上一课时,我们着重讲了方法名和参数的使用方法,这一课时我们来看下Repository 支持的返回结果有哪些,以及 DTO 类型的返回结果如何自定义,及其在实际工作场景中我们如何做。通过本课时的学习,你将了解到 Repository 的几种返回结果,以及如何返回 DTO。我们先看一下返回结果有哪些。
Repository 的返回结果有哪些?
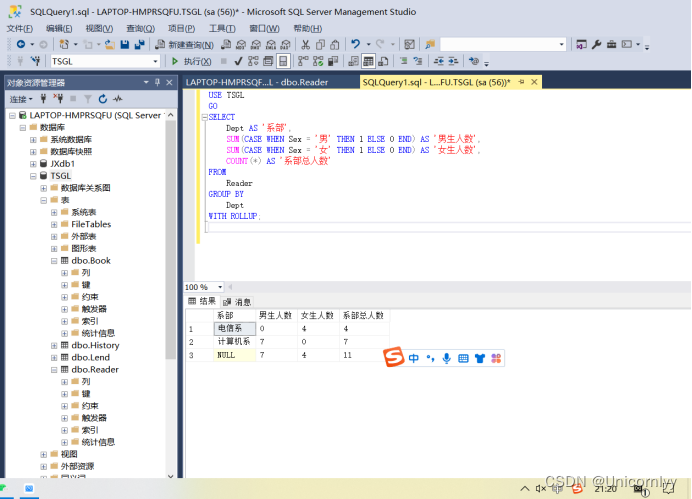
我们之前已经介绍过了 Repository 的接口,那么现在来看一下这些接口支持的返回结果有哪些,如下图所示:
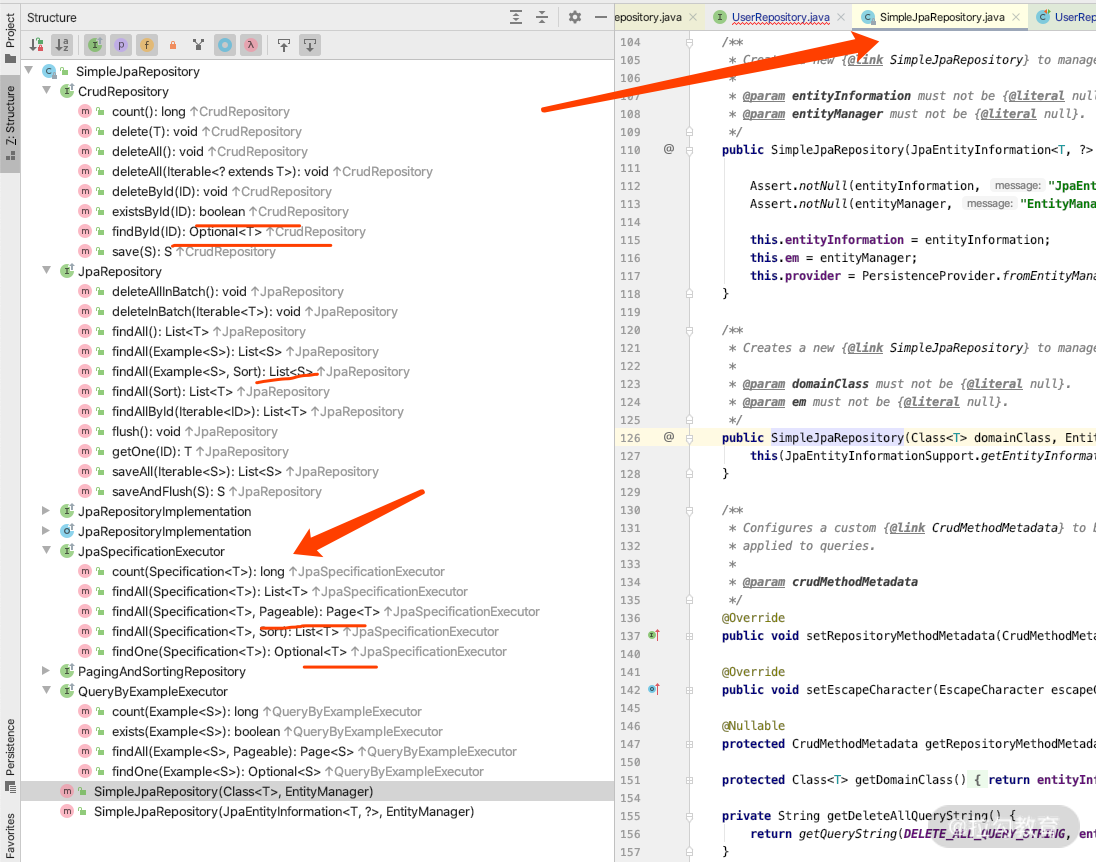
打开 SimpleJpaRepository 直接看它的 Structure 就可以知道,它实现的方法,以及父类接口的方法和返回类型包括:Optional、Iterable、List、Page、Long、Boolean、Entity 对象等,而实际上支持的返回类型还要多一些。
由于 Repository 里面支持 Iterable,所以其实 java 标准的 List、Set 都可以作为返回结果,并且也会支持其子类,Spring Data 里面定义了一个特殊的子类 Steamable,Streamable 可以替代 Iterable 或任何集合类型。它还提供了方便的方法来访问 Stream,可以直接在元素上进行 ….filter(…) 和 ….map(…) 操作,并将 Streamable 连接到其他元素。我们看个关于 UserRepository 直接继承 JpaRepository 的例子。
复制代码
public interface UserRepository extends JpaRepository<User,Long> {
}
还用之前的 UserRepository 类,在测试类里面做如下调用:
复制代码
User user = userRepository.save(User.builder().name("jackxx").email("123456@126.com").sex("man").address("shanghai").build());
Assert.assertNotNull(user);
Streamable<User> userStreamable = userRepository.findAll(PageRequest.of(0,10)).and(User.builder().name("jack222").build());
userStreamable.forEach(System.out::println);
然后我们就会得到如下输出:
复制代码
User(id=1, name=jackxx, email=123456@126.com, sex=man, address=shanghai)
User(id=null, name=jack222, email=null, sex=null, address=null)
这个例子 Streamable`` userStreamable,实现了 Streamable 的返回结果,如果想自定义方法,可以进行如下操作。
自定义 Streamable
官方给我们提供了自定义 Streamable 的方法,不过在实际工作中很少出现要自定义保证结果类的情况,在这里我简单介绍一下方法,看如下例子:
复制代码
class Product { (1)
MonetaryAmount getPrice() { … }
}
@RequiredArgConstructor(staticName = "of")
class Products implements Streamable<Product> { (2)
private Streamable<Product> streamable;
public MonetaryAmount getTotal() { (3)
return streamable.stream() //
.map(Priced::getPrice)
.reduce(Money.of(0), MonetaryAmount::add);
}
}
interface ProductRepository implements Repository<Product, Long> {
Products findAllByDescriptionContaining(String text); (4)
}
以上四个步骤介绍了自定义 Streamable 的方法,分别为:
(1)Product 实体,公开 API 以访问产品价格。
(2)Streamable`` 的包装类型可以通过 Products.of(…) 构造(通过 Lombok 注解创建的工厂方法)。
(3)包装器类型在 Streamable`` 上公开了计算新值的其他 API。
(4)可以将包装器类型直接用作查询方法返回类型。无须返回 Stremable`` 并将其手动包装在存储库 Client 端中。
通过以上例子你就可以做到自定义 Streamable,其原理很简单,就是实现Streamable接口,自己定义自己的实现类即可。我们也可以看下源码 QueryExecutionResultHandler 里面是否有 Streamable 子类的判断,来支持自定义 Streamable,关键源码如下:
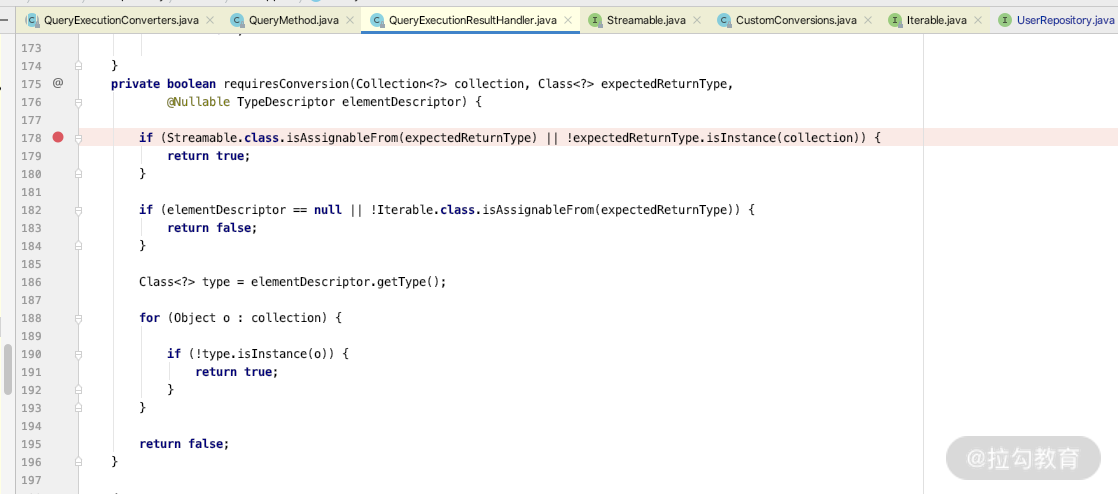
通过源码你会发现 Streamable 为什么生效,下面来看看常见的集合类的返回实现。
返回结果类型 List/Stream/Page/Slice
在实际开发中,我们如何返回 List/Stream/Page/Slice 呢?
首先,新建我们的 UserRepository:
复制代码
package com.example.jpa.example1;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import java.util.stream.Stream;
public interface UserRepository extends JpaRepository<User,Long> {
//自定义一个查询方法,返回Stream对象,并且有分页属性
