一、前言
本内容仅用于个人学习笔记,如有侵扰,联系删除
视频教程:【尚硅谷】大数据技术之Zookeeper 3.5.7版本教程
源码学习:微服务系列 - Zookeeper下篇:源码解析
二、Zookeeper入门
1、概述
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
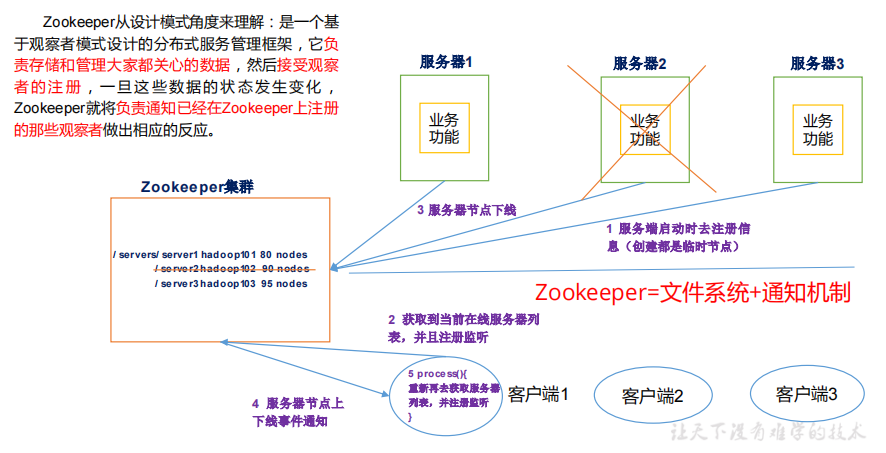
1.1、Zookeeper工作机制
1.2、Zookeeper特点
Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。- 集群中只要有半数以上节点存活,
Zookeeper集群就能正常服务。 - 全局数据一致:每个
Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。 - 更新请求顺序进行,来自同一个
Client的更新请求按其发送顺序依次执行。 - 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,
Client能读到最新数据。
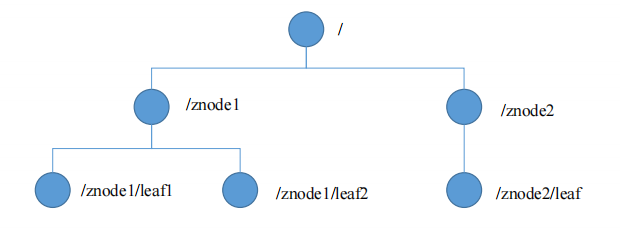
1.3、数据结构
Zookeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
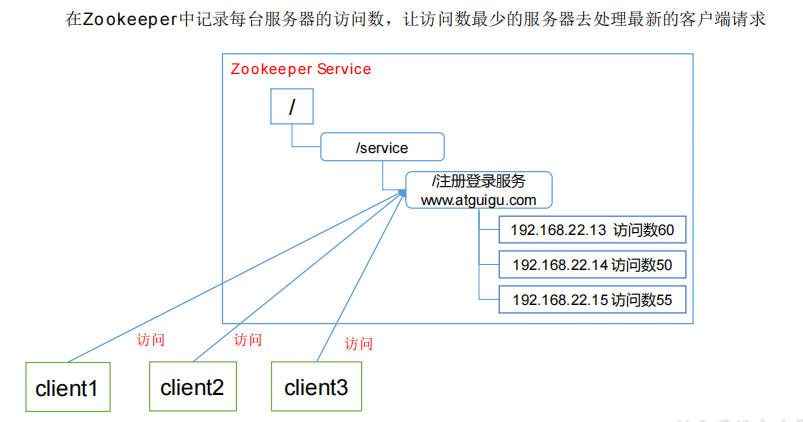
1.4、应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下
线、软负载均衡等。
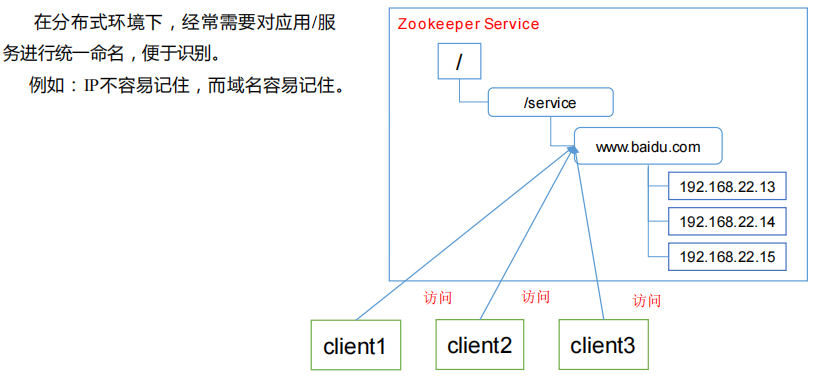
-
统一命名服务
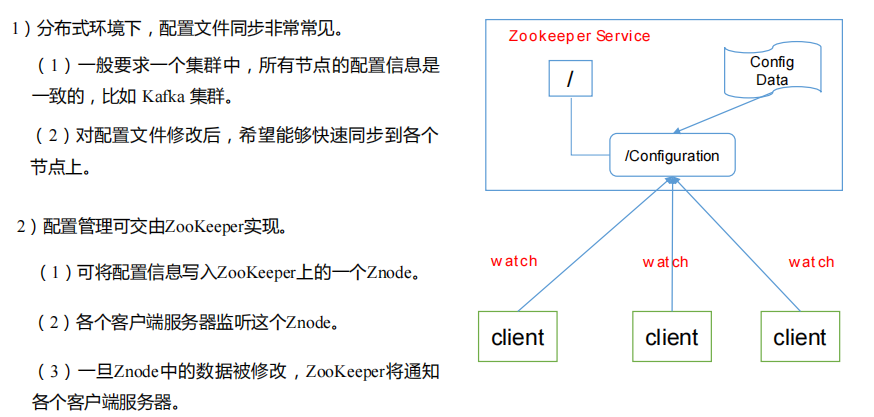
-
统一配置管理
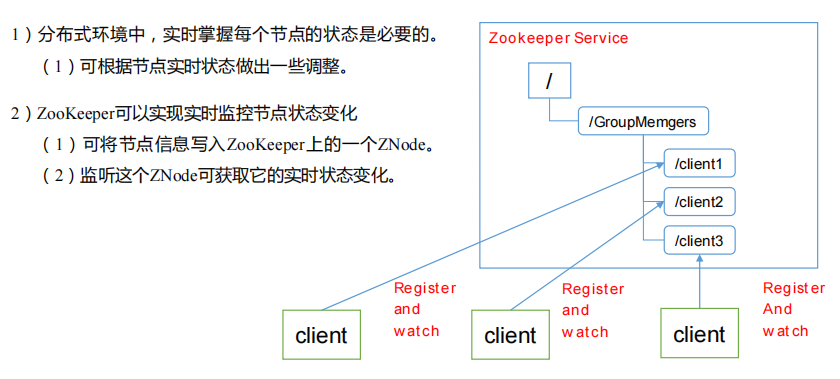
-
统一集群管理
-
服务器动态上下线
-
软负载均衡
二、Zookeeper 安装
1、下载地址
- 官网首页:https://zookeeper.apache.org/
- 下载截图
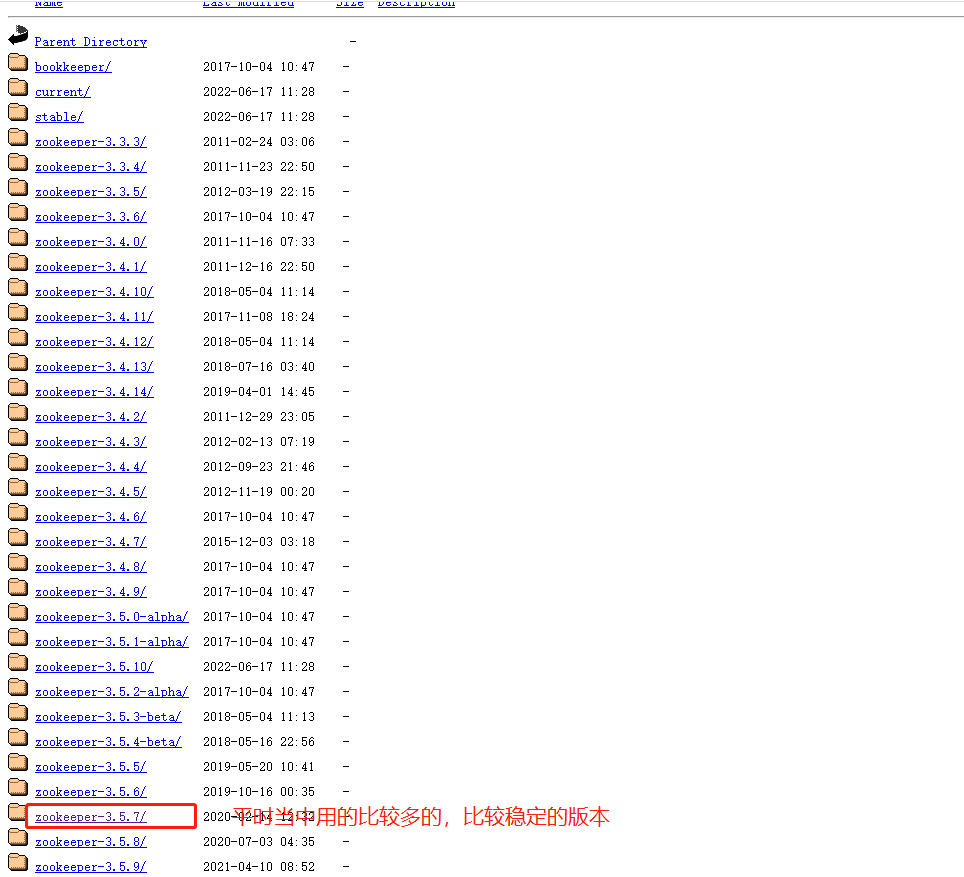
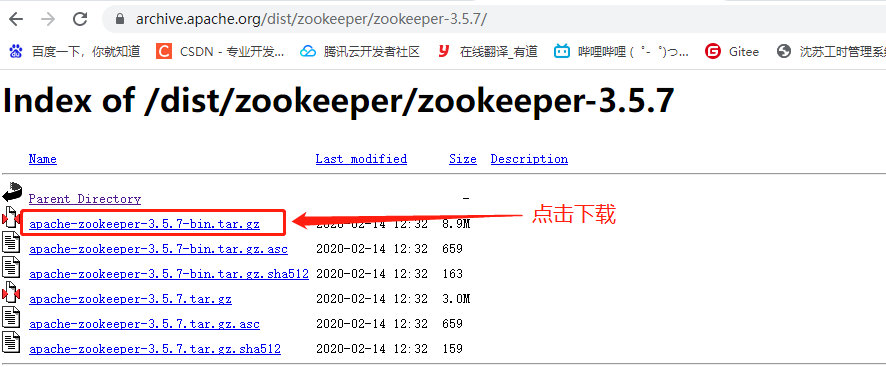
2、本地模式安装部署
1.1、安装前准备
- 安装 JDK
- 1)、下载JDK
这里我用的jdk1.8.0_321版本,大家可以从官网下载或从下方网盘下载
jdk1.8.0_321版本下载地址: https://pan.baidu.com/s/1N4KUpTyjxpsWiFCZkWecOg
提取码: in2p
- 2)、解压JDK
首先创建java文件夹: mkdir /usr/java
进入java文件夹: cd /usr/java/
上传JDK安装包: 使用工具
[root@localhost usr]# mkdir /usr/java
[root@localhost usr]# cd /usr/java/
[root@localhost java]# tar -zxvf jdk-8u191-linux-x64.tar.gz
- 3)、配置profile文件
编辑profile配置文件: vim /etc/profile
[root@localhost java]# vim /etc/profile
输入i进入编辑模式,在最下面补充配置信息,补充完后按Esc退出编辑模式后,输入:wq进行保存并退出
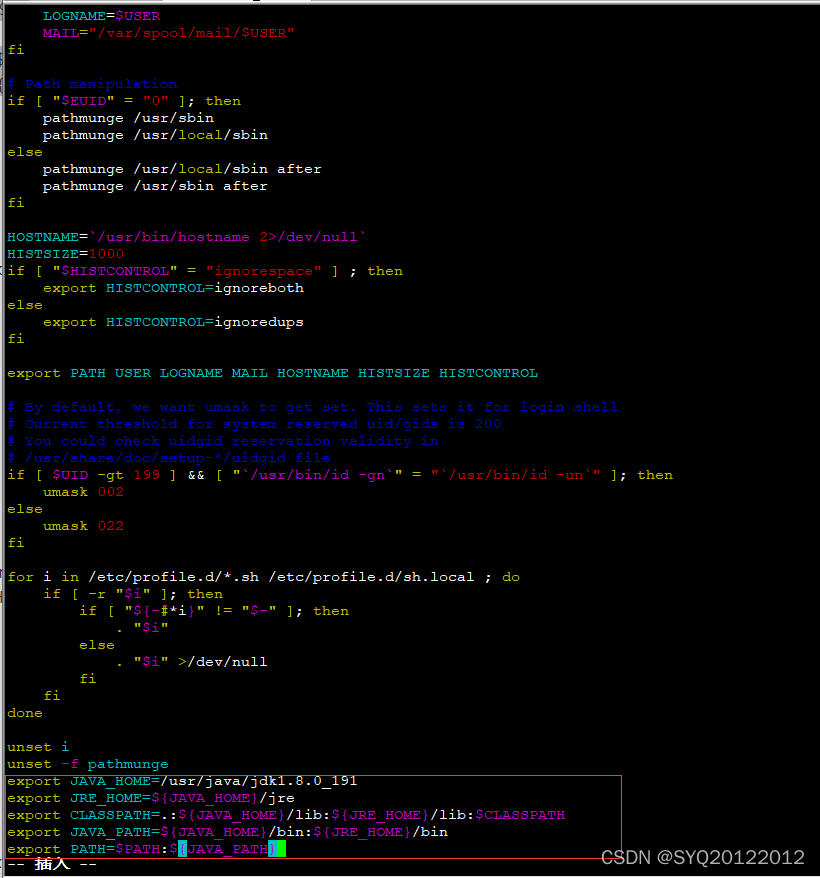
export JAVA_HOME=/usr/java/jdk1.8.0_191
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
如下图所示:
- 4)、配置文件生效
配置文件生效: source /etc/profile
查看JDK版本信息: java -version
[root@localhost java]# source /etc/profile
[root@localhost java]# java -version
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode)
[root@localhost java]#
-
拷贝 Zookeeper 安装包到 Linux 系统下

