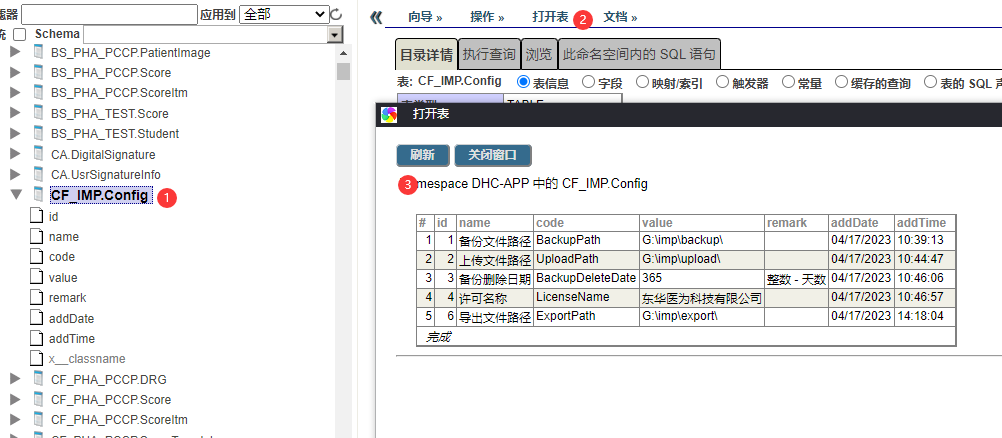
五、GPU技术要点
1.SMID和SIMT
SIMD(Single Instruction Multiple Data)是单指令多数据,在GPU的ALU(在Core内)单元内,一条指令可以处理多维向量(一般是4D)的数据。比如,有以下shader指令:
float4 c = a + b; // a,b都是float4类型
对于没有SIMD的处理单元,需要4条指令将4个float数值相加,汇编伪代码如下:
ADD c.x, a.x, b.x
ADD c.y, a.y, b.y
ADD c.z, a.z, b.z
ADD c.w, a.w, b.w
但是有了SIMD技术,只需要一条指令即可处理完:
SIMD_ADD c, a, b
for(i=0; i < n ; ++i) c[i] = a[i] + b[i];
