文章目录
- 1. 三大组件
- 1.1 Channel
- 1.2 Buffer
- 1.2 Selector
- 2.ByteBuffer
- 2.1 ByteBuffer 正确使用姿势
- 2.2 ByteBuffer 结构
- 2.3 ByteBuffer 常见方法
- 分配空间
- 向 buffer 写入数据
- 从 buffer 读取数据
- mark 和 reset
- 字符串与 ByteBuffer 互转
- 分散度集中写
- byteBuffer黏包半包
- 3. 文件编程
- 3.1 FileChannel
- 获取
- 读取
- 写入
- 关闭
- 位置
- 大小
- 强制写入
- 3.2 两个 Channel 传输数据
- 3.3 Path
- 3.4 Files
- 遍历目录
- 删除多级目录
- 拷贝多级目录
黑马视频地址:https://www.bilibili.com/video/BV1py4y1E7oA/?p=1
Netty是基于NIO(non-blocking io 非阻塞 IO),先了解nio
1. 三大组件
1.1 Channel
channel 是一个读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel
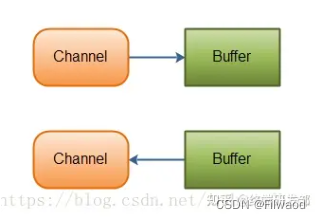
常见的 Channel 有
- FileChannel (文件)
- DatagramChannel (UDP)
- SocketChannel (TCP 客户端/服务端都能用)
- ServerSocketChannel(TCP 服务端)
1.2 Buffer
buffer就是缓冲区,用来缓冲读写数据,常见的 buffer 有
- ByteBuffer
- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
1.2 Selector
字面理解就是选择器,作用就是配合一个线程来管理多个 channel,获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,不会让线程吊死在一个 channel 上。适合连接数特别多,但流量低的场景(low traffic)
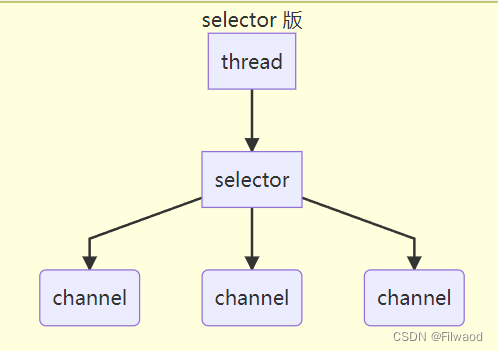
调用 selector 的 select() 会阻塞直到 channel 发生了读写就绪事件,这些事件发生,select 方法就会返回这些事件交给 thread 来处理
2.ByteBuffer
简单案例:有一普通文本文件 data.txt,内容为
1234567890abcd
使用 FileChannel 来读取文件内容
@Slf4j
public class TestByteBuffer {
public static void main(String[] args) throws FileNotFoundException {
// 读取文件,并自动释放输入流
try (FileChannel channel = new FileInputStream("data.txt").getChannel()) {
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
while (true) {
//读出文件内容写入缓冲区
int read = channel.read(buffer);
log.info("读到的字节数:{}", read);
if (read == -1) {
break;
}
//切换到读模式
buffer.flip();
while (buffer.hasRemaining()) {
log.info("实际字节:{}", (char) buffer.get());
}
//切换到写模式
buffer.clear();
}
} catch (
IOException e) {
e.printStackTrace();
}
}
}
结果
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 读到的字节数:10
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:1
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:2
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:3
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:4
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:5
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:6