-
解压到指定目录

-
修改文件名为:zookeeper-3.5.7

-
查看

1.2.配置修改
- 将/opt/software/zookeeper-3.5.7/conf这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;


- 打开 zoo.cfg 文件,修改 dataDir 路径:

修改如下内容:
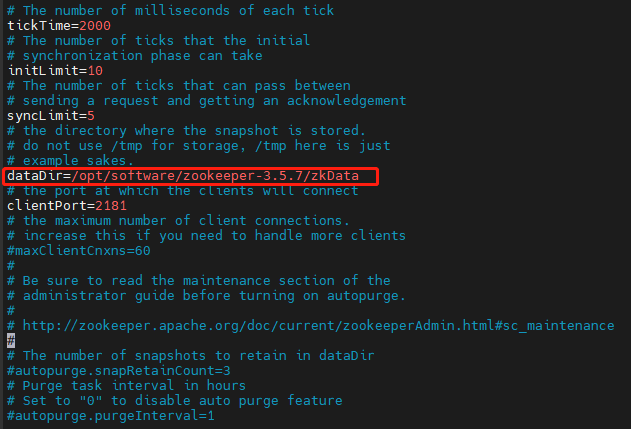
- 在/opt/software/zookeeper-3.5.7/这个目录上创建 zkData 文件夹
mkdir zkData
1.3.操作 Zookeeper
(1)启动 Zookeeper

(2)查看进程是否启动

(3)查看状态:

(4)启动客户端:

(5)退出客户端:

(6)停止 Zookeeper
bin/zkServer.sh stop
3、配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
- tickTime =2000:通信心跳数,
Zookeeper服务器与客户端心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,
也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超
时时间是2*tickTime) - initLimit =10:LF 初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心
跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。 - syncLimit =5:LF 同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follower死掉,从服务器列表中删除Follower。 - dataDir:数据文件目录+数据持久化路径
主要用于保存Zookeeper中的数据。 - clientPort =2181:客户端连接端口
监听客户端连接的端口
三、Zookeeper 实战(开发重点)
1、分布式安装部署
1.1. 集群规划
在 hadoop102、hadoop103 和 hadoop104 三个节点上部署Zookeeper。
1.2. 解压安装
- (1)解压
Zookeeper安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/
- (2)同步/opt/module/zookeeper-3.5.7 目录内容到 hadoop103、hadoop104
[atguigu@hadoop102 module]$ xsync zookeeper-3.5.7/
1.3. 配置服务器编号
- (1)在/opt/module/zookeeper-3.5.7 /这个目录下创建 zkData
[atguigu@hadoop102 zookeeper-3.5.7 ]$ mkdir -p zkData
- (2)在/opt/module/zookeeper-3.5.7 /zkData 目录下创建一个 myid 的文件
[atguigu@hadoop102 zkData]$ touch myid
添加 myid 文件,注意一定要在 linux 里面创建,在 notepad++里面很可能乱码
- (3)编辑 myid 文件
[atguigu@hadoop102 zkData]$ vi myid
在文件中添加与 server 对应的编号:
2
- (4)拷贝配置好的 zookeeper 到其他机器上
[atguigu@hadoop102 zkData]$ xsync myid
并分别在 hadoop103、hadoop104 上修改 myid 文件中内容为 3、4
- 配置 zoo.cfg 文件
- (1)重命名/opt/module/zookeeper-3.5.7/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
- (2)打开 zoo.cfg 文件
[atguigu@hadoop102 conf]$ vim zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
- (3)同步 zoo.cfg 配置文件
[atguigu@hadoop102 conf]$ xsync zoo.cfg
- (4)配置参数解读
server.A=B:C:D。
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D 是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的
Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
1.4. 集群操作
(1)分别启动 Zookeeper
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
(2)启动客户端
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkCli.sh
这种方式启动是本地的客户端

我们也可以指定服务器客户端
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkCli.sh -server hadoop102:2181

(3)查看状态
[atguigu@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-
3.5.7/bin/../conf/zoo.cfg
Mode: follower
[atguigu@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-
3.5.7/bin/../conf/zoo.cfg
Mode: leader
[atguigu@hadoop104 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-
3.5.7/bin/../conf/zoo.cfg
Mode: follower
1.5、zk集群启动停止脚本
进入到linux下的bin目录下
cd /bin
编辑zk.sh
vim zk.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop02 hadoop3 hadoop4
do
echo -------------zookeeper $i 启动 -----------------
ssh $i "opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
}
;;
"stop"){
for i in hadoop02 hadoop3 hadoop4
do
echo -------------zookeeper $i 停止 -----------------
ssh $i "opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
}
;;
"status"){
for i in hadoop02 hadoop3 hadoop4
do
echo -------------zookeeper $i 状态 -----------------
ssh $i "opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
}
;;
esac
一定要在INSERT下编辑,编辑完wq保存退出

我们ll查看发现颜色不对
chmod 777 zk.sh

这样就可执行了
- 脚本启动集群
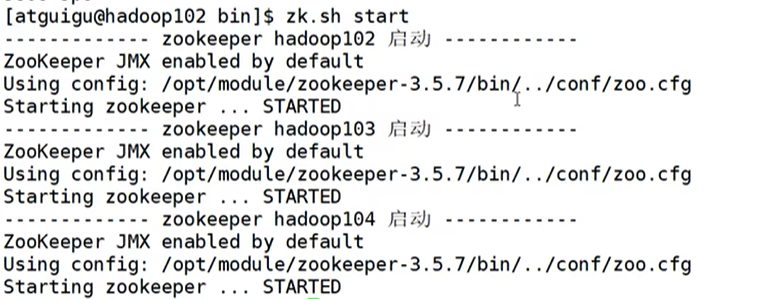
2、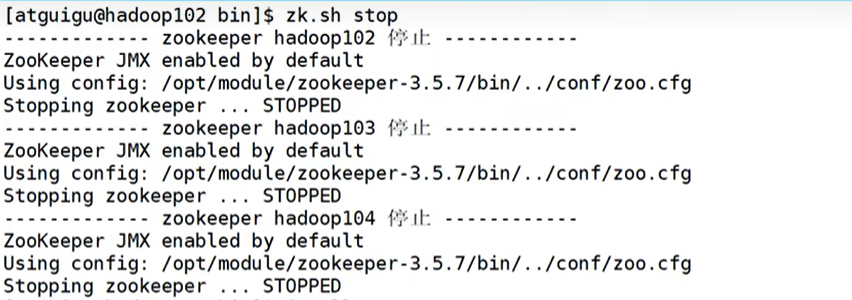
- 脚本查看集群状态
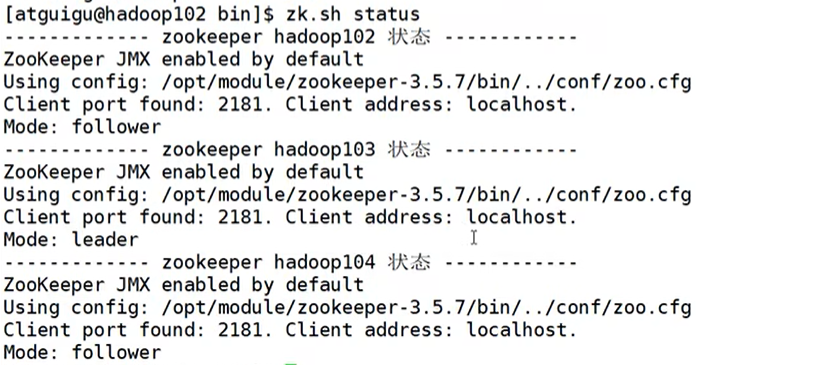
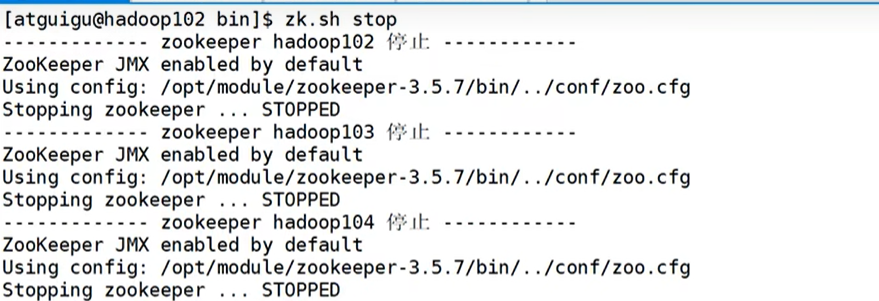
- 脚本停止集群
- 查看所有进程

