基础概念
什么是Ascend C
Ascend C是CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,最大化匹配用户开发习惯;通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。
使用Ascend C开发自定义算子的优势
- C/C++原语编程,最大化匹配用户的开发习惯
- 编程模型屏蔽硬件差异,编程范式提高开发效率
- 多层级API封装,从简单到灵活,兼顾易用与高效
- 孪生调试,CPU侧模拟NPU侧的行为,可优化在CPU侧调试
昇腾计算架构CANN
CANN 介绍网站:https://www.hiascend.com/software/cann
AI Core是NPU卡的计算核心,NPU内部有多个AI Core。每个AI Core相当于多核CPU中的一个核心
SIMD
SIMD,也就是单指令多数据计算,一条指令可以处理多个数据:Ascend C编程API主要是向量计算API和矩阵运算API,计算API都是SIMD样式
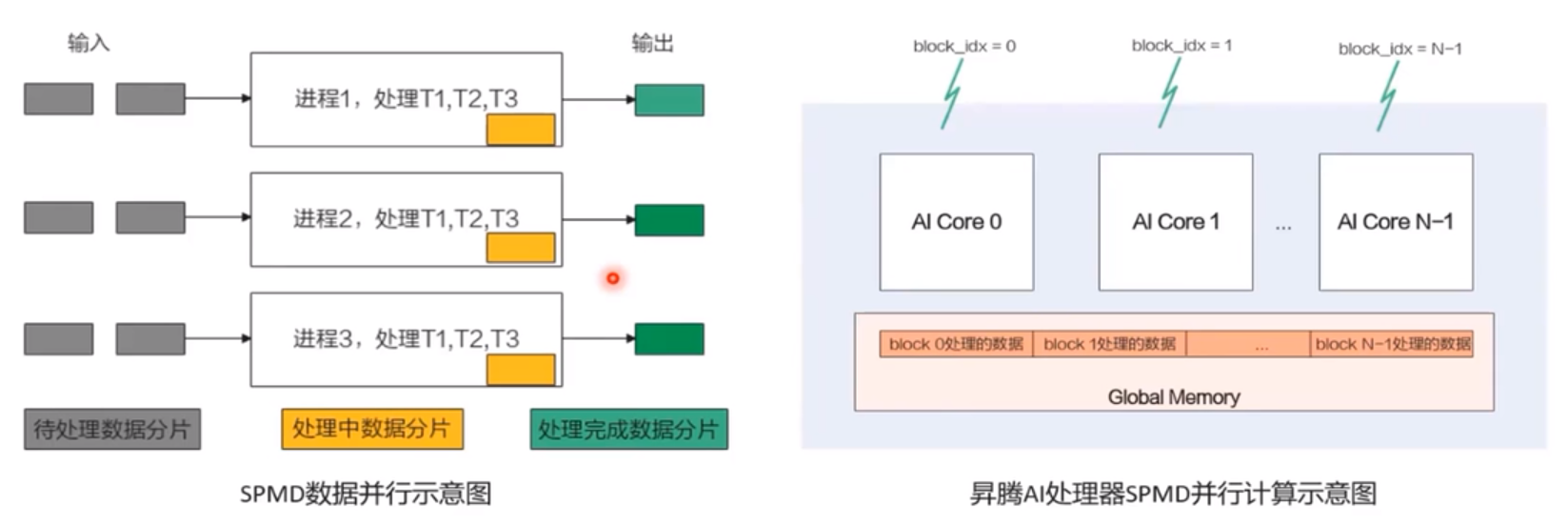
并行计算之SPMD数据并行与流线型并行
SPMD数据并行原理
- 启动一组进程,他们运行的相同程序
- 把待处理数据切分,把切分后数据分片分发给不同进程处理
- 每个进程对自己的数据分片进行3个任务T1、T2、T3的处理
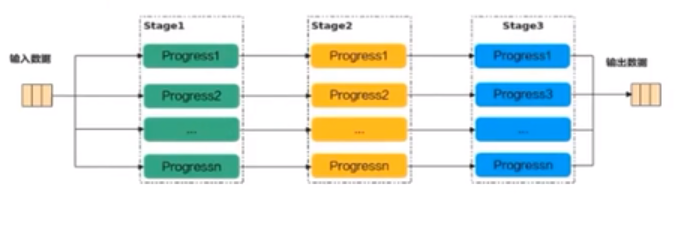
流水线并行原理
- 启动一组进程
- 对数据进行切分
- 每个进程都处理所有的数据切片,对输入数据分片只做一个任务的处理
Ascend C编程模型与范式
并行计算架构抽象
使用Ascend C编程语言开发的算子运行在AI Core上,AI Core是昇腾AI处理器中的计算核心
一个AI处理器内部有多个AI Core,AI Core中包含计算单元、存储单元、搬运单元等核心组件
计算单元包括了三种基础计算资源
- Scalar计算单元:执行地址计算、循环控制等标量计算工作,并把向量计算、矩阵计算、数据半圆、同步指令发射给对应单元执行
- Cube计算单元:负责执行矩阵运算
- Vector计算单元:负责执行向量计算
搬运单元负责在Global Memory和Local Memory之间搬运数据,包含搬运单元MTE(Memory Transfer Engine,数据搬入单元),MTE3(数据搬出单元)
存储单元为AI Core的内部存储,统称为Local Memory与此相对应,AI Core的外部存储称之为Global Memory
异步指令流
Scalar计算单元读取指令序列,并把向量计算、矩阵计算、数据搬运指令发射给对应单元的指令队列,向量计算单元、矩阵计算单元、数据搬运单元异步的并行执行接收到的指令
同步信号流
指令间可能存在依赖关系,为了保证不同指令队列间的指令按照正确的逻辑关系执行,Scalar计算单元也会给对应单元下发同步指令
计算数据流
DMA搬入单元把数据搬运到Local Memory,Vector/Cube计算单元完成数据计算,并把计算结构写回Local Memory,DMA搬出单元把处理好的数据搬运回Global Memory
SPMD编程模型介绍
Ascend C算子编程是SPMD的编程,将需要处理的数据拆分并行分布在多个计算核心上运行多个AI Core共享相同的指令代码,每个核上的运行实例唯一的区别是block_idx不同block的类似于进程,block_idx就是标识进程唯一性的进程ID,编程中使用函数GetBlockIdx()获取ID
核函数编写及调用
核函数(Kernel Function)是Acend C算子设备侧的入口。Ascend C允许用户使用核函数这种C/C++函数的语法扩展来管理设备侧的运行代码,用户在核函数中实现算子逻辑的编写,例如自定义算子类及其成员函数以实现该算子的所有功能。核函数是主机侧和设备侧连接的桥梁
