本文分享单目3D目标检测,MonoCon模型的论文解读,了解它的设计思路,论文核心观点,模型结构,以及效果和性能。

目录
一、MonoCon简介
二、论文核心观点
三、模型框架
四、模型预测信息与3D框联系
五、损失函数
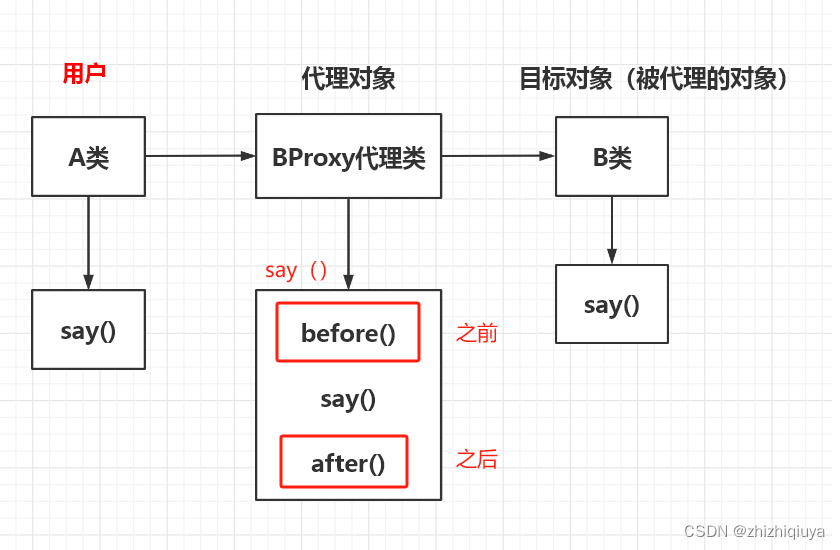
六、核心内容——辅助训练分支与3D检测分支
七、实验对比与模型效果
一、MonoCon简介
MonoCon是一个延续CenterNet框架的单目3d检测器,在不依赖dcn的情况下获得了较好的性能,并且融入了辅助学习,提升模型性能。
曾经在Kitti 单目3D目标检测上,霸榜了一段时间。
MonoCon和MonoDLE很像,在它基础上添加了一些辅助分支检测头,促进网络学习特征的能力。
- MonoCon = MonoDLE + 辅助学习
- 辅助学习:训练阶段增加一些网络分支,对其计算loss项,而在推理阶段完全忽略掉它们,以期得到更好的特征表示。
开源地址(官方):https://github.com/Xianpeng919/MonoCon
开源地址(pytorhc):https://github.com/2gunsu/monocon-pytorch
论文地址:Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection
二、论文核心观点
论文核心观点,主要包括为两点:
- 带注释的3D 边界框,可以产生大量可用的良好投影的 2D 监督信号。
- 使用辅助学习,促进网络学习特征的能力。
三、模型框架
MonoCon是基于CenterNet框架,实现单目3d检测的。模型结构如下:
Backbone:DLA34
Neck:DLAUp
常规3D框检测头:5个分支
- 分支一 通过输出heatmap,预测2D框中心点的粗略坐标,以及类别分数。
- 分支二 预测2D框中心点粗坐标与真实的3D投影坐标之间的偏移。