@Query("select u from User u")
Stream<User> findAllByCustomQueryAndStream(Pageable pageable);
//测试Slice的返回结果
@Query("select u from User u")
Slice<User> findAllByCustomQueryAndSlice(Pageable pageable);
}
然后,修改一下我们的测试用例类,如下,验证一下结果:
复制代码
package com.example.jpa.example1;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.assertj.core.util.Lists;
import org.junit.Assert;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Slice;
import org.springframework.data.util.Streamable;
import java.util.List;
import java.util.stream.Stream;
@DataJpaTest
public class UserRepositoryTest {
@Autowired
private UserRepository userRepository;
@Test
public void testSaveUser() throws JsonProcessingException {
//我们新增7条数据方便测试分页结果
userRepository.save(User.builder().name("jack1").email("123456@126.com").sex("man").address("shanghai").build());
userRepository.save(User.builder().name("jack2").email("123456@126.com").sex("man").address("shanghai").build());
userRepository.save(User.builder().name("jack3").email("123456@126.com").sex("man").address("shanghai").build());
userRepository.save(User.builder().name("jack4").email("123456@126.com").sex("man").address("shanghai").build());
userRepository.save(User.builder().name("jack5").email("123456@126.com").sex("man").address("shanghai").build());
userRepository.save(User.builder().name("jack6").email("123456@126.com").sex("man").address("shanghai").build());
userRepository.save(User.builder().name("jack7").email("123456@126.com").sex("man").address("shanghai").build());
//我们利用ObjectMapper将我们的返回结果Json to String
ObjectMapper objectMapper = new ObjectMapper();
//返回Stream类型结果(1)
Stream<User> userStream = userRepository.findAllByCustomQueryAndStream(PageRequest.of(1,3));
userStream.forEach(System.out::println);
//返回分页数据(2)
Page<User> userPage = userRepository.findAll(PageRequest.of(0,3));
System.out.println(objectMapper.writeValueAsString(userPage));
//返回Slice结果(3)
Slice<User> userSlice = userRepository.findAllByCustomQueryAndSlice(PageRequest.of(0,3));
System.out.println(objectMapper.writeValueAsString(userSlice));
//返回List结果(4)
List<User> userList = userRepository.findAllById(Lists.newArrayList(1L,2L));
System.out.println(objectMapper.writeValueAsString(userList));
}
}
这个时候我们分别看下四种测试结果:
第一种:通过Stream``取第二页的数据,得到结果如下:
User(id=4, name=jack4, email=123456@126.com, sex=man, address=shanghai)
User(id=5, name=jack5, email=123456@126.com, sex=man, address=shanghai)
User(id=6, name=jack6, email=123456@126.com, sex=man, address=shanghai)
Spring Data 的支持可以通过使用 Java 8 Stream 作为返回类型来逐步处理查询方法的结果。需要注意的是:流的关闭问题,try catch 是一种常用的关闭方法,如下所示:
复制代码
Stream<User> stream;
try {
stream = repository.findAllByCustomQueryAndStream()