2、客户端命令行操作
2.1、命令行语法
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path [watch] | 使用 ls 命令来查看当前 znode 中所包含的内容 |
| ls2 path [watch] | 查看当前节点数据并能看到更新次数等数据 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path [watch] | 获得节点的值 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| rmr | 递归删除节点 |
- 显示所有操作命令
[zk: localhost:2181(CONNECTED) 1] help
- 查看当前 znode 中所包含的内容
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
2.2、znode节点数据信息
- 查看当前节点详细数据
[zk: localhost:2181(CONNECTED) 1] ls2 /
[zookeeper]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
1)、czxid - 创建节点的事务zxid
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
2)、ctime - znode被创建的毫秒数(从1970年开始)
3)、mzxid - znode最后更新的事务zxid
4)、mtime - znode最后修改的毫秒数(从1970年开始)
5)、pZxid - znode最后更新的子节点zxid
6)、cversion - znode子节点变化号,znode子节点修改次数
7)、dataversion - znode数据变化号
8)、aclVersion - znode访问控制列表的变化号
9)、ephemeralOwner - 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
10)、dataLength - znode的数据长度
11)、numChildren - znode子节点数量
2.3、节点类型(持续/短暂/有序号/无序号)

- 分别创建两个普通节点(永久节点 + 不带序号节点)
[zk: localhost:2181(CONNECTED) 3] create /sanguo "jinlian"
Created /sanguo
[zk: localhost:2181(CONNECTED) 4] create /sanguo/shuguo
"liubei"
Created /sanguo/shuguo
- 获得节点的值
[zk: localhost:2181(CONNECTED) 5] get -s /sanguo
jinlian
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000003
mtime = Wed Aug 29 00:03:23 CST 2018
pZxid = 0x100000004
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 1
[zk: localhost:2181(CONNECTED) 6]
[zk: localhost:2181(CONNECTED) 6] get -s /sanguo/shuguo
liubei
cZxid = 0x100000004
ctime = Wed Aug 29 00:04:35 CST 2018
mZxid = 0x100000004
mtime = Wed Aug 29 00:04:35 CST 2018
pZxid = 0x100000004
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
- 创建短暂节点
[zk: localhost:2181(CONNECTED) 7] create -e /sanguo/wuguo
"zhouyu"
Created /sanguo/wuguo
(1)在当前客户端是能查看到的
[zk: localhost:2181(CONNECTED) 3] ls /sanguo
[wuguo, shuguo]
(2)退出当前客户端然后再重启客户端
[zk: localhost:2181(CONNECTED) 12] quit
[atguigu@hadoop104 zookeeper-3.4.10]$ bin/zkCli.sh
(3)再次查看根目录下短暂节点已经删除
[zk: localhost:2181(CONNECTED) 0] ls /sanguo
[shuguo]
- 创建带序号的节点
(1)先创建一个普通的根节点/sanguo/weiguo
[zk: localhost:2181(CONNECTED) 1] create /sanguo/weiguo
"caocao"
Created /sanguo/weiguo
(2)创建带序号的节点
[zk: localhost:2181(CONNECTED) 2] create -s
/sanguo/weiguo/xiaoqiao "jinlian"
Created /sanguo/weiguo/xiaoqiao0000000000
[zk: localhost:2181(CONNECTED) 3] create -s
/sanguo/weiguo/daqiao "jinlian"
Created /sanguo/weiguo/daqiao0000000001
[zk: localhost:2181(CONNECTED) 4] create -s
/sanguo/weiguo/diaocan "jinlian"
Created /sanguo/weiguo/diaocan0000000002
如果原来没有序号节点,序号从 0 开始依次递增。如果原节点下已有 2 个节点,则再排序时从 2 开始,以此类推。
- 修改节点数据值
[zk: localhost:2181(CONNECTED) 6] set /sanguo/weiguo "simayi"
- 节点的值变化监听
(1)在 hadoop104 主机上注册监听/sanguo 节点数据变化
[zk: localhost:2181(CONNECTED) 26] [zk:
localhost:2181(CONNECTED) 8] get /sanguo watch
(2)在 hadoop103 主机上修改/sanguo 节点的数据
[zk: localhost:2181(CONNECTED) 1] set /sanguo "xisi"
(3)观察 hadoop104 主机收到数据变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged
path:/sanguo
注意:在hadoop103再多次修改/sanguo的值,hadop104上不会再收到监听。因为注册一次,只能监听一次。想再次监听,需要再次注册。