核函数是直接在设备侧执行的代码。在核函数中,需要为在一个核上执行的代码规定要进行的数据访问和计算操作,SPMD编程模型允许核函数调用时,多个核并行地执行同一个计算任务。
使用函数类型限定符
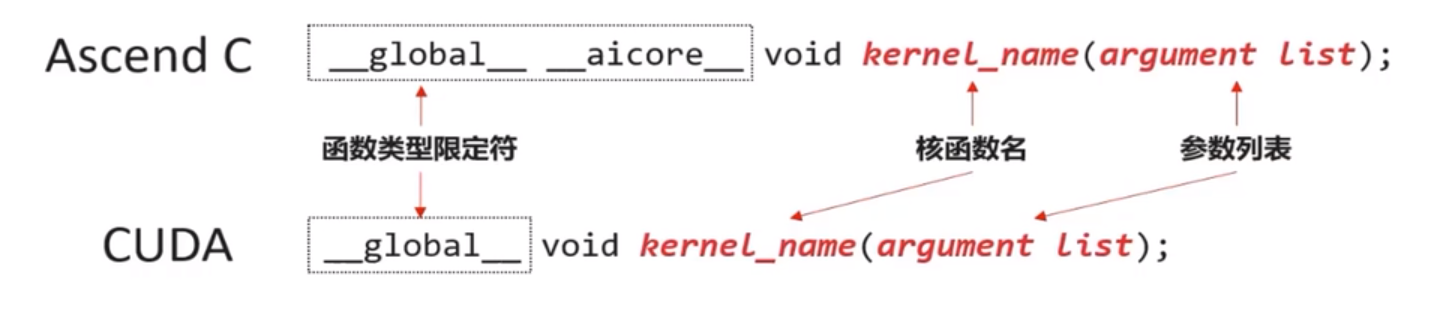
除了需要按照C/C++函数声明的方式定义核函数之外,还要为核函数加上额外的函数类型限定符,包含__global__和__aicore__
使用__global__函数类型限定符来标识它是一个核函数,可以被<<<…>>>调用;使用__aicore__函数类型限定符来标识该函数在设备侧AI Core上执行
__gloabl__ __aircore__ void kernel_name(argument list);

使用变量类型限定符
为了方便:指针入参变量统一的类型定义为__gm__uint8_t*
用户可统一使用uint8_t类型的指针,并在使用时转化为实际的指针类型;亦可直接传入实际的指针类型

规则或建议
- 核函数必须具有void返回类型
- 仅支持入参为指针类型或C/C++内置数据类型(Primitive Data Types),如:half* s0、flat* s1、int32_t c
- 提供了一个封装的宏GM_ADDR来避免过长的函数入参列表
#define GM_ADDR __gm__ unit8_t* __restrict__
调用核函数
核函数的调用语句是C/C++函数调用语句的一种扩展
常见的C/C++函数调用方式是如下的形式:
function_name(argument list);
核函数使用内部调用符<<<…>>>这种语法形式,来规定核函数的执行配置:
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);
注:内核调用符仅可在NPU模式下编译时调用,CPU模式下编译无法识别该符号
blocakdim,规定了核函数将会在几个核上执行,每个执行该核函数的核会被分配一个逻辑ID,表现为内置变量block_idx,编号从0开始,可为不同的逻辑核定义不同的行为,可以在算子实现中使用GetBlockIDX()函数来获得
l2ctl,保留函数,展示设置为固定值nullptr
stream:类型为aclrtStream,stream是一个任务队列,应用程序通过stream来管理任务的并行
使用内核调用符<<<…>>>调用核函数:
HelloWorld<<<8, nullptr, stream>>>(fooDevice));
blockDim设置为8,表示在8个核上调用了HelloWorld核函数,每个核都会独立且并行地执行该核函数Stream可以通过aclrtCreateStream来创建,它的作用是在当前进程或线程中显式创建一个aclrtStream argument list设置为cooDevice这1个入参
核函数的调用是异步的,核函数的调用结束后,控制权立刻返回给主机侧
强制主机侧程序等待所有核函数执行完毕的API(阻塞应用程序运行,直到指定Stream中的所有任务都完成,同步接口)为aclrtSynchronizeStream
aclError aclrtSynchronizeStream(aclrtStream stream);
编程API介绍
Ascend C算子采用标准C++语法和一组类库API进行编程
计算类API:标量计算API、向量计算API、矩阵计算API、分别实现调用Scalar计算单元、Vector计算单元、Cube计算单元
数据搬运API:基于Local Memory数据进行计算、数据需要先从Gloabl Memory搬运至Local Memory,再使用计算接口完成计算,最后从Local Memory搬出至Gloabl Memory。比如DataCopy接口
内存管理API:用于分配管理内存,比如AllocTensor、FreeTensor接口