stream.forEach(…);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (stream!=null){
stream.close();
}
}
第二种:返回 Page`` 的分页数据结果,如下所示:
复制代码
{
"content":[
{
"id":1,
"name":"jack1",
"email":"123456@126.com",
"sex":"man",
"address":"shanghai"
},
{
"id":2,
"name":"jack2",
"email":"123456@126.com",
"sex":"man",
"address":"shanghai"
},
{
"id":3,
"name":"jack3",
"email":"123456@126.com",
"sex":"man",
"address":"shanghai"
}
],
"pageable":{
"sort":{
"sorted":false,
"unsorted":true,
"empty":true
},
"pageNumber":0,当前页码
"pageSize":3,页码大小
"offset":0,偏移量
"paged":true,是否分页了
"unpaged":false
},
"totalPages":3,一共有多少页
"last":false,是否是到最后
"totalElements":7,一共多少调数
"numberOfElements":3,当前数据下标
"sort":{
"sorted":false,
"unsorted":true,
"empty":true
},
"size":3,当前content大小
"number":0,当前页面码的索引
"first":true,是否是第一页
"empty":false是否有数据
}
这里我们可以看到 Page`` 返回了第一个页的数据,并且告诉我们一共有三个部分的数据:
- content:数据的内容,现在指 User 的 List 3 条。
- pageable:分页数据,包括排序字段是什么及其方向、当前是第几页、一共多少页、是否是最后一条等。
- 当前数据的描述:“size”:3,当前 content 大小;“number”:0,当前页面码的索引; “first”:true,是否是第一页;“empty”:false,是否没有数据。
通过这三部分数据我们可以知道要查数的分页信息。我们接着看第三种测试结果。
第三种:返回 Slice`` 结果,如下所示:
复制代码
{
"content":[
{
"id":4,
"name":"jack4",
"email":"123456@126.com",
"sex":"man",
"address":"shanghai"
},
{
"id":5,
"name":"jack5",
"email":"123456@126.com",
"sex":"man",
"address":"shanghai"
},
{
"id":6,
"name":"jack6",
"email":"123456@126.com",
"sex":"man",
"address":"shanghai"
}
],
"pageable":{
"sort":{
"sorted":false,
"unsorted":true,
"empty":true
},
"pageNumber":1,
"pageSize":3,
"offset":3,
"paged":true,
"unpaged":false
},
"numberOfElements":3,
"sort":{
"sorted":false,
"unsorted":true,
"empty":true
},
"size":3,
"number":1,
"first":false,
"last":false,
"empty":false
}
这时我们发现上面的 Page 返回结果少了,那么一共有多少条结果、多少页的数据呢?我们再比较一下第二种和第三种测试结果的执行 SQL:
第二种执行的是普通的分页查询 SQL:
复制代码
查询分页数据
Hibernate: select user0_.id as id1_0_, user0_.address as address2_0_, user0_.email as email3_0_, user0_.name as name4_0_, user0_.sex as sex5_0_ from user user0_ limit ?
计算分页数据
Hibernate: select count(user0_.id) as col_0_0_ from user user0_
第三种执行的 SQL 如下:
复制代码
Hibernate: select user0_.id as id1_0_, user0_.address as address2_0_, user0_.email as email3_0_, user0_.name as name4_0_, user0_.sex as sex5_0_ from user user0_ limit ? offset ?
通过对比可以看出,只查询偏移量,不计算分页数据,这就是 Page 和 Slice 的主要区别。我们接着看第四种测试结果。
第四种:返回 List`` 结果如下:
复制代码
[
{
"id":1,
"name":"jack1",
"email":"123456@126.com",
"sex":"man",
"address":"shanghai"
},
{
"id":2,
"name":"jack2",
"email":"123456@126.com",
"sex":"man",
"address":"shanghai"
}
]
到这里,我们可以很简单地查询出来 ID=1 和 ID=2 的数据,没有分页信息。
上面四种方法介绍了常见的多条数据返回结果的形式,单条的我就不多介绍了,相信你一看就懂,无非就是对 JDK8 的 Optional 的支持。比如支持了 Null 的优雅判断,再一个就是支持直接返回 Entity,或者一些存在 / 不存在的 Boolean 的结果和一些 count 条数的返回结果而已。
我们接下来看下 Repository 的方法是如何对异步进行支持的?
