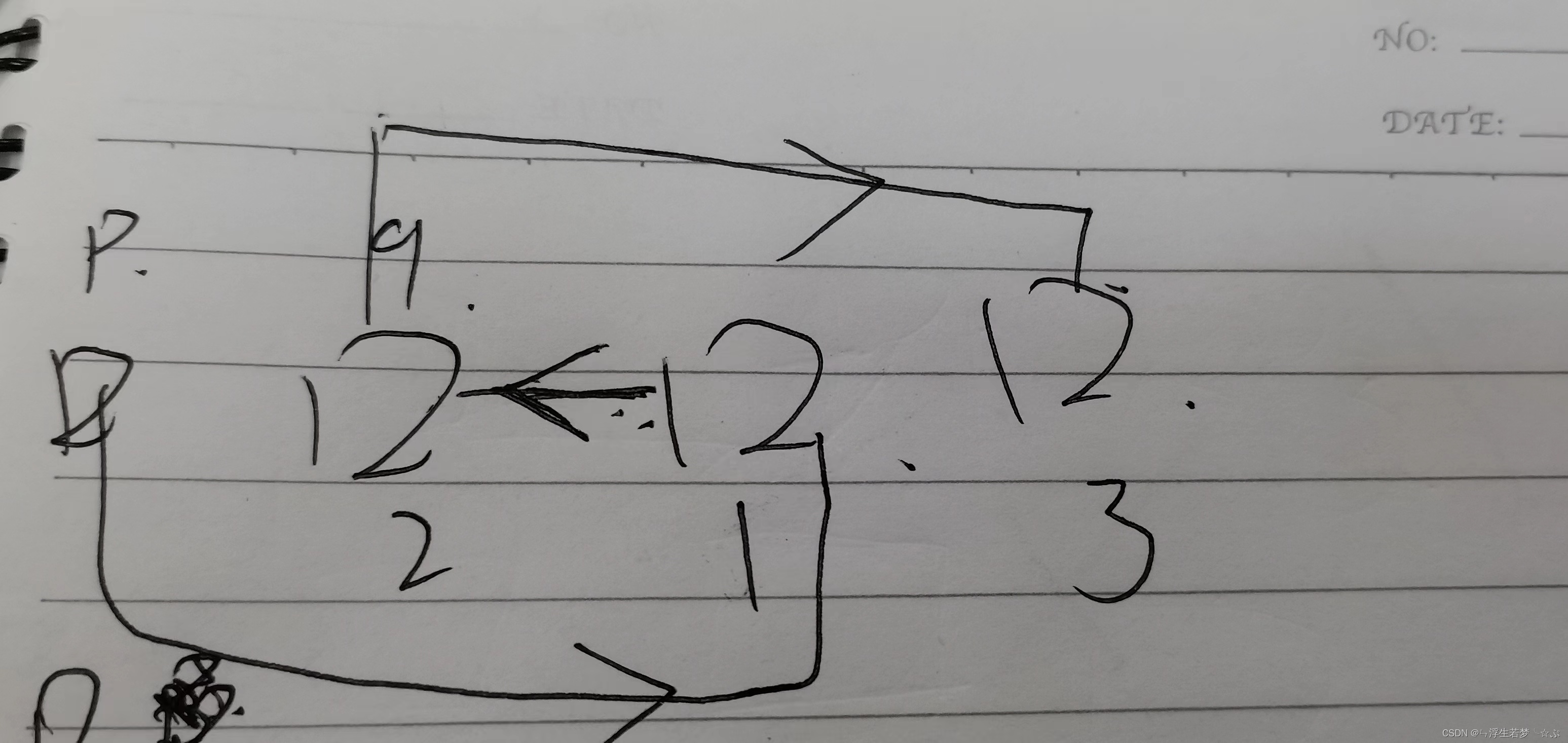
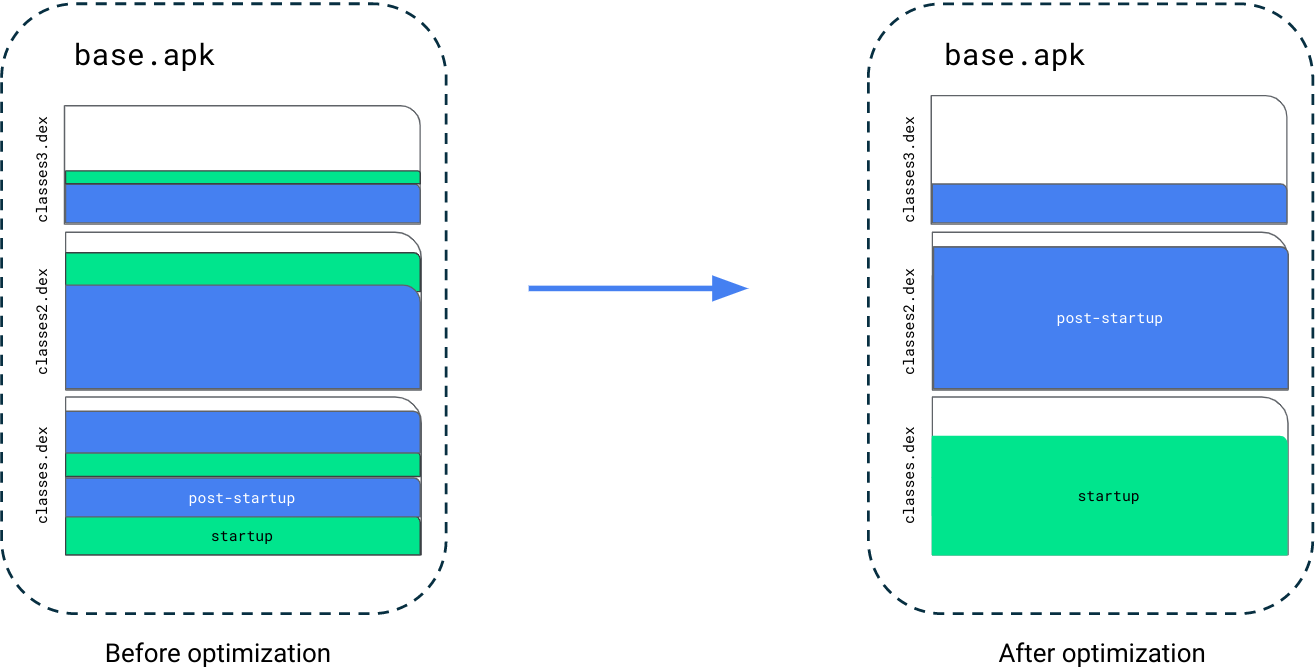
以下列代码为例
//终于给我搞清楚指针的指向究竟是怎么看的了
// 按编号对职工记录进行递增排序
void sortById(List* list) {
Employee* p, * q, * tail = NULL;
// tail 变量则是一个边界指针,初始值为 NULL。
while (list->head->next != tail) // tail 变量则是一个边界指针,等于tail时,即终止循环
//tail只会不断向前靠,一旦tail为初始数据指针即排序完毕
{
p = list->head;//记录头结点,也就是链表位置的指针
q = p->next;//记录初始起始数据指针,便于后面交换数据
while (q->next != tail) {
if (q->id > q->next->id) {
p->next = q->next;
//意思是p的头结点的下一个位置改为q->next,也就是直接连接了下一个最小的节点
q->next = q->next->next;
//同理,q的下一个节点,即下一个位置的连接为q的下一个的下一个节点的位置
//也就是直接跳过了中间的q->next
// 这里的意思是直接q节点直接跳过q->next,链接q->next->next的意思
//你记住,在左边,最后一个next永远都是指它的下一个位置是什么的意思
// 也就是与哪个节点连接的意思
//而如果前面有多的next,才是看作一个整体,
// 如q->next->next,
//可看成(q->next)->next,即q的下一个节点的下一个位置,即链接的位置是哪?
//而如果在右边,那么next的意思那就全都是看作一起,也就是一个整体
//直接把右边的指针看作成一整块,而不是分开来。
/* 很简单,代码从来都是左边操作,右边赋值的*/
p->next->next = q;
/* 这个就很经典了,意思是