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:7
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:8
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:9
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:0
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 读到的字节数:4
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:a
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:b
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:c
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 实际字节:d
11:15:40 [INFO ] [main] c.i.b.TestByteBuffer - 读到的字节数:-1
2.1 ByteBuffer 正确使用姿势
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或 compact() 切换至写模式
- 重复 1~4 步骤
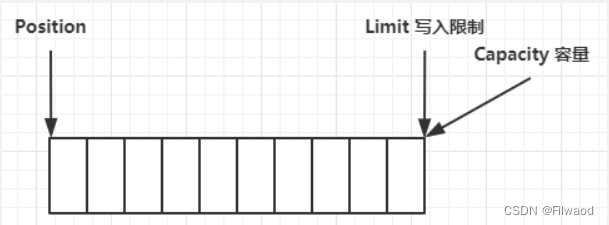
2.2 ByteBuffer 结构
ByteBuffer 有以下重要属性
- capacity
- position
- limit
一开始
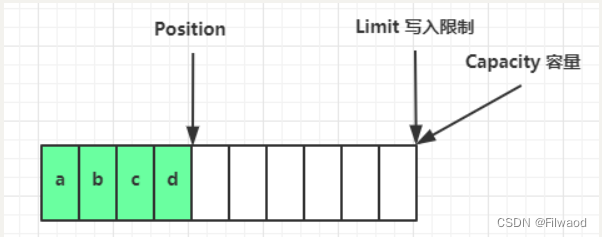
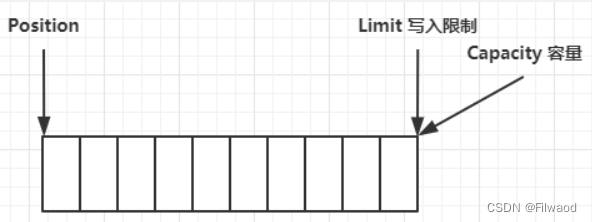
写模式下,position 是写入位置,limit 等于容量,下图表示写入了 4 个字节后的状态
flip 动作发生后,position 切换为读取位置,limit 切换为读取限制
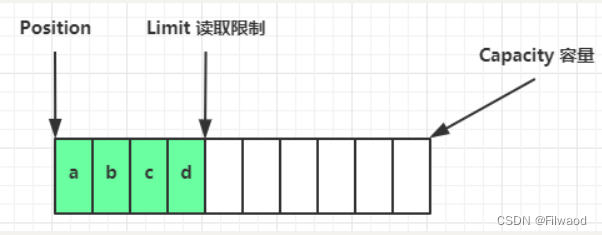
读取 4 个字节后,状态
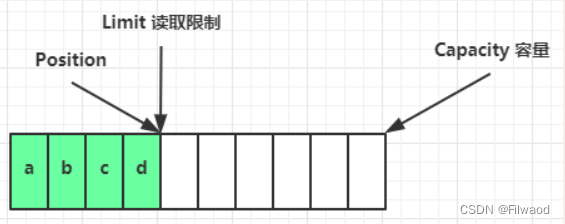
clear 动作发生后,状态
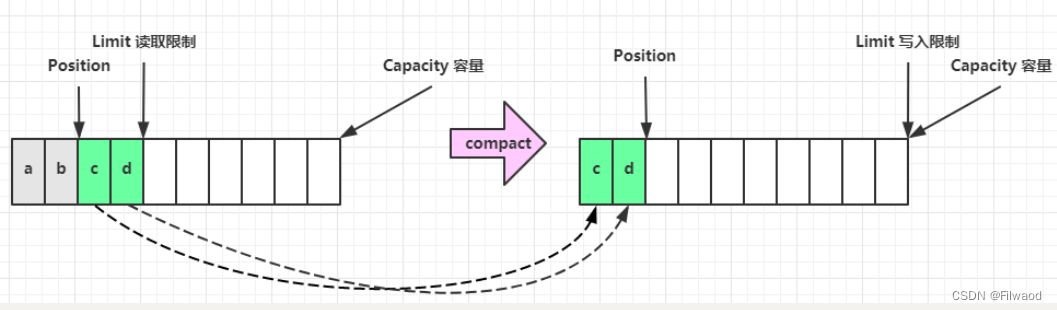
compact 方法,是把未读完的部分向前压缩,然后切换至写模式
💡 调试工具类
public class ByteBufferUtil {
private static final char[] BYTE2CHAR = new char[256];
private static final char[] HEXDUMP_TABLE = new char[256 * 4];
private static final String[] HEXPADDING = new String[16];
private static final String[] HEXDUMP_ROWPREFIXES = new String[65536 >>> 4];
private static final String[] BYTE2HEX = new String[256];
private static final String[] BYTEPADDING = new String[16];
static {
final char[] DIGITS = "0123456789abcdef".toCharArray();
for (int i = 0; i < 256; i++) {
HEXDUMP_TABLE[i << 1] = DIGITS[i >>> 4 & 0x0F];
HEXDUMP_TABLE[(i << 1) + 1] = DIGITS[i & 0x0F];
}
int i;
// Generate the lookup table for hex dump paddings
for (i = 0; i < HEXPADDING.length; i++) {
int padding = HEXPADDING.length - i;
StringBuilder buf = new StringBuilder(padding * 3);
for (int j = 0; j < padding; j++) {
buf.append(" ");
}
HEXPADDING[i] = buf.toString();
}
// Generate the lookup table for the start-offset header in each row (up to 64KiB).