Repository 对 Feature/CompletableFuture 异步返回结果的支持:
我们可以使用 Spring 的异步方法执行Repository查询,这意味着方法将在调用时立即返回,并且实际的查询执行将发生在已提交给 Spring TaskExecutor 的任务中,比较适合定时任务的实际场景。异步使用起来比较简单,直接加@Async 注解即可,如下所示:
复制代码
@Async
Future<User> findByFirstname(String firstname); (1)
@Async
CompletableFuture<User> findOneByFirstname(String firstname); (2)
@Async
ListenableFuture<User> findOneByLastname(String lastname);(3)
上述三个异步方法的返回结果,分别做如下解释:
- 第一处:使用 java.util.concurrent.Future 的返回类型;
- 第二处:使用 java.util.concurrent.CompletableFuture 作为返回类型;
- 第三处:使用 org.springframework.util.concurrent.ListenableFuture 作为返回类型。
以上是对 @Async 的支持,关于实际使用需要注意以下三点内容:
- 在实际工作中,直接在 Repository 这一层使用异步方法的场景不多,一般都是把异步注解放在 Service 的方法上面,这样的话,可以有一些额外逻辑,如发短信、发邮件、发消息等配合使用;
- 使用异步的时候一定要配置线程池,这点切记,否则“死”得会很难看;
- 万一失败我们会怎么处理?关于事务是怎么处理的呢?这种需要重点考虑的,我将会在 14 课时(乐观锁机制和重试机制在实战中应该怎么用?)中详细介绍。
接下来看看 Repository 对Reactive 是如何支持的。
对 Reactive 支持 flux 与 Mono
