索引模板了解么
索引模板,一种复用机制,就像一些项目的开发框架如 Laravel 一样,省去了大量的重复,体力劳动。当新建一个 Elasticsearch 索引时,自动匹配模板,完成索引的基础部分搭建。
模板定义,看似复杂,拆分来看,主要为如下几个部分:
{
"order": 0, // 模板优先级
"template": "sample_info*", // 模板匹配的名称方式
"settings": {...}, // 索引设置
"mappings": {...}, // 索引中各字段的映射定义
"aliases": {...} // 索引的别名
}
模板优先级
一个模板可能绝大部分符合新建索引的需求,但是局部需要微调,此时,如果复制旧的模板,修改该模板后,成为一个新的索引模板即可达到我们的需求,但是这操作略显重复。此时,可以采用模板叠加与覆盖来操作。模板的优先级是通过模板中的 order 字段定义的,数字越大,优先级越高。
索引模板的匹配
索引模板中的 "template" 字段定义的是该索引模板所应用的索引情况。如 "template": "tete*" 所表示的含义是,当新建索引时,所有以 tete 开头的索引都会自动匹配到该索引模板。利用该模板进行相应的设置和字段添加等。
setting 部分
索引模板中的 setting 部分一般定义的是索引的主分片、拷贝分片、刷新时间、自定义分析器等。
Elasticsearch 是如何实现 master 选举的
前提条件:
只有候选主节点(master:true)的节点才能成为主节点。
最小候选主节点数(min_master_nodes)的目的是防止脑裂。
实现步骤:
- 第一步:确认候选主节点数达标,elasticsearch.yml 设置的值discovery.zen.minimum_master_nodes:作用是只有足够的master候选节点时,才可以选举出一个master。该参数必须设置为集群中master候选节点的quorum数量。quorum的算法=master候选节点数量/2+1(就是必须超过所有候选主节点一般以上,可以思考redis cluster、zk集群的脑裂问题,也有类似的参数设置)
- 第二步:对所有候选主节点根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
- 第三步:如果对某个节点的投票数达到一定的值(候选主节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
【补充】master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能。
如何解决ES集群的脑裂问题
【原因】
所谓集群脑裂,是指 Elasticsearch 集群中的节点(比如共 20 个),可能因为网络问题,其中的 10 个选了一个 master,另外 10 个选了另一个 master 的情况。
【解决】
当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes:最小候选主节点数)超过所有候选节点一半以上来解决脑裂问题;
对公司ES集群了解,ES集群架构,索引数据大小,分片数量
想了解应聘者之前公司接触的ES使用场景、规模,有没有做过比较大规模的索引设计、规划、调优
解答:
查看es集群状态:
curl -XGET http://localhost:9200/_cat/health?v
返回结果:
{
"cluster": "es-9pu872sa", #集群名称
"status": "green", #集群状态 green代表健康;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;red代表部分主分片不可用,可能已经丢失数据
"node.data": "8", #代表在线的数据节点的数量
"node.total": "11", #代表在线的节点总数量
"init": "0", #initializing_shards 初始化中的分片数量 正常情况为 0
"relo": "0", #relocating_shards 迁移中的分片数量,正常情况为 0
"pending_tasks": "0", #准备中的任务,任务指迁移分片等 正常情况为 0
"unassign": "0", #unassigned_shards 未分配的分片 正常情况为 0
"pri": "3699", #active_primary_shards 存活的主分片数量 正常情况下 shards的数量是pri的两倍
"shards": "4343", #active_shards 存活的分片数量
"active_shards_percent": "100.0%", #正常分片百分比 正常情况为 100%
"max_task_wait_time": "-", #任务最长等待时间
"epoch": "1696748727",
