Index
- 索引相关概念
- 数据结构
- B+树
- 优点及用处
- 优点
- 用处
- 分类
- 技术名词
- 回表
- 覆盖索引
- 最左匹配
- 索引下推
- 索引的匹配方式
- 哈希索引
- 特点
- 代价
- 案例
- 组合索引
- 案例
- 聚簇索引与非聚簇索引
- 聚簇索引
- 非聚簇索引
- 覆盖索引
- 基本介绍
- 优点
- 判断
- 参考
索引相关概念
数据结构
B+树
推荐一篇讲的很不错的文章(为什么MySQL数据库索引选择使用B+树?)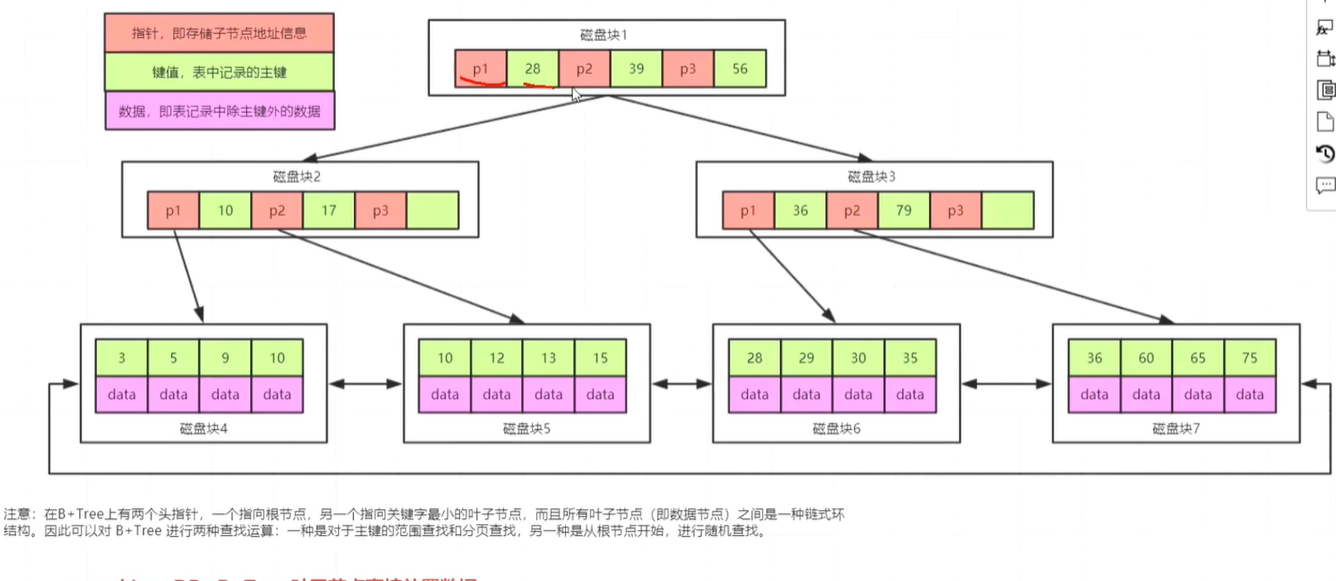
1. 无论是二叉树还是红黑树,都会因为树的深度过深导致IO次数变多,影响数据读取效率
2. InnoDB是通过B+Tree结构对主键创建索引,然后叶子节点当中存储数据,如果没有主键,那么会选择唯一键,如果没有唯一键,那么会生成一个6位数的row_id来作为主键
3. 如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后再通过主键索引找到对应的记录,叫做回表
优点及用处
优点
1.达到减少服务器所需要扫描的数据量
2.帮助服务器避免排序和临时表
3.将随机io变成顺序io
用处
1.快速查找匹配where子句的行
2.从consideration中消除行。如果可以再多个索引当中选择,Mysql一半会使用找到最少行的索引
3.如果具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
4.当有表连接的时候,从其他表检索数据
5.查找特定索引的max或者min值
6.如果排序或分组时在可用索引的最左前缀上完成,则对表进行排序和分组
7.在某些情况下,可以优化查询以检索值而无需查找数据行
分类
1.主键索引(PRIMARY KEY)
主键索引是一种特殊的唯一索引,不允许有空值。一般是在建表的时候指定了主键,就会创建主键索引,CREATE INDEX不能用来创建主键索引,使用Alert table来代替
2.唯一索引
数据库会为我们自动创建索引,创建的就是唯一索引
与普通索引类似,不同的就是,索引的列值必须唯一,但允许有空置。如果是组合索引,则列值的组合必须唯一。
3.普通索引
最基本的索引,没有任何限制
4.全文索引
全文索引用于全文搜索。只有InnoDB和 MyISAM存储引擎支持 FULLTEXT索引,仅适用于 CHAR, VARCHAR和 TEXT列。
5.组合索引
一个索引包含多个列
技术名词
回表
同B+树第三点( 如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后再通过主键索引找到对应的记录,叫做回表)
通俗点讲就是 select 当中有大量的非索引列,查到之后去表中查询相应列信息。
覆盖索引
与回表相对应,只需要在一棵索引树上就能获取SQL 所需的所有列信息,无需回表,速度更快。
explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
最左匹配
在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配
参考下文的组合索引案例
建立索引 a,b,c
语句 索引是否有用
where a =1 有,只使用了a
where a = 1 and b =1 有,用了a,b
where a = 1 and b =1 and c =2 有,用了a,b
where b =2 or c = 4 否
where a=1 and c =2 是,只是有了a
where a =3 and b > 10 and c = 7 是,只是有了a,b
where a = 3 and b like "%5%" and c = 7 是,只用到了a
索引下推
索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询。
举个例子,现在有 索引 a_b_c
5.6之前
where a like 'a%' and b =1 and c =2
根据最左匹配原则,会从索引匹配到a,然后回表查询,再对b 和 c进行过滤,回表比较多
5.6之后
会在索引内部就判断好b = 1 and c=2 然后再次回表查询,回表就比较少
前文MySql性能优化(三)执行计划详解 最后的 extra当中:
Using index condition:在5.6版本后加入的新特性(Index Condition Pushdown); Using index condition 会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行; using index condition = using index + 回表 + where 过滤
