目录
摘要:
1.导言
2.文献综述
3 数据集
4.特征集
4.1 CAP_UNI Botometer分数
4.2.与帐户配置文件/时间线相关的功能
4.3.非官方Twitter账户发送的推文比例
4.4.实验装置
5. 实验结果
5.1. Celebrity-Botwiki
5.2. Verified-Botwiki
5.3. Verified-Vendor
5.4. Stock
5.5. Rtbust
6.讨论
6.1 Twitter API和Botometer速率限制,简而言之
6.2.通过CAP*作为Botometer的输出或作为学习模型的输入进行分类
6.3.主要发现
6.4.考虑到少于400条推文的时间表
6.5. 特征分析
7.结论
论文链接:链接: https://pan.baidu.com/s/1VQl-Q18KTi4UfeFHvkXDFw 提取码: l2dc
摘要:
十多年来,院士和在线平台管理员一直在研究解决bot检测问题的方法。
机器人是计算机算法,其使用远非良性: 故意创建恶意机器人是为了散布垃圾邮件,赞助公共角色,并最终在公众舆论中引起偏见。
为了对抗机器人入侵我们的在线生态系统,已经实施了几种方法,主要是基于 (监督和无监督) 分类器,这些分类器采用了最多样化的账户功能,从最简单到最昂贵的账户功能,从可通过Twitter公共api获得的原始数据中提取。
在这项探索性研究中,使用Twitter作为基准,我们比较了四个最先进的功能集在检测新颖机器人方面的性能:
流行的bot检测器botmeter的输出分数之一,它考虑了帐户的1,000多种功能来做出决定;
基于帐户配置文件和时间轴的两个功能集;
以及有关用户推文的Twitter客户端的信息。
我们对最近发布的六个Twitter帐户数据集进行的分析结果暗示了可能使用通用分类器和便宜的计算帐户功能来检测进化的机器人。
1.导言
在一项关于社交媒体操纵的开创性研究中,它表明,在2010马萨诸塞州大选前夕,少数自动Twitter帐户散布了有关民主党候选人的错误信息 (Mustafaraj & Metaxas,2010)。尽管Twitter迅速禁止了这些帐户,但破坏性信息已经传播到平台之外。机器人设法创建了病毒级联,甚至Google搜索结果也报告了虚假消息。尽管机器人检测,搜索引擎过滤和排名技术有所进步,但自动帐户仍然是社会和政治辩论的威胁。
机器人在每一个重大事件中都发挥了重要作用: 从选举 (例如,参见2016和2020美国选举夏尔马、费拉拉和刘、2020和英国退欧公投) 到关于移民和流行病等热门话题的宣传和错误信息的传播 (Caldarelli、De Nicola、Del Vigna,petrocchi,& Saracco,2019; Caldarelli,De Nicola,Petrocchi,Pratelli,& Saracco,2021)。不幸的是,在过去的十年里,机器人的技能有了显著的提高 (Cresci,Di Pietro,Petrocchi,Spognardi,& Tesconi,2017; Ferrara,Varol,Davis,Menczer,& Flammini,2016),因为假账户能够创建一个朋友网络,与真正的帐户聊天而不背叛其性质,并以协调的方式行事。
他们的行为不再是个人的: 同步和协调是机器人团队的特征,如果单独考虑,则最先进的分类器很难检测到这些机器人。引用该领域的先驱的话,“即使10年后,也不乏研究挑战,以尝试识别这种操作” (Sonic research Group,2020)。
动机:多年来,机器人经历了演变:从相当简单的账户到复杂的账户,它们的行为和在线互动几乎与真实账户的行为和在线互动几乎没有区别(Cresi等人,2017;Ferrara等人,2016)。本文源于作者在阅读2019年一篇关于2016年美国总统选举期间网络操纵的论文时产生的好奇心(Bovet&Makse,2019年)。具体地说,为了估计有多少机器人参与了Twitter上的在线政治讨论,文章建议检查发布推文的Twitter客户端(直观地说,专业人士使用非官方客户端来自动执行一些任务)。
对这种简单的方法很感兴趣,我们想知道几年前用来检测早期机器人的功能和方法在多大程度上仍然有效,如果是的话,它们在多大程度上可以用于检测新的机器人。
研究目标: 因此,面临的挑战是开发通用的机器人检测系统,即使该系统不针对检测特定的虚假信息和垃圾邮件促销,仍然能够在检测多种类型的机器人帐户 (包括属于战略活动的帐户) 方面提供良好的性能。& Menc,2020b)。因此,我们研究的主要目的是对通用bot检测器的功效 (就性能而言) 进行探索性研究,也适用于以协调方式运行的bot。我们将使用Twitter作为基准。
方法: 为了实现这一目标,我们考虑了众所周知的学习算法,以了解不同的特征集在应用于最近发布的Twitter帐户数据集时是如何有效的,其中先验地知道帐户的性质 (机器人或真正账户)。
作为第一个特征,我们考虑由Botometer (Varol,Ferrara,Davis,Menczer,& Flammini,2017; Yang,Varol,Davis,Ferrara,Flammini,& Menczer,2020a) 提供的分数之一,印第安纳大学开发的流行机器人检测器。此工具检查Twitter帐户的1000多个功能 (例如,与网络、时间线和帐户配置文件相关的属性),并返回一组分数作为输出,该分数指示帐户的 “boticity” 级别;
