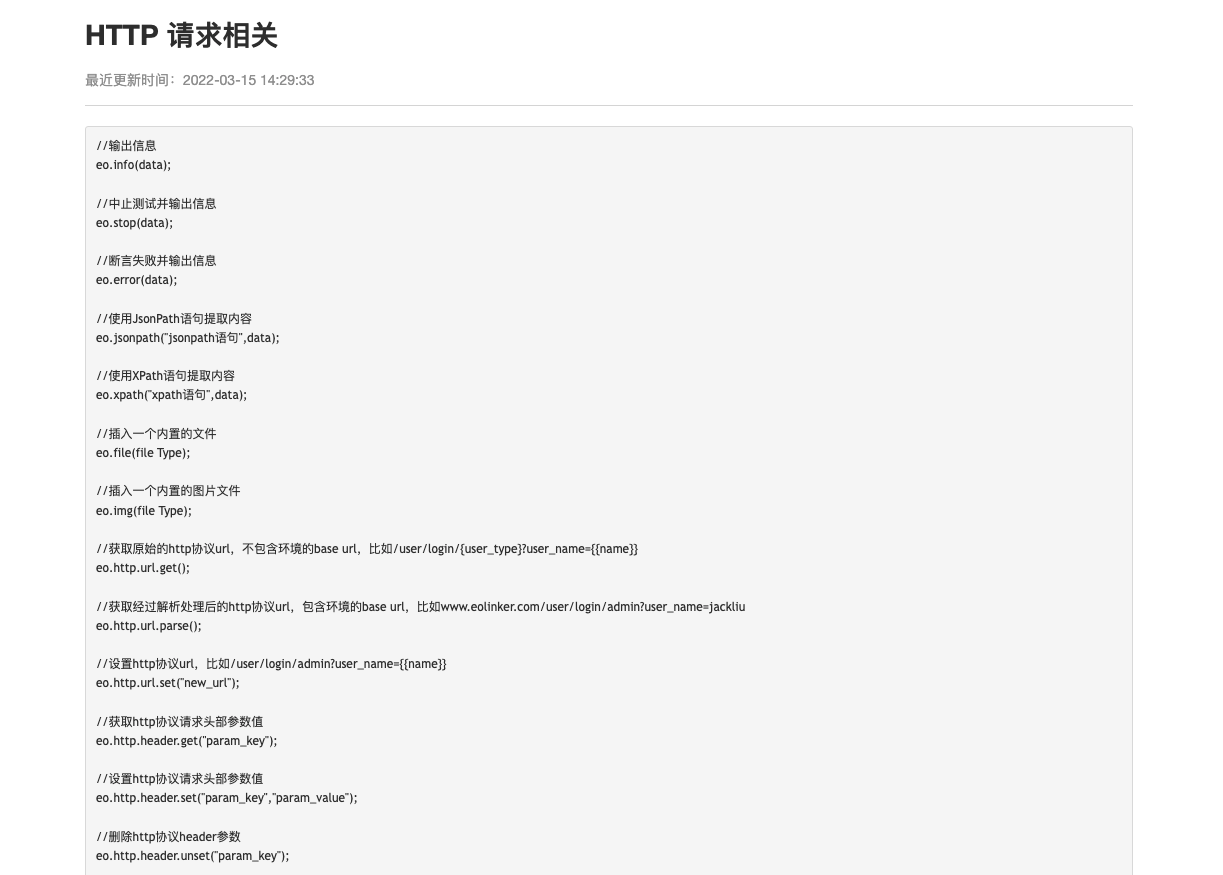
- 用好大模型的层次:1. 提示词工程(prompt engineering); 2. 大模型微调(fine tuning)
- 为什么要对大模型微调: 1. 大模型预训练成本非常高; 2. 如果prompt engineering的效果达不到要求,企业又有比较好的自有数据,能够通过自由数据,更高的提升大模型在特定领域的能力
- 大模型微调的两个方案:全量微调(full fine tunning) ; 部分参数微调(parameter - effictient fine tuning)
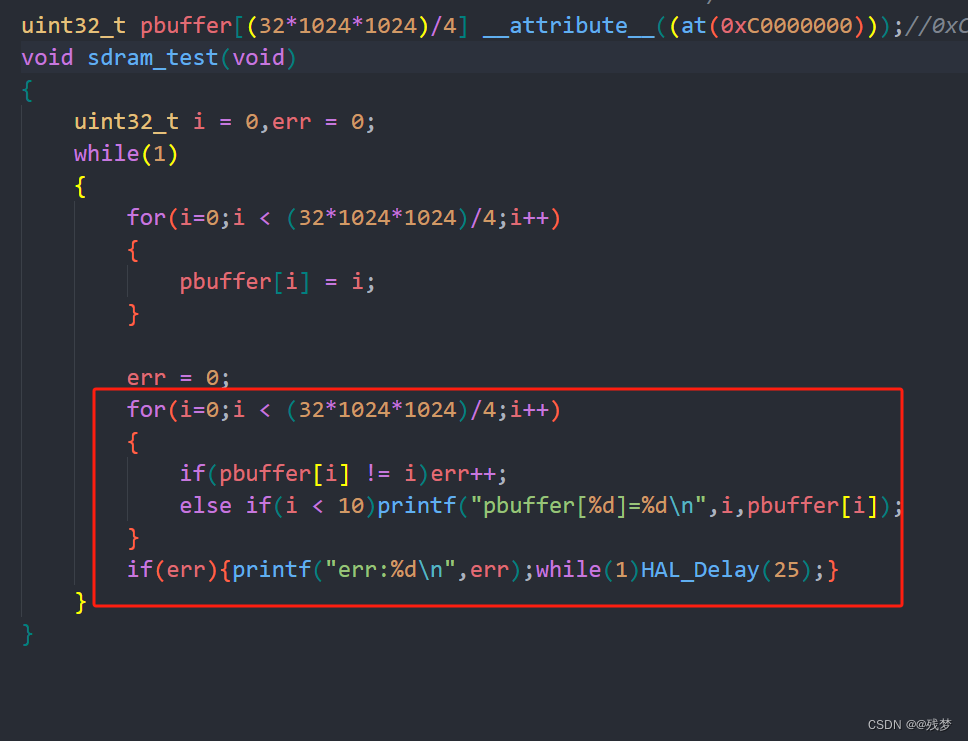
- 全量微调的问题:1. 参数量和预训练相同,消耗大量资源; 2. 灾难性遗忘
- 常见的模型微调路线:1. 监督式微调SFT( Supervised Fine Tuning); 2. 基于人类反馈的强化学习微调RLHF(把人类的反馈通过强化学习的方式,引入到大模型的微调中); 3. 基于AI反馈的强化学习微调RLAIF(人类反馈成本高)