(p->next)->next*/
//即p->next这个整体的下一个位置,链接何处
q = p->next;
/* q重新指向为p->next这个位置*/
//更新p的指针位置,即更新交换后的起始数据指针
}
p = p->next;
q = q->next;
//第一次循环的时候,已经将头指针和最小的节点给确认了
//所以前两个点可以不用管了,直接往下与新的节点比较就好
}
tail = q;
//当内循环退出时,表示当前轮次的排序已完成。将 tail 设为最后一次交换的节点 q,相当于缩小了待排序的范围。
//就是冒泡排序的道理一样的,最后的数据一定是最大的,每一次排序完后,最后的位置是不用动的,
//而前面的数据很可能还要反复地交换,tail就是每一次标记每次循环中最大的数据,一旦遇见直接跳出排序即可
}
printf("按编号排序已完成。\n");
}
//理解误区
//指针的next本质上不是替换,而是位置的确认!
//你记住,next无论如何都是指当前的值的下一个位置指向哪里
//是指向哪里 ,也就是包含了链接的意思,同时又确认了当前指针的下一个位置是什么
//而不是替换值的大小!
//你记住,链表指向的意思是,当前指针的前一个节点,或者下一个节点是什么,是连接也是存储不同的值
//不要把指针和next等同于一个单位看,它还包括了链表之间的连接关系!
//你该关注的是什么,不是next和pre,而是最原始的指针如p,q
//你要关注的是目前p,q这样的指针的具体动向在哪,有没有改变,如果改变了他们的指向也会变得不同
//如果没变,那么p,q永远都是在同一个位置!
//关注原始指针!
//同时还有很重要的一点,就是你一定要考虑清楚,指针究竟有没有改动,以及下一个位置究竟是哪
//都是前后文,自己要注意和看清楚位置究竟是哪,然后,前面自己有改动的地方也要知道
//总的来说就是你一定要清楚自己指针指向的最新位置是哪,前面的可以不考虑
//但当前指向的最新位置一定要清楚!
// 按部门号对职工记录进行递增排序,若部门号相同,则按职工编号递增排序