VIT (Vision Transformer) 模型论文+代码(源码)从零详细解读,看不懂来打我_哔哩哔哩_bilibili
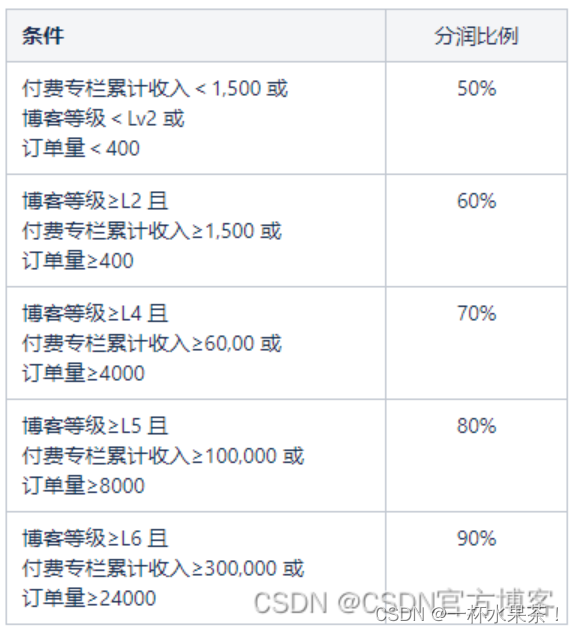
VIT模型架构图
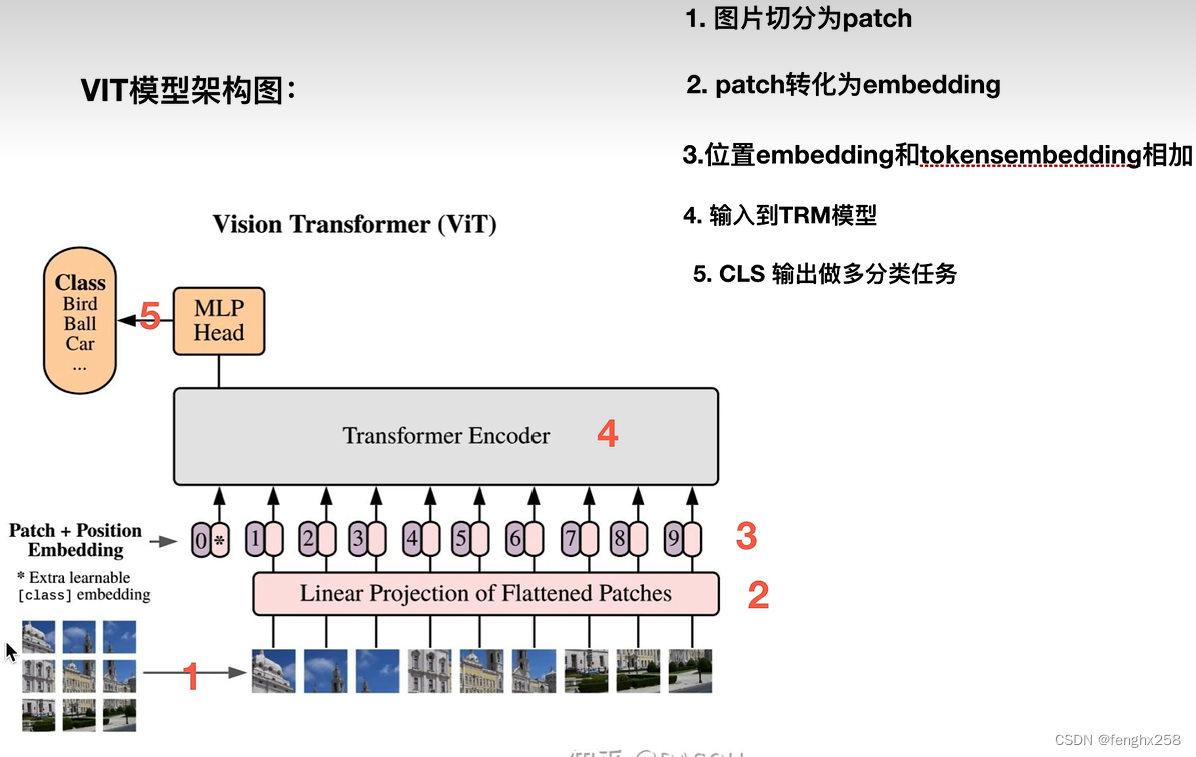
1.图片切分为patch
2. patch转化为embedding
1)将patch展平为一维长度
2)token embedding:将拉平之后的序列映射到规定的向量长度(transformer encoder 的embedding size)
实现方法有两种,一种是线性(此处展示为线性),一种是卷积操作
3.位置embedding和token embedding相加