任务同步API:完成任务间的通信和同步,比如EnQue、DeQue接口。不同的指令异步并行执行,为了保证不同指令队列间的指令按照正确的逻辑关系执行,需要向不同的组件发送同步指令
Ascend C API用于计算的基本数据类型都是Tensor:GlobalTensor和LocalTensor
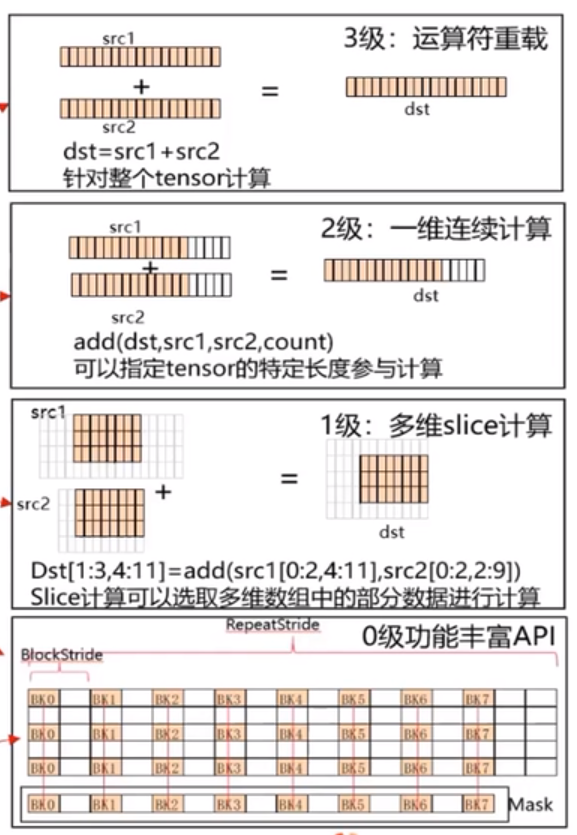
4级API定义
4级API定义:API根据用户使用的场景分为4级
3级API,运算符重载,支持+, - ,* ,/ ,= ,| ,& ,^ ,> ,< ,>- ,<= 实现计算的简单表述,类似dst=src1+src2
2级连续计算API,类似Add(dst,src1,src2,count),针对源操作数的连续COUNT个数据进行计算连续写入目的操作数,解决一维tensor的连续count个数据的计算问题
1级slice计算API,解决多维数据中的切片计算问题(开发中)
0级丰富功能计算API,可以完整发挥硬件优势的计算API,该功能可以充分发挥CANN系列芯片的强大指令,支持对每个操作数的repeattimes,repetstride,MASK的操作。调用类似:Add(dst,src1,src2,repeatTimes,repeatParams);
流水编程范式介绍
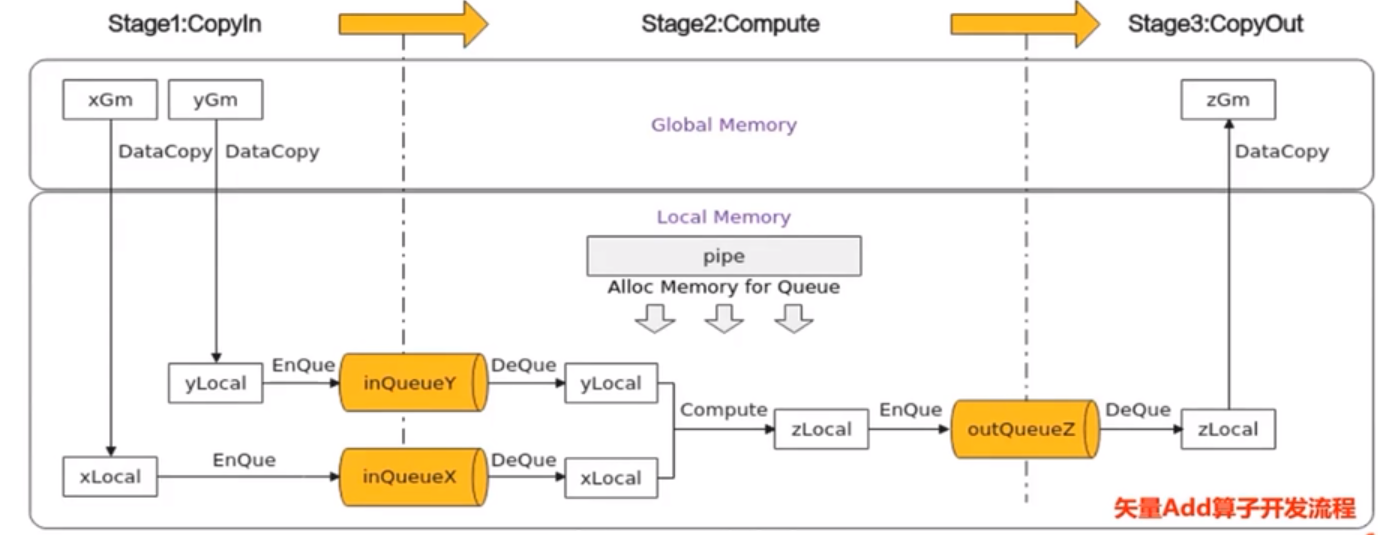
Ascend C编程范式把算子内部的处理程序,分成多个流水任务(Stage),以张量(Tensor)为数据载体,以队列(Queue)进行任务之间的通信与同步,以内存管理模块(Pipe)管理任务间的通信内存。
- 快速开发编程的固定步骤
- 统一代码框架的开发捷径
- 使用者总结出的开发经验
- 面向特定场景的编程思想
- 定制化的方法论开发体验
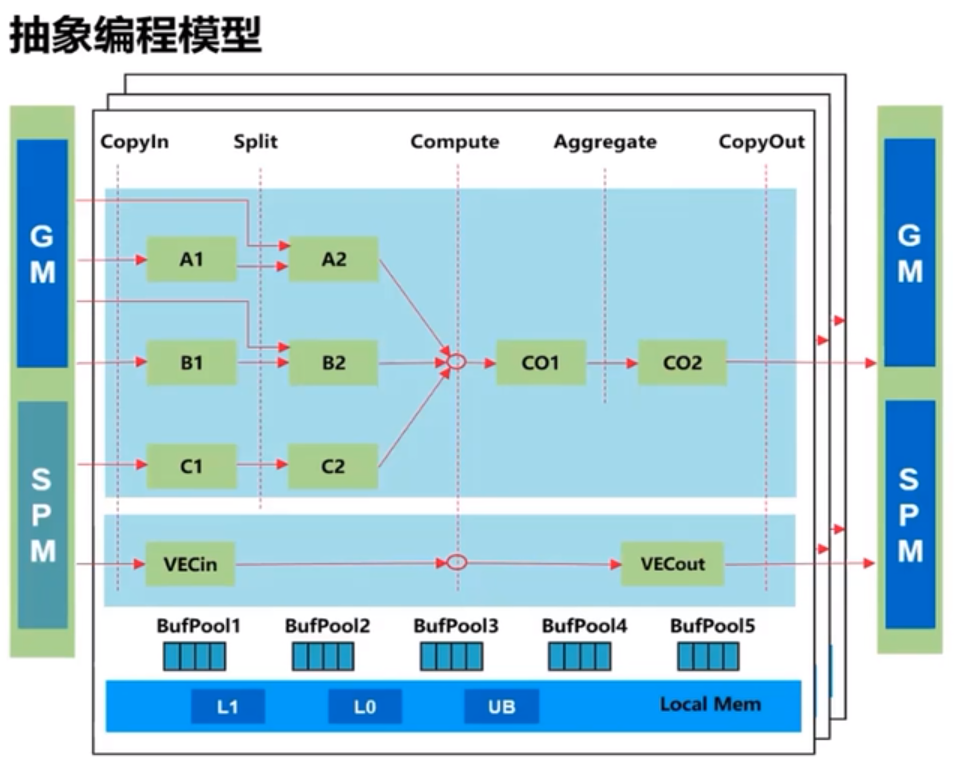
抽象编程模型“TPIPE并行计算"
- 针对各代Davinci芯片的复杂数据流,根据实际计算需求,抽象出并行编程范式,简化流水并行
- Ascend C的并行编程式范式核心要素
- 一组并行计算任务
- 通过队列实现任务之间的通信和同步
- 程序员自主表达对并行计算任务和资源的调度
- 典型的计算范式
- 基本的矢量编程范式:计算任务分为CopyIn,Compute,CopyOut
- 基本的矩阵编程范式:计算任务分为CopyIn,Compute,Aggregate,CopyOut
- 复杂的矢量/矩阵编程范式,通过将矢量/矩阵的Out/ln组合在一起的方式来实现复杂计算数据流
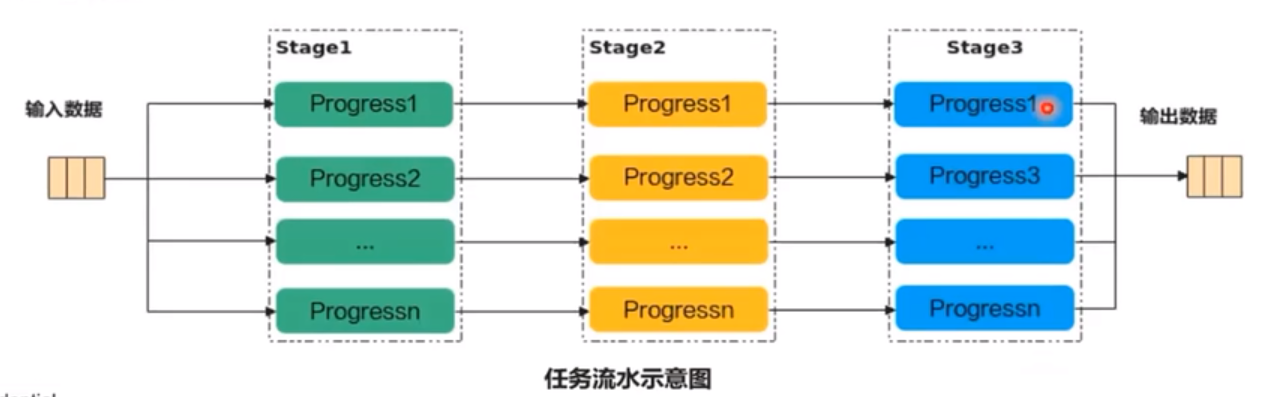
流水任务
流水任务(Stage)指的是单核处理程序中主程序调度的并行任务。
在核函数内部,可以通过流水任务实现数据的并行处理来提升性能
举例来说,单核处理程序的功能可以拆分为3个流水任务:Stage1、Stage2、Stage3,每个任务专注数据切片的处理。Stage间的剪头表达数据间的依赖,比如Stage1处理完Progress1之后,Stage2才能对Proress1进行处理。
若Progres的n=3,待处理的数据被切分成3片,对于同一片数据,Stage1、Stage2、Stage3之间的处理具有依赖关系,需要串行处理;不同的数据切片,同一时间点,可以有多个流水任务Stage在并行处理,由此达到任务并行、提升性能的目的
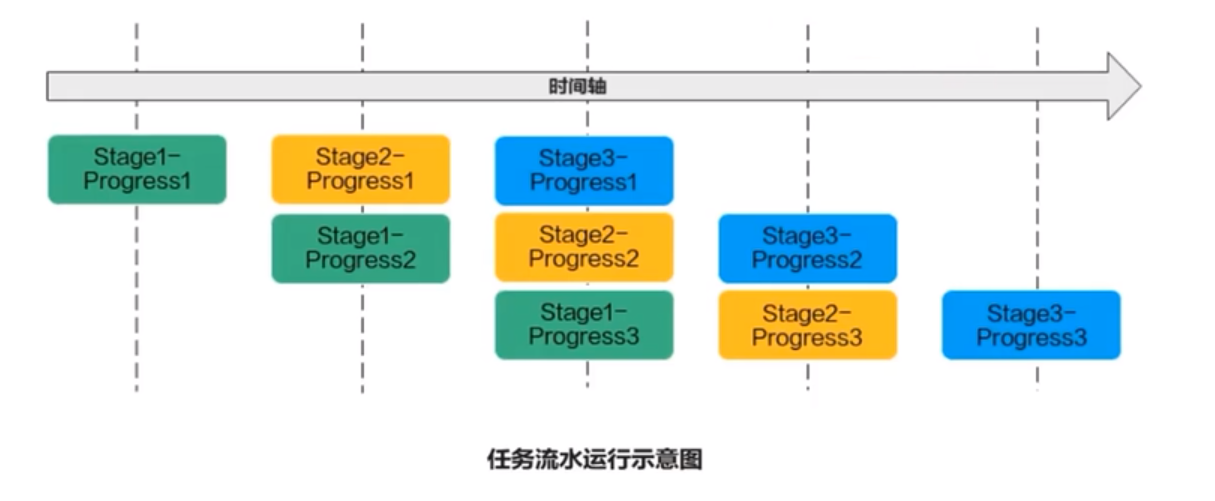
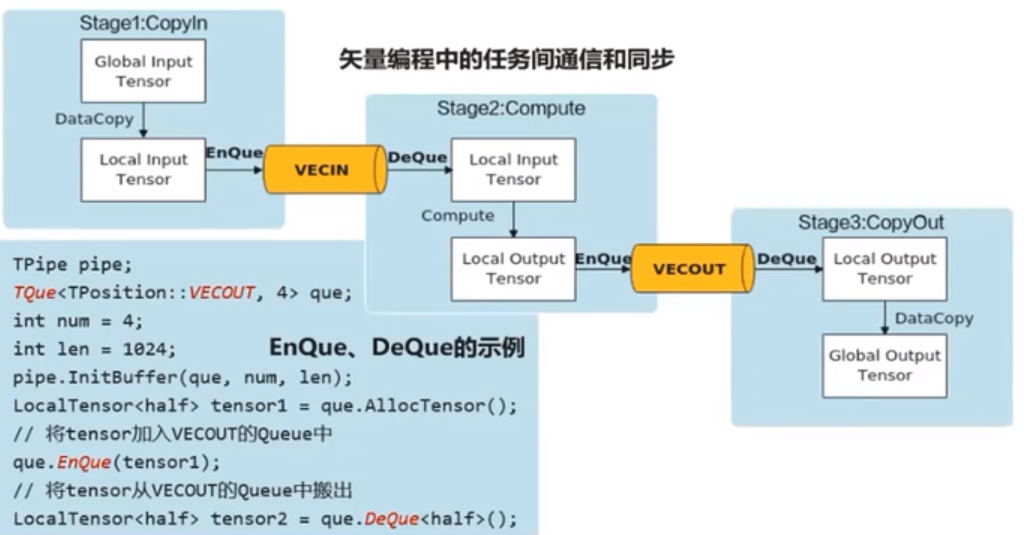
任务间通信和同步
数据通信与同步的管理者
Ascend C中使用Queue队列完成任务之间的数据通信和同步,Queue提供了EnQue、DeQue等基础API
Queue队列管理NPU上不同层级的物理内存时,用一种抽象的逻辑位置(QuePosition)来表达各个级别的存储(Storage Scope),代替了片上物理存储的概念,开发者无需感知硬件架构