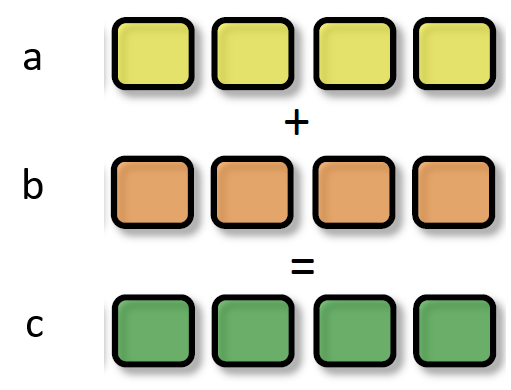
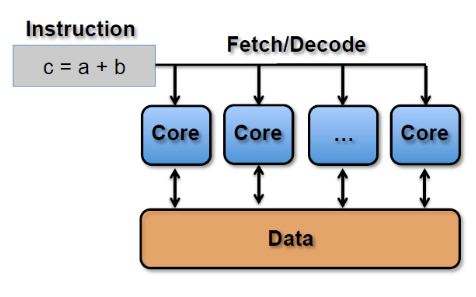
SIMT(Single Instruction Multiple Threads,单指令多线程)是SIMD的升级版,可对GPU中单个SM中的多个Core同时处理一个指令,并且每个Core存取的数据可以是不同的。
SIMT_ADD c,a,b
上述指令会被同时送入在单个SM中被编组的所有Core中,同事执行运算,但a、b、c的值可以不一样:

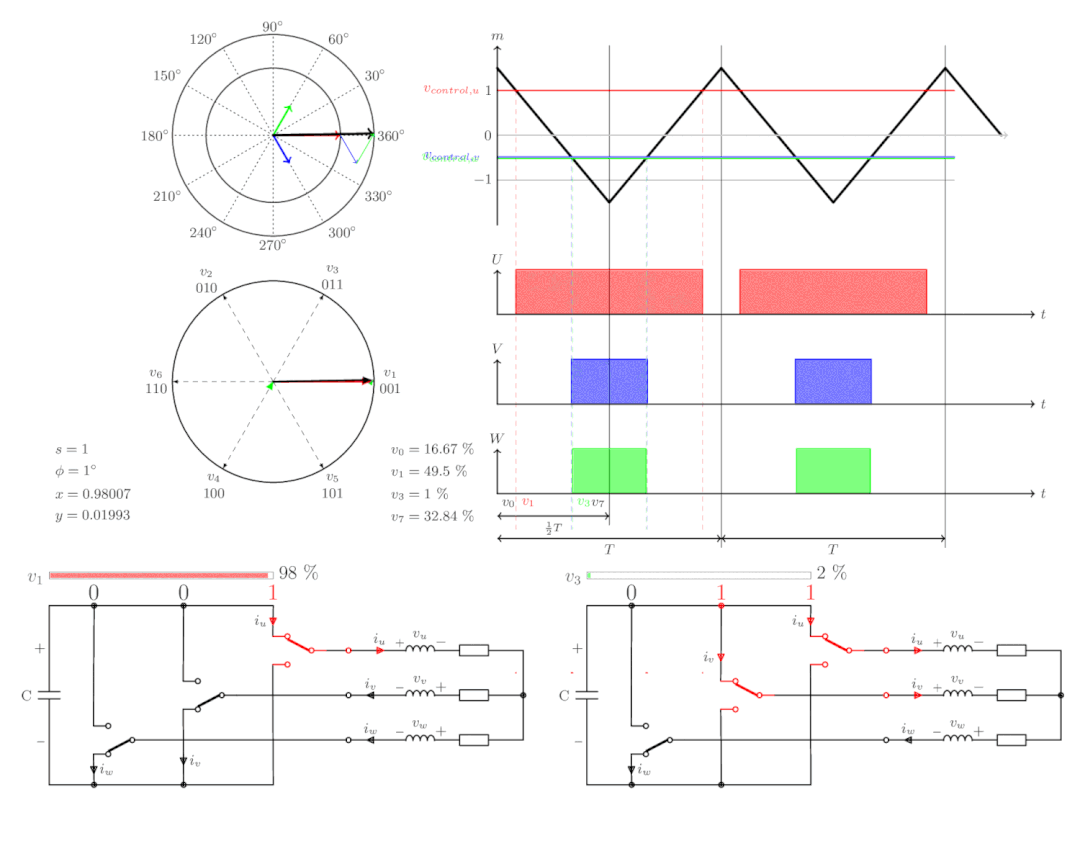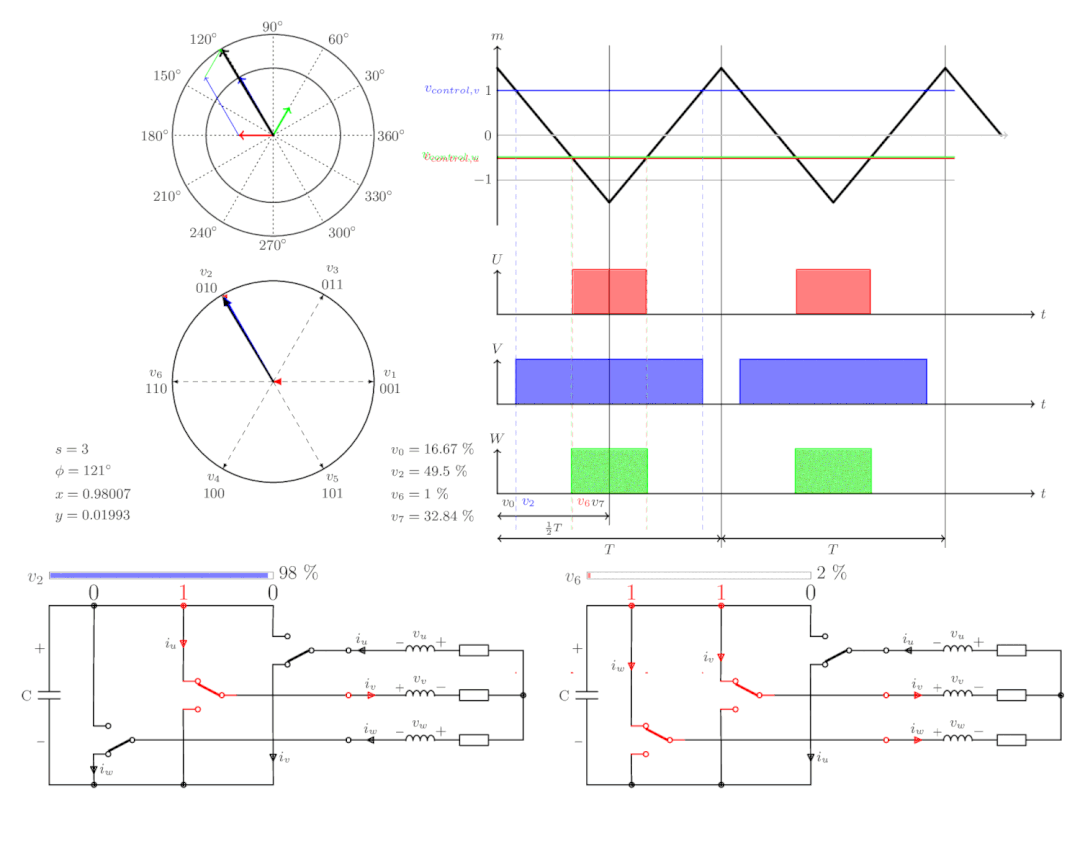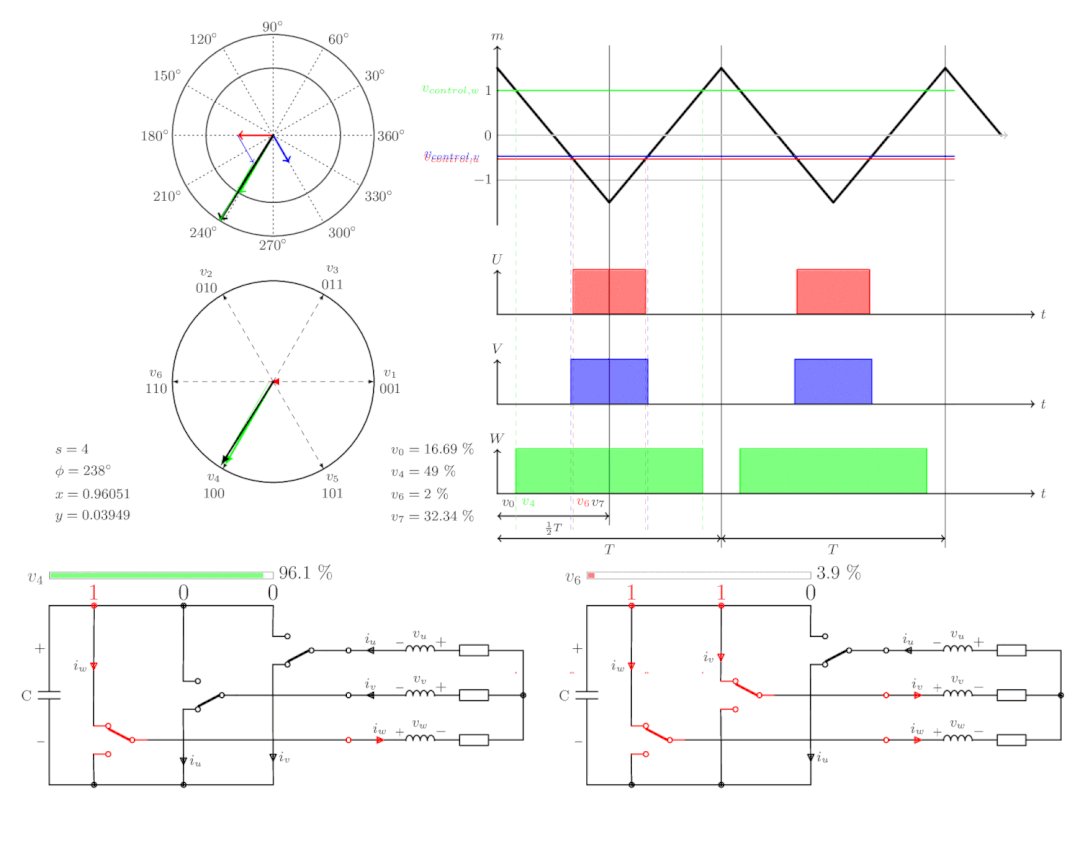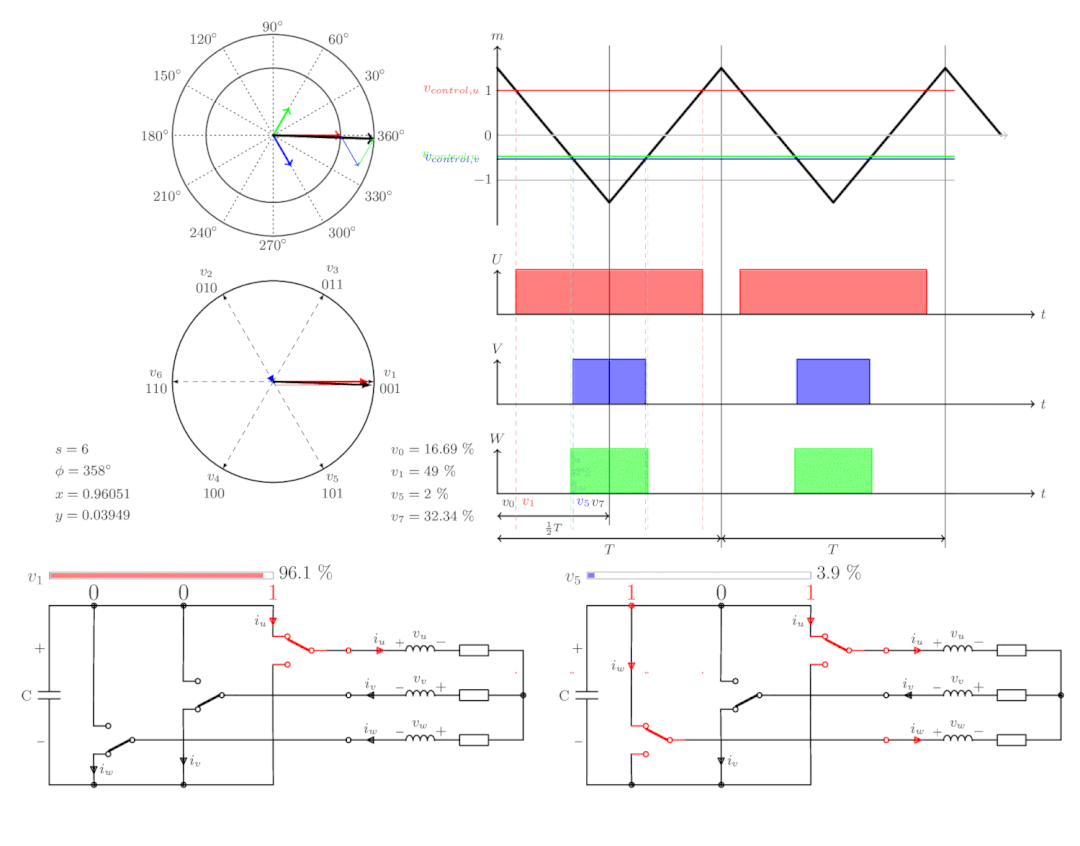
2.co-issue