从成本和效果角度考虑:PEFT是目前业界比较流行的微调方案
- Prompt Tuning: 在输入序列X之前,增加特定长度的特殊Token,发生在Enbedding环节
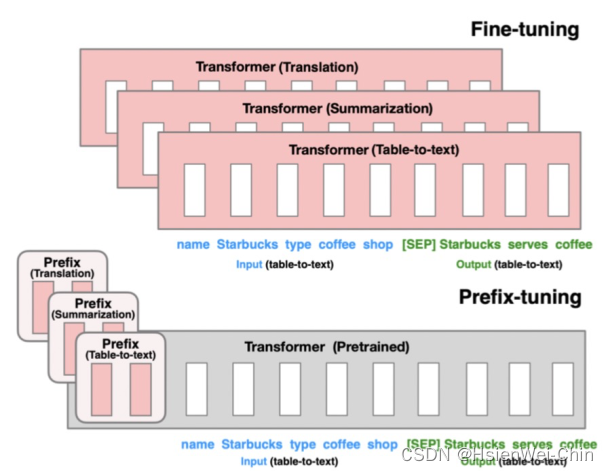
- Prefix Tuning: 在transformer的encoder和decoder的网络中都加入特定前缀
- LoRA
- QLoRA 量化的LoRA:量化的核心目标是降低成本,降低训练成本,特别是降低后期的推理成本
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
比较高效的finetuning方法包括adaptor, prefix-tuning, LoRA
adaptor
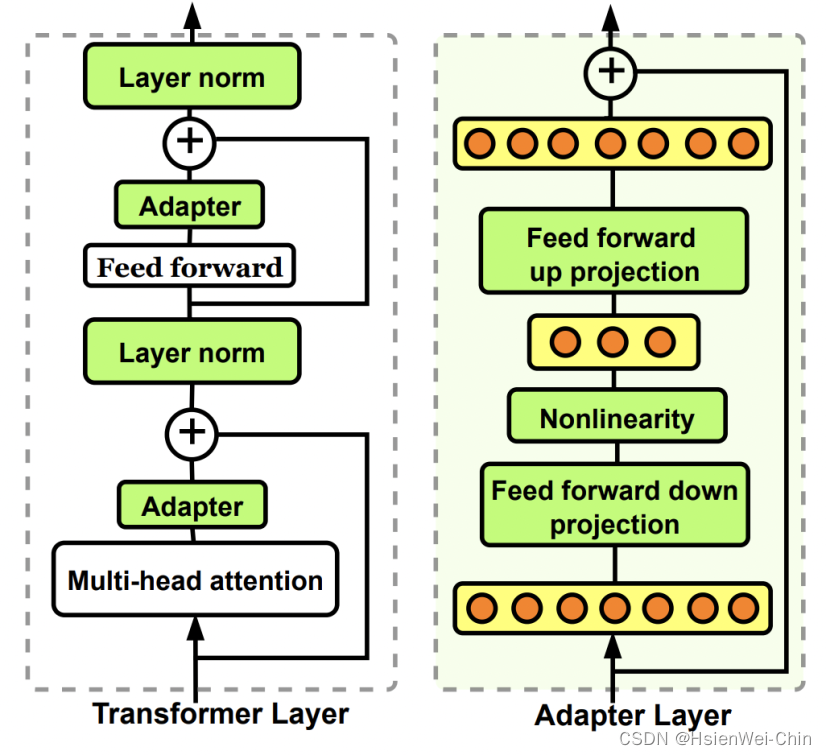
prefix-tunning
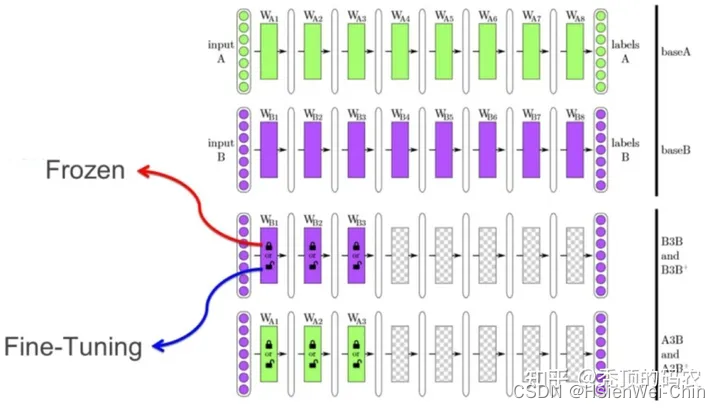
