目录
1、编码器的作用
2、编码器的结构图
3、代码实现如下
1、编码器的作用
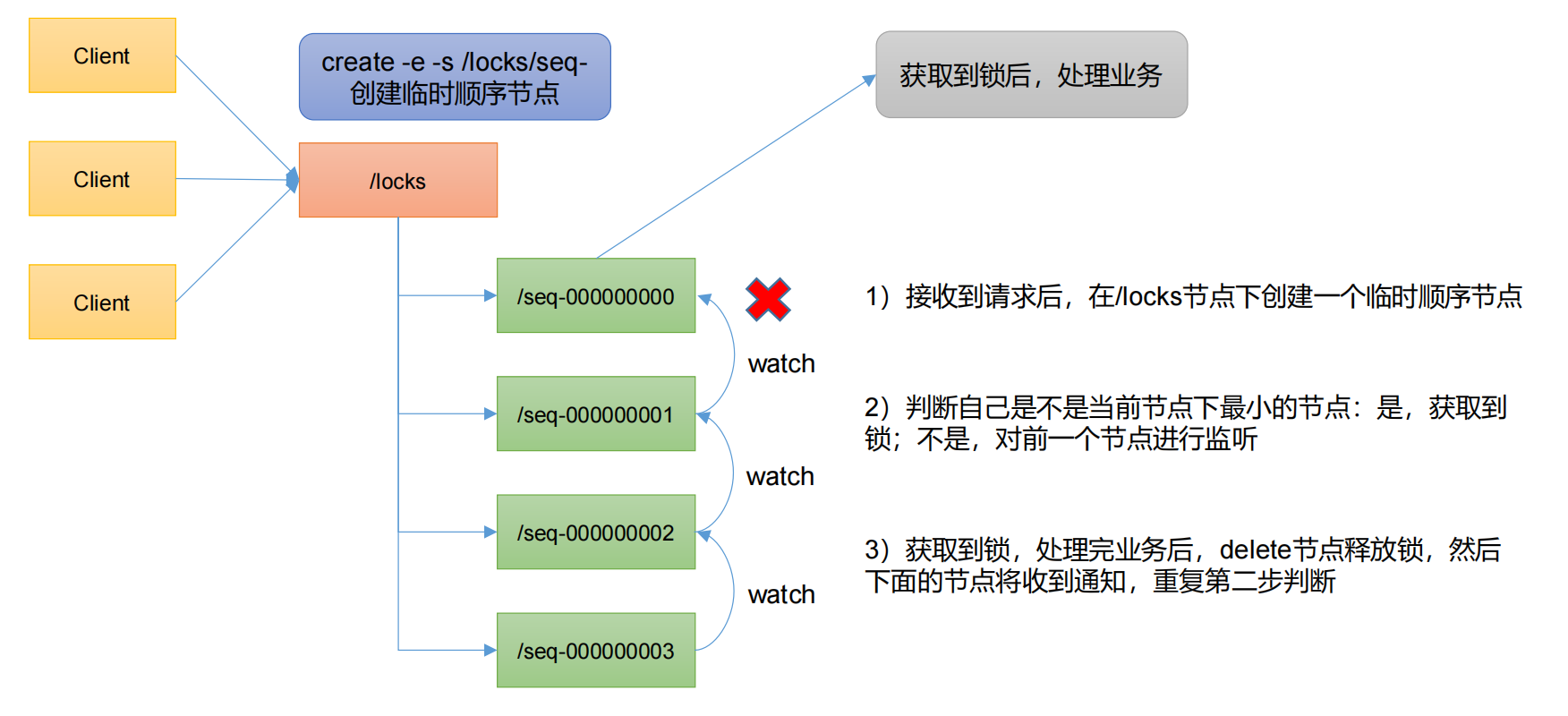
编码器用于对输入进行指定的特征提取的过程,也称为编码,由 N 个编码器层堆叠而成
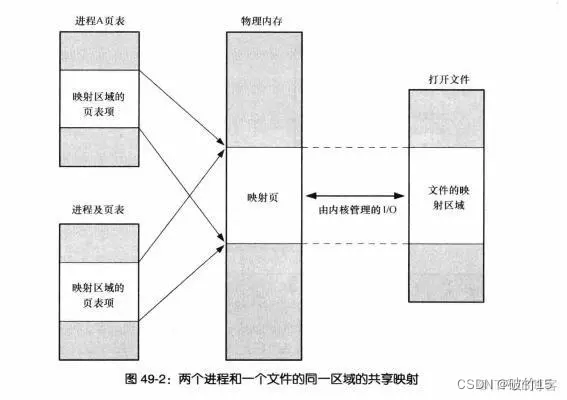
2、编码器的结构图
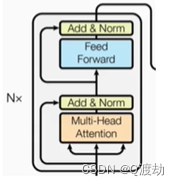
3、代码实现如下
import numpy as np
from torch.autograd import Variable
import copy
from torch import softmax
import math
import torch.nn as nn
import torch
# 构建Embedding类来实现文本嵌入层
class Embeddings(nn.Module):
def __init__(self,vocab,d_model):
"""
:param vocab: 词表的大小
:param d_model: 词嵌入的维度
"""
super(Embeddings,self).__init__()
self.lut = nn.Embedding(vocab,d_model)
self.d_model = d_model
def forward(self,x):
"""
:param x: 因为Embedding层是首层,所以代表输入给模型的文本通过词汇映射后的张量
:return:
"""
return self.lut(x) * math.sqrt(self.d_model)
class PositionalEncoding(nn.Module):
def __init__(self,d_model,dropout,max_len=5000):
"""
:param d_model: 词嵌入的维度
:param dropout: 随机失活,置0比率
:param max_len: 每个句子的最大长度,也就是每个句子中单词的最大个数
"""
super(PositionalEncoding,self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len,d_model) # 初始化一个位置编码器矩阵,它是一个0矩阵,矩阵的大小是max_len * d_model
position = torch.arange(0,max_len).unsqueeze(1) # 初始一个绝对位置矩阵 max_len * 1
div_term = torch.exp(torch.arange(0,d_model,2)*-(math.log(1000.0)/d_model)) # 定义一个变换矩阵,跳跃式的初始化
# 将前面定义的变换矩阵进行奇数、偶数的分别赋值
pe[:,0::2] = torch.sin(position*div_term)
pe[:,1::2] = torch.cos(position*div_term)
pe = pe.unsqueeze(0) # 将二维矩阵扩展为三维和embedding的输出(一个三维向量)相加
self.register_buffer('pe',pe) # 把pe位置编码矩阵注册成模型的buffer,对模型是有帮助的,但是却不是模型结构中的超参数或者参数,不需要随着优化步骤进行更新的增益对象。注册之后我们就可以在模型保存后重加载时,将这个位置编码与模型参数一同加载进来
def forward(self, x):
"""
:param x: 表示文本序列的词嵌入表示
:return: 最后使用self.dropout(x)对对象进行“丢弃”操作,并返回结果
"""
x = x + Variable(self.pe[:, :x.size(1)],requires_grad = False) # 不需要梯度求导,而且使用切片操作,因为我们默认的max_len为5000,但是很难一个句子有5000个词汇,所以要根据传递过来的实际单词的个数对创建的位置编码矩阵进行切片操作
return self.dropout(x)
def subsequent_mask(size):
"""
:param size: 生成向后遮掩的掩码张量,参数 size 是掩码张量的最后两个维度大小,它的最后两个维度形成一个方阵
:return:
"""
attn_shape = (1,size,size) # 定义掩码张量的形状
subsequent_mask = np.triu(np.ones(attn_shape),k = 1).astype('uint8') # 定义一个上三角矩阵,元素为1,再使用其中的数据类型变为无符号8位整形
return torch.from_numpy(1 - subsequent_mask) # 先将numpy 类型转化为 tensor,再做三角的翻转,将位置为 0 的地方变为 1,将位置为 1 的方变为 0