可能有同学会问,看到Spring Data Common里面对React还是有支持的,那为什么在JpaRespository里面没看到有响应的返回结果支持呢?其实Common里面提供的只是接口,而JPA里面没有做相关的Reactive 的实现,但是本身Spring Data Common里面对 Reactive 是支持的。
下面我们在 gradle 里面引用一个Spring Data Common的子模块implementation ‘org.springframework.boot:spring-boot-starter-data-mongodb’ 来加载依赖,这时候我们打开 Repository 看 Hierarchy 就可以看到,这里多了一个 Mongo 的 Repsitory 的实现,天然地支持着 Reactive 这条线。
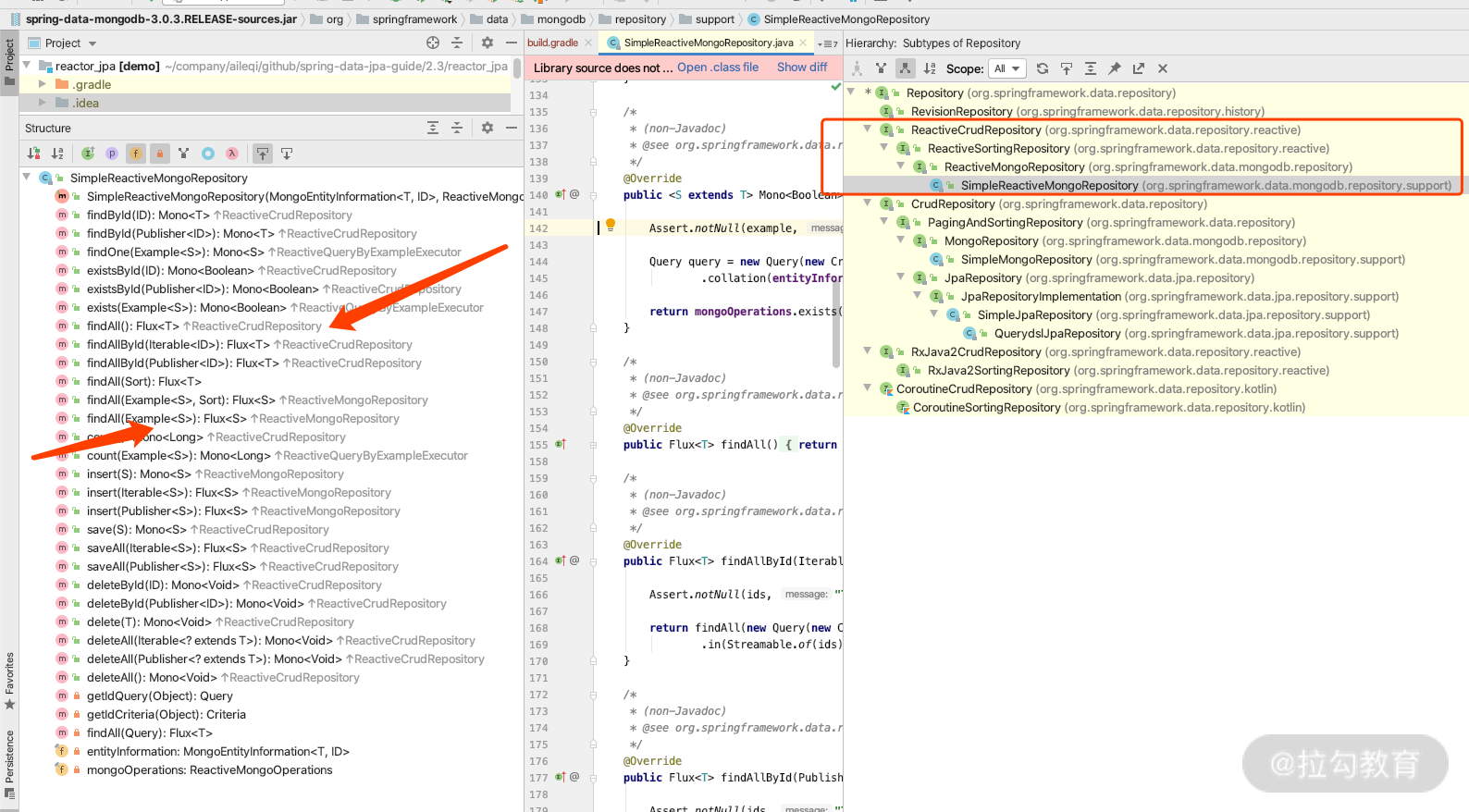
相信到这里你能感受到 Spring Data Common 的强大支持,对 Repository 接口的不同实现也有了一定的认识。对于以上讲述的返回结果,你可以自己测试一下加以理解并运用,那么接下来我们进行一个总结。
返回结果支持总结
下面打开 ResultProcessor 类的源码看一下支持的类型有哪些。
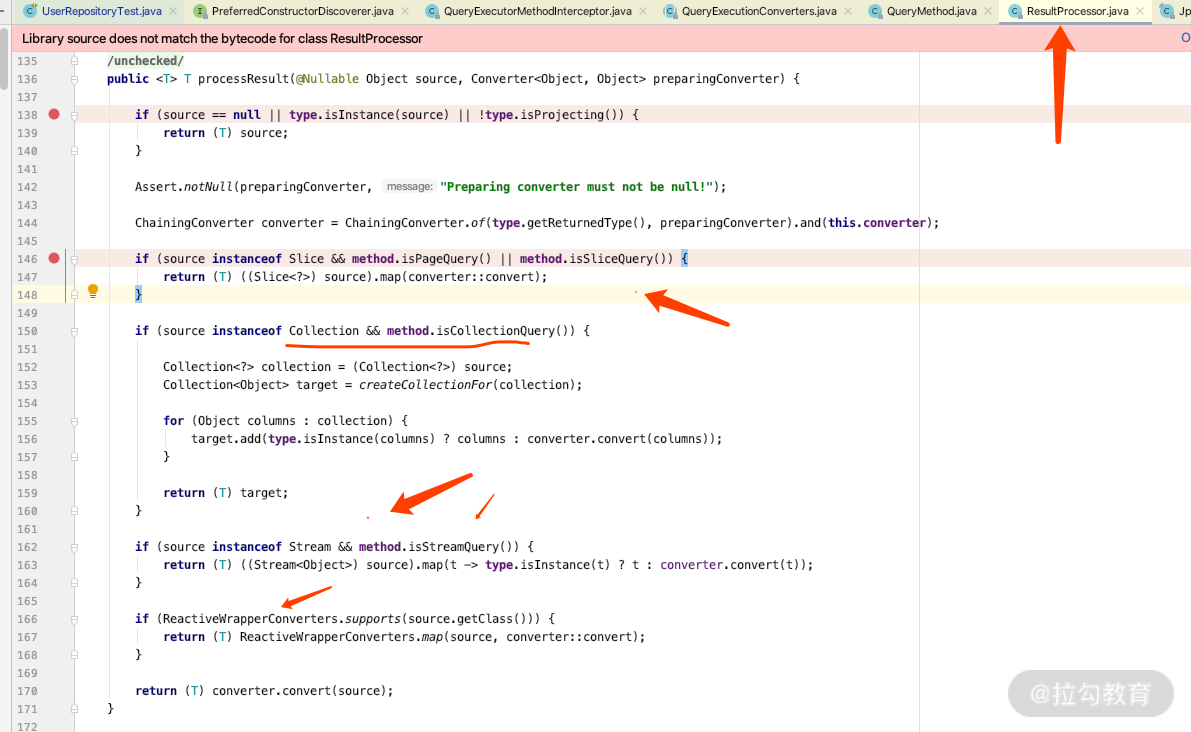
从上图可以看出 processResult 的时候分别对 PageQuery、Stream、Reactiv 有了各自的判断,我们 debug 到这里的时候来看一下 convert,进入到类里面。
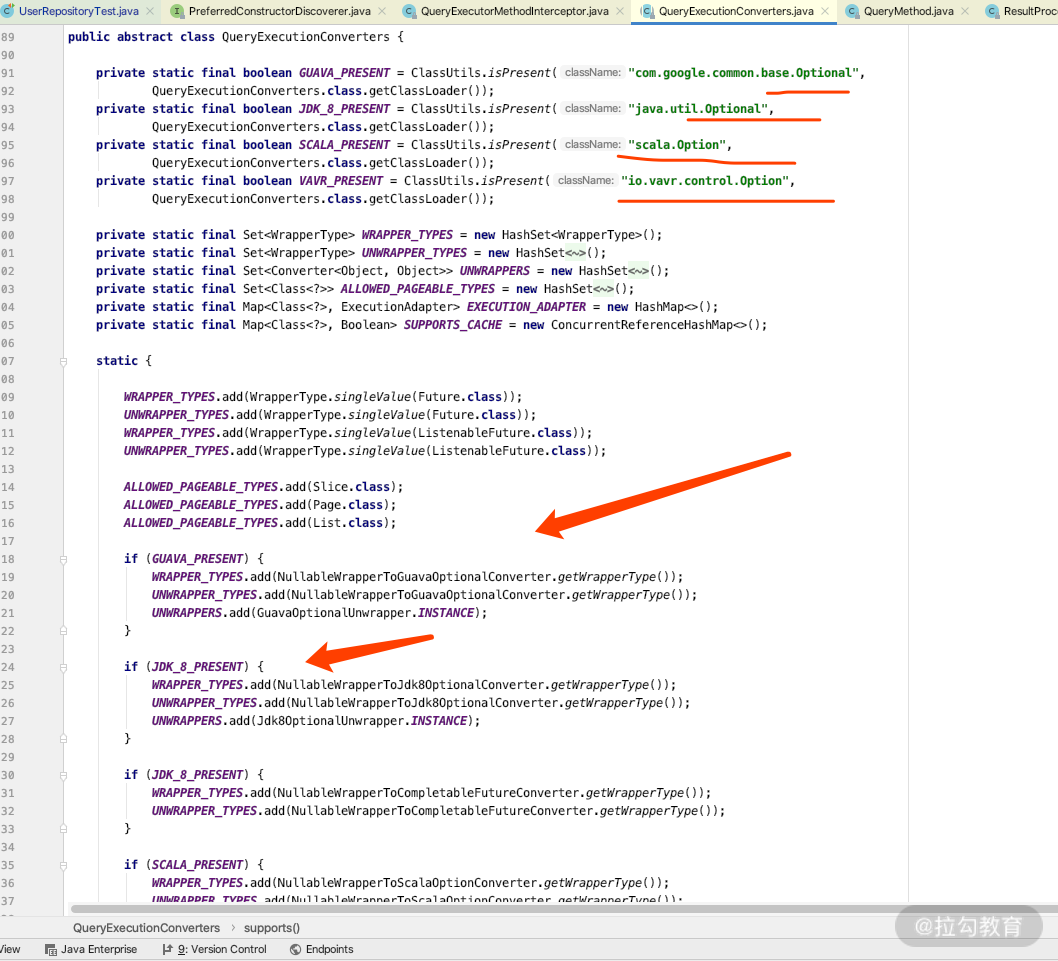
可以看到 QueryExecutorConverters 里面对 JDK8、Guava、vavr 也做了各种支持,如果你有兴趣可以课后去仔细看看源码。
这里我们先用表格总结一下返回值,下表列出了 Spring Data JPA Query Method 机制支持的方法的返回值类型:
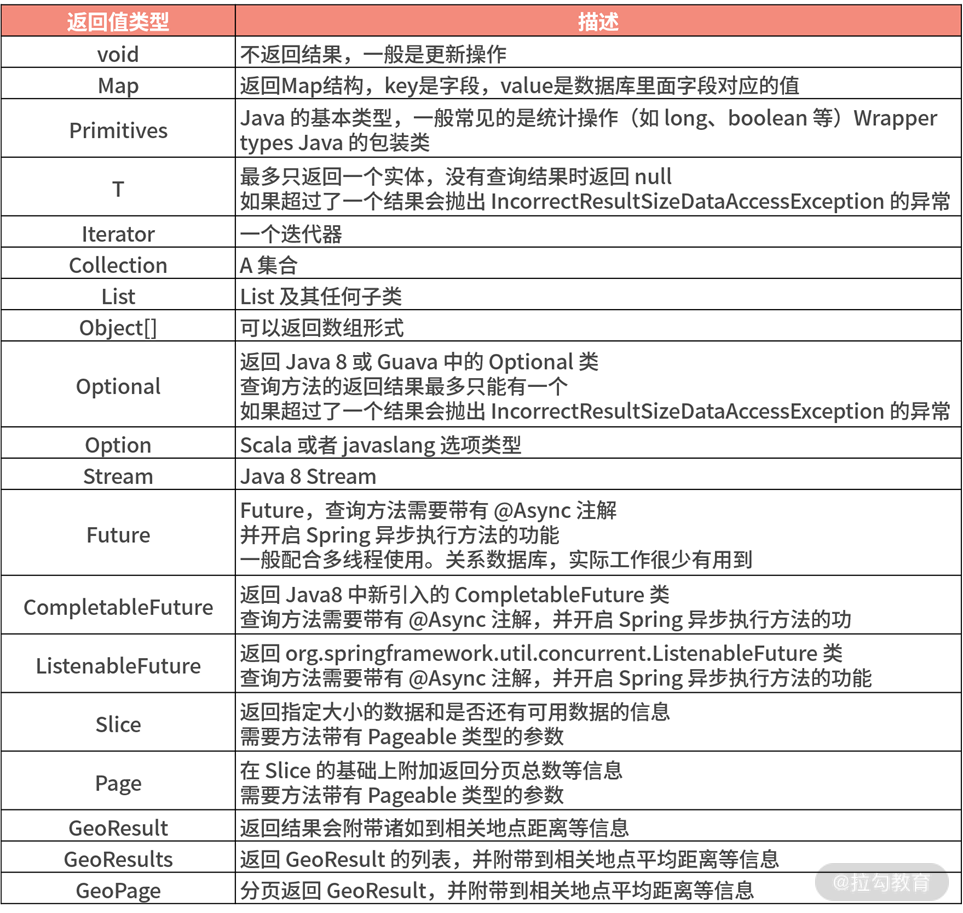
以上是对返回的类型做的总结,接下来进入本课时的第二部分,来看看工作中最常见的、同一个 Entity 的不同字段的返回形式有哪些。
最常见的 DTO 返回结果的支持方法有哪些?
