1、Python对并发编程的支持
- 多线程: threading, 利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成
- 多进程: multiprocessing, 利用多核CPU的能力,真正的并行执行任务
- 异步IO: asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
- 使用Lock对资源加锁,防止冲突访问
- 使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
- 使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果
- 使用subprocess启动外部程序的进程,并进行输入输出交互
2、 怎样选择多线程多进程多协程
Python并发编程有3三种方式:多线程Thread、多进程Process、多协程Coroutine
2.1 什么是CPU密集型计算、IO密集型计算?
CPU密集型(CPU-bound ) :
CPU密集型也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高
例如:压缩解压缩、加密解密、正则表达式搜索
IO密集型(I/0 bound):
IO密集型指的是系统运作大部分的状况是CPU在等I/O (硬盘/内存)的读/写操作,CPU占用率仍然较低。
例如:文件处理程序、网络爬虫程序、读写数据库程序(依赖大量的外部资源)
2.2 多线程、多进程、多协程的对比
一个进程中可以启动N个线程,一个线程中可以启动N个协程
多进程Process ( multiprocessing )
- 优点:可以利用多核CPU并行运算
- 缺点:占用资源最多、可启动数目比线程少
- 适用于:CPU密集型计算
多线程Thread ( threading)
- 优点:相比进程,更轻量级、占用资源少
- 缺点:
相比进程:多线程只能并发执行,不能利用多CPU ( GIL )
相比协程:启动数目有限制,占用内存资源,有线程切换开销 - 适用于: IO密集型计算、同时运行的任务数目要求不多
多协程Coroutine ( asyncio )
- 优点:内存开销最少、启动协程数量最多
- 缺点:支持的库有限制(aiohttp VS requests )、代码实现复杂
- 适用于:IO密集型计算、需要超多任务运行、但有现成库支持的场景
2.3 怎样根据任务选择对应技术?
flowchart LR
A[待执行任务]-->B{任务特点}
B --- C(CPU密集型)
C-->E(["使用多进程
multiprocessing"])
B ---D(IO密集型)
D-->F{"1、需要超多任务量?
2、有现成协程库支持?
3、协程实现复杂度可接受?"}
F -- 否---> G(["使用多线程
threading"])
F -- 是---> H(["使用多协程
asyncio"])
%% style选项为每个节点设置了颜色和边框样式
style A fill:#333399,color:#fff
style B fill:#fff,stroke:#CC6600
style C fill:#FFFFCC
style D fill:#FFFFCC
style E fill:#FF9999
style F fill:#fff,stroke:#CC6600
style G fill:#FF9999
style H fill:#FF9999
%% linkStyle选项为连接线设置颜色和样式
linkStyle 1 stroke:blue,stroke-width:1px;
linkStyle 3 stroke:blue,stroke-width:1px;
3、 Python速度慢的罪魁祸首——全局解释器锁GIL
3.1 Python速度慢的两大原因
相比C/C+ +/JAVA, Python确实慢,在一些特殊场景 下,Python比C+ +慢100~ 200倍
由于速度慢的原因,很多公司的基础架构代码依然用C/C+ +开发
比如各大公司阿里/腾讯/快手的推荐引擎、搜索引擎、存储引擎等底层对性能要求高的模块
Python速度慢的原因1
动态类型语言,边解释边执行
Python速度慢的原因2
GIL ,无法利用多核CP并发执行
3.2 GIL是什么?
全局解释器锁( 英语: Global Interpreter Lock,缩写GIL)
是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。
即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。
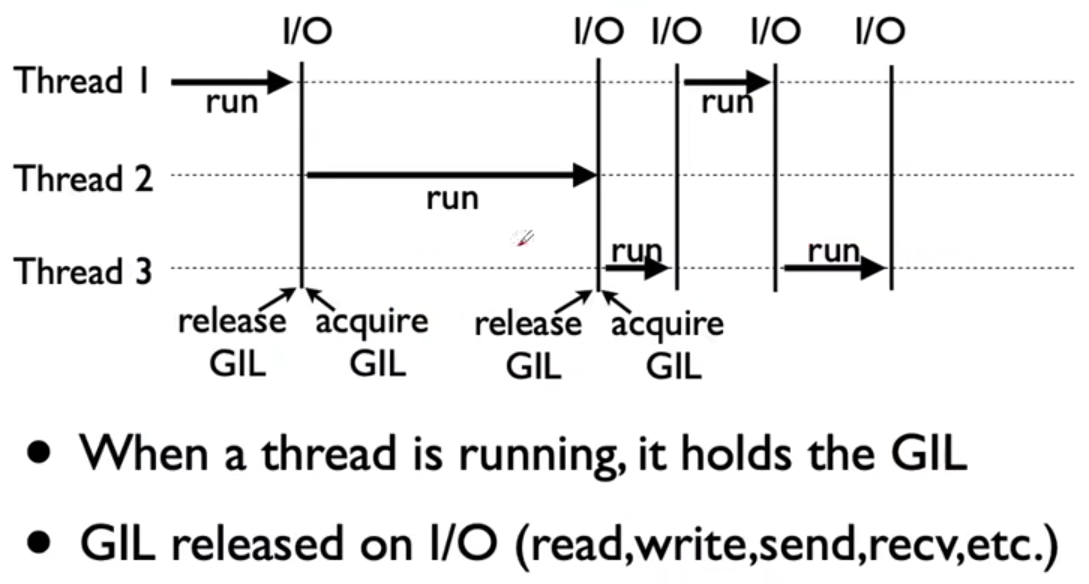
由于GIL的存在,即使电脑有多核CPU,单个时刻也只能使用1个,相比并发加速的C+ +/JAVA所以慢
3.3 为什么有GIL .这个东西?