- 节点的子节点变化监听(路径变化)
(1)在 hadoop104 主机上注册监听/sanguo 节点的子节点变化
[zk: localhost:2181(CONNECTED) 1] ls /sanguo watch
[aa0000000001, server101]
(2)在 hadoop103 主机/sanguo 节点上创建子节点
[zk: localhost:2181(CONNECTED) 2] create /sanguo/jin "simayi"
Created /sanguo/jin
(3)观察 hadoop104 主机收到子节点变化的监听
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged
path:/sanguo
- 删除节点
[zk: localhost:2181(CONNECTED) 4] delete /sanguo/jin
- 递归删除节点
[zk: localhost:2181(CONNECTED) 15] rmr /sanguo/shuguo
- 查看节点状态
[zk: localhost:2181(CONNECTED) 17] stat /sanguo
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000011
mtime = Wed Aug 29 00:21:23 CST 2018
pZxid = 0x100000014
cversion = 9
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 1
3、API应用
3.1Zookeeper API简介
org.apache.zookeeper.Zookeeper是ZooKeeper客户端的主类
创建一个ZooKeeper的实例来使用org.apache.zookeeper.Zookeeper里的方法,官方文档已经指出没有特别声明的话,ZooKeeper类里的方法是线程安全的。客户端连接到ZooKeeper服务的时候,会给客户端分配一个会话ID(session ID),客户端与服务端会通过心跳来保持会话有效。
org.apache.zookeeper.Zookeeper里的方法非常多,就不一一列举了,只列几个增删改查的。
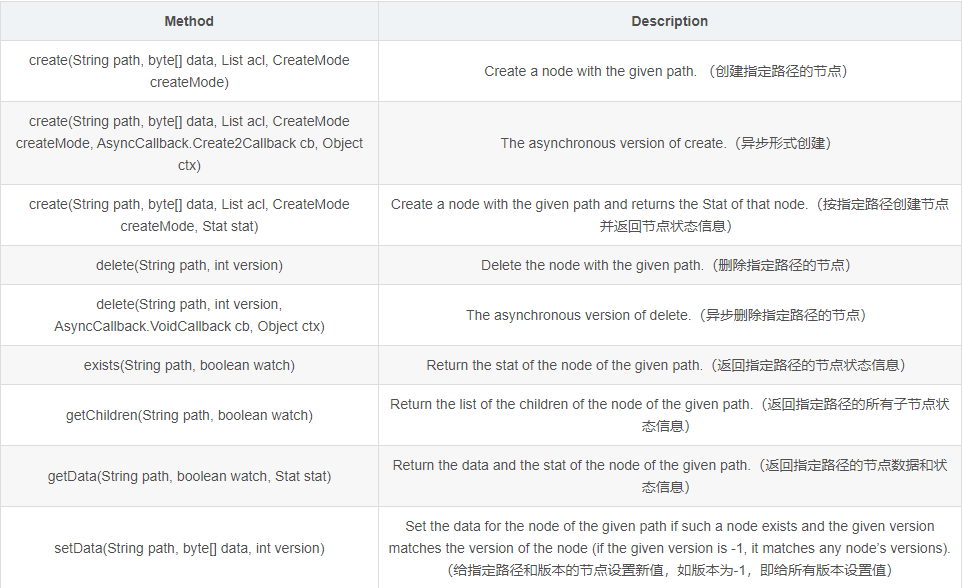
3.2、IDEA环境搭建
- 创建一个maven项目
- 添加 pom 文件
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
3.3、api操作
- ZooKeeper客户端
com.wts.zk.ZkClient
public class ZkClient {
Logger log = LoggerFactory.getLogger(ZkClient.class);
private static String connectString = "150.158.135.181:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zk = null;
private static final String ZNODE_PATH = "/zk_demo";
private static final String ZNODE_PATH_CHILDREN = "/zk_demo/app";
/**
* zookeeper客户端
*
* @throws Exception
*/
@Before
public void init() throws Exception {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("已经触发了" + event.getType() + "事件!");
}
});
}
}
【结果】
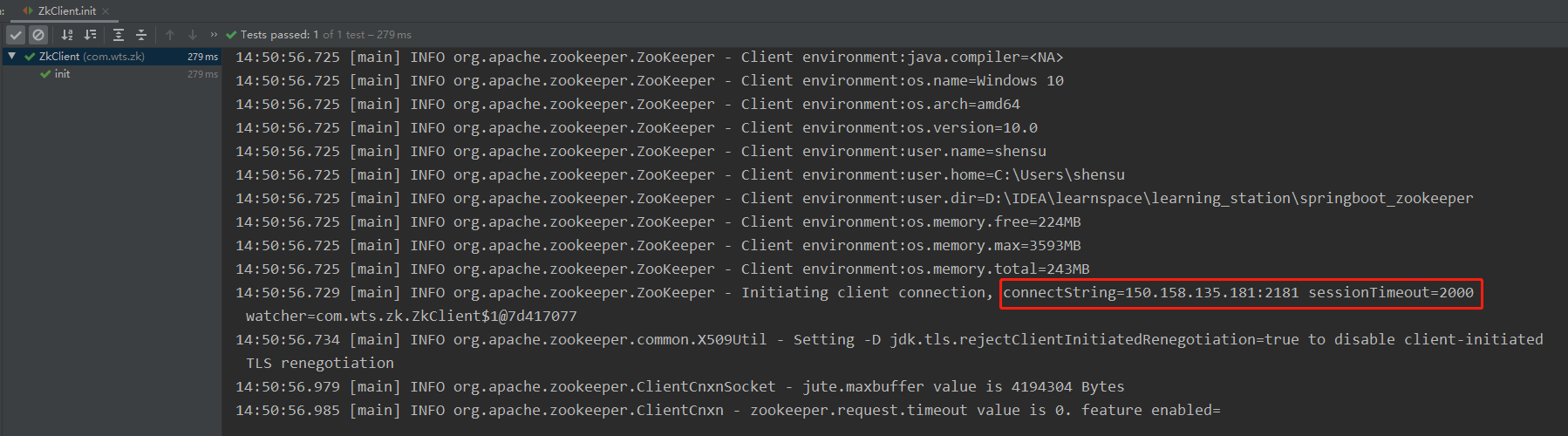
- 创建节点
public class ZkClient {
Logger log = LoggerFactory.getLogger(ZkClient.class);
private static String connectString = "150.158.135.181:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zk = null;
private static final String ZNODE_PATH = "/zk_demo";
private static final String ZNODE_PATH_CHILDREN = "/zk_demo/app";
/**
* zookeeper客户端
*
* @throws Exception
*/
@Before
public void init() throws Exception {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("已经触发了" + event.getType() + "事件!");
}
});
}
/**
* 创建节点
*
* @throws KeeperException
* @throws InterruptedException
*/
@Test
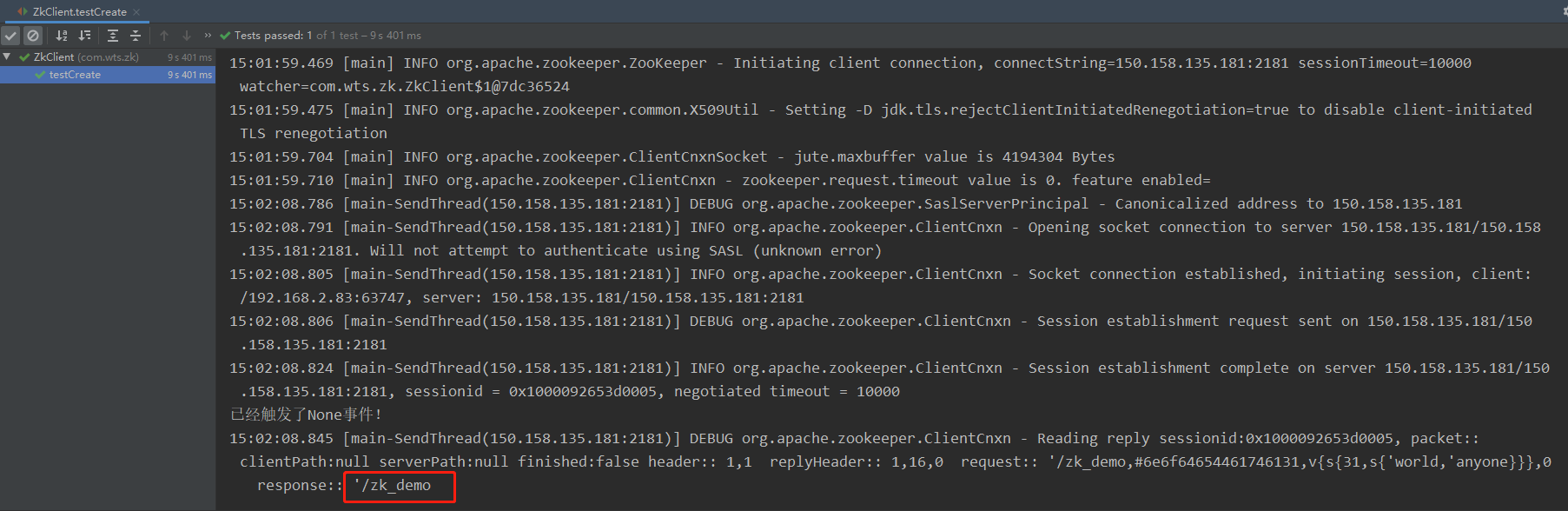
public void testCreate() throws KeeperException, InterruptedException {
// 参数1:要创建的节点的路径; 参数2:节点数据 ; 参数3:节点权限 ;参数4:节点的类型
zk.create(ZNODE_PATH, "nodeData1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
【结果】
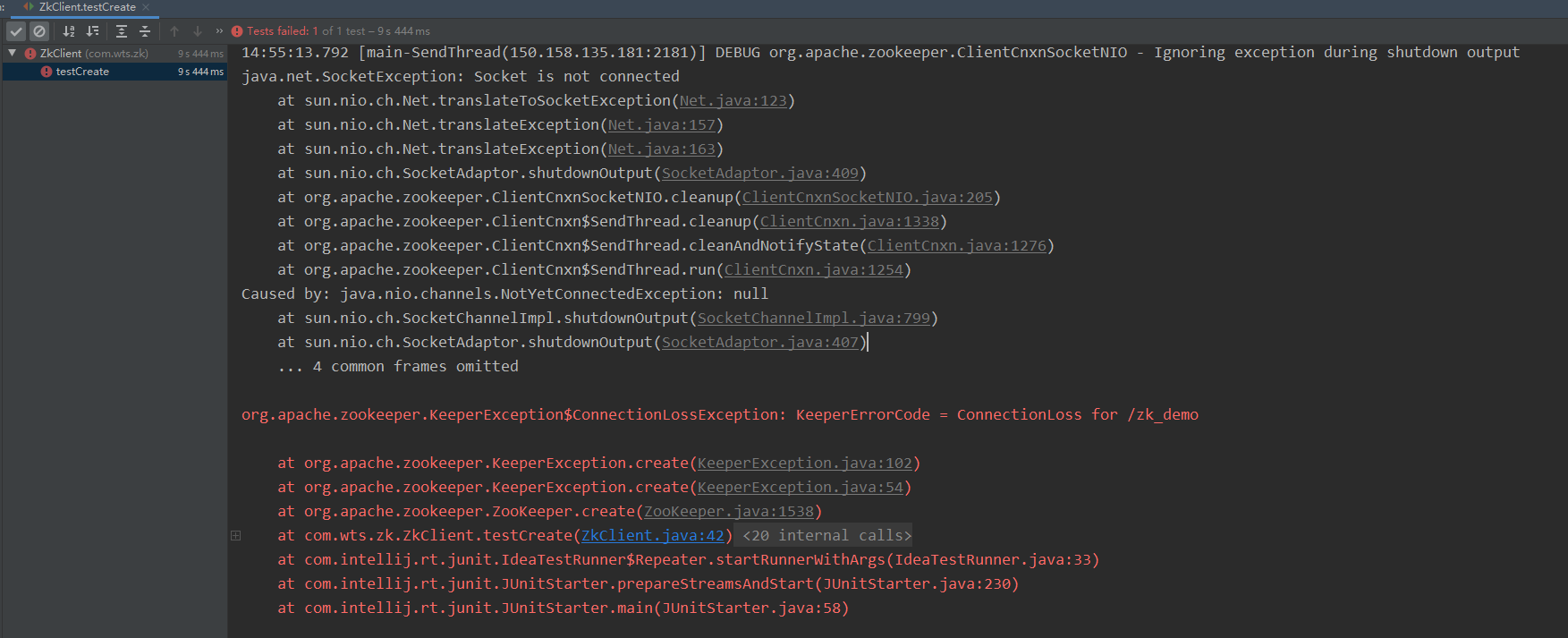
起初以为是ZooKeeper服务部署有问题或服务没启动,经检查确认无误后,debug调试发现,是SESSION_TIME_OUT = 2000;设置的值太小,改为10000后,不再报错。
SESSION_TIME_OUT是会话超时时间,也就是当一个zookeeper超过该时间没有心跳,则认为该节点故障。所以,如果此值小于zookeeper的创建时间,则当zookeeper还未来得及创建连接,会话时间已到,因此抛出异常认为该节点故障。
上面有用到@Before,简单说明下:
@BeforeClass – 表示在类中的任意public static void方法执行之前执行
@AfterClass – 表示在类中的任意public static void方法执行之后执行
@Before – 表示在任意使用@Test注解标注的public void方法执行之前执行
@After – 表示在任意使用@Test注解标注的public void方法执行之后执行
@Test – 使用该注解标注的public void方法会表示为一个测试方法
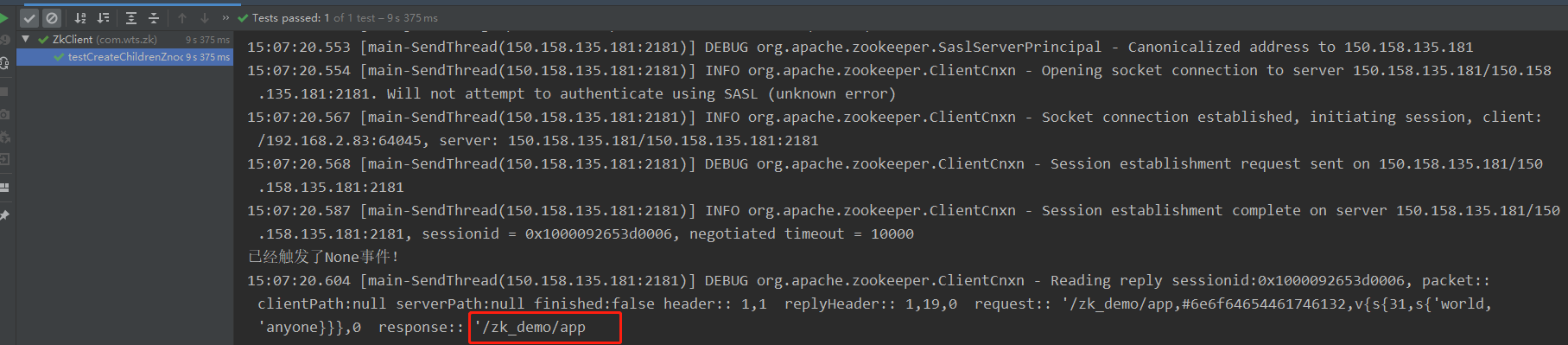
- 创建子节点
/**
* 创建子节点
*
* @throws KeeperException
* @throws InterruptedException
*/
@Test
public void testCreateChildrenZnode() throws KeeperException, InterruptedException {
// 参数1:要创建的节点的路径; 参数2:节点数据 ; 参数3:节点权限 ;参数4:节点的类型
zk.create(ZNODE_PATH_CHILDREN, "nodeData2".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
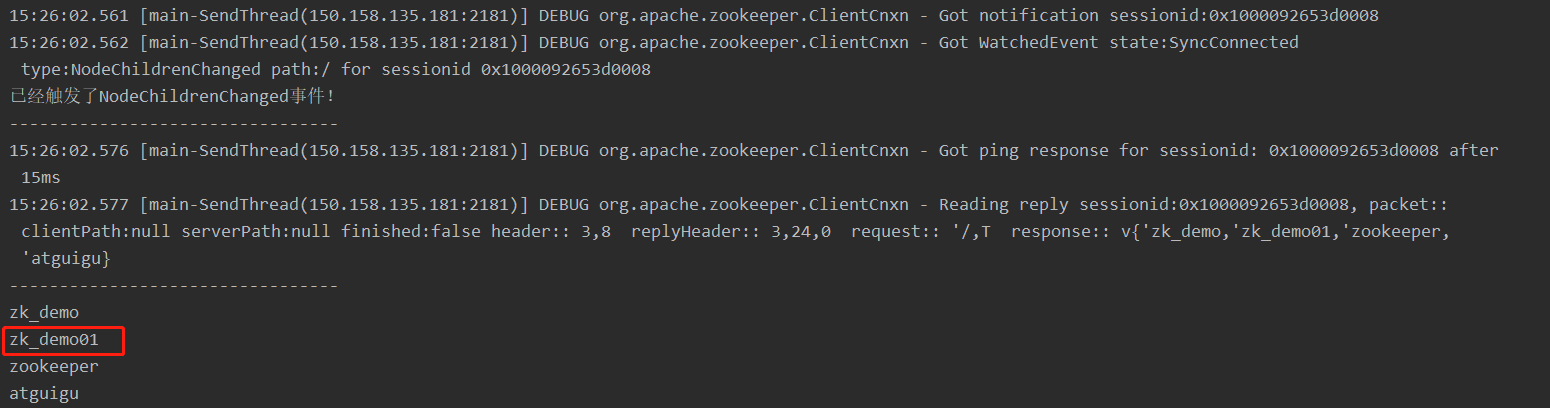
4. 监听节点变化
添加监听节点变化方法
// 监听节点变化
@Test
public void getChildren() throws Exception {
List<String> children = zk.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
// 延时阻塞
Thread.sleep(Long.MAX_VALUE);
}
修改init方法
/**
* zookeeper客户端
*
* @throws Exception
*/
@Before
public void init() throws Exception {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("已经触发了" + event.getType() + "事件!");
System.out.println("---------------------------------");
List<String> children = null;
try {
children = zk.getChildren("/", true);
System.out.println("---------------------------------");
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (String child : children) {
System.out.println(child);
}
}
});
}
当我们命令行操作创建节点的时候,发现会监听到我们创建的节点

