什么是自动查重?
自动查重是指使用计算机程序来比较两个或多个文件的内容,判断它们之间是否存在相似或相同的部分,从而检测出抄袭或重复的情况。自动查重可以用于学术论文、代码、文本等各种类型的文件,帮助提高原创性和质量。
为什么要使用Python进行自动查重?
Python是一种广泛使用的编程语言,具有简洁、易读、灵活和强大的特点。Python中有许多现成的库和工具,可以方便地实现自动查重的功能。其中,difflib库就是一个专门用于比较文件和字符串差异的库,它提供了多种方法和API,可以根据不同的需求和场景进行自动查重。
如何使用Python中的difflib库进行自动查重?
pip install cdifflib
difflib库中最常用的两个类是SequenceMatcher和Differ,它们都可以用来比较两个序列(如字符串、列表、元组等)之间的差异,并生成相应的结果。
SequenceMatcher
SequenceMatcher类可以用来计算两个序列之间的相似度,以及找出它们最长的匹配子序列。它有以下几个主要的方法:
-
__init__(a, b, isjunk=None):创建一个SequenceMatcher对象,参数a和b是要比较的两个序列,参数isjunk是一个可选的函数,用于指定哪些元素应该被忽略。 -
ratio():返回两个序列之间的相似度,范围在0到1之间,越接近1表示越相似。 -
quick_ratio():返回两个序列之间的快速估计相似度,比ratio()方法更快但可能不太准确。 -
real_quick_ratio():返回两个序列之间的非常快速估计相似度,比quick_ratio()方法更快但可能更不准确。 -
get_matching_blocks():返回一个列表,包含了两个序列中最长匹配子序列的信息,每个元素是一个元组(i, j, n),表示第一个序列中从索引i开始长度为n的子序列与第二个序列中从索引j开始长度为n的子序列完全匹配。 -
get_opcodes():返回一个列表,包含了将第一个序列转换为第二个序列所需的操作,每个元素是一个元组(tag, i1, i2, j1, j2),表示对第一个序列中从索引i1到索引i2(不包括)的子序列执行操作tag后,它将与第二个序列中从索引j1到索引j2(不包括)的子序列相等。操作有以下几种:-
'equal': 表示两个子序列相等,无需修改。 -
'replace': 表示需要将第一个子序列替换为第二个子序列。 -
'delete': 表示需要删除第一个子序列。 -
'insert': 表示需要在第一个子序列后插入第二个子序列。 -
'noop': 表示无操作。
-
Differ
Differ类可以用来生成两个序列之间的差异报告,以便于人类阅读和理解。它有以下几个主要的方法:
-
__init__(linejunk=None, charjunk=None):创建一个Differ对象,参数linejunk和charjunk是两个可选的函数,用于指定哪些行或字符应该被忽略。 -
compare(a, b):返回一个生成器,逐行比较两个序列a和b,并生成差异报告。每一行的开头有一个标记,表示该行的状态,有以下几种:-
' ': 表示该行在两个序列中都存在,无差异。 -
'-': 表示该行只在第一个序列中存在,被删除。 -
'+': 表示该行只在第二个序列中存在,被添加。 -
'?': 表示该行在两个序列中有不同的字符,需要进一步比较。
-
一个简单的例子
为了演示如何使用difflib库进行自动查重,我们可以用它来比较两篇文章的内容,并输出相似度和差异报告。假设我们有以下两篇文章:
文章A:
Python是一种高级编程语言,它的设计哲学是“优雅”、“明确”、“简单”。Python拥有动态类型系统和垃圾回收功能,能够自动管理内存使用,并且支持多种编程范式,包括面向对象、命令式、函数式和过程式编程。Python的语法简洁而清晰,使用缩进来表示代码块,从而减少了代码的冗余。Python解释器本身几乎可以在所有的操作系统中运行。Python的标准库提供了丰富的功能,包括图形界面、数据库、网络、多线程、正则表达式等。Python还有许多第三方库和框架,可以用于科学计算、数据分析、机器学习、Web开发等领域。Python是一种通用的编程语言,适用于各种应用场景。
文章B:
Python是一门通用的高级编程语言。它具有简单明确的语法,使用缩进来组织代码结构。Python支持多种编程范式,如面向对象、函数式和过程式编程。Python具有动态类型系统和自动内存管理功能,可以适应不同的需求和环境。Python可以在多种操作系统中运行,并且拥有庞大的标准库和第三方库,涵盖了图形界面、数据库、网络、多线程、正则表达式等各种功能。Python还可以用于科学计算、数据分析、机器学习、Web开发等领域。Python是一门优雅而强大的编程语言,适合各种应用场景。
我们可以将这两篇文章保存为两个文本文件,分别命名为article_a.txt和article_b.txt,然后使用以下代码来进行自动查重:
# 导入difflib库
import difflib
# 打开并读取两个文本文件
with open('article_a.txt', 'r', encoding='utf-8') as f:
a = f.read()
with open('article_b.txt', 'r', encoding='utf-8') as f:
b = f.read()
# 创建一个SequenceMatcher对象
sm = difflib.SequenceMatcher(None, a, b)
# 计算并打印两篇文章的相似度
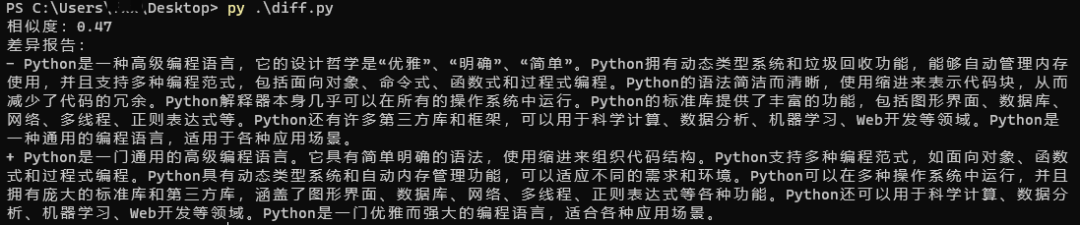
similarity = sm.ratio()
print(f'相似度:{similarity:.2f}')
# 创建一个Differ对象
d = difflib.Differ()
# 比较并生成差异报告
diff = d.compare(a.splitlines(), b.splitlines())
# 打印差异报告
print('差异报告:')
for line in diff:
print(line)
运行结果如下图:
总结
本教程介绍了如何使用Python中的difflib库进行自动查重,主要介绍了SequenceMatcher和Differ两个类的用法和API,以及一个简单的例子。通过使用difflib库,我们可以方便地比较两个文件或字符串之间的相似度和差异,并生成可读的结果。这对于检测抄袭或重复的情况,提高原创性和质量,有很大的帮助。希望本教程能够对你有所启发和帮助。😊







![2023年中国非血管介入手术无源耗材发展现状、竞争格局及行业市场规模[图]](https://img-blog.csdnimg.cn/img_convert/94f23c2d8786548fe882c4946b0a6b8f.png)