for (i = 0; i < HEXDUMP_ROWPREFIXES.length; i++) {
StringBuilder buf = new StringBuilder(12);
buf.append(NEWLINE);
buf.append(Long.toHexString(i << 4 & 0xFFFFFFFFL | 0x100000000L));
buf.setCharAt(buf.length() - 9, '|');
buf.append('|');
HEXDUMP_ROWPREFIXES[i] = buf.toString();
}
// Generate the lookup table for byte-to-hex-dump conversion
for (i = 0; i < BYTE2HEX.length; i++) {
BYTE2HEX[i] = ' ' + StringUtil.byteToHexStringPadded(i);
}
// Generate the lookup table for byte dump paddings
for (i = 0; i < BYTEPADDING.length; i++) {
int padding = BYTEPADDING.length - i;
StringBuilder buf = new StringBuilder(padding);
for (int j = 0; j < padding; j++) {
buf.append(' ');
}
BYTEPADDING[i] = buf.toString();
}
// Generate the lookup table for byte-to-char conversion
for (i = 0; i < BYTE2CHAR.length; i++) {
if (i <= 0x1f || i >= 0x7f) {
BYTE2CHAR[i] = '.';
} else {
BYTE2CHAR[i] = (char) i;
}
}
}
/**
* 打印所有内容
* @param buffer
*/
public static void debugAll(ByteBuffer buffer) {
int oldlimit = buffer.limit();
buffer.limit(buffer.capacity());
StringBuilder origin = new StringBuilder(256);
appendPrettyHexDump(origin, buffer, 0, buffer.capacity());
System.out.println("+--------+-------------------- all ------------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), oldlimit);
System.out.println(origin);
buffer.limit(oldlimit);
}
/**
* 打印可读取内容
* @param buffer
*/
public static void debugRead(ByteBuffer buffer) {
StringBuilder builder = new StringBuilder(256);
appendPrettyHexDump(builder, buffer, buffer.position(), buffer.limit() - buffer.position());
System.out.println("+--------+-------------------- read -----------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), buffer.limit());
System.out.println(builder);
}
private static void appendPrettyHexDump(StringBuilder dump, ByteBuffer buf, int offset, int length) {
if (isOutOfBounds(offset, length, buf.capacity())) {
throw new IndexOutOfBoundsException(
"expected: " + "0 <= offset(" + offset + ") <= offset + length(" + length
+ ") <= " + "buf.capacity(" + buf.capacity() + ')');
}
if (length == 0) {
return;
}
dump.append(
" +-------------------------------------------------+" +
NEWLINE + " | 0 1 2 3 4 5 6 7 8 9 a b c d e f |" +
NEWLINE + "+--------+-------------------------------------------------+----------------+");
final int startIndex = offset;
final int fullRows = length >>> 4;
final int remainder = length & 0xF;
// Dump the rows which have 16 bytes.
for (int row = 0; row < fullRows; row++) {
int rowStartIndex = (row << 4) + startIndex;
// Per-row prefix.
appendHexDumpRowPrefix(dump, row, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + 16;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(" |");
// ASCII dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append('|');
}
// Dump the last row which has less than 16 bytes.