矢量编程中Queue类型(逻辑位置)包括:VECIN、VECOUT
数据的载体
Ascend C使用GlobalTensor和LocalTensor作为数据的基本操作单元,它是各种指令API直接调用的对象,也是数据的载体
矢量编程任务间通信和任务
矢量编程中的逻辑位置(QuePosition):搬入数据的存放位置:VECIN、搬出数据的存放位置:VECOUT
矢量编程主要分为CopyIn、Compute、CopyOut三个任务
- CopyIn任务中将输入数据从GlobalTensor搬运至LocalTensor后,需要使用EnQue将LocalTensor放入VECIN的Queue中
- Compute任务等待VECIN的Queue中LocalTensor出队之后才可以进行矢量计算,计算完成后使用EnQue将计算结果LocalTensor放入VECOUT的Queue中
- CopyOut任务等待VECOUT的Queue中Localtensor出队,再将其拷贝至GlobalTensor
Stage1:CopyIn任务
使用DataCopy接口将GlobalTensor拷贝纸LocalTensor
使用EnQue将LocalTensor放入VECIN的Queue中
Stage2:Compute任务
使用DeQue从VECIN中取出LocalTensor
使用Ascend C指令API完成矢量计算:Add
使用EnQue将结果LocalTensor放入VECOUT的Queue中
Stage3:CopyOut任务
使用DeQue接口从VECOUT的Queue中取出LocalTensor
使用DataCopy接口将LocalTensor拷贝至GlobalTensor
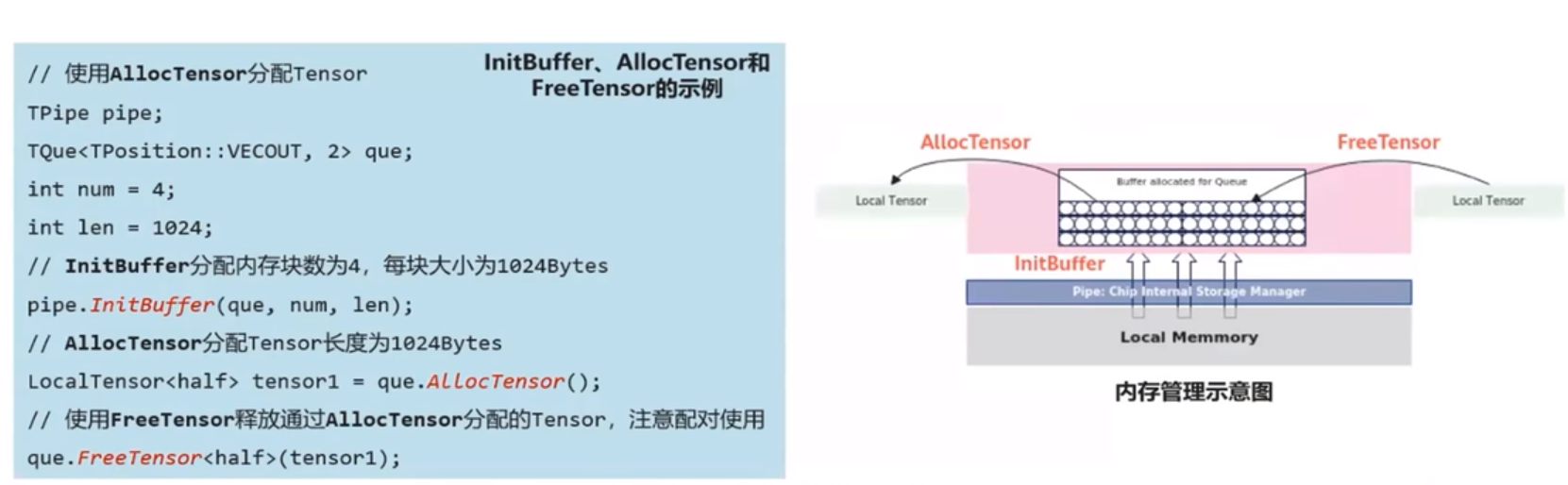
内存管理
任务见数据传递使用到的内存统一由内存管理模块Pipe进行管理
Pipe作为片上内存管理者,通过InitBuffer接口对外提供Queue内存初始化功能,开发者可以通过该接口为指定的Queue分配内存
Queue队列内存初始化完成后,需要使用内存时,通过调用AllocTensor来为LocalTensor分配内存给Tensor,当创建的LocalTensor完成相关计算无需再使用时,再调用FreeTensor来回收LocalTensor的内存
临时变量内存管理
编程过程中使用到的临时变量内存同样通过Pipe进行管理。临时变量可以使用TBuf数据结构来申请指定QuePosition上的存储空间,并使用Get()来将分配到的存储空间分配给新的LocalTensor从TBuf上获取全部长度,或者获取指定长度的LocalTensor
LocalTensor<T> Get<T>();
LocalTensor<T> Get<T>(uint32_t len);
Tbuf及Get接口的示例
//为TBuf初始化分配内存,分配内存长度为1024字节
TPipe pipe;
TBuf<TPosition::VECIN> calcBuf; //模板参数为QuePosition中的VECIN类型
uint32_t byteLen = 1024;
pipe.InitBuffer(calcBuf,byteLen);
//从calcBuf获取Tensor,Tensor为pipe分配的所有内存大小,为1024字节
LocalTensor<int32_t> tempTensor1 = calcBuf.Get<int32_t>();
//从calcBuf获取Tensor,Tensor为128个int32_t类型元素的内存大小,为512字节
LocalTensro<int32_t> tempTensor1 = calcBuf.Get<int32_t>(128);
使用TBuf申请的内存空间只能参与计算,无法执行Queue队列的入队出队操作