第二个特征集可从帐户的配置文件中检索;
第三个特征集仅依赖于与帐户时间线相关的功能;
这两组都忽略了已知计算成本最高的功能 (主要是数据收集所需的时间),即与帐户关系 (朋友和关注者) 有关的功能;
第四个特征是用于推文的Twitter客户端。Bovet & Makse在Bovet和Makse (2019) 中利用它来分析与美国2016总统选举有关的推文数据集,并过滤机器人发布的推文。
贡献: 本手稿的主要贡献是对经过不同特征训练的成熟学习算法的性能进行了调查,该算法在六个最近发布的机器人和人工账户数据集上进行了研究,其组成是先验的。本分析的主要结论如下:
对于某些训练集,对Twitter客户端的检查足以区分bot帐户和真实帐户。然而,我们不得不说,我们一直在考虑非常容易识别的机器人: 它们是自声明的机器人,其性质是他们的程序员无意隐藏;
考虑到基于账户的配置文件和时间线的功能,它们对于单独行动的机器人和团队行动的机器人都工作得很好。这很令人惊讶。这并不是第一次证明所谓的“低成本”特征能够很好地用于机器人检测(例如,参见Cresi等人的工作)。关于虚假追随者的检测,Cresi,Di Pietro, Petrocchi,Spognardi和Tesconi,2015年,重点是机器人只在孤立的情况下行动)。
我们测试最新的、新奇的机器人。在分类阶段获得的良好性能表明,通过利用已经在较少进化版本上测试过的众所周知的特征来抵消机器人的进化是可能的;
总体而言,评估结果让我们认为,并非专门为识别特定类型的账户而创建的通用BOT检测器可以用于浏览异常账户,随后可以应用特定技术来发现这些账户之间的协调行为。
路线图:本文的其余部分组织如下。第二节讨论了近期的相关工作,将我们的研究定位在相关的最新论文中。在第3节中,我们介绍用于分析的数据集。第4节介绍了功能集和实验设置。第五节给出了实验结果。在第六节中,我们讨论了我们调查的主要发现和局限性。最后,第七节得出结论。
2.文献综述
这篇文献综述首先强调了多年来机器人检测的不同趋势。然后,考察了近期的研究成果,并与我们的研究成果进行了比较。
介绍三个研究阶段:
我们想通过将它们与那不勒斯哲学家詹巴蒂斯塔·维科(GiamBattista Vico)创造的历史周期进行比较来强调这些趋势,后者生活在17世纪和18世纪之交。他发展了一套独特的人类历史理论。他确信,历史的特征是三个不同周期的连续和不间断的重复(维柯,1744年):(1)神的时代,人类相信他们生活在神的统治下;(2)英雄的时代,在这个时代,他们形成了贵族共和国;(3)人类的时代,当所有人最终承认自己是平等的,因为他们都属于人类。当我们谈论机器人检测时,我们谈论的是在过去10-11年中进行的研究(事实上,第一项工作出现在Mustafaraj&Metaxas,2010年左右;Yardi,Romero,Schoenebeck和Danah Boyd,2010年)。我们当然不是在谈论几个世纪,就像维科的周期一样。但是,令人惊讶的是,该理论似乎如何适用于机器人检测领域,至少就三个不同阶段的存在而言是如此。
第一阶段:事实上,在机器人狩猎的头几年(2010-2013/14),研究人员主要关注有监督的机器学习和对单一账户的分析:“分类器被分别应用于组中的每个账户”,他们为这些账户分配了一个机器人或非机器人标签(Cresi,2020)。这第一个时期可以被看作是维科的神的时代,在这个时期,‘deus ex machina’出现了,并解决了全新的研究问题。
第二阶段:相反,大约在过去五年,比如到2019年,一些研究团队独立提出了新的方法,旨在检测自动恶意账户组的协调和同步行为,例如,参见Cresi,Di Pietro,Petrocchi,Spognardi和Tesconi(2016),Viswanath等人。(2015)和于、何、刘(2015)。因此,研究人员不再将个人账户归类为BOT或非BOT。相反,他们考虑了一组账户及其共同特征,即那些可能表明其中一些账户是为相同目的而编程的账户(因此,例如,它们在网上的行为方式是相同的)。建议的技术之一是测量账户在其在线活动中留下的痕迹的相似性(Cresi,Di Pietro,Petrocchi,Spognardi,&Tesconi,2018):通过组成账户的数字DNA(即,编码账户操作的字符串),可以利用字符串挖掘工具,从人群中提取行为相同的账户。这第二个阶段可以被视为维科时代的英雄,他们开辟了新的道路来探测机器人团队。
第三阶段:令人惊讶的是,2019年后,我们见证了这两个研究方向的融合:获得所谓的通用分类器,即不特定于机器人类型的分类器,但也能够识别属于团队的机器人,而这些团队以前只能作为团队的一部分而不是作为个人来检测。这第三个时期可以被视为人类的维科时代,研究人员在这一时期进行了各种努力。在下文中,我们将描述通用BOT检测器的最新贡献,同时强调与我们的不同和相似之处。
最近的工作和我们的工作:
Sayyadiharikandeh,Varol,Yang,Flammini和Menczer(2020)最近的工作始于观察到不同的BOT类具有不同的信息特征集,因此,作者为不同的BOT类构建了专门的监督模型。专门的模型被聚合到一个整体中,它们的输出通过投票方案组合在一起。我们的工作并没有像Sayyadiharikandeh(2020)等人那样提出一种新的机器人检测方法。相反,我们采用了过去文献中已经使用的一般技术和功能。然而,我们看到了相似之处,因为两者都倾向于测试分类器是否可以识别不止一种机器人。在测试的数据集上,性能结果是可比的,因此令人鼓舞。
以测试传统检测器在不同类型的机器人上的通用性为目标,Yang等人进行了研究(2020b)提出一个高度可扩展的框架,使他们能够实时处理Twitter上的全部公共推文。分析的关键秘诀是使用账户功能,就计算它们所需的数据而言,这些功能的成本非常低。特别是,作者只使用与帐户配置文件相关的功能。这篇手稿的第二作者在2015年,也就是杨等人发表之前的5年,使用这种类型的特征来检测虚假的Twitter追随者(Cresi等人,2015)。(2020b)。这使我们相信,为了同样的目的,采用“旧的”特征进行机器人检测在今天是值得研究的。在考虑与时间线相关的账户特征时,验证Yang等人 (2020b) 执行实时分析的方法的可持续性将是有趣的。在本手稿中,我们考虑例如帐户推文中的提及,主题标签和url。
Schuchard and Crooks (2021)考虑了与2018美国中期选举相关的大量Twitter帖子。他们不考虑同一训练集上的不同特征集,而是运行三种最先进的模型,即在Varol等人 (2017),DeBot (Chavoshi,hamoni和Mueen,2016) 和Bot-hunter (Beskow等人,2018) 来测试他们的协议。在负责超过4000万条推文的数量的帐户中,大约254K个帐户被识别为机器人 (如果至少一个检测器将其分类为机器人,则将机器人识别为机器人)。分类器的一致性很差,事实上,在上述254k个账户中,令人难以置信的是,只有8个被所有3种检测方法标记为机器人。后者在根据机器人与人类帐户的交互程度对机器人进行分类方面也有所不同。这导致Schuchard和Crooks (2021) 的作者推荐了一种混合的检测方法,适用于在野外狩猎机器人。
Ferrara (2017) 探索了文献中考虑的最重要的功能,以检测机器人帐户,从而依靠用户个人资料,帐户的地理定位及其活动 (如推文的数量和频率,以及推文和转发之间的比率),创建一个简单但有效的,通过使用Scikit- learn中可用的各种算法 (Pedregosa等人,2011) 的bot检测系统。我们看到了与Ferrara (2017) 和我们的工作的相似之处,因为他们都在分类过程中考虑了相对容易计算的功能,就数据收集所需的时间而言。因此,在我们的数据集上评估Ferrara (2017) 中的特征将是有趣的,这些特征是最近的。
El-Mawass,Honeine和Vercout(2020)提出了一种混合方法来降低传统监督系统中的错误正确率,从而在不降低准确率的情况下提高召回率。它们依赖于分类器的级联,并使用监督分类器的输出作为概率图形模型框架中的先验信念。这一框架允许将信念传播到类似的社交账户。分类结果表明,在保持查准率的同时,召回率有了显著的提高。
到目前为止描述的工作是基于单个帐户的分类 (分类器将帐户作为输入,并说它是否是机器人)。在下面,我们想简单地提到的工作,在很大程度上属于第二阶段的机器人检测,在该阶段,一组帐户被分析其 “团队” 特征 (例如,通过比较创建时间的帐户,或通过比较他们的在线行为)。Hui,Yang,Torres-Lugo和Menczer (2020) 提出了BotSlayer,这是一种基于异常检测算法的工具,该算法通过突出显示主题标签,链接,短语和趋势媒体来使协调的活动从人群中出现。例如,其他技术基于同步性和正态性的异常 (Giatsoglou等人,2015; Jiang,Cui和Faloutsos,2016),检测松散同步的动作 (Cao,Yang,Yu和Palow,2014),声誉得分分布之间的距离 (Viswanath等人,2015),以及动作序列之间的相似性 (Cresci等人,2018)。
最后,Sharma等人在Sharma等人 (2020) 中放弃了基于有关此类帐户之间的协调和同步行为的特征来检测机器人团队的研究趋势,并提出了一种从帐户活动和帐户之间的交互中自动发现协调小组行为的方法。基于时间点过程。
3 数据集
我们考虑根据帐户创建日期选择的六个公开可用的数据,即我们选择了日期为2018或2019的数据。这样做是为了了解我们的比较分析中使用的方法是否允许检测比几年前创建的机器人更复杂的机器人。数据集如下:
Verified:最早在Yang等人 (2020b) 中引入,由2000个经过验证的人类账户组成。Twitter提供了 (应帐户所有者的要求) 获得帐户真实性的官方证明的可能性。认证帐户被标记为 “已验证”,并且在官方门户网站上有一个蓝色圆圈,中间有一个白色勾号;
Celebrity:首次在Yang等人 (2020a) 中引入,由作为真实用户收集的5970名人帐户组成;
Botwiki:由来自https://botwiki.org的704个公开声明的机器人组成。Botwiki组织的目标是保留 “有趣和创意的在线机器人的示例,为有兴趣制作它们的人们提供教程和其他资源”。Botwiki Twitter帐户是易于识别的机器人,例如,用户名或帐户描述中的单词 'bot'。这些机器人不会隐藏其自动性质或恶意意图。