"timestamp": "07:05:27"
}
模块运营ES集群11个节点,6个hot节点16C64G配置,5个warm节点4C16G。集群因为有部门内其他项目也在用,跟我们业务相关主要索引在8+个以上,例如模块运营,
主要业务索引:
菜单访问记录按天 mcs_menu_user_access-yyyyMMdd,
菜单访问统计按月 mcs_menu_user_access_aggregation-yyyyMM,
菜单访问小时统计按月 mcs_menu_user_access_aggregation_hour-yyyyMM,
事件访问明细索引 mcs_menu_user_access_action-yyyyMM
数据量计算:前提:公司菜单总数在2300个左右,公司员工访问总人数在5-6w左右
- 菜单访问记录索引mcs_menu_user_access,6个分片,没有副本。每日数据增量在600w左右,一个月30天数据量在2亿左右。单索引大概4G,一个月所有该索引大概120G
- 菜单访问统计按天索引mcs_menu_user_access_aggregation,6个分片,没有副本。一个月也在1300w左右,单索引一个月大概15G的数据量
- 菜单访问小时统计按月索引mcs_menu_user_access_aggregation_hour ,6个分片,没有副本。一个月40002左右的数据。一个月所有该索引大概30G
- 事件访问明细按月索引 mcs_menu_user_access_action ,12个分片,没有副本。一个月数据量大概在5亿作业,占用磁盘大概在400G
索引增量:根据日期,有的按月有的按天递增,每月递增33+索引以上。
菜单访问相关的数据量没那么大,索引分片在6个分片,为节省磁盘和性能没有副本
事件访问明细索引数据量笔记打,索引分片在12个,一样没有副本
保存近1年的数据,1年以前的数据删除。
这一年的数据做采取了冷热分离机制,热数据存储到SSD,提高检索效率;冷数据定期进行shrink操作,以缩减存储;近6个月的数据在hot节点,前6个月的数据移到warm节点
冷热数据分离了解么
ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储数据。若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。为了解决控制成本的前提下读写性能问题,Elasticsearch冷热分离架构应运而生。
冷数据索引:查询频率低,基本无写入,一般为当天或最近2天以前的数据索引
热数据索引:查询频率高,写入压力大,一般为当天数据索引

实现原理
Hot节点设置:索引节点(写节点),同时保持近期频繁使用的索引。 属于IO和CPU密集型操作,建议使用SSD的磁盘类型,保持良好的写性能;节点的数量设置一般是大于等于3个。将节点设置为hot类型:node.attr.box_type: hot
Warm节点设置: 用于不经常访问的read-only索引。由于不经常访问,一般使用普通的磁盘即可。内存、CPU的配置跟Hot节点保持一致即可;节点数量一般也是大于等于3个。将节点设置为warm类型:node.attr.box_type: warm
可以通过两种方式对数据进行冷热的那种处理
1、针对索引设置冷热属性:指定某个索引为热索引,另一个索引为冷索引。通过索引的分布来实现控制数据分布的目的。业务上根据实际情况对索引设置冷热属性,如果按照时间定期处理。
index.routing.allocation.include.{attribute}表示索引可以分配在包含多个值中其中一个的节点上。index.routing.allocation.require.{attribute}表示索引要分配在包含索引指定值的节点上(通常一般设置一个值)。index.routing.allocation.exclude.{attribute}表示索引只能分配在不包含所有指定值的节点上。
2、通过索引生命周期管理,ES (版本>=6.6) 提供了索引生命周期管理功能。索引生命周期管理可以通过 API 或者 kibana 界面配置,详情可参考 index-lifecycle-management。使用索引生命周期管理,可以实现索引数据的自动滚动跟过期,并结合冷热分离架构进行数据的降冷跟删除。 一般通过kibana界面去创建代理任务进行配置,实现索引的动态管理,索引的生命周期被分为:Hot phrase,Warm phase, Cold phase,Delete phrase四个阶段
- Hot phrase: 该阶段可以根据索引的文档数,大小,时长决定是否调用rollover API来滚动索引
- Warm phrase: 当一个索引在Hot phrase被roll over后便会进入Warm phrase,进入该阶段的索引会被设置为read-only, 用户可以为这个索引设置要使用的attribute, 如对于冷热分离策略,这里可以选择temperature: warm属性。另外还可以对索引进行forceMerge, shrink等操作