- 分支三 预测2D框中心点粗坐标的深度值,和其不确定性。
- 分支四 预测3D框的尺寸。
- 分支五 预测观测角。
辅助训练头:5个分支
- 分支一 8个投影角点和3D框的投影中心。
- 分支二 8个投影角点到2D框中心的offsets。
- 分支三 2D框的尺寸。
- 分支四 2D框中心量化误差建模。
- 分支五 8个投影角点量化误差建模。
模型结构如下图所示:
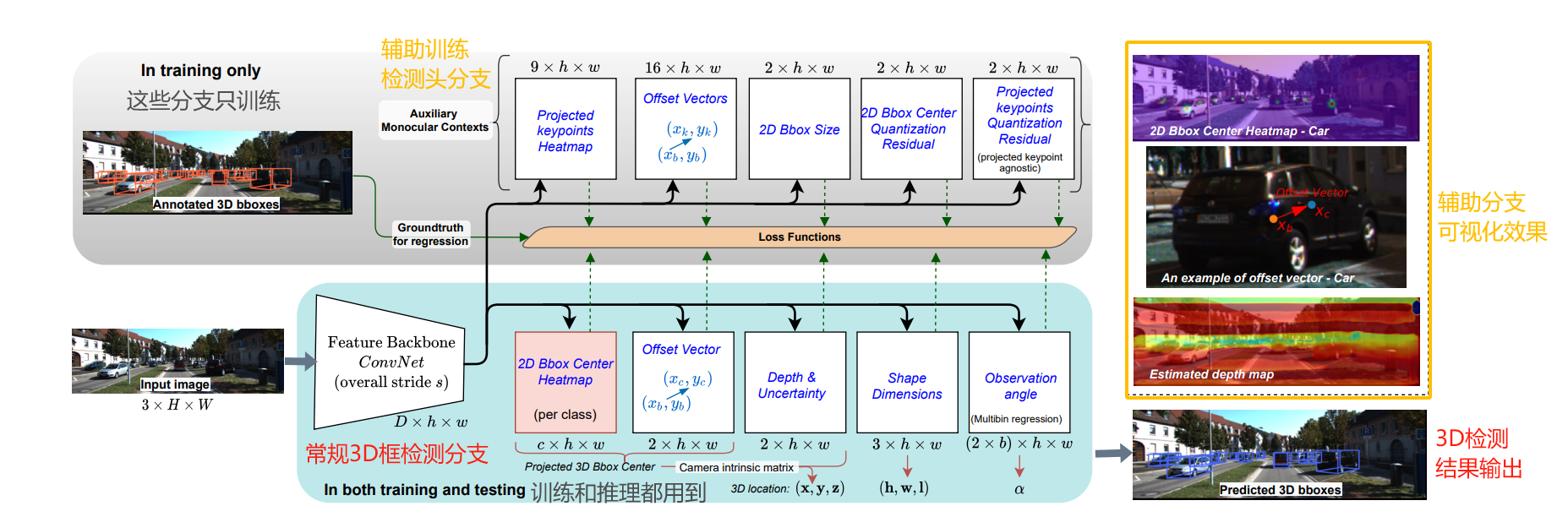
四、模型预测信息与3D框联系
3D框相关的信息
1、3D中心点坐标(cw, yw, zw):通过预测3D中心在像素坐标系下的坐标,结合相机内参可以获得中心点在图像物理坐标系下的坐标(x,y,z)。再结合预测深度zw,获得zw/z的比例系数,就能求出xw,yw。由此可见,深度估计对整体定位精度的影响还是很大的。
2、深度估计:基于端到端的思路实现;同时在输出上做了一个不确定性建模,在预测深度d的基础上同时预测标准差σ。对于σ的分布,文中做了拉普拉斯分布和高斯分布,起到一定优化作用。
3、尺寸估计:以往的尺寸估计,应用的损失函数都是通过计算和真值框之间的交并比来约束尺寸。这样带来的问题就是,由于中心点的预测误差导致的损失偏大,会给尺寸估计带来不必要的负担。所以作者提出了尺寸估计并专门设计了损失函数,只针对尺寸的预测误差对这个分支进行优化。并且根据长宽高对于IOU影响的比例不同,对参数优化的权重也按比例进行了设置。
4、航向角估计:用的是multi-bin loss。
模型预测信息,如下图所示:
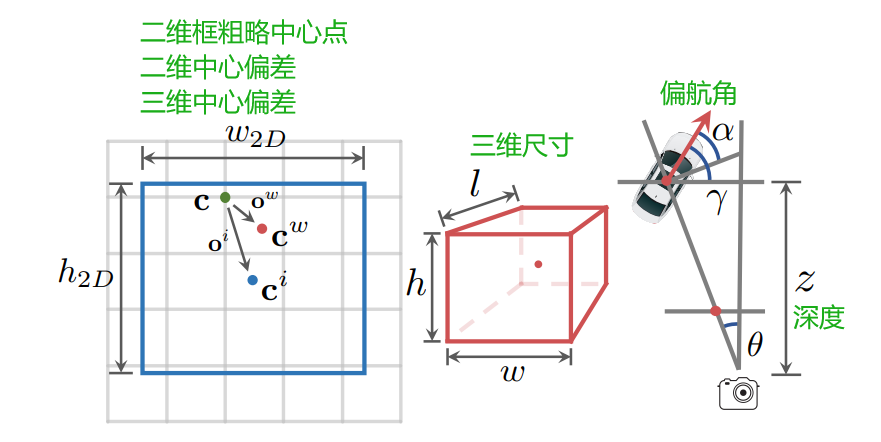
五、损失函数
MonoCon的损失由10部分组成,
常规3D框检测头:5个分支
- 分支一 heatmap 类别分数,使用FocalLoss。2D 中心点损失,使用L1 Loss。
- 分支二 2D框中心点粗坐标与真实的3D投影坐标之间的偏移,使用L1 Loss。
