流程
milvus的使用流程是 创建collection -> 创建partition -> 创建索引(如果需要检索) -> 插入数据 -> 检索
这里以Python为例, 使用的milvus版本为2.3.x
首先按照库, python3 -m pip install pymilvus
Connect
from pymilvus import connections
connections.connect(
alias="default",
user='username',
password='password',
host='localhost',
port='19530'
)
connections.list_connections()
connections.get_connection_addr('default')
connections.disconnect("default")
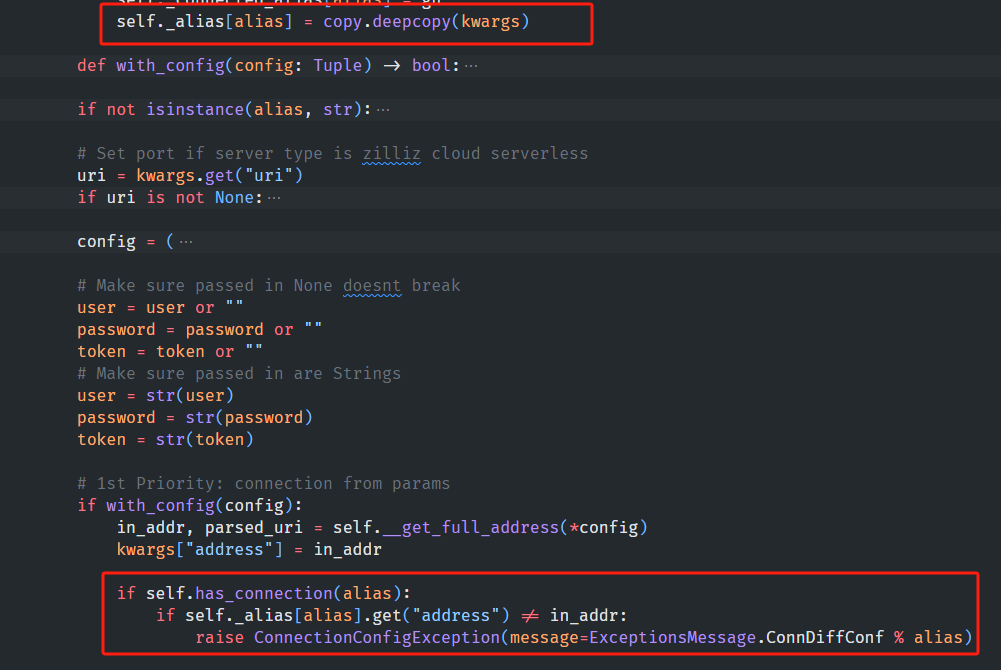
以上是源码,可以看出alias只是一个字典的映射的key
通过源码可以看到,还有两种连接方式:
- 在.env文件中添加参数,
MILVUS_URI=milvus://<Your_Host>:<Your_Port>,之后可以使用connections.connect()连接 - 在一次连接成功后,将连接配置数据保存在内存,下次近执行
connections.connect()即可连接,可以通过connections.remove_connection删除连接配置数据
Database
from pymilvus import connections, db
conn = connections.connect(host="127.0.0.1", port=19530)
database = db.create_database("book")
db.using_database("book") # 切换数据库
db.list_database()
db.drop_database("book")
Collection
和一些非关系型数据库(MongoDB)类似,Collection就是表
# collection
from pymilvus import Collection, CollectionSchema, FieldSchema, DataType, utility
## 需要提前创建列的名称、类型等数据,并且必须添加一个主键
book_id = FieldSchema(
name="book_id",
dtype=DataType.INT64,
is_primary=True,
)
book_name = FieldSchema(
name="book_name",
dtype=DataType.VARCHAR,
max_length=200,
# The default value will be used if this field is left empty during data inserts or upserts.
# The data type of `default_value` must be the same as that specified in `dtype`.
default_value="Unknown"
)
word_count = FieldSchema(
name="word_count",
dtype=DataType.INT64,
# The default value will be used if this field is left empty during data inserts or upserts.
# The data type of `default_value` must be the same as that specified in `dtype`.
default_value=9999
)
book_intro = FieldSchema(
name="book_intro",
dtype=DataType.FLOAT_VECTOR,
dim=2
)
# dim=2是向量的维度
schema = CollectionSchema(
fields=[book_id, book_name, word_count, book_intro],
description="Test book search",
enable_dynamic_field=True
)
collection_name = "book"
collection = Collection(
name=collection_name,
schema=schema,
using='default',
shards_num=2
)
utility.rename_collection("book", "lights4")
utility.has_collection("lights1")
utility.list_collections()
# utility.drop_collection("lights")
collection = Collection("lights3")
collection.load(replica_number=2)
# reduce memory usage
collection.release()
Partition
# Create a Partition
collection = Collection("book") # Get an existing collection.
collection.create_partition("novel")
Index
milvus的索引决定了搜索所用的算法,必须设置好所引才能进行搜索。
# Index
index_params = {
"metric_type":"L2",
"index_type":"IVF_FLAT",
"params":{"nlist":1024}
}
collection.create_index(
field_name="book_intro",
index_params=index_params
)
## metric_type是相似性计算算法,可选的有以下
## For floating point vectors:
## L2 (Euclidean distance)
## IP (Inner product)
## COSINE (Cosine similarity)
## For binary vectors:
## JACCARD (Jaccard distance)
## HAMMING (Hamming distance)
utility.index_building_progress("<Your_Collection>")
Data
数据可以从dataFrame来,也可以从其他方式获得,只要列名对上,即可。
import pandas as pd
import numpy as np
insert_data = pd.read_csv("<Your_File>")
mr = collection.insert(insert_data)
Search
# search
search_params = {
"metric_type": "L2",
"offset": 5,
"ignore_growing": False,
"params": {"nprobe": 10}
}
results = collection.search(
data=[[0.1, 0.2]],
anns_field="book_intro",
# the sum of `offset` in `param` and `limit`
# should be less than 16384.
param=search_params,
limit=10,
expr=None,
# 这里需要将想看的列名列举出来
output_fields=['title'],
consistency_level="Strong"
)
# get the IDs of all returned hits
results[0].ids
# get the distances to the query vector from all returned hits
results[0].distances
# get the value of an output field specified in the search request.
hit = results[0][0]
hit.entity.get('title')
具体的代码在我的github。希望对你有所帮助!