用户只需要点确认发布按钮即可。我们会不断朝着这个目标努力。



![[Linux打怪升级之路]-管道](https://img-blog.csdnimg.cn/b8ff56527d19416da31bda4e3b50dbe7.png)