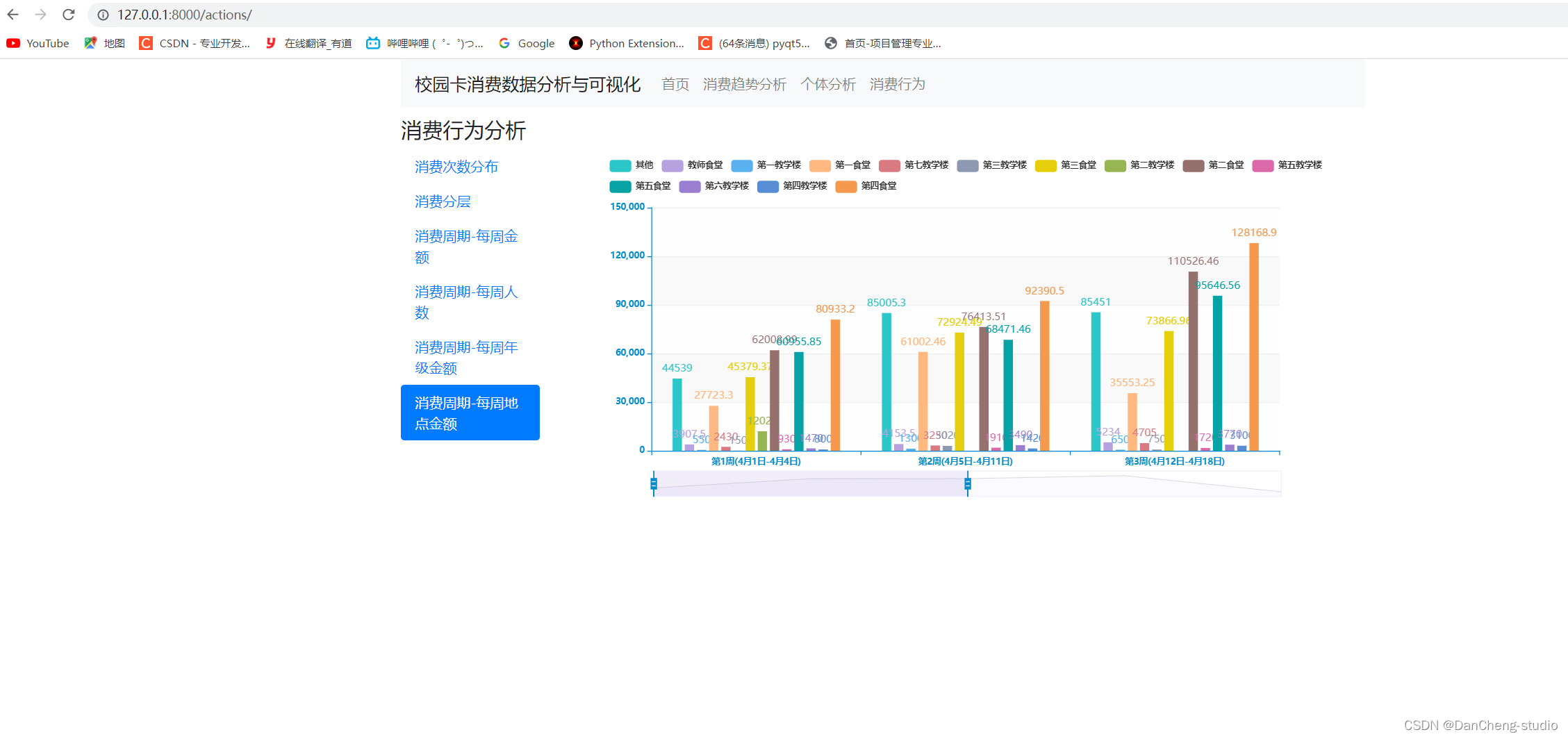
co-issue是为了解决SIMD运行单元无法充分利用的问题。例如下图,由于float数量的不同,ALU利用率从100%依次下降为75%、50%、25%。

为了解决着色器在低维向量的利用率低的问题,可以通过合并1D与3D与2D的指令。例如下图,DP3指令用了3D数据,ADD指令只有1D数据,co-issue会自动将他们合并,在同一个ALU只需要一个指令周期即可执行完。

但是对于向量运算(Vector ALU),如果其中一个变量既是操作数又是存储数的情况,无法启用co-issue技术:

3.if-else语句
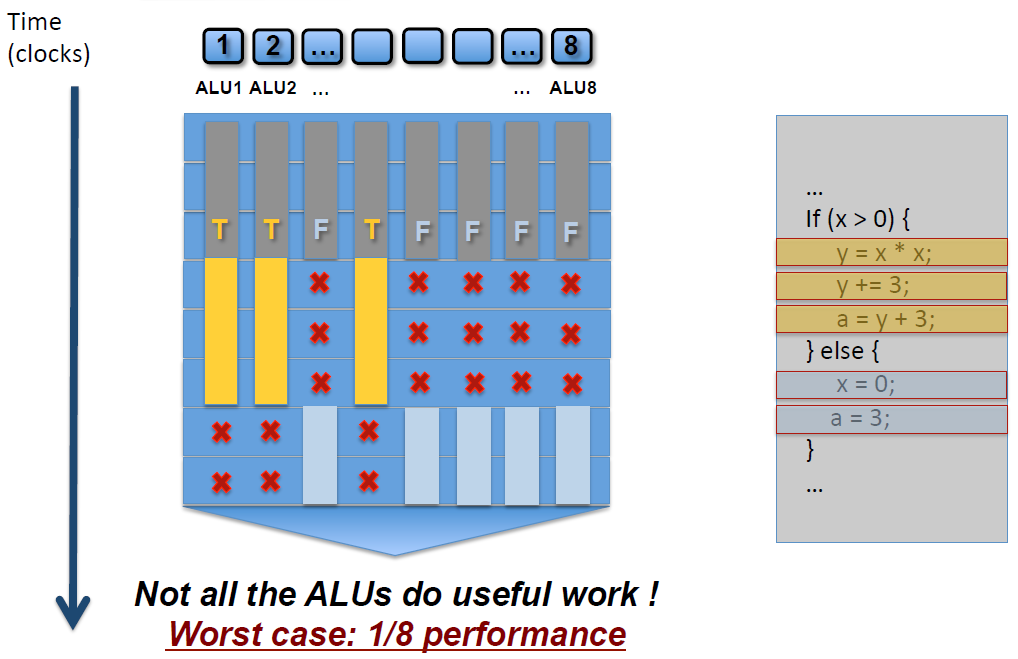
如上图,SM中有8个ALU(Core),由于SIMD的特性,每个ALU的数据都不一样,导致if-else语句在某些ALU中执行的是true分支(黄色),有些ALU执行的是false分支(灰蓝色),这样导致很多ALU的执行周期被浪费掉了(即masked out),拉长了整个执行周期。