简而言之: Python设计初期,为了规避并发问题引入了GIL,现在想去除却去不掉了!
为了解决多线程之间数据完整性和状态同步问题
Python中对象的管理,是使用引用计数器进行的,引用数为0则释放对象
开始:线程A和线程B都引用了对象obj,obj.ref_ num = 2,线程A和B都想撤销对obj的引用
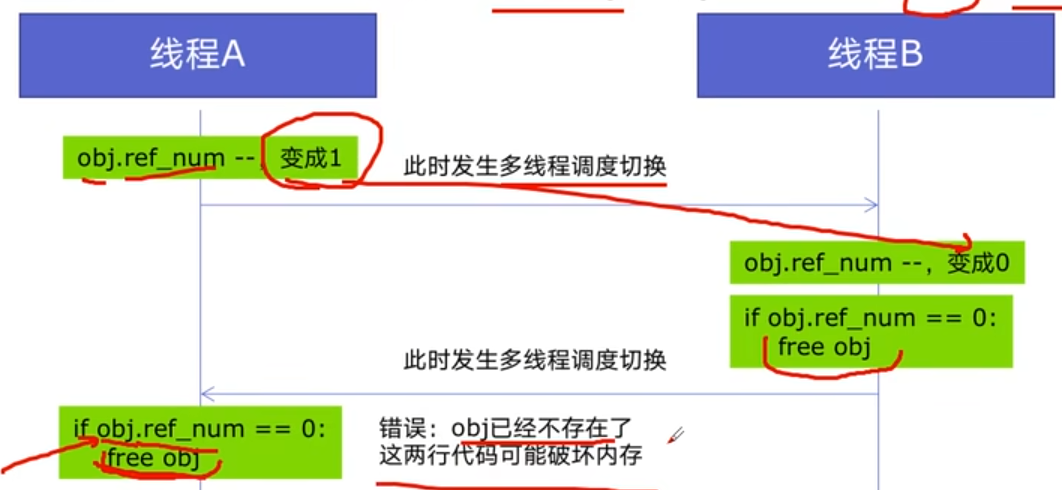

GIL确实有好处:简化了Python对共享资源的管理;
3.4 怎样规避GIL带来的限制?
多线程threading机制依然是有用的,用于IO密集型计算
因为在I/O (read,write ,send,recv,etc. )期间,线程会释放GIL,实现CPU和IO的并行
因此多线程用于IO密集型计算依然可以大幅提升速度
但是多线程用于CPU密集型计算时,只会更加拖慢速度
使用multiprocessing的多进程机制实现并行计算、利用多核CPU优势
为了应对GIL的问题,Python提供了multiprocessing
4、使用多线程,爬虫被加速
4.1 Python创建多线程的方法
1、准备一个函数
def my_func(a,b):
do_craw(a,b)
2、创建一个线程
import threading
t = threading.Thread(target=my_func,args=(100,200))
3、启动线程
t.start()
4、等待结束
t.join()
4.2 改写爬虫程序,变成多线程爬取
blog_spider.py程序
import requests
urls = [
f"https://www.cnblogs.com/sitehome/p/{page}"
for page in range(1, 50 + 1)
]
def craw(url):
r = requests.get(url)
print(url, len(r.text))
import blog_spider
import threading
import time
def single_thread():
print("single_thread begin...")
for url in blog_spider.urls:
blog_spider.craw(url)
print("single_thread end...")
def multi_thread():
print("multi_thread begin...")
threads = []
for url in blog_spider.urls:
threads.append(threading.Thread(target=blog_spider.craw,args=(url,)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print("multi_thread end...")
