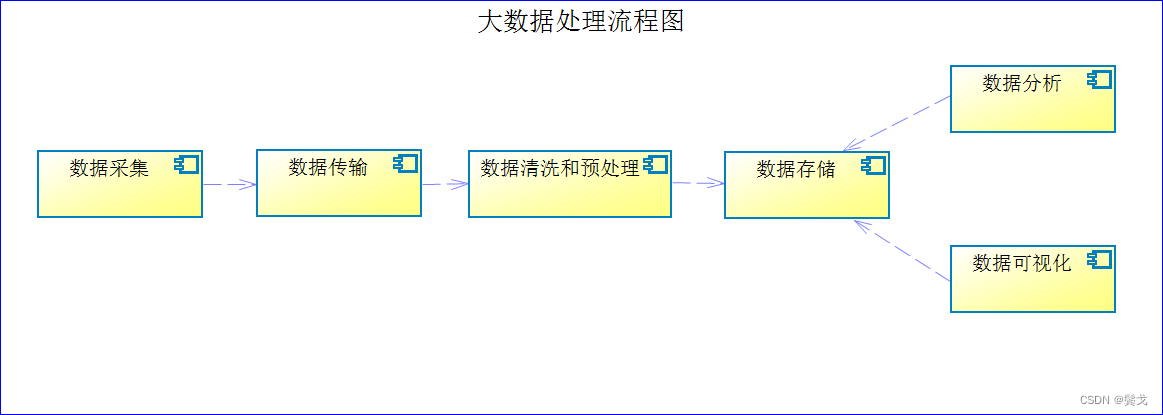
大家对大数据处理流程大体上认识差不多,具体做起来可能细节各不相同,一幅简单的大数据处理流程图如下:
1)数据采集:数据采集是大数据处理的第一步。
数据采集面对的数据来源是多种多样的,包括各种传感器、社交媒体、电子邮件、数据库、程序运行日志等。
数据采集面对的数据类型是多种多样的,有文本数据、结构化数据、图片数据、语音数据、视频数据等。
数据采集使用的各种开源工具也是多种多样的,如采用FileBeat对日志文件进行采集,采用Flink CDC从数据库采集,采用OpenCV采集视频数据等。
2)数据传输:数据传输是大数据处理的第二步。数据采集点各种各样,物联网上的各种传感器一般采用无线网络传输数据到数据中心,而其它数据采集大多走有线网络传输,带宽和速度是不一样的,采用的通讯协议也是不一样的。
物联网传输协议一般有MQTT、CoAP、RESTfulHTTP等。也可以采用google protobuf协议、MessagePack协议等进行数据封装和传输。
数据传输有时是很复杂的,它可能穿过很多网络最终才达到存储系统所在的网络。
数据传输还涉及各种消息队列,比如我们喜欢用Kafka系统来做数据分发。
3)数据清洗和预处理:收集到的数据可能包含噪声、缺失值和异常值,在入库之前,需要对数据进行清洗和预处理,以确保数据的质量和准确性。这包括数据去重、去噪、填充缺失值等。前端采集设备常常以最小数据字段集来传输数据包,特别是采取无线网络传输的,尽量让数据包小一些,当数据到了数据网关之后,可能我们会补齐一些字段,比如从设备ID映射出设备所在地址、区域、厂商等等,这些字段补齐之后去入库,方便之后数据查询分析。
在这个阶段,可能在数据网关处就做了一定的处理,之后继续前传,中间处理系统继续做不同的数据处理。
比如在入库前,常常采用流式计算框架Flink程序对数据做实时计算处理。
4)数据存储:一旦数据被传输到数据中心,并进行了一定的处理,它们需要被存储在适当的地方。大数据处理需要使用分布式存储系统,如Hadoop的HDFS、HBase、Elasticsearch、MongoDB等。这些系统具有高可扩展性和容错性,能够处理大规模的数据。
存储系统是非常重要的,怎样把海量数据存储起来是一个挑战,存储到一定量之后,存储系统稳定性又是一个挑战,非常考验开发团队和运维团队的技术水平和实际经验。
大数据存储系统常常指NoSQL系统,包括KV数据库,文档数据库,列式数据库以及图数据库等等。
5)数据分析:数据分析是大数据处理的核心步骤。这包括使用各种技术和工具对数据进行统计分析、数据挖掘、机器学习等,以发现数据中的模式、关联和趋势。数据分析的目标是提取有价值的信息和知识,以支持业务决策和行动。
数据分析主要有两大计算类型:批处理计算和流处理计算。
批处理计算以Hadoop MapReduce、Spark框架为代表。Flink号称支持批处理,其实不够好。
流处理计算以Flink、Spark Streaming框架为代码。而Spark也号称支持流处理,同样不够好。
6)数据可视化:数据可视化是将分析结果以图表、图形、地图等形式展示出来,以便用户更直观地理解和利用数据。数据可视化可以帮助用户发现数据中的模式和趋势,以及进行更深入的分析和洞察。
有很多专业的开源大数据可视化工具,如Kibana、Zeppelin等。
7)数据安全和隐私保护:在整个大数据处理流程中,数据安全和隐私保护是非常重要的。这包括对数据进行加密、访问控制、身份验证等,以确保数据的机密性和完整性。同时,还需要遵守相关的法律法规,保护用户的隐私权益。
8)数据应用:大数据的数据最终都是为了某个目的而采集入库的,数据应用是很重要的,如果没有得到合理利用,大数据就是资源浪费了。





![[开源]基于流程编排的自动化测试工具,插件驱动,测试无限可能](https://img-blog.csdnimg.cn/img_convert/f1e62312961fe3ace7a5816bc94c3be8.png)