Ascend C矢量编程
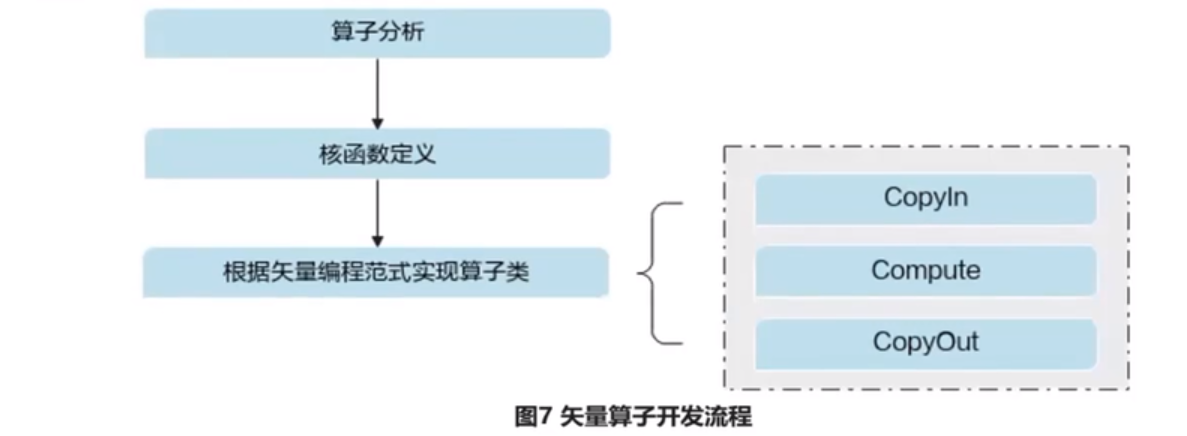
算子分析
开发流程
算子分析:分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的Ascend接口
核函数定义:定义Ascend算子入口函数
根据矢量编程范式实现算子类:完成核函数的内部实现
以ElemWise(ADD)算子为,数学公式 z ⃗ = x ⃗ + y ⃗ \vec{z}=\vec{x}+\vec{y} z=x+y,为简单起见,设定张量x,y,z为固定shape(8,2048),数据类型dtype为half类型,数据排布类型format为ND,核函数名称为add_custom
算子分析
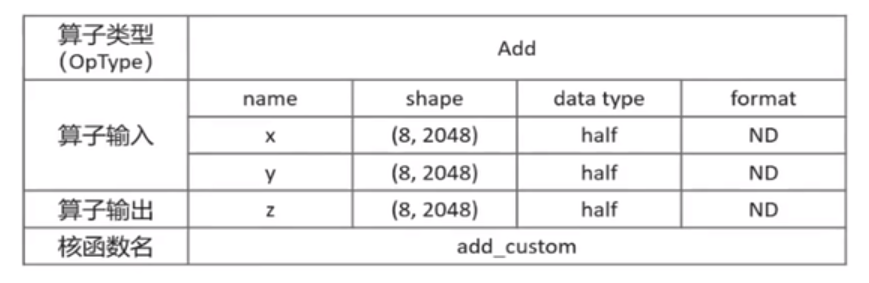
明确算子的数学表达式及计算逻辑
Add算子的数学表达式为
z
⃗
=
x
⃗
+
y
⃗
\vec{z}=\vec{x}+\vec{y}
z=x+y,计算逻辑:输入数据需要先搬入到片上存储,然后使用计算接口完成两个加法运算,得到最终结果,再搬出到外部存储
明确输入输出
Add算子有两个输入:
x
⃗
\vec{x}
x与
v
e
c
y
vec{y}
vecy,输出为
v
e
c
z
vec{z}
vecz,输入数据类型为half,输出数据类型与输入数据类型相同。输入支持固定shape(8,2048),输出shape与输入shape相同,输入数据排布类型为ND
确定核函数名称和参数
自定义核函数明,如add_custom,根据输入输出,确定核函数有3个入参x,y,z
x,y为输入在GlobalMemory上的内存地址,z为输出在globalMemory上的内存地址
确定算子实现所需接口
涉及内外部存储间的数据搬运,使用数据搬移接口:DataCopy实现
涉及矢量计算的加法操作,使用矢量双目指令:Add实现
使用到LocalTensor,使用Queue队列管理,会使用到Enque,Deque等接口。
算子实现
核函数定义
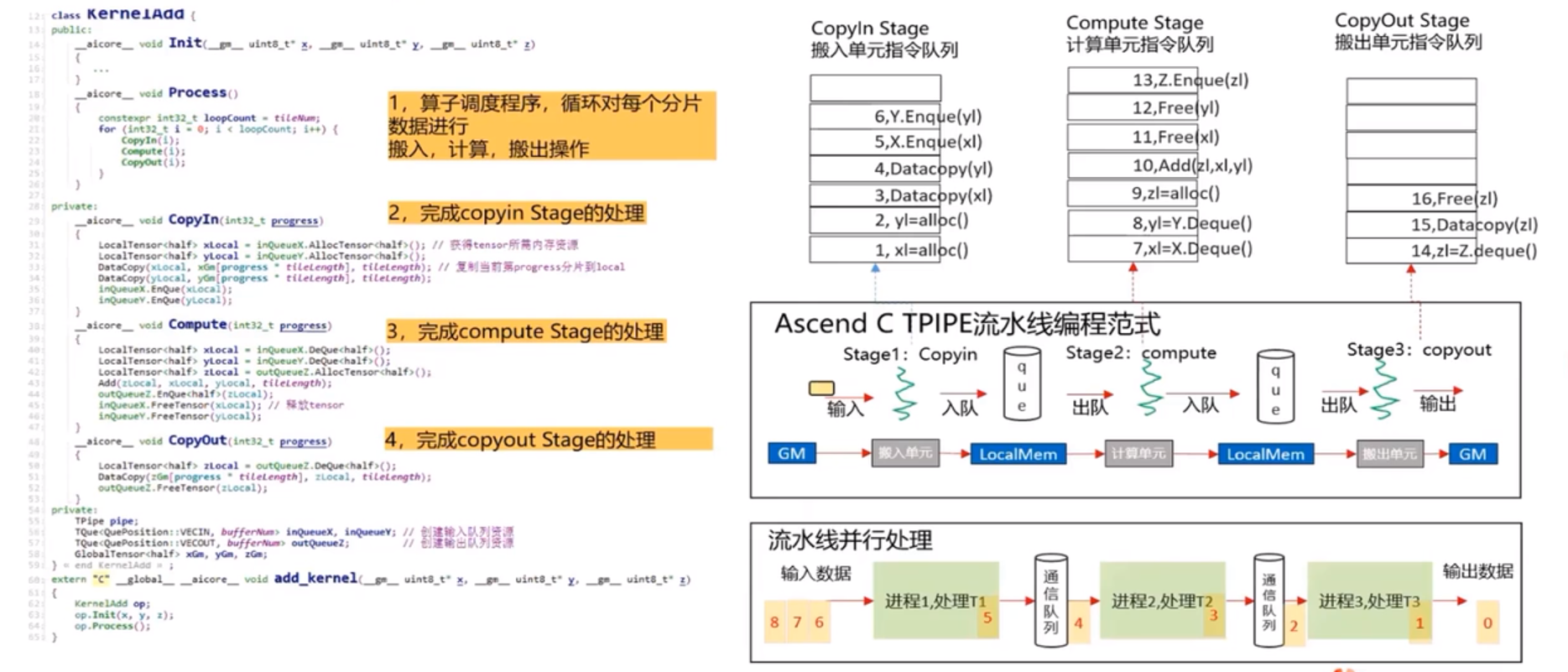
在add_custom核函数的实现中示例化KernelAdd算子类,调用Init()函数完成内存初始化,调用Process()函数完成核心逻辑
注:算子类和成员函数名无特殊要求,开发者可根据自身的C/C++编码习惯,决定核函数中的具体实现。
// implementation of kenel function
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z)
{
kernelAdd op;
op.Init(x,y,z);
op.Process();
}
对于核函数的调用,使用内置宏__CCE_KT_TEST__来标识<<<…>>>仅在NPU模式下才会编译到(CPU模式g++没有<<<…>>>的表达),对核函数的调用进行封装,可以在封装函数中补充其他逻辑,这里仅展示对于核函数的调用
#ifndef __CCE_KT_TEST__
// call of kernel function
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z)
{
add_custom<<<blockDim, l2ctrl, stream>>>(x,y,z);
}
算子类实现
CopyIn任务:将Global Memory上的输入Tensor xGm和yGm搬运至Local Memory,分别存储在xlocal,ylocal
Compute任务:对xLocal,yLocal执行加法操作,计算结果存储在zlocal中
CopyOut任务:将输出数据从zlocal搬运至Global Memory上的输出tensor zGm中
CopyIn.Compute任务间通过VECIN队列和inQueueX,inQueueY进行通信和同步