if (remainder != 0) {
int rowStartIndex = (fullRows << 4) + startIndex;
appendHexDumpRowPrefix(dump, fullRows, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + remainder;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(HEXPADDING[remainder]);
dump.append(" |");
// Ascii dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append(BYTEPADDING[remainder]);
dump.append('|');
}
dump.append(NEWLINE +
"+--------+-------------------------------------------------+----------------+");
}
private static void appendHexDumpRowPrefix(StringBuilder dump, int row, int rowStartIndex) {
if (row < HEXDUMP_ROWPREFIXES.length) {
dump.append(HEXDUMP_ROWPREFIXES[row]);
} else {
dump.append(NEWLINE);
dump.append(Long.toHexString(rowStartIndex & 0xFFFFFFFFL | 0x100000000L));
dump.setCharAt(dump.length() - 9, '|');
dump.append('|');
}
}
public static short getUnsignedByte(ByteBuffer buffer, int index) {
return (short) (buffer.get(index) & 0xFF);
}
}
2.3 ByteBuffer 常见方法
分配空间
可以使用 allocate 方法为 ByteBuffer 分配空间,其它 buffer 类也有该方法
Bytebuffer buf = ByteBuffer.allocate(16);
Bytebuffer buf = ByteBuffer.allocateDirect(16)
//class java.nio.HeapByteBuffer java堆内存,读写效率较低,受到 GC 的影响
//class java.nio.DirectByteBuffer 直接内存,读写效率高(少一次拷贝),不会受 GC 影响,分配的效丰低
向 buffer 写入数据
有两种办法
-
从Channel写到Buffer。
-
通过Buffer的put()方法写到Buffer里。
int readBytes = channel.read(buf);
buf.put((byte)127);
从 buffer 读取数据
同样有两种办法
- 从Buffer读取数据到Channel。
- 使用get()方法从Buffer中读取数据。
int writeBytes = channel.write(buf);
byte b = buf.get();
get 方法会让 position 读指针向后走,如果想重复读取数据
- 可以调用 rewind 方法将 position 重新置为 0
- 或者调用 get(int i) 方法获取索引 i 的内容,它不会移动读指针
public static void main(String[] args) {
//rewind
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'a','b','c','d','e'});
buffer.flip();
buffer.get(new byte[4]);
debugAll(buffer);
buffer.rewind();
debugAll(buffer);
System.out.println((char)buffer.get());
//get(i)
debugAll(buffer);
System.out.println((char)buffer.get(2));
debugAll(buffer);
}
mark 和 reset
mark 是在读取时,做一个标记,记录position 位置,即使 position 改变,只要调用 reset 就能回到 mark 的位置
注意
rewind 和 flip 都会清除 mark 位置
public static void main(String[] args) {
// mark & reset
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'a','b','c','d','e'});
buffer.flip();
System.out.println((char)buffer.get());//a
System.out.println((char)buffer.get());//b
buffer.mark();//记录position位置
System.out.println((char)buffer.get());//c
System.out.println((char)buffer.get());//d
buffer.reset();//重置到记录的position位置
System.out.println((char)buffer.get());//c
System.out.println((char)buffer.get());//d
}
字符串与 ByteBuffer 互转
字符串转buffer
- buffer1.put(字符串.getBytes());
- StandardCharsets.UTF_8.encode(字符串);
- ByteBuffer.wrap(字符串.getBytes());
buffer转字符串
- StandardCharsets.UTF_8.decode(buffer1).toString();
public static void main(String[] args) {
//字符串转buffer
ByteBuffer buffer1 = ByteBuffer.allocate(16);
buffer1.put("nihao".getBytes());//写模式,转换要改为读模式
debugAll(buffer1);
ByteBuffer buffer2 = StandardCharsets.UTF_8.encode("nihao");//读模式
debugAll(buffer2);
ByteBuffer buffer3 = ByteBuffer.wrap("nihao".getBytes());//读模式
debugAll(buffer3);
//buffer转字符串
buffer1.flip();
String s1 = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(s1);
String s2 = StandardCharsets.UTF_8.decode(buffer2).toString();
System.out.println(s2);
}
分散度集中写
分散读取,有一个文本文件 parts.txt
onetwothree
使用如下方式读取,可以将数据填充至多个 buffer
public static void main(String[] args) throws IOException {
try(FileChannel channel=new RandomAccessFile("part.txt","r").getChannel()) {
ByteBuffer a = ByteBuffer.allocate(3);
ByteBuffer b = ByteBuffer.allocate(3);
ByteBuffer c = ByteBuffer.allocate(5);
channel.read(new ByteBuffer[]{a,b,c});
a.flip();
b.flip();
c.flip();
debugAll(a);//one
debugAll(b);//two
debugAll(c);//three
}
}
使用如下方式写入,可以将多个 buffer 的数据填充至 channel
public static void main(String[] args) throws IOException {
ByteBuffer a = StandardCharsets.UTF_8.encode("hello");
ByteBuffer b = StandardCharsets.UTF_8.encode("world");
ByteBuffer c = StandardCharsets.UTF_8.encode("你好");
try (FileChannel channel = new RandomAccessFile("new.txt", "rw").getChannel()) {
channel.write(new ByteBuffer[]{a, b, c});
}
}
byteBuffer黏包半包
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔,但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条为
- Hello,world\n
- I’m zhangsan\n
- How are you?\n
- haha!\n
变成了下面的两个 byteBuffer (黏包,半包)
- Hello,world\nI’m zhangsan\nHo
- w are you?\nhaha!