上面我们讲解了 Repository 不同的返回类型,下面我们着重说一下除了 Entity,还能返回哪些 POJO 呢?我们先了解一个概念:Projections。
Projections 的概念
Spring JPA 对 Projections 扩展的支持,我个人觉得这是个非常好的东西,从字面意思上理解就是映射,指的是和 DB 的查询结果的字段映射关系。一般情况下,返回的字段和 DB 的查询结果的字段是一一对应的;但有的时候,需要返回一些指定的字段,或者返回一些复合型的字段,而不需要全部返回。
原来我们的做法是自己写各种 entity 到 view 的各种 convert 的转化逻辑,而 Spring Data 正是考虑到了这一点,允许对专用返回类型进行建模,有选择地返回同一个实体的不同视图对象。
下面还以我们的 User 查询对象为例,看看怎么自定义返回 DTO:
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
private String sex;
private String address;
}
看上面的原始 User 实体代码,如果我们只想返回 User 对象里面的 name 和 email,应该怎么做?下面我们介绍三种方法。
第一种方法:新建一张表的不同 Entity
首先,我们新增一个Entity类:通过 @Table 指向同一张表,这张表和 User 实例里面的表一样都是 user,完整内容如下:
复制代码
@Entity
@Table(name = "user")
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class UserOnlyNameEmailEntity {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
}
然后,新增一个 UserOnlyNameEmailEntityRepository,做单独的查询:
复制代码
package com.example.jpa.example1;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserOnlyNameEmailEntityRepository extends JpaRepository<UserOnlyNameEmailEntity,Long> {
}
最后,我们的测试用例里面的写法如下:
复制代码
@Test
public void testProjections() {
userRepository.save(User.builder().id(1L).name("jack12").email("123456@126.com").sex("man").address("shanghai").build());
List<User> users= userRepository.findAll();
System.out.println(users);
UserOnlyNameEmailEntity uName = userOnlyNameEmailEntityRepository.getOne(1L);
System.out.println(uName);
}
我们看一下输出结果:
复制代码
Hibernate: insert into user (address, email, name, sex, id) values (?, ?, ?, ?, ?)
Hibernate: select user0_.id as id1_0_, user0_.address as address2_0_, user0_.email as email3_0_, user0_.name as name4_0_, user0_.sex as sex5_0_ from user user0_
[User(id=1, name=jack12, email=123456@126.com, sex=man, address=shanghai)]
Hibernate: select useronlyna0_.id as id1_0_0_, useronlyna0_.email as email3_0_0_, useronlyna0_.name as name4_0_0_ from user useronlyna0_ where useronlyna0_.id=?
UserOnlyNameEmailEntity(id=1, name=jack12, email=123456@126.com)
上述结果可以看到,当在 user 表里面插入了一条数据,而 userRepository 和 userOnlyNameEmailEntityRepository 查询的都是同一张表 user,这种方式的好处是简单、方便,很容易可以想到;缺点就是通过两个实体都可以进行 update 操作,如果同一个项目里面这种实体比较多,到时候就容易不知道是谁更新的,从而导致出 bug 不好查询,实体职责划分不明确。我们来看第二种返回 DTO 的做法。
第二种方法:直接定义一个 UserOnlyNameEmailDto
首先,我们新建一个 DTO 类来返回我们想要的字段,它是 UserOnlyNameEmailDto,用来接收 name、email 两个字段的值,具体如下:
复制代码
@Data
@Builder
@AllArgsConstructor
public class UserOnlyNameEmailDto {
private String name,email;
}
其次,在 UserRepository 里面做如下用法:
复制代码
public interface UserRepository extends JpaRepository<User,Long> {
//测试只返回name和email的DTO
UserOnlyNameEmailDto findByEmail(String email);
}
然后,测试用例里面写法如下:
复制代码
@Test
public void testProjections() {
userRepository.save(User.builder().id(1L).name("jack12").email("123456@126.com").sex("man").address("shanghai").build());
UserOnlyNameEmailDto userOnlyNameEmailDto = userRepository.findByEmail("123456@126.com");
System.out.println(userOnlyNameEmailDto);
}
最后,输出结果如下:
复制代码
Hibernate: select user0_.name as col_0_0_, user0_.email as col_1_0_ from user user0_ where user0_.email=?