if __name__ == '__main__':
start = time.time()
single_thread()
end=time.time()
print("single thread cost:",end-start,"seconds")
begin = time.time()
multi_thread()
finish = time.time()
print("multi thread cost:", finish - begin, "seconds")
4.3 速度对比:单线程爬虫VS多线程爬虫



5 Python实现生产者消费者爬虫
5.1 多组件的Pipeline技术架构
复杂的事情一般都不会一下子做完, 而是会分很多中间步骤一步步完成。

graph LR
O[ ] --> |输入数据|A(处理器1)-->|中间数据|B(处理器X<br>很多个)-->|中间数据|C(处理器N)-->|输出数据|D[ ]
5.2 生产者消费者爬虫的架构
5.3 多线程数据通信的queue.Queue
5.4 代码编写实现生产者消费者爬虫
import requests
from bs4 import BeautifulSoup
urls = [
# f"https://www.cnblogs.com/#p{page}"
f"https://www.cnblogs.com/sitehome/p/{page}"
for page in range(1, 3 + 1)
]
def craw(url):
r = requests.get(url)
return r.text
def parse(html):
soup=BeautifulSoup(html,'html.parser')
links = soup.find_all('a',class_="post-item-title")
return [(link["href"],link.get_text()) for link in links]
if __name__ == '__main__':
for result in parse(craw(urls[0])):
print(result)
import blog_spider
import threading
import time
import queue
import random
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
print(threading.current_thread().name, f"craw {url}",
"url_queue.size=", url_queue.qsize())
# time.sleep(random.randint(1, 2))
def do_parse(html_queue: queue.Queue, fout):
while True:
html = html_queue.get()
results = blog_spider.parse(html)
for result in results:
fout.write(str(result) + "\n")
print(threading.current_thread().name, f"results.size {len(results)}",
"html_queue.size=", html_queue.qsize())
# time.sleep(random.randint(1, 2))
if __name__ == '__main__':
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{idx}")
t.start()
fout = open("02.data.txt", 'w', encoding='utf-8')
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse{idx}")
t.start()
6、Python线程安全问题以及解决方案
import threading
import time
lock = threading.Lock()
class Accout():
def __init__(self,balance):
self.balance=balance
def draw(accout,amount):
with lock:
if accout.balance>=amount:
time.sleep(0.1)
print(threading.current_thread().name,"取钱成功")
accout.balance-=amount
print(threading.current_thread().name, "余额",accout.balance)
else:
print(threading.current_thread().name, "取钱失败,余额不足")
if __name__ == '__main__':
accout=Accout(1000)
ta = threading.Thread(target=draw,args=(accout,600))
tb = threading.Thread(target=draw, args=(accout, 600))
ta.start()
tb.start()
ta.join()
tb.join()
7、Python好用的线程池ThreadPoolExecutor
import concurrent.futures
import blog_spider
with concurrent.futures.ThreadPoolExecutor() as pool:
htmls = pool.map(blog_spider.craw, blog_spider.urls)
htmls = list(zip(blog_spider.urls, htmls))
for url, html in htmls:
print(url, len(html))
print("爬虫结束..")
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(blog_spider.parse, html)
futures[future] = url
# for future,url in futures.items():
# print(url,future.result())
for future in concurrent.futures.as_completed(futures):
# url = futures[future]
futures[future] = url
print(url, future.result())
8、Python使用线程池在Web服务中实现加速
import flask
import json
import time
from concurrent.futures import ThreadPoolExecutor
app = flask.Flask(__name__)
pool = ThreadPoolExecutor()
def read_db():
time.sleep(0.2)
return "db result"
def read_file():
time.sleep(0.1)
return "file result"
def read_api():
time.sleep(0.3)
return "api result"
@app.route("/")
def index():
result_file=pool.submit(read_file)
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps({
"result_file":result_file.result(),
"result_db": result_db.result(),
"result_db": result_api.result(),
})
if __name__ == '__main__':
app.run()
9、使用多进程multiprocessing模块加速程序的运行
import math
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time
PRIMES = [112272535095293] * 10
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def single_thread():
for num in PRIMES:
is_prime(num)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
if __name__ == '__main__':
start = time.time()
single_thread()
end = time.time()
print("single thread cost:", end - start, "secend")
start = time.time()
multi_thread()
end = time.time()
print("multi thread cost:", end - start, "secend")
start = time.time()
multi_process()
end = time.time()
print("multi process cost:", end - start, "secend")
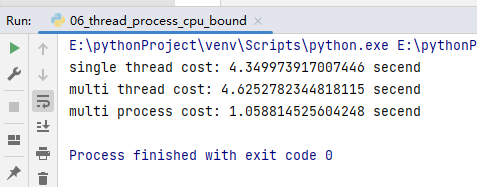
10、Python在Flask服务中使用多进程池加速程序运行
import flask
import math
import json
from concurrent.futures import ProcessPoolExecutor
app = flask.Flask(__name__)
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
@app.route("/is_prime/<numbers>")
def api_is_prime(numbers):
number_list = [int(x) for x in numbers.split(",")]
results = process_pool.map(is_prime, number_list)
return json.dumps(dict(zip(number_list, results)))
if __name__ == '__main__':
process_pool = ProcessPoolExecutor()
app.run()
11、Python异步IO实现并发爬虫
import asyncio
import aiohttp
import blog_spider
import time
async def async_craw(url):
print("爬虫开始:", url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"craw url:{url},{len(result)}")
loop = asyncio.get_event_loop()
tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("asyncio cost:", end - start, "second")
12、在异步IO中使用信号量控制爬虫并发度
import asyncio
import aiohttp
import blog_spider
import time
async def async_craw(url):
print("爬虫开始:", url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"craw url:{url},{len(result)}")
loop = asyncio.get_event_loop()
tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("asyncio cost:", end - start, "second")
参考:【2021最新版】Python 并发编程实战,用多线程、多进程、多协程加速程序运行