现在要求你编写程序,将错乱的数据恢复成原始的按 \n 分隔的数据
public class TestByteBufferNianBao {
public static void main(String[] args) {
ByteBuffer source = ByteBuffer.allocate(32);
source.put("Hello,world\nI'm zhangsan\nHo".getBytes());
split(source);
source.put("w are you?\nhaha!\n".getBytes());
split(source);
}
private static void split(ByteBuffer source) {
source.flip();
for (int i = 0; i < source.limit(); i++) {
//如果是 \n 证明是一句话
if (source.get(i) == '\n') {
//分配ByteBuffer大小
int length = i + 1 - source.position();
//用一个buffer存这一句话
ByteBuffer buffer = ByteBuffer.allocate(length);
for (int j = 0; j < length; j++) {
buffer.put(source.get());
}
debugAll(buffer);
}
}
//把半句话压入前面等待处理
source.compact();
}
}
3. 文件编程
3.1 FileChannel
获取
在使用FileChannel之前,必须先打开它。但是,我们无法直接打开一个FileChannel,需要通过使用一个InputStream、OutputStream或RandomAccessFile来获取一个FileChannel实例。
- 通过 FileInputStream 获取的 channel 只能读
- 通过 FileOutputStream 获取的 channel 只能写
- 通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定
读取
该方法将数据从FileChannel读取到Buffer中。read()方法返回的int值表示了有多少字节被读到了Buffer中。如果返回-1,表示到了文件末尾。
int readBytes = channel.read(buffer);
写入
写入的正确姿势如下
ByteBuffer buffer = ...;
buffer.put(...); // 存入数据
buffer.flip(); // 切换读模式
while(buffer.hasRemaining()) {
channel.write(buffer);
}
注意FileChannel.write()是在while循环中调用的。因为无法保证write()方法一次能向FileChannel写入多少字节,因此需要重复调用write()方法,直到Buffer中已经没有尚未写入通道的字节。
关闭
channel 必须关闭:channel.close(),不过调用了 FileInputStream、FileOutputStream 或者 RandomAccessFile 的 close 方法会间接地调用 channel 的 close 方法
位置
有时可能需要在FileChannel的某个特定位置进行数据的读/写操作。可以通过调用position()方法获取FileChannel的当前位置。
也可以通过调用position(long pos)方法设置FileChannel的当前位置
long pos = channel.positon();
大小
FileChannel实例的size()方法将返回该实例所关联文件的大小。
long size = channel.size();
强制写入
FileChannel.force()方法将通道里尚未写入磁盘的数据强制写到磁盘上。出于性能方面的考虑,操作系统会将数据缓存在内存中,所以无法保证写入到FileChannel里的数据一定会即时写到磁盘上。要保证这一点,需要调用force()方法。
force()方法有一个boolean类型的参数,指明是否同时将文件元数据(权限信息等)写到磁盘上。
channel.force(true);
3.2 两个 Channel 传输数据
public static void main(String[] args) {
try (
FileChannel from = new FileInputStream("from.txt").getChannel();
FileChannel to = new FileOutputStream("to.txt").getChannel();
) {
//效率高,底层会利用操作系统的零拷贝进行优化
long size = from.size();
// left 还剩多少未传
for (long left = size; left > 0; ) {
//每次实际传输的大小,2G是上限
long transfer = from.transferTo(size - left, left, to);
left -= transfer;
}
} catch (Exception e) {
e.printStackTrace();
}
}
3.3 Path
jdk7 引入了 Path 和 Paths 类
- Path 用来表示文件路径
- Paths 是工具类,用来获取 Path 实例
Path source = Paths.get("1.txt"); // 相对路径 使用 user.dir 环境变量来定位 1.txt
Path source = Paths.get("d:\\1.txt"); // 绝对路径 代表了 d:\1.txt
Path source = Paths.get("d:/1.txt"); // 绝对路径 同样代表了 d:\1.txt
Path projects = Paths.get("d:\\data", "projects"); // 代表了 d:\data\projects
.代表了当前路径..代表了上一级路径
例如目录结构如下
d:
|- data
|- projects
|- a
|- b
代码
Path path = Paths.get("d:\\data\\projects\\a\\..\\b");
System.out.println(path);