- Cold phrase: 可以设置当索引rollover一段时间后进入cold阶段,这个阶段也可以设置一个属性。从冷热分离架构可以看出冷热属性是具备扩展性的,不仅可以指定hot, warm, 也可以扩展增加hot, warm, cold, freeze等多个冷热属性。如果想使用三层的冷热分离的话这里可以指定为temperature: cold, 此处还支持对索引的freeze操作
- Delete phrase: 可以设置索引rollover一段时间后进入delete阶段,进入该阶段的索引会自动被删除。
分片不均衡原因&解决方案
可能存在的部分原因有以下几种:
- Shard设置不合理:大多数负载不均问题是由于shard设置不合理导致,建议优先排查。
- Segment大小不均
- 存在典型的冷热数据需求场景。说明:例如查询中添加了routing或查询频率较高的热点数据,则必然导致数据出现负载不均。
- 没有释放长连接,导致流量不均。说明:该问题时常暴露于采用负载均衡及多可用区架构部署时。
解决方案
- 方案一:手动移动分片
例如移动node-1的分片0到node-4
curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[{
"move":{
"index":"indexName", # 索引名
"shard": 0, # 需要移动的分片
"from_node":"node-1", # 从哪个节点移出来
"to_node":"node-4" # 需要移到哪个节点
}}]}'
优点:操作简单,恢复时间短;不必修改master node的配置,master node长期负载后高
缺点:索引大,移动时有很高的IO,索引容易损坏,需要做备份,不能解决master node既是数据节点又是负载均衡转发器的问题
【注意】分片和副本无法移动到同一个节点
- 方案二:重建索引,从另外一个集群导入
删除原来的索引,重新建立索引,;利用elasticsearch dump等工具从另一个集群中把数据导入到新的索引中
优点:可以重新配置master node和data node,主从负载均匀
缺点:费时间,容易数据丢失,需要验证数据的一致性
- 方案三:配置平衡参数
使用命令恢复平衡
PUT_cluster/settings
{
"persistent": {
"cluster.routing.rebalance.enable": "all"
}
}
解决Elasticsearch分片未分配的问题
原因
出现这个问题的原因是原有分片未正常关闭和清理,所以当分片要重新分配回出问题节点的时候没有办法获得分片锁。
这不会造成分片数据丢失,只需要重新触发一下分配。
unassigned 分片问题可能的原因如下:
- INDEX_CREATED: 由于创建索引的API导致未分配。
- CLUSTER_RECOVERED: 由于完全集群恢复导致未分配。
- INDEX_REOPENED: 由于打开open或关闭close一个索引导致未分配。
- DANGLING_INDEX_IMPORTED: 由于导入dangling索引的结果导致未分配。
- NEW_INDEX_RESTORED: 由于恢复到新索引导致未分配。
- EXISTING_INDEX_RESTORED: 由于恢复到已关闭的索引导致未分配。
- REPLICA_ADDED: 由于显式添加副本分片导致未分配。
- ALLOCATION_FAILED: 由于分片分配失败导致未分配。
- NODE_LEFT: 由于承载该分片的节点离开集群导致未分配。
- REINITIALIZED: 由于当分片从开始移动到初始化时导致未分配(例如,使用影子shadow副本分片)。
- REROUTE_CANCELLED: 作为显式取消重新路由命令的结果取消分配。
- REALLOCATED_REPLICA: 确定更好的副本位置被标定使用,导致现有的副本分配被取消,出现未分配。
解决方案如下:
执行修复命令: POST /_cluster/reroute?retry_failed
Elasticsearch 索引文档的过程
想了解ES的底层原理,不只是关注业务本身。
这里的索引文档应该理解为文档写入ES,创建索引的过程。这里说下单文档索引的过程
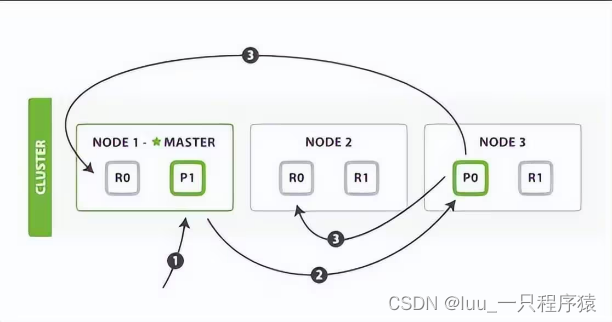
- 客户发送请求,向ES集群某节点写入数据。如果没有指定路由/协调节点,请求的节点作为协调节点
- 第1个节点(协调节点)接受到请求后,使用文档_id 来确定文档属于哪个分片,计算分片的算法是:shard = hash(routing) % number_of_primary_shards,routing默认是文档_id,也可以自定义routing。确定分片之后,请求会被转到另外的节点,假定节点 3。因此分片 0 的主分片分配到节点3上面