- 分支三 2D框中心点粗坐标的深度值,和其不确定性,使用Laplacian Aleatoric Uncertainty Loss。(MonoPair & MonoDLE & MonoFlex & GUPNet)
- 分支四 预测3D框的尺寸,使用Dimension-Aware L1 Loss(MonoDLE)。
- 分支五 预测观测角,multi-bin Loss,其中分类部分使用 CrossEntropyLoss,回归部分使用 L1 Loss。
辅助训练头:5个分支
- 分支一 8个投影角点和3D框的投影中心,使用FocalLoss。
- 分支二 8个投影角点到2D框中心的offsets,使用L1 Loss。
- 分支三 2D框的尺寸,使用L1 Loss。
- 分支四 2D框中心量化误差建模。
- 分支五 8个投影角点量化误差建模。
损失函数相关代码如下
loss_center_heatmap=dict(type='CenterNetGaussianFocalLoss', loss_weight=1.0),
loss_wh=dict(type='L1Loss', loss_weight=0.1),
loss_offset=dict(type='L1Loss', loss_weight=1.0),
loss_center2kpt_offset=dict(type='L1Loss', loss_weight=1.0),
loss_kpt_heatmap=dict(type='CenterNetGaussianFocalLoss', loss_weight=1.0),
loss_kpt_heatmap_offset=dict(type='L1Loss', loss_weight=1.0),
loss_dim=dict(type='DimAwareL1Loss', loss_weight=1.0),
loss_depth=dict(type='LaplacianAleatoricUncertaintyLoss', loss_weight=1.0),