Rtbust:由Mazza、Cresi、Avvenuti、Quattrociocchi和Tesconi(2019)通过处理2018年6月17日至30日期间由1,446,250名不同用户分享的所有(9,989,819条)意大利转发而构建。在减少了考虑的用户数量后,根据他们的转发率,759个账户被贴上了人类操作或机器人操作的标签。
Stock:Cresci,Lillo,Regoli,Tardelli和Tesconi (2019) 首次推出的股票包括真实和自动帐户,它们在推特上发布所谓的cashtags,即指上市公司的特定Twitter主题标签。已发现部分自动帐户以协调的方式起作用,特别是通过大量转发低资本化公司的现金。
Vendor:在Yang等人 (2020a) 中引入,由1088个假追随者组成,即用来夸大目标账户的追随者数量的假账户;

表1报告了数据集的名称、它们的简要描述以及它们最初具有的帐户数量;
年份代表属于数据集的帐户的创建年份的平均值。
值得注意的是,原始数据集仅包括帐户的id,以及定义其性质的标签。
因此,通过Twitter公共api和Tweepy库 (http://www.tweepy.org/),我们检索了本手稿中显示的实验所需的数据。
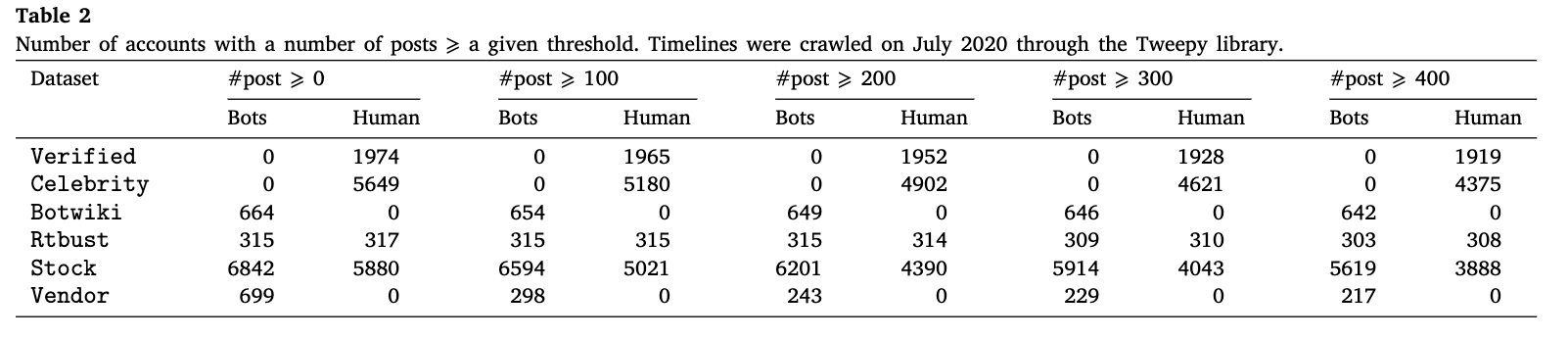
因此,表2报告了当前研究 (2020年7月) 时相同数据集的统计数据。
该表包含在时间表中至少有0条、100条、200条、300条和400条推文的机器人和人类的数量-我们始终考虑帐户发布的最新100、200条、300条和400条推文。
我们可以注意到,通过考虑每个帐户的时间轴中的最小推文数量,每个数据集的帐户数量会发生变化。特别是,通过仅考虑在其时间线中至少具有x个推文的帐户,当x增加时,每个数据集的帐户数量会减少。这一方面对于评估分类器的性能很重要。在讨论部分,为了评估我们结果的稳健性,我们将比较分类性能如何受到我们考虑的推文数量 (以及因此的帐户数量) 的影响。
为了完整起见,我们还强调指出,如果我们专注于考虑至少500条推文,而不是400推文,则取决于数据集,我们会损失2% 和5% 之间的账户数量。损失并不严重,一方面,我们可以分析时间表中有大量推文的账户。另一方面,我们更愿意将最小推文数量固定为400,以保持推文数量和帐户数量之间的良好权衡;
4.特征集
在本节中,我们考虑四个不同的特征集,可以将它们作为学习模型的输入,以检测bot帐户。首先,我们将Botometer Varol等人 (2017) 的得分输出作为特征之一,这是印第安纳大学开发的流行的bot检测工具。然后,我们描述了两个特征集,首先由Cresci等人在Cresci等人 (2015) 中引入,这两个特征集需要用于数据收集的低计算资源。最后,受Bovet和Makse (2019) 的启发,我们考虑了帐户推文最多的Twitter账户 (官方/非官方) 的类型。
4.1 CAP_UNI Botometer分数
Botometer v3 (Yang等人,2020a) 基于使用随机森林分类器的有监督机器学习方法 (Breiman,2001a)。给定一个Twitter帐户,Botometer通过Twitter API提取有关该帐户的1000多种功能,包括情绪,一天中的时间,推文内容和Twitter网络的度量。
Botometer的直接输出是范围为{0,..1} 的bot分数,但是这并不代表所考虑的帐户是bot的概率。该值必须与一组帐户中的其他分数进行比较,才能得出合理的排名。将Botometer的输出解释为bot概率,即回答以下问题: “此帐户是否为bot?',完整的自动化概率已在 (Yang等人,2020a) 中引入: 它表示一个帐户是bot的条件概率,给定其bot分数。这个条件概率是通过应用贝叶斯规则来计算的 : 。在Varol等人 (2017) 中,假设先验概率 (任何随机选择的账户是bot的概率) 为 P(Bot) = 0.15。但是,如果知道样本中机器人的背景水平 (这是我们的情况,因为数据集已标记),则可以使用校正因子进行调整:
其中
是在被调查的域中存在特定数量的机器人的实际概率。我们事先知道我们数据集的性质,因此可以计算
。
有两种类型,即CAP_ENG和CSP_UNI:前者利用与英语推文有关的文本特征,后者仅利用与语言无关的特征。在下面,我们将考虑CAP_UNI的*版本,即使在分析非英语语言的推文时,它也允许获得更可靠的结果。
4.2.与帐户配置文件/时间线相关的功能
在一项关于检测假追随者的先驱研究中 (Cresci et al.,2015),Cresci等人在参考集中测试了Twitter假追随者与基于以下的算法 :
(i) 技术博客作者和社交媒体营销公司提出的分类规则,(Stateofsearch.com: 如何识别Twitterbots: 需要注意的7个信号 (2012年8月) (在线新闻,不再提供); M.Camisani-Calzolari: 对美国总统大选候选人的Twitter追随者的分析: 巴拉克·奥巴马 (Barack Obama) 和米特·罗姆尼 (Mitt Romney) (2012年8月); 状态人物伪造者 (以前将帐户标记为假或真); SocialBakers (社交媒体营销平台,https://www.socialbakers.com/feature/假影响者检测); https:// www.tw itteraudit.co)和