Compute,CopyOut任务间通过VECOUT和outQueueZ进行通信和同步
pipe内存管理对象对任务间交互使用到的内存、临时变量是用到的内存进行统一管理
向量加法z=x+y 代码样例 TPIPE流水式编程范式
算子类实现
算子类类名: KernelAdd
初始化函数Init()和核心处理函数Process()
三个流水任务:CopyIn(),Compute(),CopyOut()
Process的含义
TQue模板的BUFFER)NUM的含义:
该Queue的深度,double buffer优化技巧
class KernelAdd{
public:
__aicore__ inline KernelAdd()
//初始化函数,完成内存初始化相关操作
__aicore__ inline voide Init(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z){}
// 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn,Compute,CopyOut完成算子逻辑
__aicore__ inline void Process(){}
private:
// 搬入函数,完成CopyIn阶段的处理,被Process函数调用
__aicore__ inline void CopyIn(int32_t process){}
// 计算函数,完成Compute阶段的处理,被Process函数调用
__aicore__ inline void Compute(int32_t process){}
// 搬出函数,完成CopyOut阶段的处理,被Process函数调用
__aicore__ inline void CopyOut(int32_t process){}
private:
// pipe内存管理对象
TPipe pipe;
// 输入数据Queue队列管理对象,QuePosition为VECIN
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY;
// 输出数据Queue队列管理对象,QuePosition为VECOUT
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
// 管理输入输出的Global Memory内存地址的对象,其中xGm,yGm为输入,zGm为输出
GlobalTensor<half> xGm, yGm ,zGm;
};
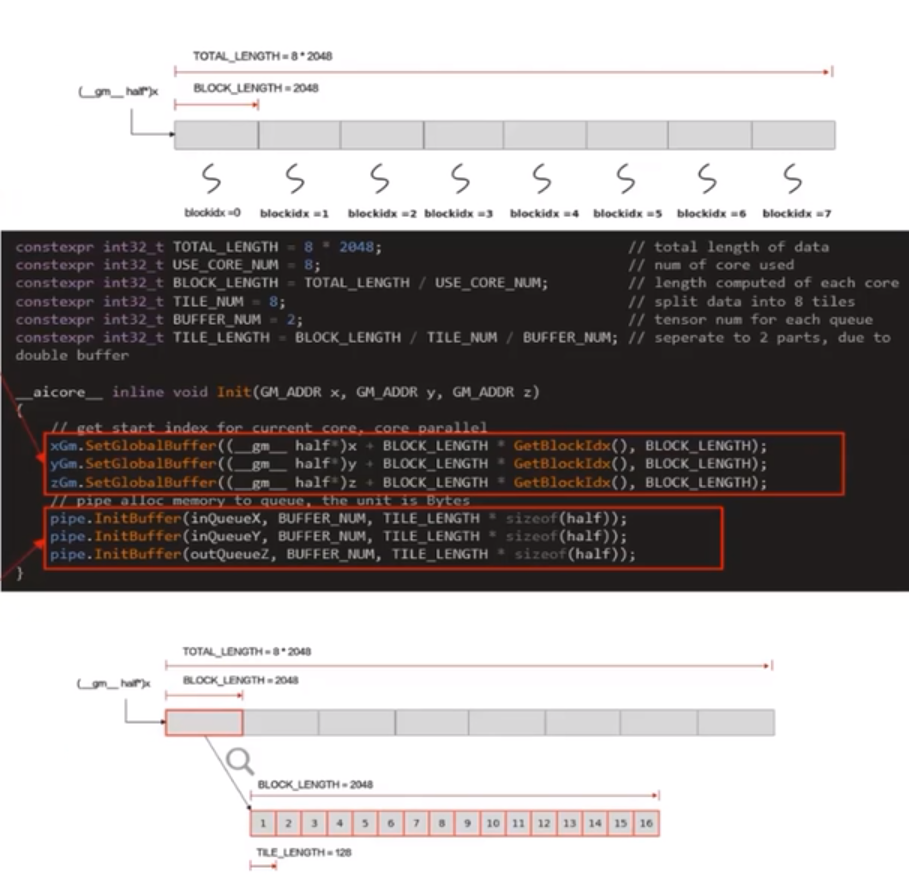
Init()函数实现
使用多核并行计算,需要将数据切片,获取到每个核实际需要处理的在Global Memory上的内存偏移地址
数据整体长度TOTAL_LENGTH为8 * 2048,平均分配到8个核上运行,每个核上处理的数据大小BLOCK_LENGTH为2048,block_idx为核的逻辑ID,(gm half*)x + GetBlockIdx() *
BLOCK_LENGTH即索引为block_idx的核的输入数据在Global Memory上的内存偏移地址
对于单核处理数据,可以进行数据切块(Tiling),将数据切分成8快,切分后的每个数据块再次切分成BUFFER_NUM=2块,可开启double buffer,实现流水线之间的并行
单核需要处理的2048个数据切分成16块,每块TILE_LENGTH=128个数据,Pipe为inQueueX分配了BUFFER_NUM块大小为TITLE_LENGTH * sizeof(half)个字节的内存块,每个内存块能容纳TILE_LENGTH=128个half类型数据
代码示例
constexpr int32_t TOTAL_LENGTH = 8 * 2048; //total length of data