浅层特征通用性强,深层特征与具体任务的关联性强
finetuning扮演的角色:
- 拿到新数据集后,想要用预训练模型处理的时候,会首先将最后一层全连接层打开,其余层冻结(transfer learning),看预训练模型在新数据上的效果怎么样,先摸个底,如果效果可以,就考虑打开更多的层,进行fine tuning
- 如果新的数据集和预训练数据集差别很大,一方面考虑从头训练,另一方面考虑打开更多的层,或干脆用预训练模型的参数作为初始值,对模型进行完整的训练
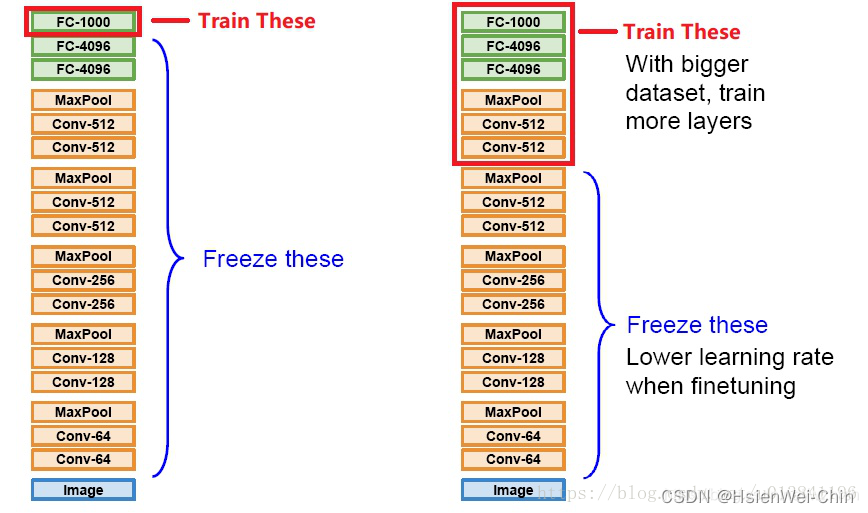
- 模型微调方式
- 固定一部分模型
- 固定全部预训练模型,添加可训练head
- 使用预训练模型推理过程,将数据处理为特征和标签,使用新的特征数据和标签,训练小的head,去进行下游任务(优点:数据特征提取一次可永久使用,特征提取结束后,下游任务和预训练模型无关,除了推理时需要将原有图片处理为特征外)
- 模型全调方式
- 加载预训练模型为模型初始权重,重训练