(ii) 文献中提出的用于检测垃圾邮件发送者的特征集。他们根据收集计算所需数据所需的成本对规则和特征进行分类,并展示了性能最佳的特征也是最昂贵的特征。然后,他们使用成本较低的特征实现了一系列轻量级分类器,尽管如此,它们仍然能够正确地分类基线数据集的95% 以上的账户。表3 显示了继承自Cresci等人 (2015) 的特征的列表,其将在下一节中用于测试多个分类器的结果。A类中的特征是只能从帐户配置文件数据中获得的功能,而B类中的功能是可以从帐户的时间表中获得的特征。

4.3.非官方Twitter账户发送的推文比例
在对2016总统选举期间传播假新闻的研究中 (Bovet & Makse,2019),Bovet和Makse建议通过检查其源字段并提取用于发布该推文的Twitter账户的名称来识别由机器人发起的推文。如Bovet和Makse (2019) 的补充表14中列出的,Bovet和Makse仅考虑了那些主要从官方Twitter客户端列表中的客户端发推文的真正用户。不考虑从第三方客户推文的真实帐户的动机是,后者主要由专业人员用于某些自动化任务,例如,请参见www.sprinklr.com 或 dlvrit.com。
同样的作者在Boveet,Morone和Makse(2018)中进一步研究了该方法,并将其分类性能与Botometer Varol等人的分类性能进行了比较。(2017年)。比较的结果表明,他们的建议具有很好的准确性,尽管假阳性的数量比Botometer高。博维和马克塞(2019)和博维等人的作者。(2018)还指出,仅通过查看源代码字段可能无法检测到进化的机器人,但对于依赖已知机器人的训练集的更高级方法来说,这也是一个问题(Varol等人,2017)。
在下文中,受推文来源字段评估的启发,我们将非官方Twitter客户端发布的推文占该帐户全部推文数量的比例作为特征。作为 “全部” 推文,我们考虑帐户时间轴中的最新400推文。
4.4.实验装置
我们结合第3节中描述的数据集来构建五个训练集,以测试四个特征集在区分机器人和真实帐户中的优度: Celebrity-Botwiki; Verified-Botwiki; Verified-Vendor; Stock; Rtbust。有关训练集中的机器人数量和真实帐户的统计数据在表4中。

选择这些组合的基本原理是评估不同的特征集如何能够识别最近的bot帐户,该帐户具有比2010-2017年的bot更高级的特征,既适用于以协调方式行事的类型 (如Stock and Rtburst),也适用于单独行事的类型 (Botwiki and Vendor)。
所有训练集都不考虑那些Botometer v3无法产生有效响应的帐户。因此,我们将仅考虑具有以下帐户的训练集的性能结果 :( i) Botometer v3已返回有效响应,并且 (ii) 在其时间轴中至少有400条推文;
在下文中,我们根据众所周知的标准指标 (例如精度,召回率,马修相关系数 (MCC)) (即预测类与样本真实类之间的相关性的估计器) 来评估五种不同学习算法的性能),以及曲线下面积度量 (AUC),即接收器工作特性 (ROC) 曲线 (Metz,1978) 下的面积。
从训练集的组成 (表4) 可以看出,它们具有不同程度的平衡,从平衡的Rtbust到轻度失衡的Verified-Botwiki和stock(少数群体等于20%-40%),celebrity-Botwiki和Verified-Vendor具有中等程度的不平衡 (少数群体等于整个集合的1%-20%)。
ROC-AUC-对应于接收器操作特性的曲线下的区域-通常被认为是不平衡设置中的无偏度量。
Provost等人提出了roc-auc作为准确性的替代方案 (Weiss & Provost,2003)。此外,作为评估指标,我们还将考虑曲线下的精确召回区域 (pr-auc),在存在中度失衡的情况下,通常被判断为比roc-auc偏倚更少 (Saito & Rehmsmeier,2015)。最后,我们报告平衡精度,定义为 (True Positive rate + True Negative rate)/2。
关于这五种算法,它们各自属于不同的类别: MlP (多层感知) (Pal & Mitra,1992),JRip,即基于Java的算法实现 (Cohen,1995),朴素贝叶斯 (John & Langley,1995),随机森林 (Breiman,2001a) 和Weka (Witten,Frank,& Hall,2011) 实现了基于实例的学习算法,即IBk (Aha,Kibler,& Albert,1991)。对于所有实验,我们都依赖于开源机器学习软件Weka。对于每次评估,我们都会对训练集进行10倍的交叉验证。对于每种算法,我们都使用默认的参数设置,在Weka官方文档中有详细说明。
最后,在介绍我们的分析结果之前,我们想强调一下,尽管我们可以直接使用Botometer CAP * 将帐户分类为bot或非bot,但我们更愿意将CAP * 作为学习模型的特征,就像我们展示的其他功能一样。这使我们能够对结果进行同质的表示。在讨论环节中,我们将展示这两个过程 (直接使用Botometer进行分类/使用学习模型进行分类) 获得相同的性能。