constexpr int32_t USE_CORE_NUM = 8; //num of core used
constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; //length computed of each ccore
constexpr int32_t TILE_NUM = 8; //split data into 8 tiles
constexpr int32_t BUFFER_NUM = 2; //tensor num for each queue
constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; //seperate to 2 parts, due to double buffer
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
//get start index for current core,core parallel
xGm,SetGlobalBuffer((__gm__ half*)x * BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
yGm,SetGlobalBuffer((__gm__ half*)y * BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
zGm,SetGlobalBuffer((__gm__ half*)z * BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
//pipe alloc memory to queue,the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
Process()函数实现
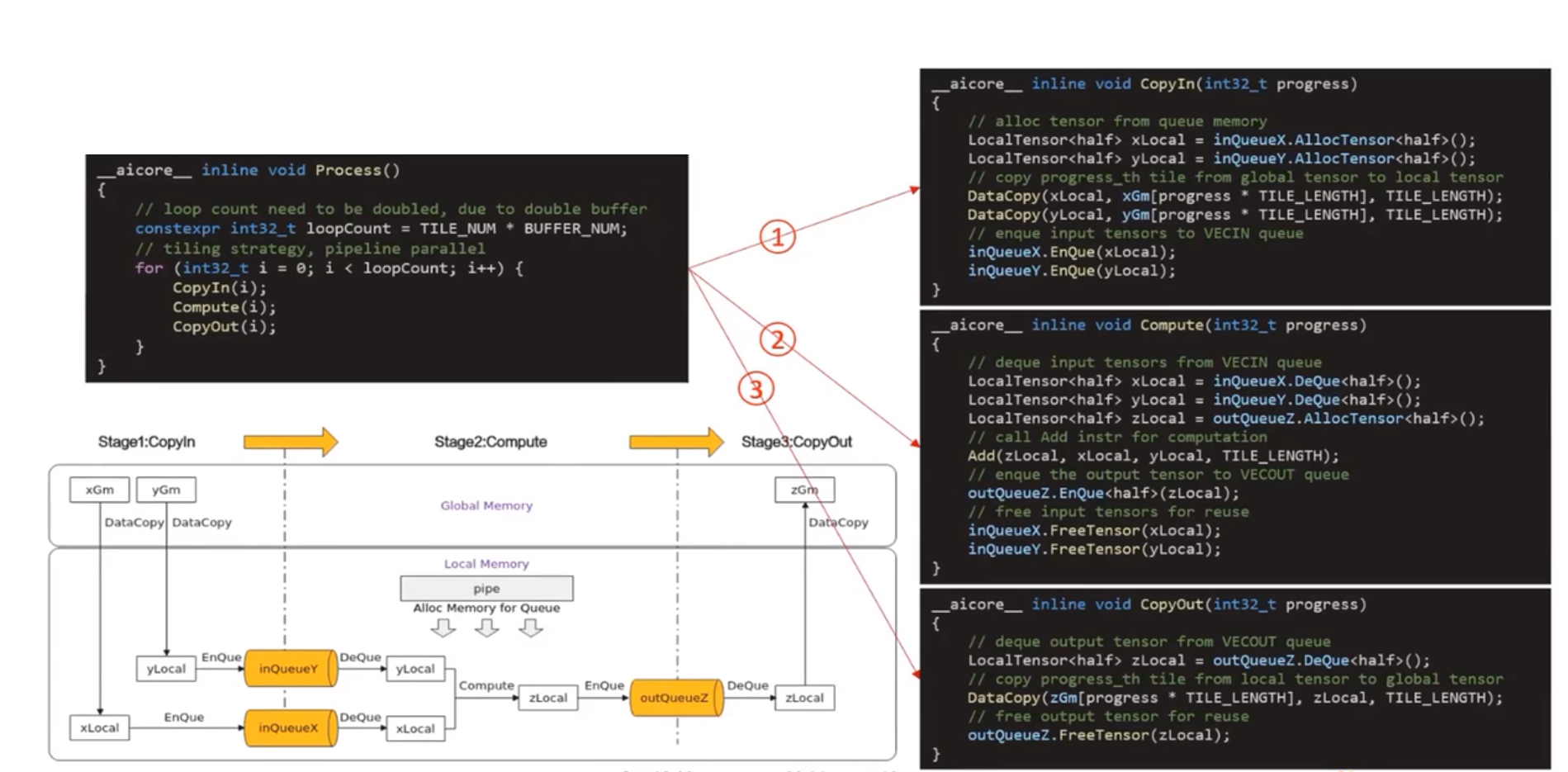
代码示例
__aicore__ inline void Process()
{
// loop count need to be doubled, due to double buffer
constexpr int32_t loopCount = TILE_NUM * BUFFER_BUM;
// tiling strategy, pipeline prallel
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
__aicore__ inline void CopyIn(int32_t progress)
{
// alloc tensor from queue memory
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// copy progress_th tile from global tensor to local tensor
DataCopy(xLocal,xGm[progress * TILE_LENGTH], TILE_LENGTH);
DataCopy(xLocal,yGm[progress * TILE_LENGTH], TILE_LENGTH);
// enque input tensors to VECIN queue
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
__aicore__ inline void Compute(int32_t progress)
{
//dque input tensors from VECIN queue
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// call Add instr for computation