def attention(query, key, value, mask=None, dropout=None):
"""
:param query: 三个张量输入
:param key: 三个张量输入
:param value: 三个张量输入
:param mask: 掩码张量
:param dropout: 传入的 dropout 实例化对象
:return:
"""
d_model = query.size(-1) # 得到词嵌入的维度,取 query 的最后一维大小
scores = torch.matmul(query,key.transpose(-2,-1)) / math.sqrt(d_model) # 按照注意力公式,将 query 和 key 的转置相乘,这里是将 key 的最后两个维度进行转置,再除以缩放系数,得到注意力得分张量 scores
# query(2,8,4,64) key.transpose(-2,-1) (2,8,64,4) 进行矩阵乘法为 (2,8,4,4)
if mask is not None:
scores = torch.masked_fill(scores,mask == 0,-1e9) # 使用 tensor 的 mask_fill 方法,将掩码张量和 scores 张量中每一个位置进行一一比较,如果掩码张量处为 0 ,则使用 -1e9 替换
# scores = scores.masked_fill(mask == 0,-1e9)
p_attn = softmax(scores, dim = -1) # 对 scores 的最后一维进行 softmax 操作,使用 F.softmax 方法,第一个参数是 softmax 对象,第二个参数是最后一个维度,得到注意力矩阵
print('scores.shape ',scores.shape)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn,value),p_attn # 返回注意力表示
class MultiHeadAttention(nn.Module):
def __init__(self, head, embedding_dim , dropout=0.1):
"""
:param head: 代表几个头的参数
:param embedding_dim: 词向量维度
:param dropout: 置零比率
"""
super(MultiHeadAttention, self).__init__()
assert embedding_dim % head == 0 # 确认一下多头的数量可以整除词嵌入的维度 embedding_dim
self.d_k = embedding_dim // head # 每个头获得词向量的维度
self.head = head
self.linears = nn.ModuleList([copy.deepcopy(nn.Linear(embedding_dim, embedding_dim)) for _ in range(4)]) # 深层拷贝4个线性层,每一个层都是独立的,保证内存地址是独立的,分别是 Q、K、V以及最终的输出线性层
self.attn = None # 初始化注意力张量
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""
:param query: 查询query [batch size, sentence length, d_model]
:param key: 待查询key [batch size, sentence length, d_model]
:param value: 待查询value [batch size, sentence length, d_model]
:param mask: 计算相似度得分时的掩码(设置哪些输入不计算到score中)[batch size, 1, sentence length]
:return:
"""
if mask is not None:
mask = mask.unsqueeze(1) # 将掩码张量进行维度扩充,代表多头中的第 n 个头
batch_size = query.size(0)
query, key, value = [l(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2) for l, x in zip(self.linears, (query, key, value))] # 将1、2维度进行调换,目的是让句子长度维度和词向量维度靠近,这样注意力机制才能找到词义与句子之间的关系
# 将每个头传递到注意力层
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 得到每个头的计算结果是 4 维的张量,需要形状的转换