注意:如果我们不在init的new Watcher匿名内部类方法放上查询方法,那么监听查询节点方法只能监听一次
【结果】
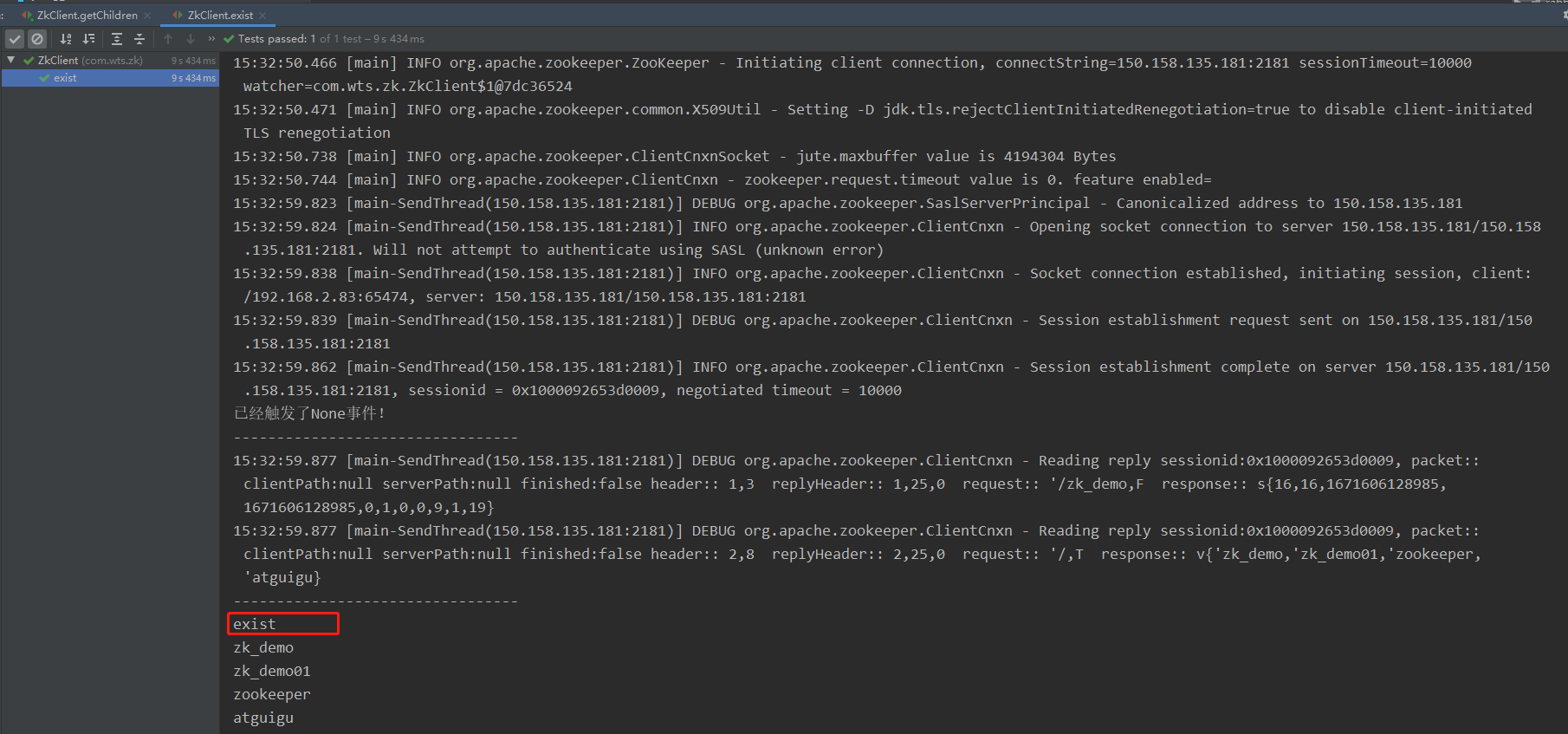
- 判断 Znode 是否存在
@Test
public void exist() throws Exception {
Stat stat = zk.exists(ZNODE_PATH, false);
System.out.println(stat == null ? "not exist" : "exist");
}
【结果】
- 获取节点数据
@Test
public void testGet() throws KeeperException, InterruptedException {
byte[] data1 = zk.getData(ZNODE_PATH, false, null);
byte[] data2 = zk.getData(ZNODE_PATH_CHILDREN, false, null);
log.info("{}的信息:{}", ZNODE_PATH, new String(data1));
log.info("{}的信息:{}", ZNODE_PATH_CHILDREN, new String(data2));
}
【结果】

- 删除
@Test
public void testDelete() throws KeeperException, InterruptedException {
// 指定要删除的版本,-1表示删除所有版本
zk.delete("/atguigu", -1);
}
【结果】

8. 删除含有子节点
@Test
public void testDeleteHasChildrenZnode() throws KeeperException, InterruptedException {
// 指定要删除的版本,-1表示删除所有版本
zk.delete(ZNODE_PATH, -1);
}
四、Zookeeper内部原理
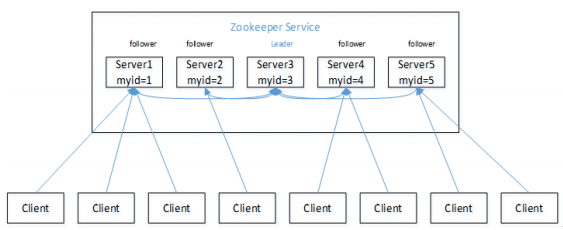
1、选举机制 - 第一次启动(面试重点)
- 半数机制:集群中半数以上机器存活,集群可用。所以
Zookeeper适合安装奇数台服务器。 Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。- 以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么,如图所示。
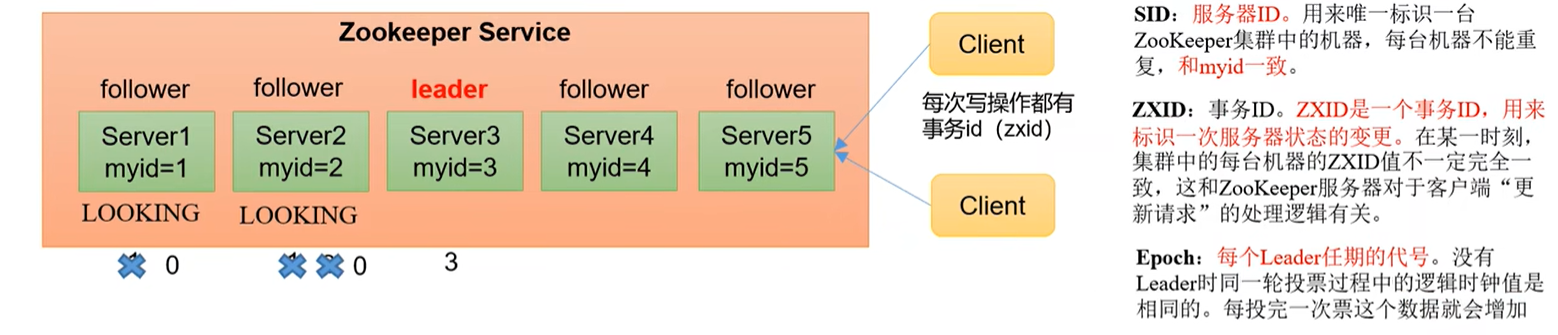
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报文没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。
2、选举机制 - 非第一次启动
(1)当zookeeper急群中的一台服务器出现以下的两种情况之一的时,就开始进入Leader选举:
- 服务器初始化启动
- 服务器运行期间无法和Leader保持连接
(2)而当一台机器进入Leader选举流程时,当前集群也可能处于以下两种状态: - 集群中本来就已经存在一个Leader.
对于第一种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并运行状态同步即可。 - 集群中确实不存在Leader。
假设Zookeeper由5台服务器组成,SID分别为1,2,3,4,5,ZXID分别为8、8、8、7、7。并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。