loss_alpha_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0),
loss_alpha_reg=dict(type='L1Loss', loss_weight=1.0),
补充说明 深度值损失的公式定义如下:

六、核心内容——辅助训练分支与3D检测分支
3D框检测头:5个分支
分支一 通过输出heatmap,预测2D框中心点的粗略坐标,以及类别分数。借鉴自CenterNet,预测C类目标(KITTI中为3类:Car,Pedestrian,Cyclist)的中心点坐标(xb, yb) 。
分支二 预测2D框中心点粗坐标与真实的3D投影坐标之间的偏移。2D框中心坐标(xb, yb),到3D框中心坐标(xc, yc)之间的偏移。
分支三 预测2D框中心点粗坐标的深度值,和其不确定性;其中深度值采用逆Sigmoid进行处理。

g(F; θZ) 估计深度及其不确定性,应用逆 sigmoid 变换来处理 g(F; θZ)[0] 的无界输出。σZ 用于对深度估计中的异方差任意不确定性进行建模。
分支四 预测3D框的尺寸,即预测长、宽、高。
分支五 预测观测角,采用multi-bin策略,分成24个区间,前12个用于分类(粗略预测),后12个用于回归(精细预测)将直接回归问题转化为先分类,再回归的问题。
辅助训练头:5个分支
分支一 8个投影角点和3D框的投影中心。
分支二 8个投影角点到2D框中心的offsets。
分支三 2D框的尺寸。
分支四 2D框中心量化误差建模。
分支五 8个投影角点量化误差建模。
由于backbone降采样的存在,原始图像目标中心点的位置和backbone输出feature map中的位置之间,存在量化误差。MonoCon对2D中心和8个投影角点,分别进行量化误差建模。
在进行量化误差建模时,MonoCon采用了keypoint-agnostic方式,即关键点无关建模。