5. 实验结果
在本节中,我们报告我们的实验并评论其主要结果。
5.1. Celebrity-Botwiki
表5显示了相同的学习算法的性能结果,当用Botometer v3 CAP_UNI * 、A类和B类特征以及非官方客户端发布的推文的百分比时,对于由自我声明的机器人和名人帐户组成的训练集。
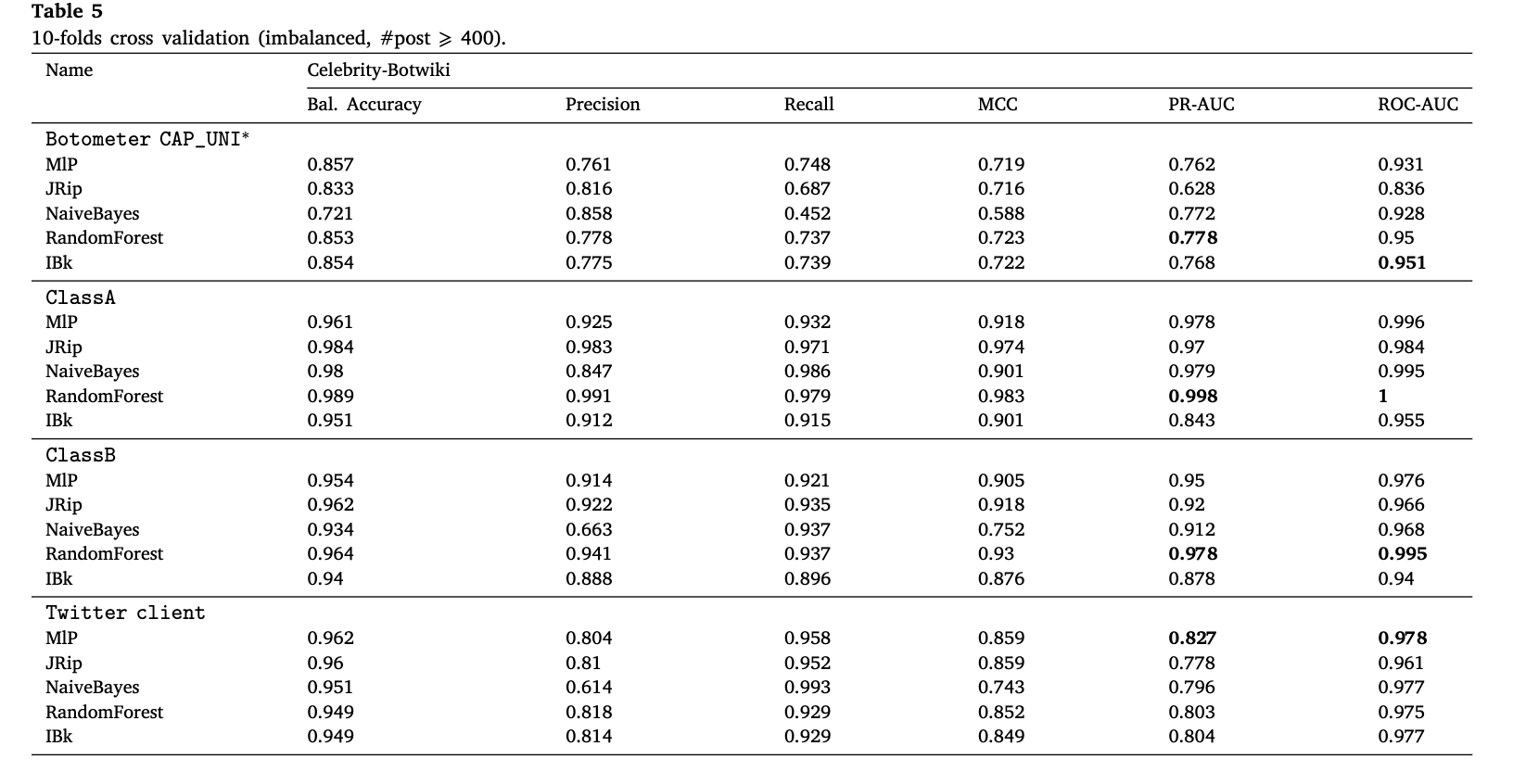
这四种方法在roc-auc方面都取得了很好的效果。可以看出,对于用Botometer v3返回的CAP_UNI * 分数训练的模型,其他指标稍差。确切地说,最糟糕的结果是通过CAP_UNI * 和有关Twitter客户端的功能获得的结果。后者的表现确实并不令人惊讶,因为名人帐户可能由社交媒体经理管理,他们也可能决定自动发布推文。关于CAP_UNI *,对于这个特定的训练集,一些名人被标记为机器人 (精度较低),一些机器人被分类为名人 (召回率较低)。这也导致roc-auc的值略低。作为最偏斜的训练集之一,我们注意到与每个测试的特征集的roc-auc相比,PR-AUC的恶化,但是a类和B类的值仍然大于0.9
5.2. Verified-Botwiki
表6显示,当训练集由Botwiki和经过验证的Twitter帐户组成时,结果与前一个非常相似。

5.3. Verified-Vendor
当我们考虑由经过验证的帐户和假追随者形成的数据集时,各种方法的结果开始明显不同,请参见表7。

Twitter客户端方法在各个方面都失败了。这个训练集是最不平衡的,事实上假追随者只代表整个集的10%。为了限制roc-auc给出的过于乐观的观点,我们可以分析pr-auc值,这些值是从各个精度和召回值得出的。撇开朴素贝叶斯和IBk不谈,对于A类和B类,其结果比CAP * 差得多,对于其他类型的算法,其精度与三组特征相当。Recall获取A类特征和随机森林 (0.729) 的最高值。但是,对于所有特征集,该算法将许多伪造的关注者归类为经过验证的帐户。
我们已经更详细地研究了这一方面: 低召回值实际上可能是由于数据集的强烈不平衡。表8比较了对于每个算法,在不平衡数据集上计算的召回和在大多数类 (验证账户) 已经under-sampled.6的数据集上计算的召回。这样,数据集由40% 个供应商账户和60% 个验证账户组成。平衡数据集中的召回值实际上会增加。即使到目前为止,它们没有达到我们分析过的0.9数据集的峰值,它们仍然在0.6和0.853之间振荡。我们将在讨论部分的第6.3节中回到这方面。
5.4. Stock
现在,我们分析一个由机器人和真实账户组成的数据集,每个账户都在推特上发布金融市场。一些机器人以协调的方式行动。数据集是最近的,这让我们假设我们正在处理一个非常复杂的机器人版本。首先,从表9中,我们可以看到roc-auc和PR-AUC的值是相似的。

实际上,数据集几乎是平衡的,机器人约占数据集中总帐户的60%。同样,分析Twitter客户端不会产生良好的结果 (尽管这种方法比第5.3节中考虑的情况表现更好)。令人惊讶的是,其余三种方法具有相似的结果,并且对于roc-auc,它们通常获得大于0.8的值 (15的11倍)。
A类通常获得精度和召回率的最低值,而B类则给出最佳结果。我们可以推测,这些机器人的性质是推文内容所特有的,这意味着帐户的时间轴功能足以最好地检测这些数据;我们想指出的是,在论文中,这些帐户首先被分析 (Mazza等人,2019),提出的检测技术是一种无监督的技术,检测这些bot帐户作为一个组以协调方式行动。我们的分析表明,即使利用传统的监督分类器,利用在数据收集方面并不昂贵的特征,我们也可以在检测级别获得良好的结果。
5.5. Rtbust
现在,我们分析最后一个数据集的分类结果,该数据集由真实帐户和机器人组成。后者具有协调的行为,其特点是转发一些目标帐户。数据集是完全平衡的 (303-308),所以我们关注roc-auc而不是PR-AUC。结果是,B类再次给出了最佳结果,达到高于0.8的值并在0.877处达到峰值。A类方法会降低性能;0.841是最好的结果,但所有其他值介于0.7和0.8之间。我们认为这是一个令人惊讶的结果,原因如下。首先,与Botometer v3中使用的特征集合相比,B类特征的计算并不繁重 (在我们由CAP_UNI * 总结的实验中)。作者首先发现这类机器人在其最佳参数配置下实现了0.934的精度 (w.r.t.我们的最佳结果 = 0.869),0.814的召回,与我们的0.826召回值相当,和MCC = 0.757 (w.r.t.我们的最佳结果 = 0.658) (Mazza等人,2019)。尽管实现了低于 (Mazza等人,2019) 的性能,但我们在不依赖于旨在检测转发者的专门技术的情况下获得了有希望的结果。同样值得注意的是Mazza等人 (2019) 用不同的参数配置进行了实验,除了它们的0.757值之外,我们在这里获得的MCCs值总是高于在Mazza等人 (2019) 中获得的测试配置。最后但并非最不重要的一点是,我们的方法及其结果使我们与Sayyadiharikandeh等人的最新方法保持一致。(2020),而无需利用Botometer v4的高级版本 (请参阅以下部分中的讨论)
6.讨论