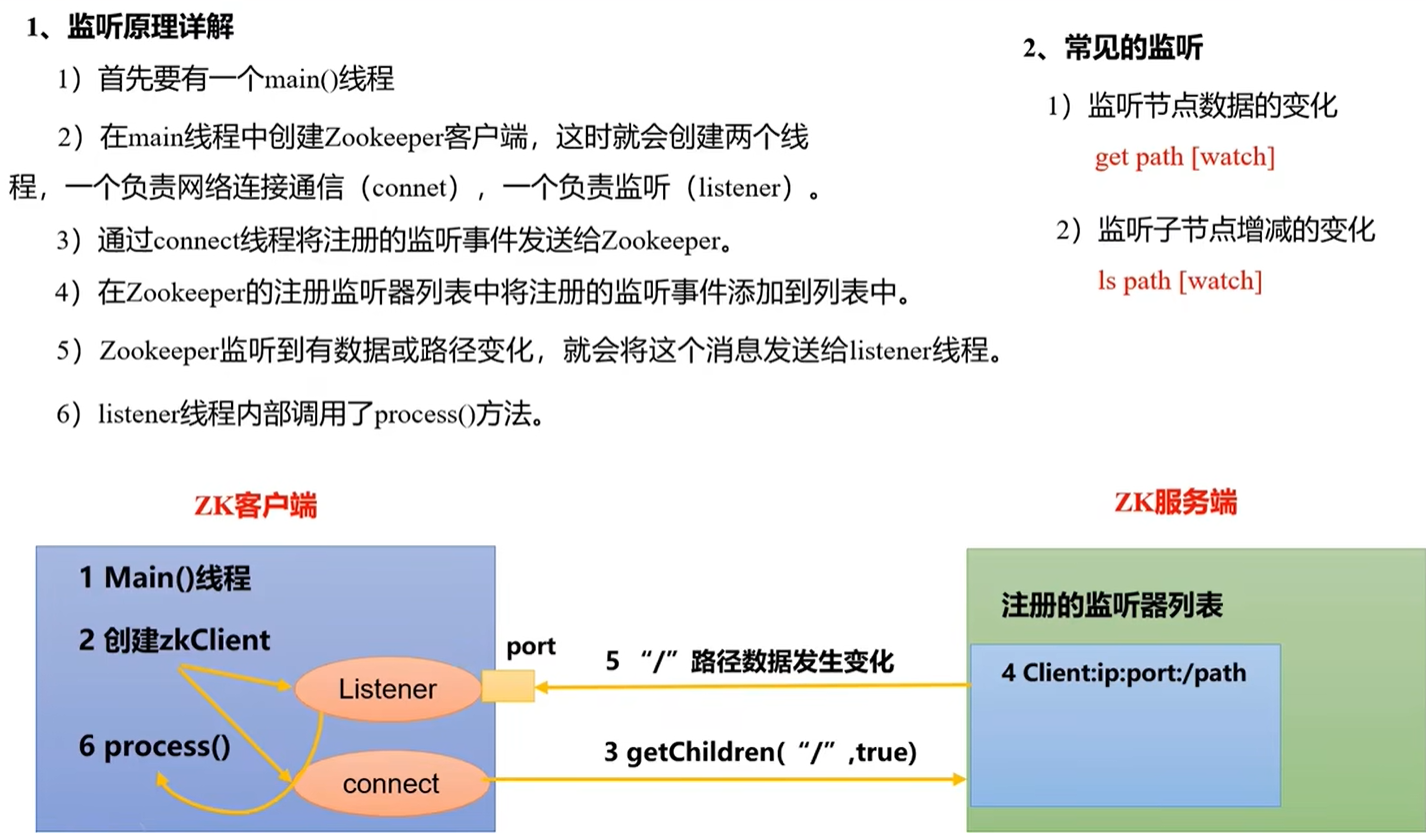
3、监听器原理(面试重点)
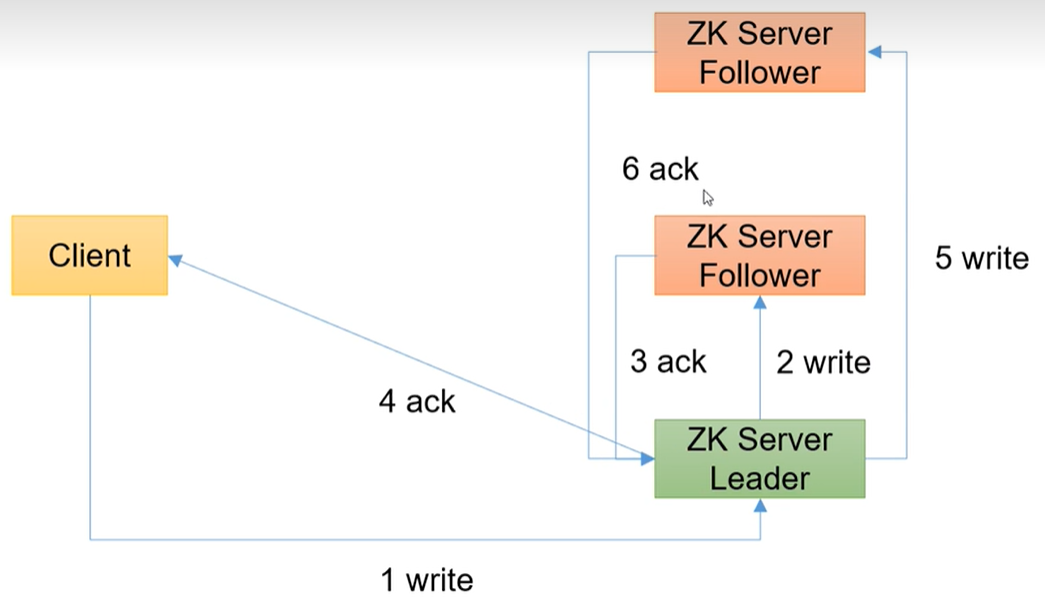
4、写数据流程
写流程写入请求直接发送给Leader节点
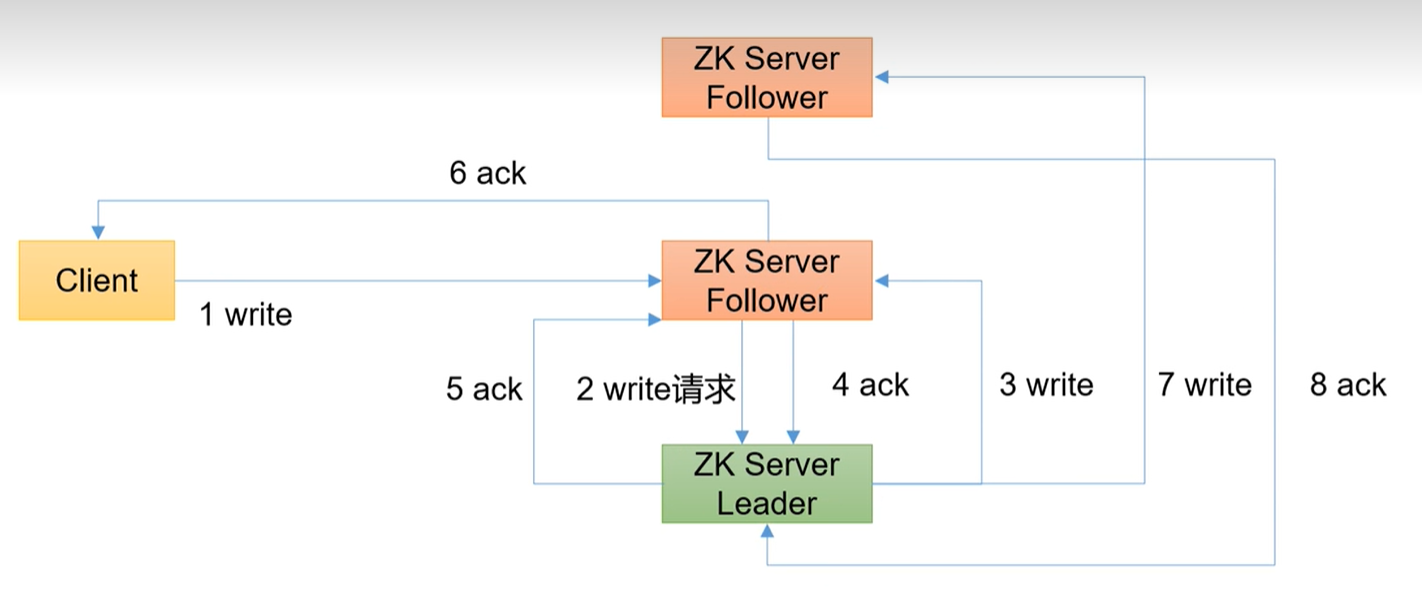
写流程写入请求直接发送给follower节点
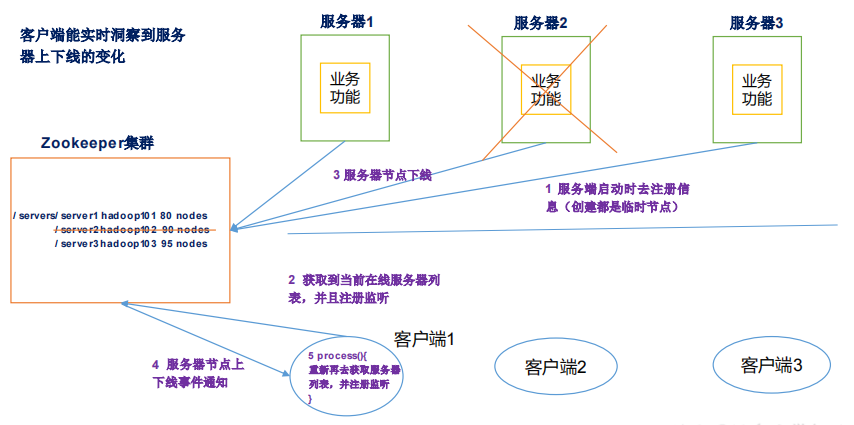
五、监听服务器节点动态上下线案例
-
需求
某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线。 -
需求分析
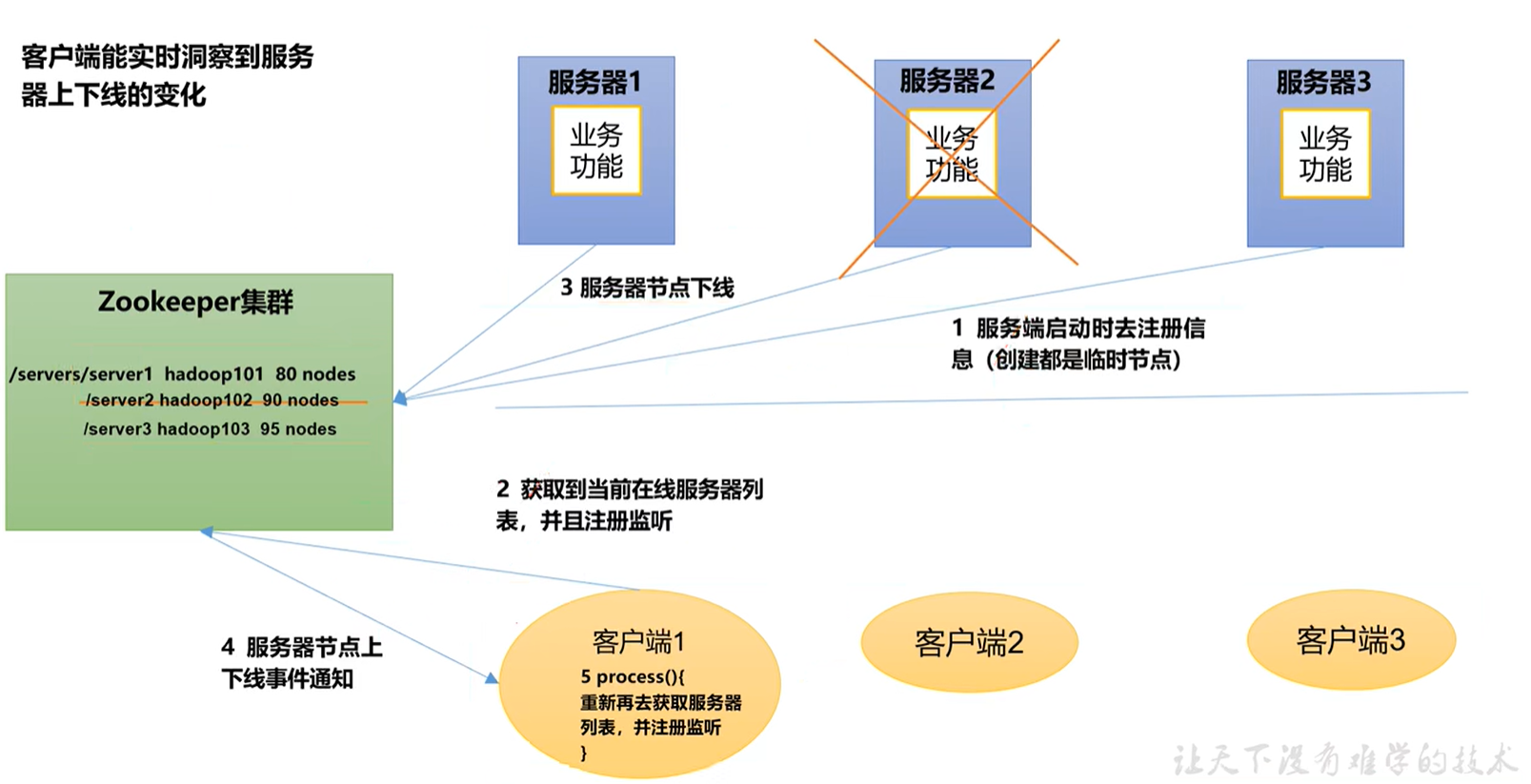
3.具体实现
- 先在集群上创建/servers 节点
[zk: localhost:2181(CONNECTED) 10] create /servers "servers"
Created /servers
- 服务器端向 Zookeeper 注册代码
public class DistributeServer {
private static String connectString = "150.158.135.181:2181";
private static int sessionTimeout = 10000;
ZooKeeper zk = null;
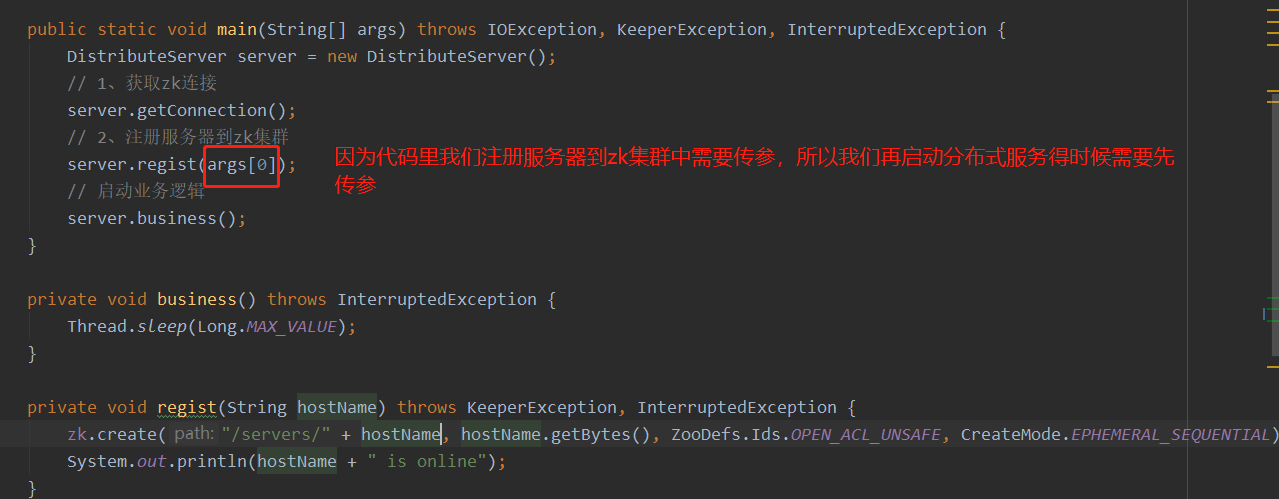
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
DistributeServer server = new DistributeServer();
// 1、获取zk连接
server.getConnection();
// 2、注册服务器到zk集群
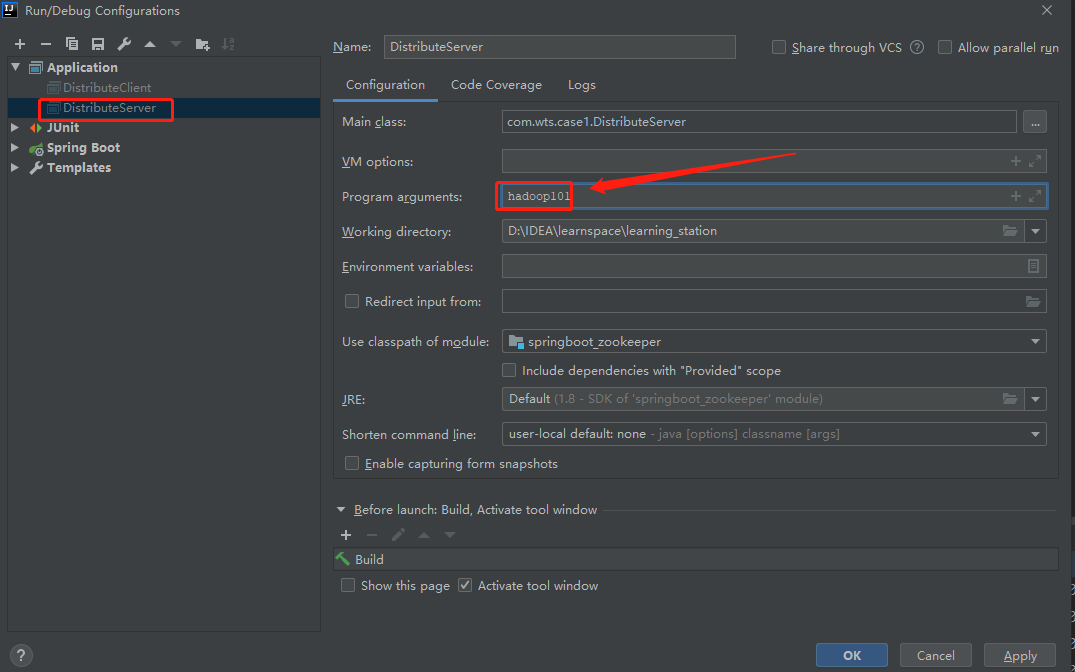
server.regist(args[0]);
// 启动业务逻辑
server.business();
}
private void business() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
private void regist(String hostName) throws KeeperException, InterruptedException {
zk.create("/servers/" + hostName , hostName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