七、实验对比与模型效果
论文于KITTI 官方测试集中“汽车类别”的最先进方法进行比较,使用单个2080Ti GPU显卡测试的。
下表中由BEV和3D的测试结果,MonoCon运行时间和精度都是Top 级别的。
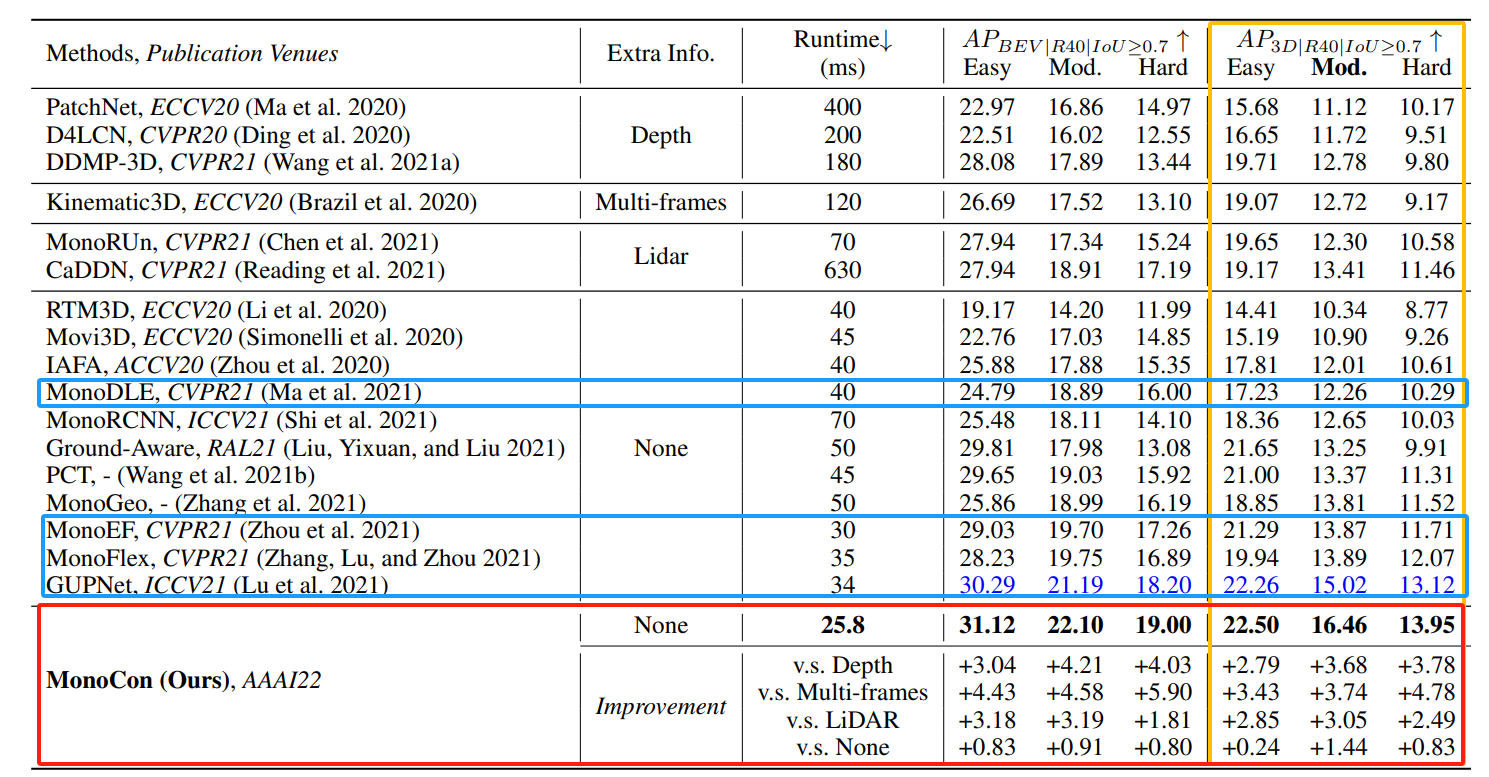
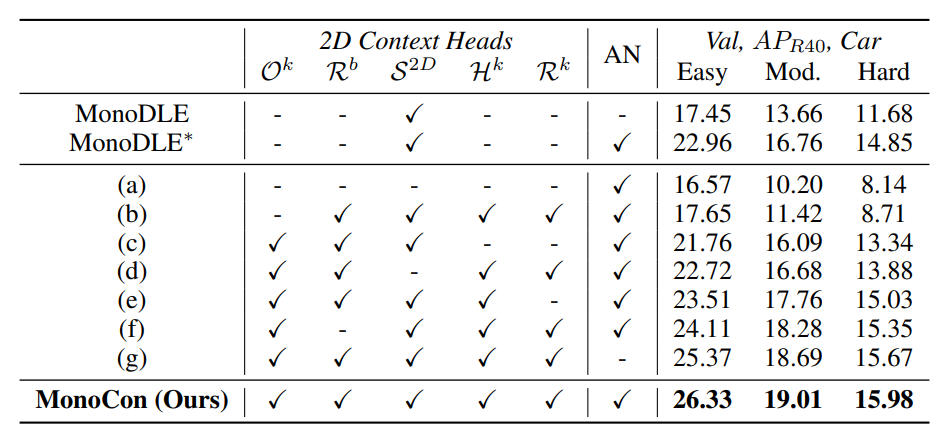
作者基于MonoDLE进行了对比实验,分析5个辅助训练分支,和把BN归一化换为AN归一化,对模型精度的影响。
模型预测效果:

下面是单目3D目标检测的效果,激光雷达点云数据仅用于可视化。

在前视图图像中,预测结果以蓝色显示,而地面实况以橙色显示。
在激光雷达视图图像中,预测结果显示为绿色。 地面实况 3D 框以蓝色显示。

分别显示2D框、3D框、BEV的检测效果:



分享完成~
【数据集】单目3D目标检测:
3D目标检测数据集 KITTI(标签格式解析、3D框可视化、点云转图像、BEV鸟瞰图)_kitti标签_一颗小树x的博客-CSDN博客
3D目标检测数据集 DAIR-V2X-V_一颗小树x的博客-CSDN博客
【论文解读】单目3D目标检测:
【论文解读】SMOKE 单目相机 3D目标检测(CVPR2020)_相机smoke-CSDN博客
【论文解读】单目3D目标检测 MonoDLE(CVPR2021)_一颗小树x的博客-CSDN博客
【实践应用】
单目3D目标检测——SMOKE 环境搭建|模型训练_一颗小树x的博客-CSDN博客
单目3D目标检测——SMOKE 模型推理 | 可视化结果-CSDN博客
后面计划分享,实时性的单目3D目标检测:MonoFlex、MonoEF、MonoDistillI、GUPNet、DEVIANT等

![[MoeCTF 2023] web题解](https://img-blog.csdnimg.cn/e1acba4f828942d9b3b7bb6ef3bc4b98.png)