在本节中,我们 (1) 通过对从Twitter收集数据的成本进行分析,突出考虑容易从帐户概况和时间轴获得的特征的动机; (2) 讨论手稿的主要发现;(3) 介绍工作的一些局限性,并通过进一步的实验来检验其鲁棒性。
6.1 Twitter API和Botometer速率限制,简而言之
在本文中,我们对真实帐户和机器人帐户的数据集进行了一些实验,以比较用于检测机器人的已知学习算法的性能,同时考虑了帐户的不同最新特征集。从最简单到最复杂的,账户特征都是从Twitter从apis提供的数据中计算出来的。如Cresci等人最初定义的。在Cresci等人 (2015) 中,这些特征可以根据计算它们所需的API调用的数量来区分,成与帐户配置文件相关的功能 (所谓的A类功能),与时间轴相关的功能 (B类功能) 以及与关系相关的功能 (C类功能)。从帐户配置文件中的数据中提取可以计算的功能以外的功能在所需的API调用数量方面具有更高的成本。
为了检索一个用户发布的最新推文,Twitter提供了同一服务的两个版本,即v1和v2。在撰写本文时,Twitter文档报告说,新的API v2将完全取代v1.1标准,高级和企业API。
与v1相比,用户时间轴API v2限制了每个请求可以获得的推文数量: 后者允许每个请求最多200个推文,而前者允许最多100个推文。此外,请求的最大数量等于每15分钟窗口1500个请求。
同样,要获取帐户的关注者和关注者的id列表,也有新版本的api。关于v1,每个请求的id的数量已经大大减少,从v1中的5000个减少到v2中的1000个。关于速率限制,v2允许每15分钟窗口15个请求。因此,例如,如果我们专注于帐户的关注者,则下载帐户的关注者的整个列表将需要5000个API调用,其中是帐户的关注者的数量。帐户的关注者和关注者的数量不受限制,因此,无法计算最大的API调用数量来抓取必要的信息并计算与帐户关系相关的功能。例如,在撰写本文时,拥有最多关注者的Twitter帐户属于巴拉克·奥巴马 (@ BarackObama),拥有约130万个帐户。要收集有关它们的信息,需要大约130,000个Twitter API调用。
综上所述,使用“低成本”的特征,以减少特征收集的时间显然更有吸引力。因此,手稿的想法是,在更高级的BOT数据集上测试低成本功能的有效性。
诸如Botometer之类的工具可以为用户节省特征提取的过程-将这部分工作留给Botometer本身。在这方面,我们想澄清一下,我们在这里的目标不是评估或质疑像Botometer这样的系统的质量。这种众所周知的机器人检测器现在处于版本4,并且最近表明它在检测单作用机器人和协调活动方面表现良好 (Sayyadiharikandeh等人,2020)。然而,Botometer有一些限制,可以证明考虑机器人检测的替代方法是合理的。在其生命的大部分时间里,Botometer都是一个可公开访问的工具,依靠Twitter API收集有关帐户的最新数据进行调查。如上所述,在这种情况下,Twitter API施加的查询限制导致对大量帐户的分析非常耗时。Botometer v3施加额外的速率限制,而当前版本v4提供免费版本和高级版本。高级版本 (50美元/月) 允许每天17,280个请求的速率限制 (每个请求仅处理1个用户)。此外,v4 premium提供了精简版BotometerLite,它不与Twitter交互,而是简单地获取推文,检索作者并进行必要的后续分析。有趣的是,此轻版本仅需要用户配置文件中的信息即可执行bot检测。这类似于本文中考虑的方法,即基于A类特征的方法。缺点是,对BotometerLite的每个请求最多可以处理100个用户,每天最多可以处理200个请求,从而每天最多可以进行20k帐户检查。
6.2.通过CAP*作为Botometer的输出或作为学习模型的输入进行分类
为了完整起见,在这里,我们比较了直接基于CAP的Botometer的性能以及使用CAP作为其输入功能的分类器的性能。如第4.1节所述,我们在这里考虑CAP_UNI的 * 版本,即考虑到训练集中机器人的实际数量,用校正因子调整的CAP_UNI。一旦训练集中的每个帐户都有CAP_UNI *,我们就通过应用基于阈值的规则来衡量Botometer的性能: 如果CAP_UNI * ≥ 都,则该帐户被标记为bot。然后,我们评估了在 [0,.1] 区间内改变阈值的规则的性能。最后,对于每个训练集,我们选择了给出最佳平衡精度的阈值。平衡精度的值 (以及相关的精度和召回率值) 已与我们的学习模型获得的最佳性能进行了比较。比较结果见表11。

对于每个训练集,我们都报告了Botometer阈值和获得最佳平衡精度的学习模型。我们还报告了相应的精度和召回值。结果表明,直接考虑CAP_UNI * 或将其作为学习模型的输入没有实质性差异。这使我们相信我们所做的选择是值得信赖的。这样,我们可以保持所采用的方法和结果表示的一致性 (第5节),即始终考虑特征集学习模型。
6.3.主要发现
从本文进行的研究中,我们可以得出以下发现。
基于单个基本特征的基本方法 (例如Twitter客户端) 不足以检测复杂的机器人,可能以协调的方式起作用。对于此处考虑的特定训练集,该方法仅在考虑单独行动的相当简单的机器人 (即Botwiki) 时才给出良好的结果。相反,有趣的是,考虑到Twitter客户端在供应商方面获得的低表现: 尽管它们单独行动,但Twitter客户端不足以识别它们,因为它们不会由第三方客户端发布推文。