最坏的情况,同一个SM中只有1/8(8是同一个SM的线程数,不同架构的GPU有所不同)的利用率。
同样,for循环也会导致类似的情况,例如以下shader代码:
void func(int count, int breakNum)
{
for(int i = 0; i < count; ++i)
{
if (i == breakNum)
break;
else
// do something
}
}由于每个ALU的count不一样,加上有break分支,导致最快执行完shader的ALU可能是最慢的N分之一的时间,但由于SIMD的特性,最快的那个ALU依然要等待最慢的ALU执行完毕,才能接下一组指令的活!也就是白白浪费了很多时间周期。
4.Early-Z
早期GPU的渲染管线的深度测试是在像素着色器之后才执行(下图),这样会造成很多本不可见的像素执行了耗性能的像素着色器计算。

后来,为了减少像素着色器的额外消耗,将深度测试提至像素着色器之前(下图),这就是Early-Z技术的由来。

Early-Z技术可以将很多无效的像素提前剔除,避免它们进入耗时严重的像素着色器。Early-Z剔除的最小单位不是1像素,而是像素块(pixel quad,2x2个像素)。
但是,以下情况会导致Early-Z失效:
- 开启Alpha Test:由于Alpha Test需要在像素着色器后面的Alpha Test阶段比较,所以无法在像素着色器之前就决定该像素是否被剔除。
- 开启Alpha Blend:启用了Alpha混合的像素很多需要与frame buffer做混合,无法执行深度测试,也就无法利用Early-Z技术。
- 开启Tex Kill:即在shader代码中有像素摒弃指令(DX的discard,OpenGL的clip)。