UserOnlyNameEmailDto(name=jack12, email=123456@126.com)
这里需要注意的是,如果我们去看源码的话,看关键的 PreferredConstructorDiscoverer 类时会发现,UserDTO 里面只能有一个全参数构造方法,如下所示:
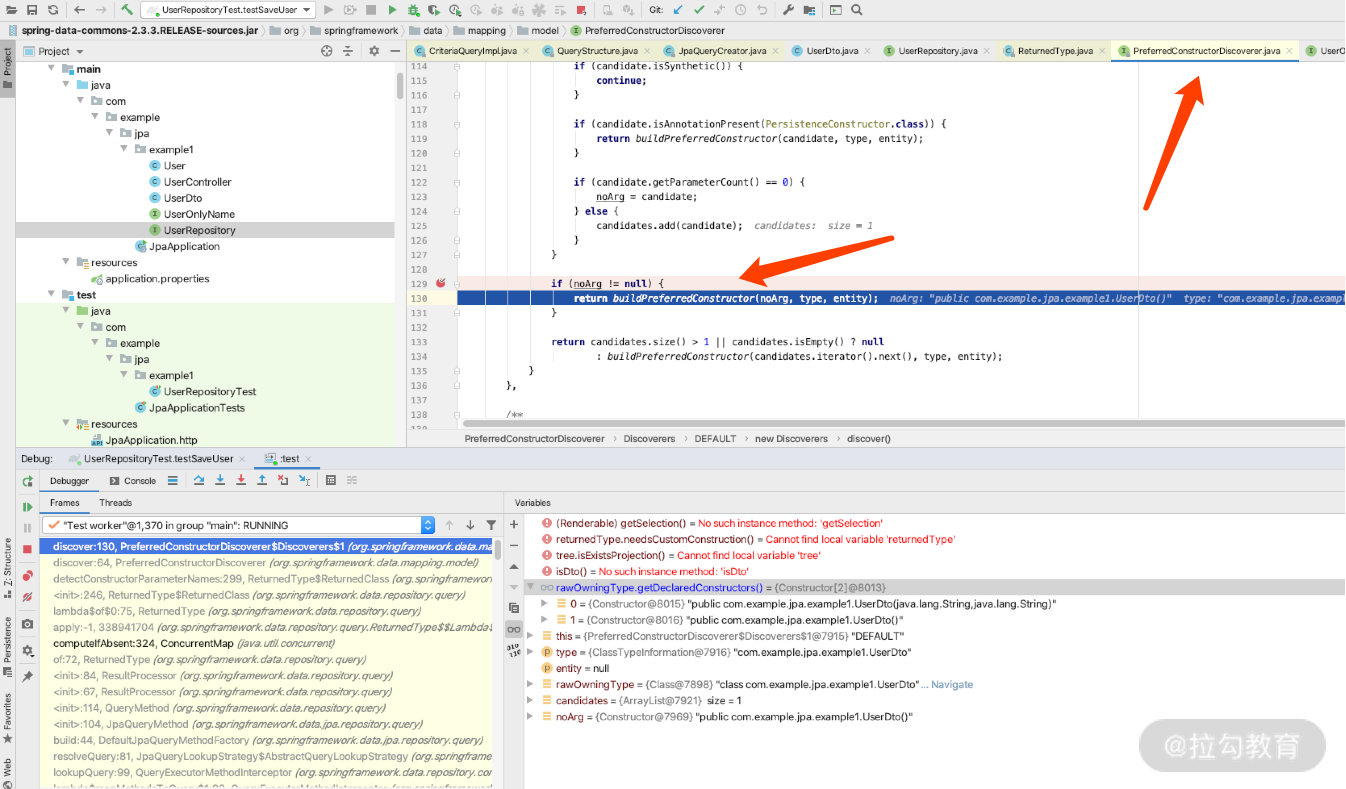
如上图所示,Constructor 选择的时候会帮我们做构造参数的选择,如果 DTO 里面有多个构造方法,就会报转化错误的异常,这一点需要注意,异常是这样的:
复制代码
No converter found capable of converting from type [com.example.jpa.example1.User] to type [com.example.jpa.example1.UserOnlyNameEmailDto
所以这种方式的优点就是返回的结果不需要是个实体对象,对 DB 不能进行除了查询之外的任何操作;缺点就是有 set 方法还可以改变里面的值,构造方法不能更改,必须全参数,这样如果是不熟悉 JPA 的新人操作的时候很容易引发 Bug。
第三种方法:返回结果是一个 POJO 的接口
我们再来学习一种返回不同字段的方式,这种方式与上面两种的区别是只需要定义接口,它的好处是只读,不需要添加构造方法,我们使用起来非常灵活,一般很难产生 Bug,那么它怎么实现呢?
首先,定义一个 UserOnlyName 的接口:
复制代码
package com.example.jpa.example1;
public interface UserOnlyName {
String getName();
String getEmail();
}
其次,我们的 UserRepository 写法如下:
复制代码
package com.example.jpa.example1;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User,Long> {
/**
* 接口的方式返回DTO
* @param address
* @return
*/
UserOnlyName findByAddress(String address);
}
然后,测试用例的写法如下:
复制代码
@Test
public void testProjections() {
userRepository.save(User.builder().name("jack12").email("123456@126.com").sex("man").address("shanghai").build());
UserOnlyName userOnlyName = userRepository.findByAddress("shanghai");
System.out.println(userOnlyName);
}
最后,我们的运行结果如下:
复制代码
Hibernate: select user0_.name as col_0_0_, user0_.email as col_1_0_ from user user0_ where user0_.address=?