令人惊讶的是,一组简单的功能,例如从用户的时间轴获得的功能,可以有效地区分新颖的社交机器人,无论是单独行动 (像供应商数据集中的那些) 还是团队行动 (像Rtbust中的转发者和股票中的低价值股票的发起人)。显然,将个人帐户视为机器人并不意味着它是为同一目标而编程的团队的一部分。然而,我们认为,一种基于诸如A类和B类特征的方法,一旦被证明在我们知道有机器人小队的数据集上运行良好,例如在本手稿中调查的那些-可以作为寻找此类小队的第一步。然后,可以通过利用专门的检测系统进一步研究公开的机器人的性质。作为一个显著的例子,社交指纹识别机器人检测技术 (Cresci等,2018) 将用户的在线行为编码为表示其数字DNA的字符串。然后,通过生物信息学算法将数字DNA序列相互比较。该技术将那些在数字DNA序列之间具有可疑高度相似性的用户归为团队中的机器人。为了获得用户的数字DNA,可以使用各种编码。如果我们的目标是了解,例如,如果在一组机器人中有一些广告相同的产品,或者指向相同的信息或帐户,我们可以考虑根据标签的性质编码他们的Twitter时间线,提及和url。最近的一些工作做了类似的事情,即使不是在数字DNA的旗帜下,参见,例如,Caldarelli等人 (2019) 和Hui等人 (2020);
当考虑在供应商验证集上启动的分析时,所有经过测试的功能都会导致召回值崩溃。在表8中,我们已经验证了,当训练集更加平衡时,召回率会上升。实际上,即使这些值没有达到0.9的峰值,它们也类似于考虑训练集Rtbust获得的值,参见表10。因此,与其他集合 (Celebrity-Botwiki,Verified-Botkiwi,Stock相比,供应商集中的一些虚假追随者被错误地标记为真正的Twitter帐户。这表明,即使是最初以非常简单的方式设计的这种帐户,只是为了增加Twitter帐户的关注者数量,已经发生了变化。
6.4.考虑到少于400条推文的时间表
我们意识到我们的研究有局限性。首先,为了与类似的方法进行可靠的比较,例如Sayyadiharikandeh等人 (2020) 中提出的方法,我们必须在该工作中使用的数据集上测试我们的特征集。这远非不可能,因为数据集是众所周知的: 我们将其列入未来工作的议程。
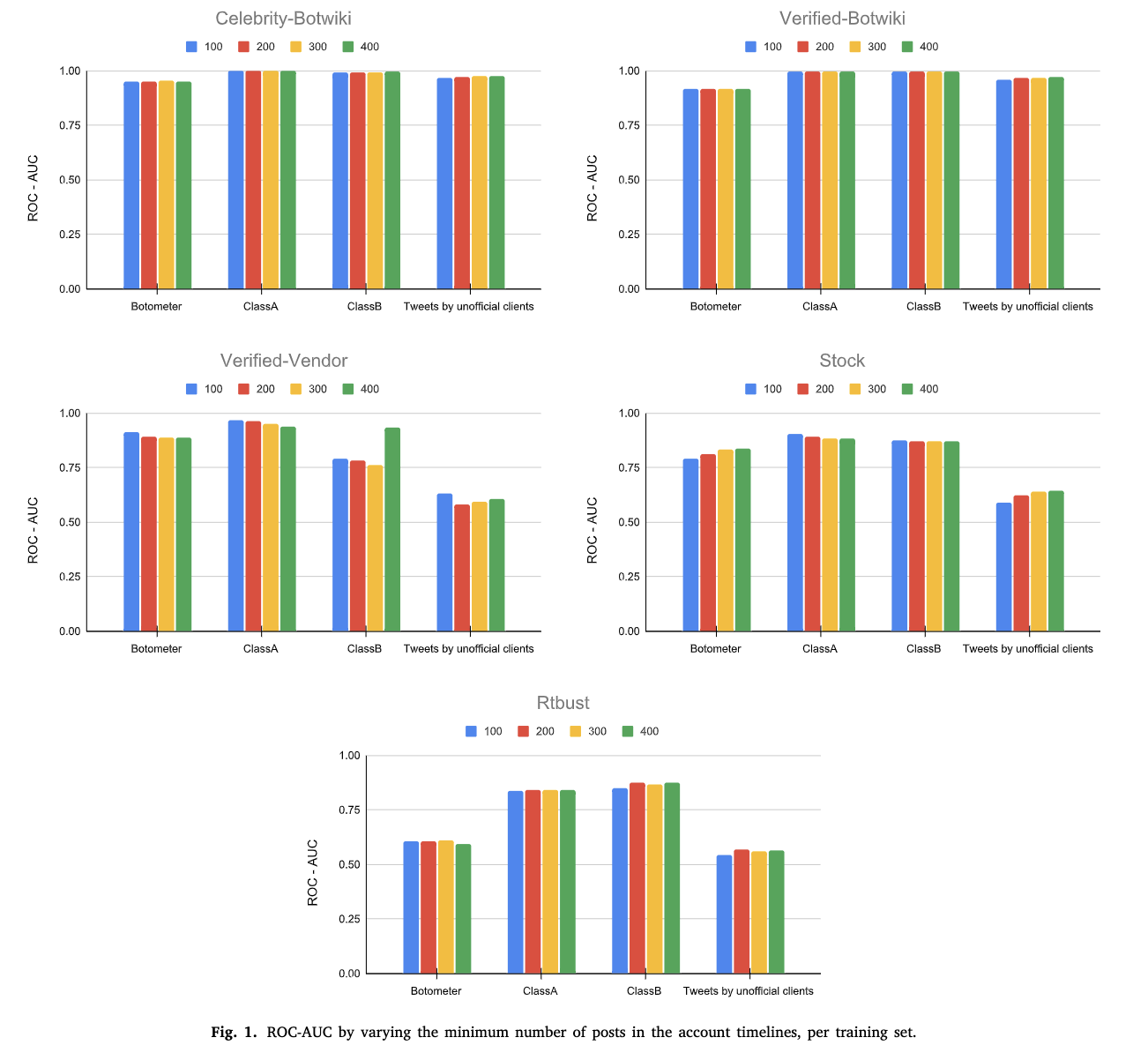
然后,我们通过考虑比400短的时间线来猜测性能结果的可能变化。实际上,从表2中可以看出,如果我们对每个帐户必须具有的最小推文数量设置阈值,则数据集中的帐户数量会发生变化。例如,考虑到供应商数据集,与数据重新抓取时当前 “活着” 的账户 (699账户) 相比,具有至少400个推文的那些账户 (217账户) 的净减少。因此,我们分析了roc-auc在会计时间表中职位数量的变化方面的变化。考虑到时间表中至少有x条推文的帐户会导致训练集的更改 (请参见表2)。为了证明我们分析的稳健性,当改变帐户在其时间轴中必须具有的最小数量时,我们应该测试roc-auc在训练集上是否保持恒定。从图1中可以看出,roc-auc值保持稳定,除了在验证供应商训练集的情况下,这显示了100、200和300推文的AUC值之间的显著差异 (0.73、0.75) 和B类功能集的400推文的值 (>0.9)。在这种情况下,当考虑较少的推文时,性能会降低
6.5. 特征分析
在这里,我们显示了基于信息增益的单个特征的相关性的结果,该信息是关于特征相对于预测类的信息性的度量 (Kent,1983)。信息增益可以被非正式地定义为由给定属性的值的知识引起的熵的预期减少 (Mitchell等,1997)。该分析已在Weka中实现,通过属性选择器算法InfoGainAttributeEval.10在表12中,我们根据信息增益值报告了前五个最重要的特征的排名,针对两个特定的训练集。
7.结论
在本文中,我们对bot检测方法可利用的不同特征集的有效性进行了探索性研究。特别是,我们专注于由于其计算复杂性而需要最少分析工作的功能。所考虑的功能在学术界是众所周知的,并且在过去通常用于机器人检测。特别地,A类和B类特征集首先在Cresci等人 (2015) 中引入,仅限于检测Twitter假追随者,并给出了优异的性能结果。多年来,对Botometer分数的判断超过了自动帐户检测的有效指标。最后,在Bovet和Makse (2019) 中提出了使用推文的源字段来评估来自哪个客户端的推文的想法。我们检查了新的机器人设计上的这些现有功能,以识别那些使我们能够构建高效,有效的机器人检测器的功能集,还用于揭示更新和更复杂的帐户。
我们主要吸取了以下教训:
1.基于考虑Twitter客户端的方法具有最小的复杂性,但事实证明不足以检测复杂的机器人;
2. 配置文件和 (尤其是) 时间轴功能被证明在区分高级机器人 (即团队中工作的机器人) 方面具有重要意义;
3.机器人的发展并没有停止: 假追随者,一种曾经非常简单的机器人类型,现在设法将自己伪装成真正的帐户。
本文显示的实验并非详尽无遗。可以考虑例如所分析的训练集和其他数据集的不同组成来执行更准确的分析。但是,我们相信,本文中显示的结果以及相关的讨论代表了一个很好的证明和推理,可以将机器人的发展与最新功能和学习模型进行对比。