- 关闭深度测试。Early-Z是建立在深度测试看开启的条件下,如果关闭了深度测试,也就无法启用Early-Z技术。
- 开启Multi-Sampling:多采样会影响周边像素,而Early-Z阶段无法得知周边像素是否被裁剪,故无法提前剔除。
- 以及其它任何导致需要混合后面颜色的操作。
此外,Early-Z技术会导致一个问题:深度数据冲突(depth data hazard)。

例子要结合上图,假设数值深度值5已经经过Early-Z即将写入Frame Buffer,而深度值10刚好处于Early-Z阶段,读取并对比当前缓存的深度值15,结果就是10通过了Early-Z测试,会覆盖掉比自己小的深度值5,最终frame buffer的深度值是错误的结果。
避免深度数据冲突的方法之一是在写入深度值之前,再次与frame buffer的值进行对比:

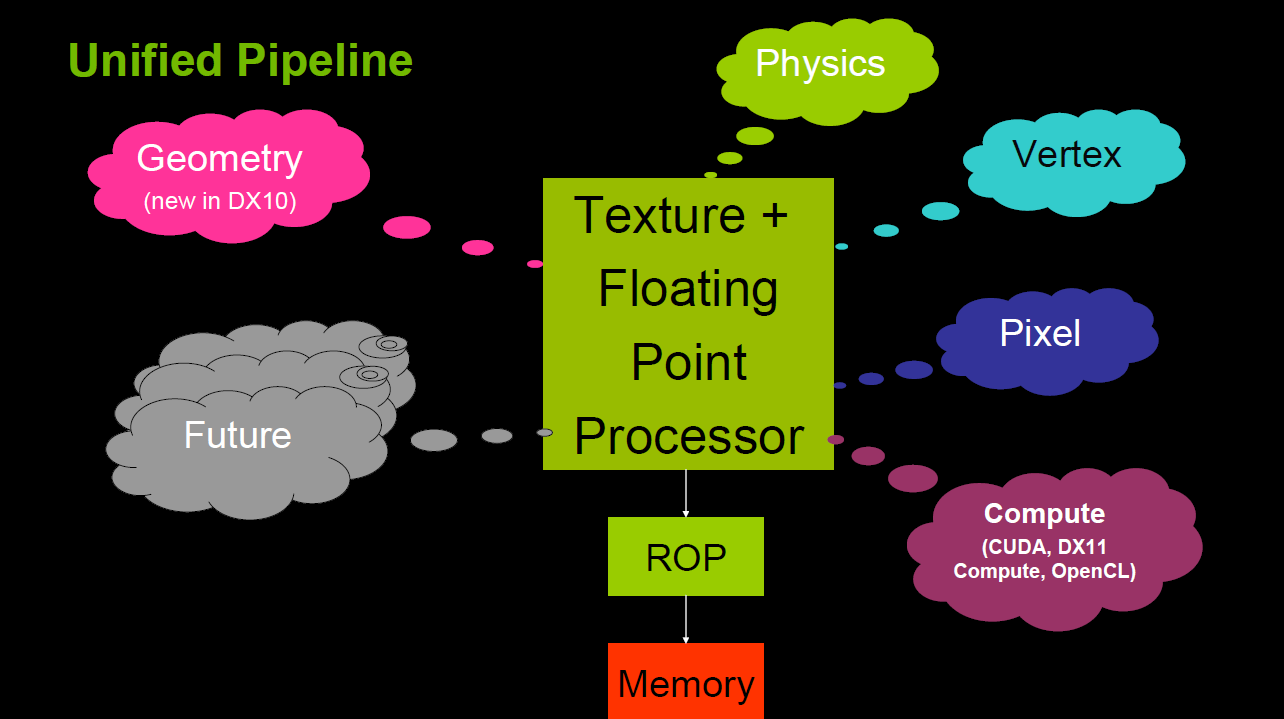