org.springframework.data.jpa.repository.query.AbstractJpaQuery$TupleConverter$TupleBackedMap@1d369521
这个时候会发现我们的 userOnlyName 接口成了一个代理对象,里面通过 Map 的格式包含了我们的要返回字段的值(如:name、email),我们用的时候直接调用接口里面的方法即可,如 userOnlyName.getName() 即可;这种方式的优点是接口为只读,并且语义更清晰,所以这种是我比较推荐的做法。
其中源码是如何实现的,我来说一个类,你可以通过 debug,看一下最终 DTO 和接口转化执行的 query 有什么不同,看下图中老师 debug 显示的 Query 语句的位置:
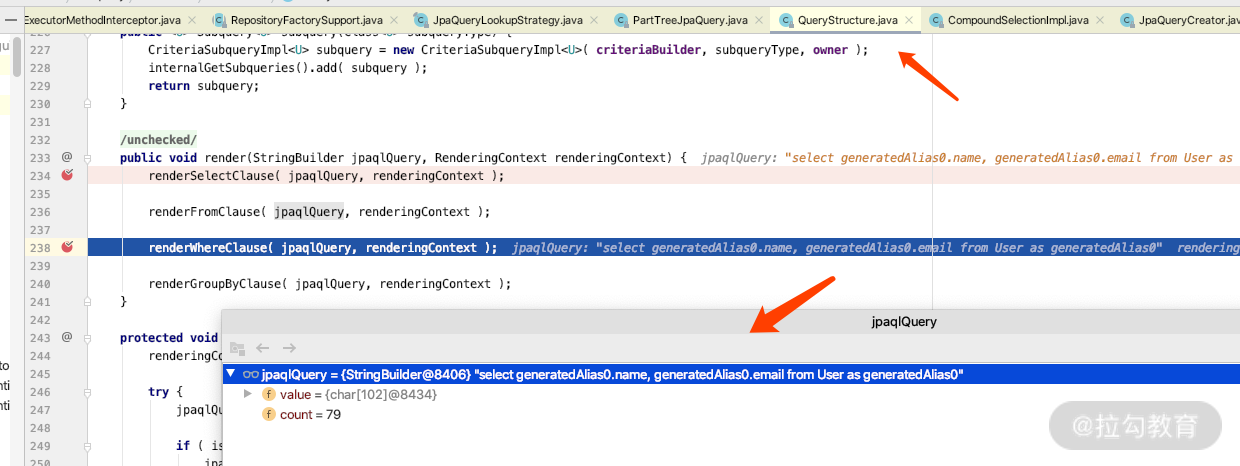
图一:是返回 DTO 接口形式的 query 生成的 JPQL。
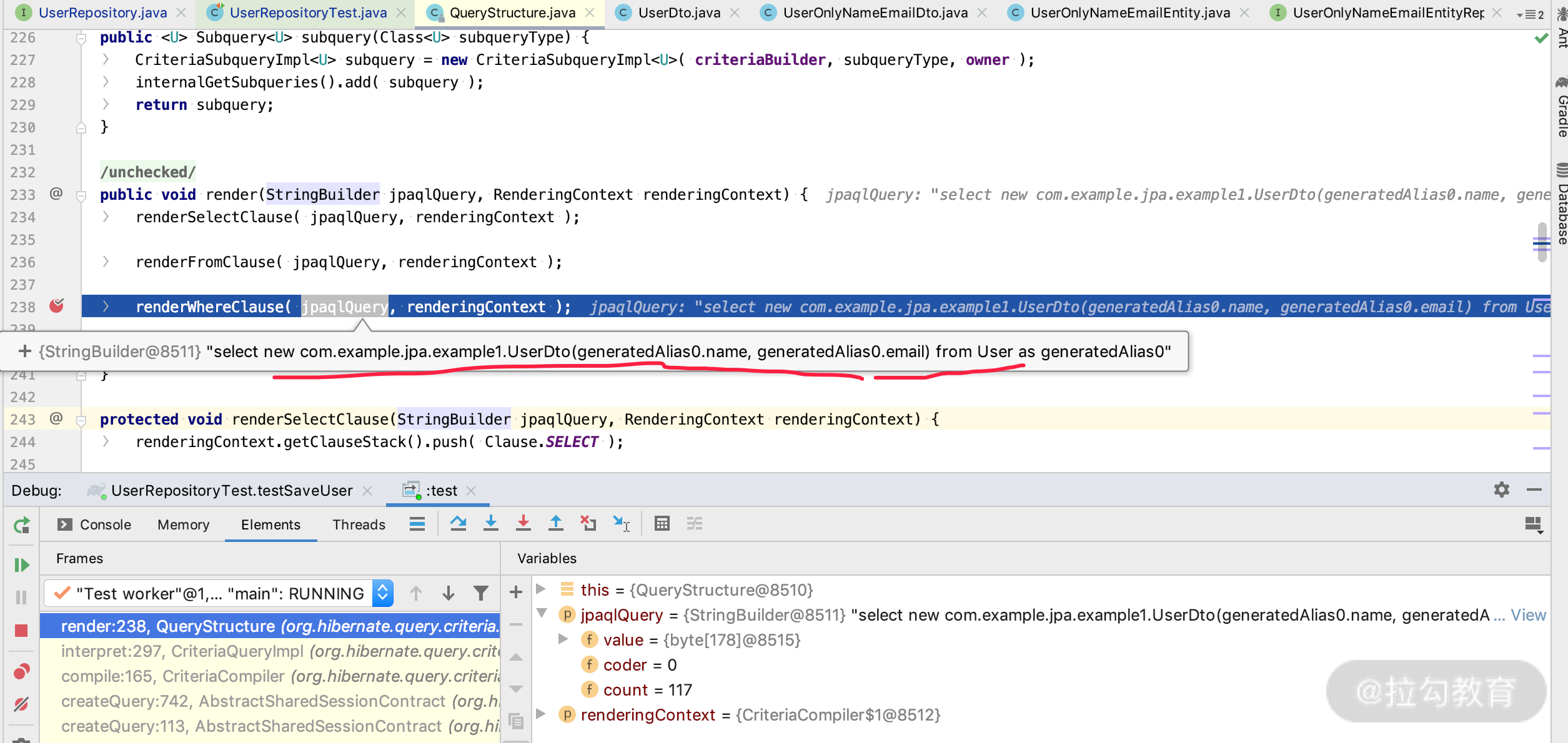
图二:是返回 DTO 类的时候 QueryStructure 生成的 JPQL 语句。
两种最大的区别是 DTO 类需要构造方法 new 一个对象出来,这就是我们第二种方法里面需要注意的 DTO 构造函数的问题;而通过图一我们可以看到接口直接通过 as 别名,映射成 hashmap 即可,非常灵活。这里我顺带给你提一个 tips。
这里说一个小技巧
当我们去写userRepositor 的定义方法的时候,IDA 会为我们提供满足 JPA 语法的提示,这也是用 Spring Data JPA 的好处之一,因为这些一旦约定死了(这里是指遵守 JPA 协议),周边的工具会越来越成熟,其中 MyBatis 太灵活了,就会导致周边的工具没办法跟上。创建 defining query method 的时候就会提示,如下图所示:
以上就是返回 DTO 的几种常见的方法了,你在实际应用时,要不断 debug 和仔细体会。当然除了这些外,还有 @Query 注解也是可以做到,下一节会有介绍。