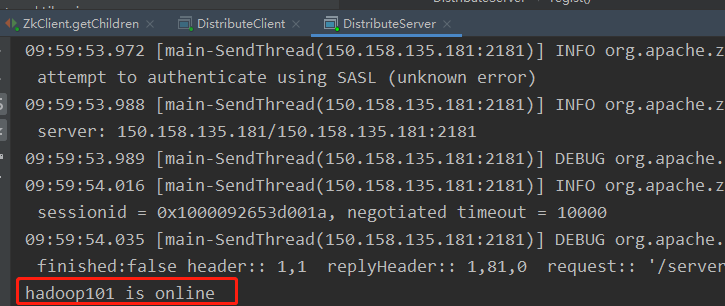
System.out.println(hostName + "is online");
}
private void getConnection() throws IOException {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
}
});
}
}
(2)客户端代码
public class DistributeClient {
private static String connectString = "150.158.135.181:2181";
private static int sessionTimeout = 10000;
ZooKeeper zk = null;
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
DistributeClient client = new DistributeClient();
// 1、获取zk连接
client.getConnection();
// 2、监听/servers下面子节点的增加和删除
client.getServerList();
// 3、业务逻辑
client.bussiness();
}
private void bussiness() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
private void getServerList() throws KeeperException, InterruptedException {
List<String> children = zk.getChildren("/servers", true);
ArrayList<String> servers = new ArrayList<>();
for (String child : children) {
byte[] data = zk.getData("/servers/" + child, false, null);
servers.add(new String(data));
}
// 打印
System.out.println(servers);
}
private void getConnection() throws IOException {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 再次启动监听
try {
getServerList();
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
}
测试
启动客户端创建三个临时有序号节点,我们看到数据正常