# 前面已经将1,2两个维度进行转置了,所以这里要重新转置回来
# 前面已经经历了transpose,所以要使用contiguous()方法,不然无法使用 view 方法
x = x.transpose(1, 2).contiguous() \
.view(batch_size, -1, self.head * self.d_k)
return self.linears[-1](x) # 在最后一个线性层中进行处理,得到最终的多头注意力结构输出
class LayerNormalization(nn.Module):
def __init__(self, features, eps=1e-6):
"""
:param features: 词嵌入的维度
:param eps: 出现在规范化公式的分母中,防止分母为0
"""
super(LayerNormalization, self).__init__()
# a 系数的默认值为1,模型的参数
self.a = nn.Parameter(torch.ones(features))
# b 系统的初始值为0,模型的参数
self.b = nn.Parameter(torch.zeros(features))
# 把 eps 传递到类中
self.eps = eps
def forward(self, x):
# 在最后一个维度上求 均值,并且输出维度保持不变
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a * (x - mean) / (std + self.eps) + self.b
class PositionFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
"""
:param d_model: 输入维度,词嵌入的维度
:param d_ff: 第一个的输出连接第二个的输入
:param dropout: 置零比率
"""
super(PositionFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p = dropout)
def forward(self, x):
return self.linear2(self.dropout(torch.relu(self.linear1(x))))
class SublayerConnection(nn.Module):
def __init__(self, size, dropout=0.1):
super(SublayerConnection,self).__init__()
# 实例化了一个 LN 对象
self.norm = LayerNormalization(size)
self.dropout = nn.Dropout(p = dropout)
def forward(self,x,sublayer):
"""
:param x: 接受上一个层或者子层的输入作为第一个参数
:param sublayer: 该子层连接中的子层函数胡作为第二个参数
:return:
"""
"首先对输出进行规范化,然后将结果交给子层处理,之后对子层进行 dropout处理" \
"随机失活一些神经元,来防止过拟合,最后还有一个add操作" \
"因此存在跳跃连接,所以是将输入x与dropout后的子层输出结果相加作为最终的子层连接输出"
return x + self.dropout(sublayer(self.norm(x)))
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
"""
:param size: 词嵌入的维度
:param self_attn: 传入多头自注意力子层实例化对象,并且是自注意力机制
:param feed_forward: 前馈全连接层实例化对象
:param dropout: 置零比率
"""
super(EncoderLayer,self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = nn.ModuleList([copy.deepcopy(SublayerConnection(size,dropout)) for _ in range(2)])
self.size = size
def forward(self, x, mask):
"""
:param x: 上一层的输出
:param mask: 掩码张量
:return:
"""
"首先通过第一个子层连接结构,其中包含多头自注意力子层"
"然后通过第二个子层连接结构,其中包含前馈全连接子层,最后返回结果"
x = self.sublayer[0](x,lambda x:self.self_attn(x,x,x,mask))
return self.sublayer[1](x,self.feed_forward)import torch.nn as nn
import copy
class Encoder(nn.Module):