1)生成CLS 符号的token embedding(图中粉色表示)
2)生成所有序列的位置编码。针对patch生成patch embedding,对应CLS是初始化了CLS的token embedding,位置编码(图中紫色表示)生成所有序列的位置编码
3)粉色和紫色相加,token embedding和位置embedding相加
位置信息

4.输入到TRM模型
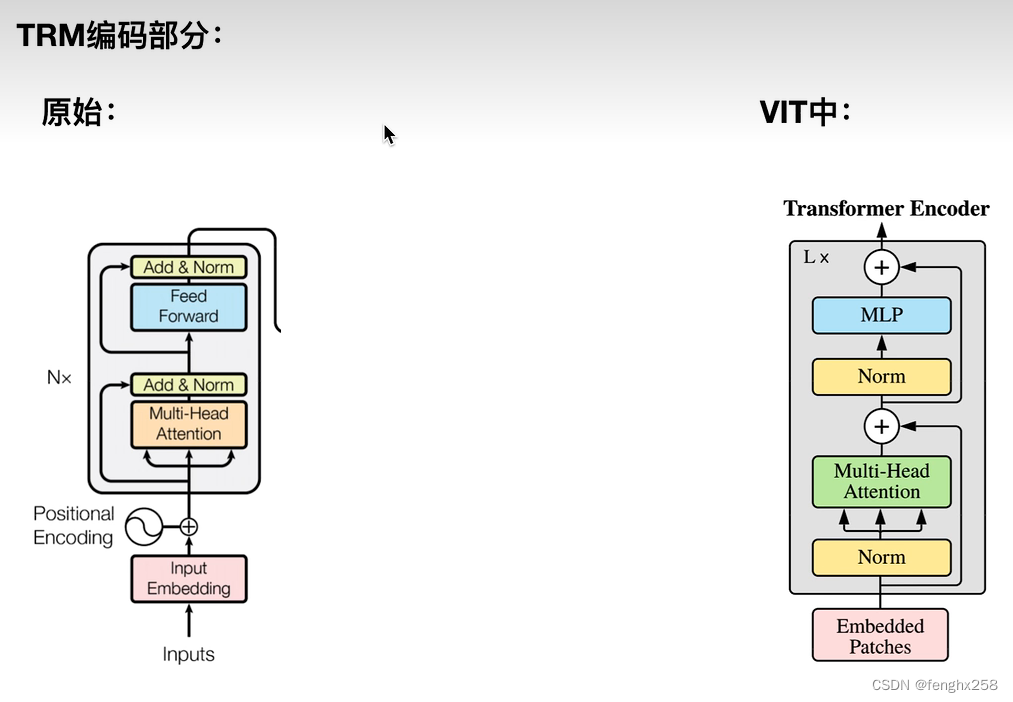
原始TRM中,Norm放在了多头自注意力机制(Muti-Head Attention)后面,Norm放在了前馈神经网络(Feed