表示已经使用了索引下推
索引的匹配方式
全值匹配
索引值和所有的列进行匹配
匹配最左前缀
参照上文最左匹配

匹配列前缀
可以匹配一个列开头部分
比如说截取多长的字段当作索引
匹配范围值
可以查找某个范围的值
精确匹配某一列并范围匹配另一列
只访问索引的查询
哈希索引
特点
- 基于哈希表的实现,只有精确匹配索引列所有值的查询才有效(范围查询不可用)
- 在mysql当中,只有memory的存储引擎支持哈希索引
- 哈希索引存储对应hash值,所以索引十分紧凑,这让hash索引速度十分快
代价
- 哈希索引只包含哈希值和行指针,而不存储字段值,索引不能使用索引中的值来避免读取行
- 哈希索引数据并不是按照索引值顺序存储的,所以无法进行排序
- 哈希索引不支持部分匹配查找,哈希索引是使用索引列的全部内容来计算哈希值
- 哈希索引支持等值比较查询,不支持任何范围查询
- 访问哈希索引的数据非常快,除非有很多哈希冲突,当出现哈希冲突时,存储引擎必须遍历链表中的所有行指针,逐行进行比较,直到查找到所有符合条件的行
- 哈希冲突比较高的时候,维护代价也会很高
案例
当需要存储大量的URL,并且根据url进行搜索查找的时候,如果使用B+树,存储内容就会很大。
select id from url_table where url = “”
这时候可以将url使用CRC32做哈希,可以使用以下查询方式
select id from url_table where url = “” and url_crc=CRC32(“”)
此查询效率较高,因为使用体积很小的索引来完成查找
组合索引
当包含多个列为索引,需要注意正确的顺序依赖于该索引的查询,同时需要考虑如何更好的满足排序和分组的需要
案例
建立索引 a,b,c
语句 索引是否有用
where a =1 有,只使用了a
where a = 1 and b =1 有,用了a,b
where a = 1 and b =1 and c =2 有,用了a,b
where b =2 or c = 4 否
where a=1 and c =2 是,只是有了a
where a =3 and b > 10 and c = 7 是,只是有了a,b
where a = 3 and b like "%5%" and c = 7 是,只用到了a
聚簇索引与非聚簇索引
聚簇索引
索引和数据文件存放在一起
优点
- 可以把相关数据保存在一起
- 数据访问更快,因为索引和数据保存在一个树当中
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值
缺点
- 聚簇数据最大限度的提高了IO密集型应用的性能,如果数据全部放在内存,那聚簇索引没啥优势
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式
- 更新聚簇索引列的代价很高,因为会强制将每个被更新的行移动到新的位置
- 基于聚簇索引的表在插入新行,或者主键被更新需要移动行的时候,可能面临页分裂的问题
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致存储数据不连续的时候
非聚簇索引
索引和数据文件分开存放
覆盖索引
基本介绍
- 如果一个列包含所有需要查询的字段的值,我们称之为覆盖索引
- 不是所有类型的索引都可以称为覆盖索引。覆盖索引必须要存储索引列的值
- 不同的存储实现覆盖索引的方式不同,不是所有的引擎都支持覆盖索引,memory不支持覆盖索引
优点
- 索引条目往往小于数据行代销,如果只需要读取索引,那么mysql就会极大的减少数据访问量
- 因为索引是按照列值顺序存储的,所以对于IO密集型的范围查询回避随机从磁盘读取每一行数据的IO要少的多
- 一些存储引擎如MYISAM在内存中只要缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用,这可能会导致严重的性能问题
- 由于INNODB的聚簇索引,覆盖索引对INNODB表特别有用
判断
当发起一个被索引覆盖的查询时,在explain的extra列可以看到using index的信息,此时就使用了覆盖索引
参考
MySQL索引底层:B+树详解
MySQL索引为什么要用B+树实现
索引下推
MYSQL 官方文档






![[一个无框架的javaweb demo]番荒之冢 --番剧灯塔站](https://img-blog.csdnimg.cn/img_convert/b473df07a5caa7df7fc5098d8037dbc6.png)