Add(zLocal, xLocal, yLocal, TILE_LENGTH);
// enque the output tensor to VECOUT queue
outQueueZ.EnQue<half>(zLocal)l
// free input tensors for reuse
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
__aicore__ inline void CopyOut(int32_t progress)
{
//deque output tensor form VECOUT queue
LocalTensor<half> zLocal = outQueueZ.Deque<half>();
// copy progress_th tile form local tensor to global tensor
DataCopy(zGm[progress * TILE_LENGTH), zlocal, TILE_LENGTH);
// free outpupt tensor for reuse
outQueueZ.freeTensor(zLocal);
}
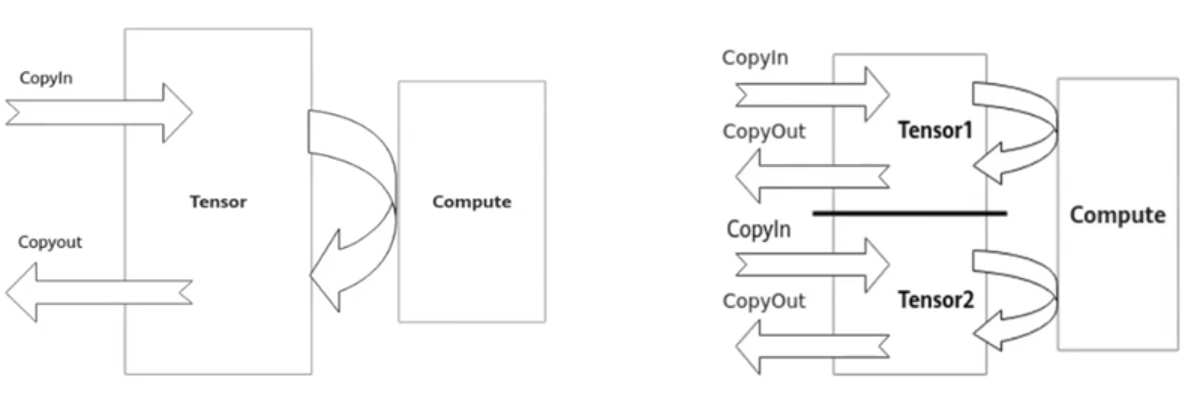
double buffer机制
double buffer通过将数据搬运与矢量计算并执行以隐藏数据搬运时间并降低矢量指令的等待时间,最终提高矢量计算单元的利用效率1个Tensor同一时间只能进行搬入、计算和搬出三个流水任务中的一个,其他两个流水任务涉及的硬件但愿则处于Idle状态
如果将待处理的数据一分为而,比如Tensor1、Tensor2
- 当矢量计算单元对于Tensor1进行Compute时,Tensor2可以进行CopyIn的任务
- 当矢量计算单元对于Tensor2进行Compute时,Tensor1可以进行CopyOut的任务
- 当矢量计算单元对于Tensor2进行CopyOut时,Tensor2可以进行CopyIn的任务
由此,数据的进出搬运和矢量计算之间实现你并行,硬件单元闲置问题得以有效缓解
Ascend C 算子调用
HelloWorld样例
-
运行CPU模式包含的头文件
-
运行NPU模式包含的头文件
-
核函数的定义
-
内置宏__CE_KT_TEST__:区分运行CPU模式或NPU模式逻辑的标志
-
主机侧执行逻辑:负责数据在主机侧内存的申请,主机到设备的拷贝,核函数执行同步和回收资源的工作
-
设备侧执行逻辑
-
主机侧执行CPU模式逻辑:使用封装的执行宏ICPU_RUN_KF
主要包括:
gMAlloc(…):申请CPU模式下的内存空间
ICPU_RUN_KF:使用封装的执行宏
GmFree:释放CPU模式下的内存空间
流程
AscendCL初始化—>运行管理资源申请—>Host数据传输至Device—>执行任务并等待—>Device数据传输至Host—>运行资源释放—>AscendCL去初始化 -
主机侧执行NPU模式逻辑:使用内核调用符<<<…>>>
重要接口
- aclInit
- aclCreateStream
- aclMallocHost
- aclMalloc
- aclMemcpy
- <<<…>>>
- aclrtSynchronizeStream
- aclrtFree
- aclrtfreeHost
- aclrtDestoryStream
- aclFinalize
AddCustom样例
Ascend C矢量算子样例代码
- 核函数源文件:add_custom.app
- 真值数据生成脚本:add_custom.py
- CmakeLists.txt:方便对多个源文件进行编译
- 读写数据文件辅助函数:data_utils.h
- 主机侧源文件:main.cpp
- 一键执行脚本:run.sh
- 组织CPU模式和NPU模式下编译的cmake脚本