Forward)后面;在VIT中,Norm放在了多头自注意力机制(Muti-Head Attention)前面,Norm放在了前馈神经网络(Feed Forward)前面
VIT没有pad符号,不做边缘补0
5. CLS输出做多分类任务
复习
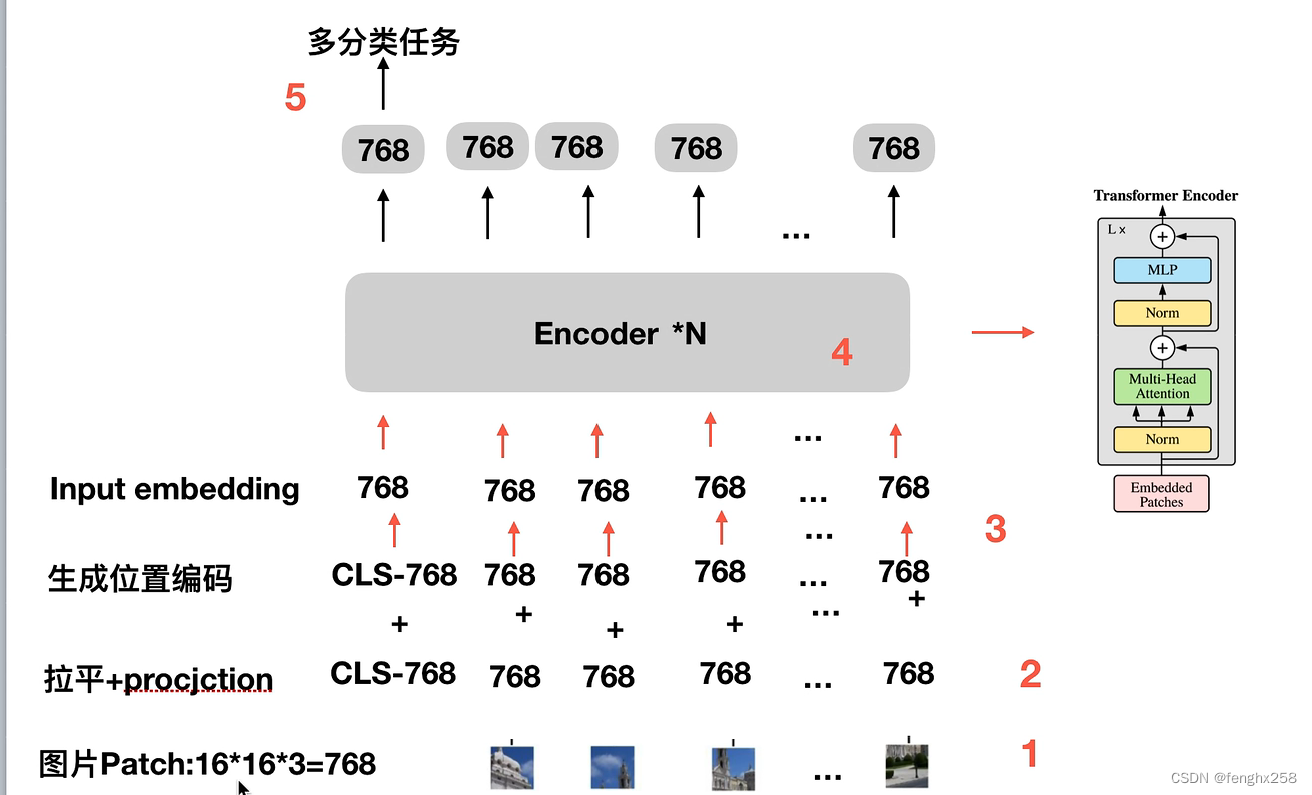
图片切分为patch
每个pacth拉平为768,映射为encode 中的embedding size,768
生成CLS初始化token embedding
拉平映射的token embedding和位置embedding相加得到Input embedding
输入到encoder中,*N对应多少层
最终每个token都会得到768输出,将每个输出进行多分类任务。