5.统一着色器架构(Unitfied shader Architecture)
在早期的GPU,顶点着色器和像素着色器的硬件结构是独立的,它们各有各的寄存器、运算单元等部件。这样很多时候,会造成顶点着色器与像素着色器之间任务的不平衡。对于顶点数量多的任务,像素着色器空闲状态多;对于像素多的任务,顶点着色器的空闲状态多(下图)。

于是,为了解决VS和PS之间的不平衡,引入了统一着色器架构(Unified shader Architecture)。用了此架构的GPU,VS和PS用的都是相同的Core。也就是,同一个Core既可以是VS又可以是PS。
6.像素块
5.4中提到的:
32个像素线程将被分成一组,或者说8个2x2的像素块,这是在像素着色器上面的最小工作单元,在这个像素线程内,如果没有被三角形覆盖就会被遮掩,SM中的warp调度器会管理像素着色器的任务。
也就是说,在像素着色器中,会将相邻的四个像素作为不可分隔的一组,送入同一个SM内4个不同的Core。
为什么像素着色器处理的最小单元是2x2的像素块?
推测有以下原因:
1、简化和加速像素分派的工作。
2、精简SM的架构,减少硬件单元数量和尺寸。
3、降低功耗,提高效能比。
4、无效像素虽然不会被存储结果,但可辅助有效像素求导函数。
这种设计虽然有其优势,但同时,也会激化过绘制(Over Draw)的情况,损耗额外的性能。比如下图中,白色的三角形只占用了3个像素(绿色),按我们普通的思维,只需要3个Core绘制3次就可以了。
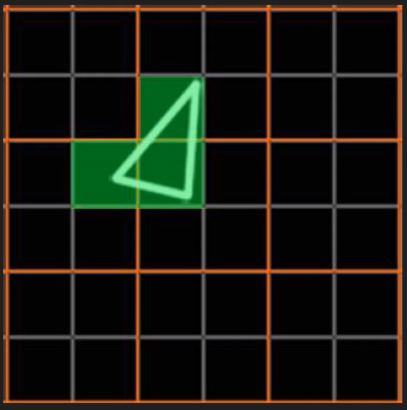
但是,由于上面的3个像素分别占据了不同的像素块(橙色分隔),实际上需要占用12个Core绘制12次(下图)。
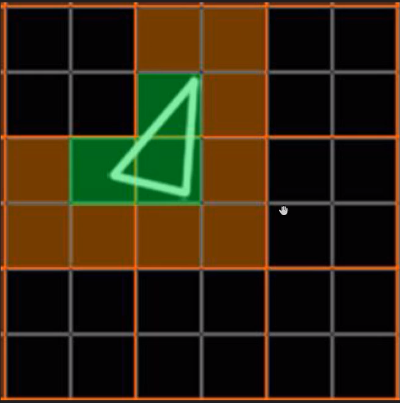
这就会额外消耗300%的硬件性能,导致了更加严重的过绘制情况。
更多详情可以观看虚幻官方的视频教学:实时渲染深入探究。