System.out.println(path.normalize()); // 正常化路径
会输出
d:\data\projects\a\..\b
d:\data\projects\b
3.4 Files
检查文件是否存在
Path path = Paths.get("helloword/data.txt");
System.out.println(Files.exists(path));
创建一级目录
Path path = Paths.get("helloword/d1");
Files.createDirectory(path);
- 如果目录已存在,会抛异常 FileAlreadyExistsException
- 不能一次创建多级目录,否则会抛异常 NoSuchFileException
创建多级目录用
Path path = Paths.get("helloword/d1/d2");
Files.createDirectories(path);
拷贝文件
Path source = Paths.get("helloword/data.txt");
Path target = Paths.get("helloword/target.txt");
Files.copy(source, target);
- 如果文件已存在,会抛异常 FileAlreadyExistsException
如果希望用 source 覆盖掉 target,需要用 StandardCopyOption 来控制
Files.copy(source, target, StandardCopyOption.REPLACE_EXISTING);
移动文件
Path source = Paths.get("helloword/data.txt");
Path target = Paths.get("helloword/data.txt");
Files.move(source, target, StandardCopyOption.ATOMIC_MOVE);
- StandardCopyOption.ATOMIC_MOVE 保证文件移动的原子性
删除文件
Path target = Paths.get("helloword/target.txt");
Files.delete(target);
- 如果文件不存在,会抛异常 NoSuchFileException
删除目录
Path target = Paths.get("helloword/d1");
Files.delete(target);
- 如果目录还有内容,会抛异常 DirectoryNotEmptyException
遍历目录
public static void main(String[] args) throws IOException {
Path path = Paths.get("D:\\Program Files (x86)\\DingDing");
AtomicInteger dirCount = new AtomicInteger();
AtomicInteger fileCount = new AtomicInteger();
Files.walkFileTree(path, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println("+" + dir);
dirCount.incrementAndGet();
return super.preVisitDirectory(dir, attrs);
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("-" + file);
fileCount.incrementAndGet();
return super.visitFile(file, attrs);
}
});
System.out.println("dirCount:" + dirCount);
System.out.println("fileCount:" + fileCount);
}
删除多级目录
public static void main(String[] args) throws IOException {
Path path = Paths.get("D:\\Program Files (x86)\\DingDing - 副本");
Files.walkFileTree(path, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
//访问文件的时候删除文件
Files.delete(file);
return super.visitFile(file, attrs);
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
//退出文件夹的时候删除文件夹
Files.delete(dir);
return super.postVisitDirectory(dir, exc);
}
});
}
拷贝多级目录
public static void main(String[] args) throws IOException {
String source = "D:\\Program Files (x86)\\DingDing";
String target = "D:\\Program Files (x86)\\DingDingfuben";
Files.walk(Paths.get(source)).forEach(path -> {
try {
String targetName = path.toString().replace(source, target);
//如果是目录
if (Files.isDirectory(path)) {
Files.createDirectory(Paths.get(targetName));
}
//如果是文件
else if (Files.isRegularFile(path)) {
Files.copy(path, Paths.get(targetName));
}
} catch (IOException e) {
e.printStackTrace();
}
});
}



![2023年中国睡眠检测仪产量、销量及市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/a5220abb99d778492f57484595c1e290.png)