依次删除我们可以看到数据都正常






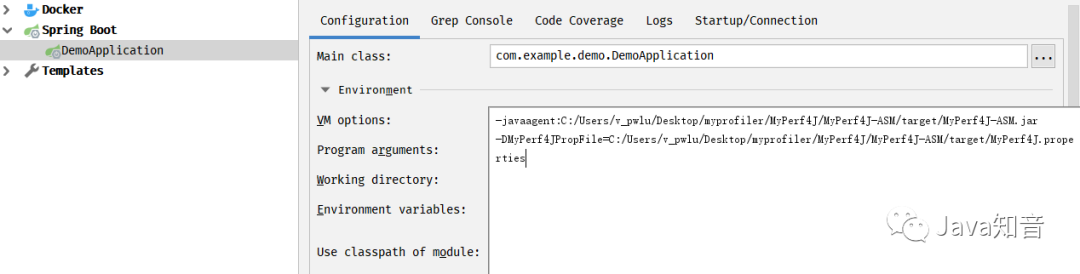
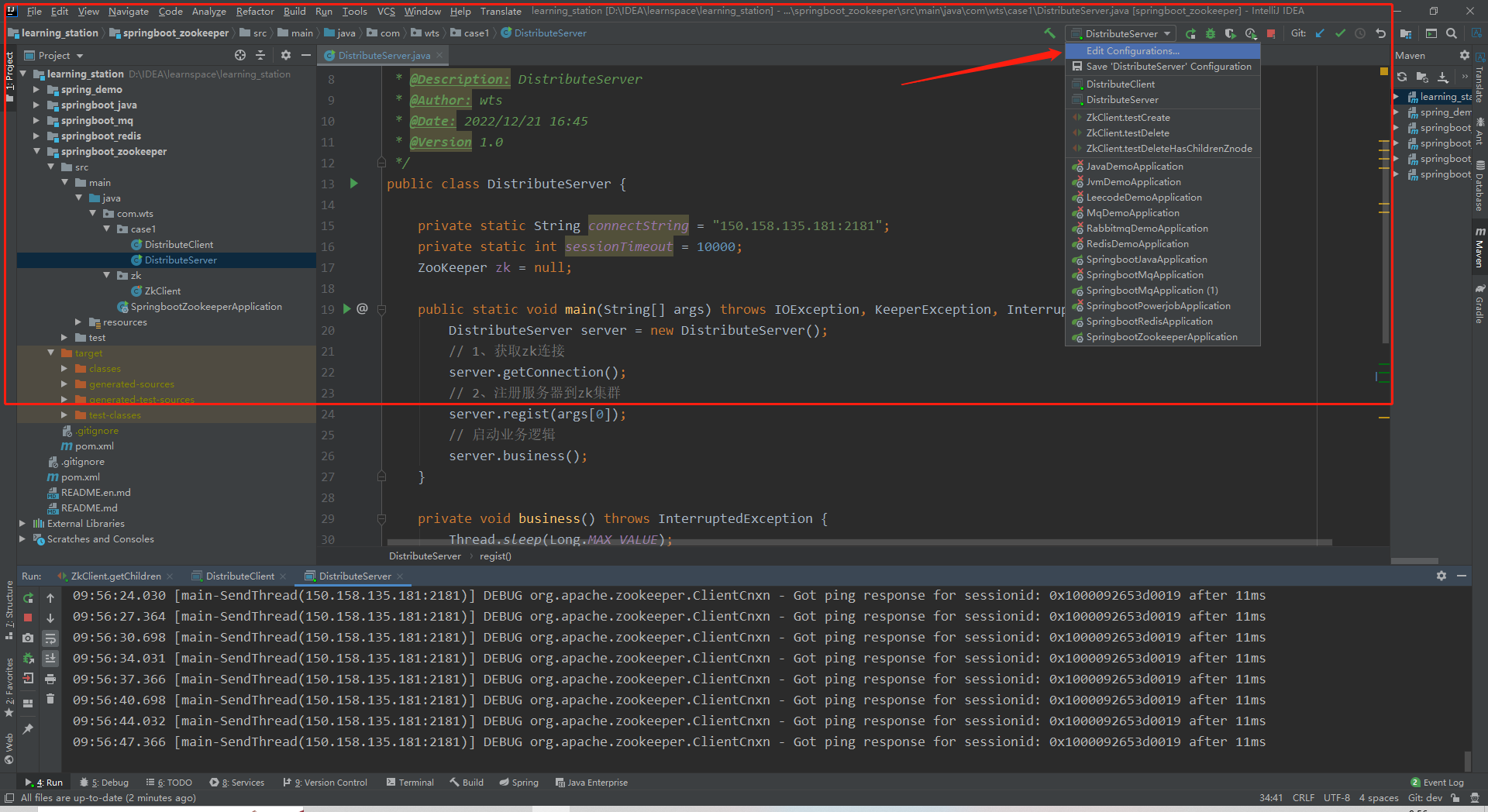
编辑Edit Configurations…
运行可以看到
【结果】

六、zookeeper分布式锁案例
1、什么叫分布式锁呢?
比如说“进程1”再使用该资源得时候,会先去获得锁,“进程1”获得锁以后会对该资源保持独占,这样其他进程就无法访问该资源,“进程1”用完该资源以后就会将锁释放掉,让其他进程来获得锁,那么通过这个锁机制,我们就能保证了分布式系统中读个进程能够有序得访问该临界资源。那么我们把这个分布式环境得这个锁叫做分布式锁。
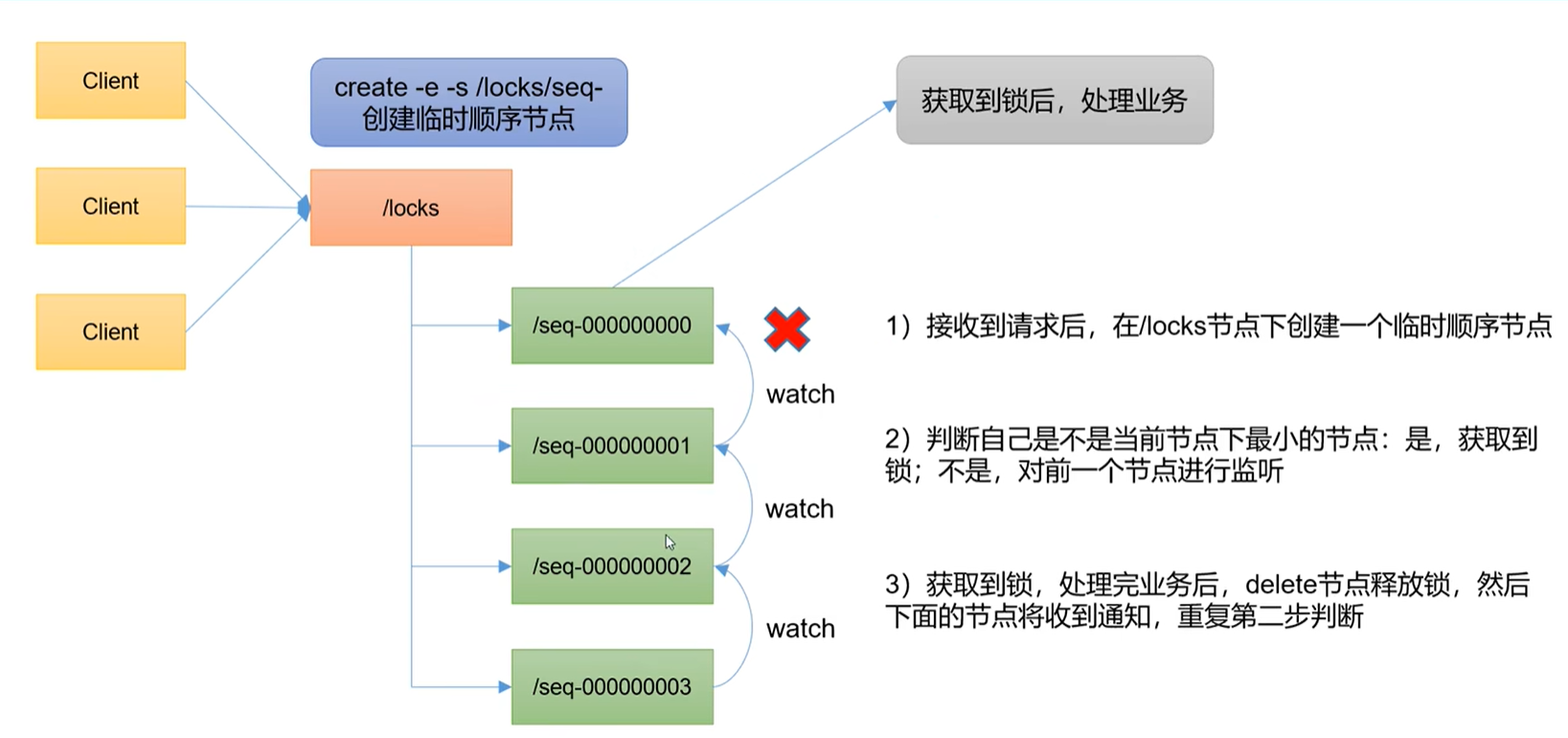
2、分布式锁案例分析
3、原生zookeeper实现分布式锁案例
public class DistributeLock {
private static String connectString = "150.158.135.181:2181";
private static int sessionTimeout = 10000;
ZooKeeper zk = null;
private CountDownLatch connectLatch = new CountDownLatch(1);
private CountDownLatch waitLatch = new CountDownLatch(1);
private String currentNode;
private String waitPath;
public DistributeLock() throws IOException, InterruptedException, KeeperException {
// 获取连接
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// connectLatch 如果连接上zk, 可以释放
if (event.getState() == Event.KeeperState.SyncConnected) {
connectLatch.countDown();
}
// waitLatch需要释放
if (event.getType() == Event.EventType.NodeDeleted && event.getPath().equals(waitLatch)) {
waitLatch.countDown();
}
}
});
// 等待zk正常连接后,往下走程序
connectLatch.await();
// 判断根节点/locks是否存在
Stat stat = zk.exists("/locks", false);
if (stat == null) {
// 创建一个根节点
zk.create("/locks", "locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
/**
* 对zk加锁
*/
public void zkLock() throws KeeperException, InterruptedException {
//创建临时带序号节点
currentNode = zk.create("/locks/" + "seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 判断创建的节点是否是最小的序号节点,如果是获取到锁,如果不是监听他序号前一个节点
List<String> children = zk.getChildren("/locks", false);
// 如果children只有一个值,直接获取到锁,如果有多个节点那就要判断谁最小
if (children.size() == 1) {
return;
} else {
Collections.sort(children);
// 获取节点名称 seq-00000000
String thisNode = currentNode.substring("/locks/".length());
// 通过seq-00000000获取该节点在children集合的位置
int index = children.indexOf(thisNode);
// 判断
if (index == -1) {
System.out.println("数据异常");
} else if (index == 0) {
// 就一个节点,可以获取锁了
return;
} else {
// 需要监听 他前一个节点的变化
waitPath = "/locks/" + children.get(index - 1);
zk.getData(waitPath, true, null);
// 等待监听
waitLatch.await();
return;
}
}
}
/**
* 解锁
*/
public void unZkLock() throws KeeperException, InterruptedException {
// 删除节点
zk.delete(currentNode, -1);
}
}
测试
public class DistributeLockTest {
public static void main(String[] args) throws InterruptedException, IOException, KeeperException {
final DistributeLock lock1 = new DistributeLock();
final DistributeLock lock2 = new DistributeLock();
new Thread(new Runnable() {
@Override
public void run() {
try {
System.out.println("线程1 启动,获取到锁");
lock1.zkLock();
Thread.sleep(5 * 1000);
lock1.unZkLock();
System.out.println("线程1 释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
System.out.println("线程2 启动,获取到锁");
lock2.zkLock();
Thread.sleep(5 * 1000);
lock2.unZkLock();
System.out.println("线程2 释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}).start();
}
}
4、Curator框架实现分布式锁案例
1)、原生的Java API开发存在的问题
- 会话连接是异步的,需要自己去处理。比如使用CountDownLatch
- Watch需要重复注册,不然就不能生效
- 开发的复杂性还是比较高的。
- 不支持多节点删除和创建。需要自己递归删除
2)、Curator是一个专门解决分布式锁的矿机,解决原生Java API开发分布式遇到的问题
详情请查看官方问的:http://curator.apache.org/index.html
2)、观察控制台变化
线程1获取锁
线程1再次获取锁
线程1释放锁
线程1再次释放锁
线程2获取锁
线程2再次获取锁
线程2释放锁
线程2再次释放锁
六、企业面试题
1、选举机制
半数机制,超过半数的投票通过,即通过。
(1)、第一次启动选举规则
投票数过半时,服务器id大的胜出。
(2)、第二次启动选举规则
- EPOCH大的直接胜出
- EPOCH相同,事务id大的胜出。
- 事务id相同,服务器id大的胜出
2、生产集群安装多少zk合适
安装奇数台
生产经验
- 10台服务器:3台zk
- 20台服务器:5台zk
- 100台服务器:11台zk
- 200台服务器:11台zk
服务器台数多,好处:提高可靠性;坏处:提高通信延时
3、常用命令
ls get create delete