def __init__(self, layer, N):
"""
:param layer: 编码器层
:param N: 编码器的个数
"""
super(Encoder,self).__init__()
self.layers = nn.ModuleList(copy.deepcopy(layer) for _ in range(N))
"初始化一个规范化层,用于最后的输出"
self.norm = LayerNormalization(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x,mask)
return self.norm(x)
# 实例化参数
size = d_model = 512
head = 8
mask = torch.zeros(2,4,4)
d_ff = 62
dropout = 0.2
max_len = 60 # 句子最大长度
#-----------------------------------------词嵌入层
# 输入 x 是 Embedding层输出的张量,形状为 2 * 4 * 512
x = Variable(torch.LongTensor([[100,2,42,508],[491,998,1,221]]))
emb = Embeddings(1000,512) # 嵌入层
embr = emb(x)
#-----------------------------------------位置编码
pe = PositionalEncoding(d_model, dropout,max_len)
pe_result = pe(embr)
x = pe_result
#-----------------------------------------多头注意力
self_attn = MultiHeadAttention(head,d_model)
#-----------------------------------------FFN
ff = PositionFeedForward(d_model, d_ff, dropout)
#-----------------------------------------编码器层
layer = EncoderLayer(size, copy.deepcopy(self_attn), copy.deepcopy(ff),dropout)
#-----------------------------------------编码器
N = 8
en = Encoder(layer, N)
en_result = en(x,mask)
print(en_result)
print(en_result.shape)scores.shape torch.Size([2, 8, 4, 4])
scores.shape torch.Size([2, 8, 4, 4])
scores.shape torch.Size([2, 8, 4, 4])
scores.shape torch.Size([2, 8, 4, 4])
scores.shape torch.Size([2, 8, 4, 4])
scores.shape torch.Size([2, 8, 4, 4])
scores.shape torch.Size([2, 8, 4, 4])
scores.shape torch.Size([2, 8, 4, 4])
tensor([[[ 0.8972, 1.1464, -2.2886, ..., 0.4909, 0.5196, 0.0756],
[-0.1428, 1.3504, 0.2368, ..., -1.0005, 0.1516, -2.1761],
[-0.0204, 0.1874, -0.7120, ..., 1.0886, 0.5129, 1.1401],
[-0.1354, -0.0835, -1.4364, ..., 1.4079, 0.3481, -0.0844]],
[[-1.5945, -0.1464, 0.3596, ..., -1.7038, 1.0241, -0.0716],
[-0.4506, -0.0832, -0.3198, ..., 0.0378, -0.5991, -0.7635],
[ 1.4974, 1.8504, 2.1817, ..., -0.7692, -0.1072, -1.0367],
[-0.2180, -0.8411, 0.1120, ..., 1.3320, -0.3436, -0.3399]]],
grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])


![2023年中国数控系统市场发展历程及趋势分析:数控系统市场规模将持续扩大[图]](https://img-blog.csdnimg.cn/img_convert/496d439bbf7717dadfc23c76eead425b.png)