- 节点 3 在主分片上执行写操作,如果成功,则将请求并行转发到节点 1和节点 2 的副本分片上,等待结果返回。所有的副本分片都报告成功,节点 3 将向协调节点(节点 1)报告成功,节点 1 向请求客户端报告写入成功。
Elasticsearch 写入数据的过程
es的写入过程还是很复杂的,整个过程中还涉及到refresh刷新、强制flush一些操作,画个图可能更好理解一些
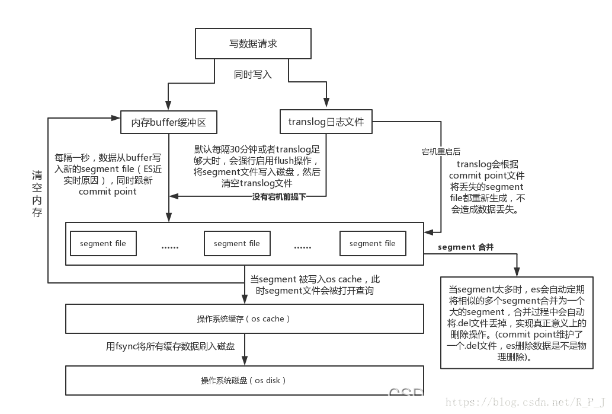
添加doc的流程:
- 将数据写入buffer缓冲区域,同步会将记录写入到translog日志文件中,之后返回结果。写到buffer缓冲区中的数据是还不能被search到的,可以通过get得到数据
- 之后buffer缓冲区中的数据,在空间被占用或者通过refresh近实时性的刷新操作,将数据刷到segment段中之后,这个时候才能被search
- 之后通过fsync操作将segment中的数据写入到磁盘
- 还会清空buffer缓冲区,等待接收新的数据
translog 和 flush操作的作用
translog文件:为了保证数据安全而存在的机制,因为文档doc刚开始是写到内存中的,还没有入到磁盘。如果此时服务器宕机那么数据就丢失了。引入translog,文档写入buffer时是同时写入到translog文件中的,这个是落盘的。这样就能防止数据丢失,并且translog是追加的方式,因此性能比较好
flush操作:每隔30分钟或者translog日志文件达到一定大小(默认512M)的时候,就会触发一次flush操作,此时ES会执行一次flush操作先将segment刷到磁盘。原有translog文件已经落盘,会生成一份新的translog日志文件
近实时性-refresh操作
es接收数据请求时先存入buffer缓冲区中,默认每隔一秒会从buffer中将数据写入segment中,这个过程叫做refresh;
当一个文档写入Lucene后是不能被立即查询到的,Elasticsearch提供了一个refresh操作,会定时地为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由refresh_interval参数控制,默认为1s, 当然还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。
产生的问题
于是这个过程中就产生了大量的segment,数量越多就会占用更多的内存,并且还会影响查询的效率,因为查询数据是要具体到分片上去的,其实就是遍历segment文件进行查询,segment越多就会影响性能
merge操作
由于refresh操作1秒钟执行一次,每次都会产生一个segment段,会产生大量的segment段。这对于查询性能来说影响很大,并且占用空间。因此ES会运行一个任务检测segment,对符合要求的segment段进行合并操作,提高查询速度。用户也可以手动调用_forcemerge API强制合并merge
常用基本调优思路有哪些
设计阶段调优
- 根据业务增量需求,采取基于日期模板创建索引,常用的方式就是基于索引模板在索引数据的时候动态创建索引。获取也可以通过rollover API动态滚动创建索引。rollover API翻滚索引指的就是 对满足特定条件的拥有别名的索引,进行采用旧索引的配置创建新索引,并对将新索引别名下的is_write_index设为true
- 使用别名进行索引管理;
- 每天定时在业务量低的时间点,对索引做force_merge强制合并segment段操作,手动释放磁盘空间;force_merge强制合并是指ES索引文档会产生很多个小segment段,每一个段都会占用cpu资源、句柄、内存等,并且查询的时候要到段上面进行搜索,段越多效率越慢,所以需要进行合并段操作,对这些segment进行合并减少磁盘空间,优化查询效率
- 采取冷热分离机制,热数据存储到SSD,提高检索效率;冷数据定期进行shrink压缩操作,以缩减存储;
- 采取curator进行索引的生命周期管理;
- 仅针对需要分词的字段,合理的设置分词器;
- Mapping阶段充分结合各个字段的属性,是否需要检索、是否需要存储等
写入调优思路
- 写入前副本数设置为 0,设置副本数 number_of_replicas = 0;
- 写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
- 写入过程中:采取 bulk 批量写入;
- 写入后恢复副本数和刷新间隔;
- 尽量使用自动生成的 id。
查询调优思路
- 禁用 wildcard(wildcard 检索可以定义为:支持通配符的模糊检索。类似于mysql的like);
- 禁用批量 terms(成百上千的场景);
- 充分利用倒排索引机制,能 keyword 类型尽量 keyword;
- 数据量大时候,可以先基于时间敲定索引再检索;
- 设置合理的路由机制。