Conv1d 和 Conv2d 分别是卷积神经网络(CNN)中的两种卷积层操作,它们在处理不同维度的数据上有联系和区别,本文是一篇学习笔记。
本文主要包括以下内容:
- 1.联系
- 2.区别
- 3.Conv1d卷积
- 4.Conv2d卷积
- 5.图解Conv1d卷积
- (1)Full 卷积(全卷积,Full Convolution)
- (2)Same 卷积(相同卷积,Same Convolution)
- (3) Valid 卷积(有效卷积,Valid Convolution)
- 6.图解Conv2d卷积
- 7.Conv1d的pytorch实现
- (1)代码示例
- (2)注意事项
- 8.Conv2d的pytorch实现
- (1)代码示例
- (2)注意事项
1.联系
-
卷积操作原理:无论是
Conv1d还是Conv2d,它们的基本原理都是一样的,都是通过卷积核(或滤波器)与输入数据进行卷积运算,以提取特征。 -
神经网络中的使用:
Conv1d通常用于处理序列数据,如文本数据或音频数据,因为它在一个维度上进行卷积操作。而Conv2d通常用于处理图像数据,因为它在两个维度上进行卷积操作。 -
参数配置:它们都可以配置卷积核的大小、步幅、填充等参数,以控制卷积操作的行为。
2.区别
-
维度:最明显的区别是维度。
Conv1d是一维卷积,主要用于处理一维序列数据,如文本或音频。而Conv2d是二维卷积,主要用于处理二维数据,如图像。 -
卷积核的形状:在
Conv1d中,卷积核是一维的,通常表示为 (kernel_size,)。而在Conv2d中,卷积核是二维的,通常表示为 (height, width)。 -
输入数据的维度:
Conv1d的输入数据是一维的,形状通常为 (batch_size, channels, sequence_length),其中sequence_length表示序列的长度。而Conv2d的输入数据是二维的,形状通常为 (batch_size, channels, height, width),其中height和width表示图像的高度和宽度。 -
应用领域:由于不同的数据类型和维度要求,它们在不同的应用领域中得到广泛使用。
Conv1d用于文本分类、语音识别等,而Conv2d用于图像分类、目标检测等。
总之,Conv1d 和 Conv2d 是卷积神经网络中的两种常见卷积操作,它们在维度、卷积核的形状和应用领域等方面存在区别。选择合适的卷积层取决于输入数据的类型和任务要求。
3.Conv1d卷积
一维卷积在深度学习中有几种常见的变体,包括:
-
Valid 卷积(有效卷积,Valid Convolution): 这是一种常见的卷积操作,它不对输入进行填充,因此输出的大小会随着卷积核的大小和步幅的设置而减小。这意味着在有效卷积中,输出序列的长度会小于输入序列的长度。
-
Same 卷积(相同卷积,Same Convolution): Same 卷积旨在保持输出的大小与输入的大小相同。为了实现这一点,填充会添加到输入的两侧,以使输出大小保持不变。在一维卷积中,通常将填充大小设置为卷积核大小的一半。
-
Full 卷积(全卷积,Full Convolution): 全卷积操作的目标是生成一个输出大小大于输入大小的输出。这通常需要添加大量的填充以实现,以使输出的大小大于输入的大小。
这些卷积操作可以根据任务需求进行选择。Valid 卷积通常用于减小特征图的大小,以减少模型参数和计算成本。Same 卷积通常用于保持输出和输入的大小一致,有助于保留更多的信息。Full 卷积可能不太常见,但在某些特定情况下可能会有用。
选择哪种卷积操作取决于你的任务和模型设计的需要。
4.Conv2d卷积
在二维卷积中,通常不像一维卷积那样明确定义为有效卷积、相同卷积和全卷积。相反,二维卷积的种类更多,可以根据不同的需求和应用进行调整和组合。以下是一些常见的二维卷积类型和变体:
-
标准的二维卷积(2D Convolution):这是最常见的卷积操作,用于图像处理和计算机视觉等任务。
-
分离卷积(Separable Convolution):将标准的二维卷积分解成两个独立的卷积操作,分别在水平和垂直方向执行,以减少计算量。
-
转置卷积(Transpose Convolution或Deconvolution):用于上采样、反卷积和生成分割结果等任务,可以扩大特征图的尺寸。
-
空洞卷积(Dilated Convolution):通过在卷积核内部引入空洞(也称为膨胀率)来增加感受野,常用于语义分割等任务。
-
深度可分离卷积(Depthwise Separable Convolution):将卷积操作分成深度卷积和逐点卷积两个步骤,以减少参数数量和计算量。
-
膨胀卷积(Atrous Convolution):与空洞卷积类似,可以通过调整膨胀率来控制感受野的大小。
这些是二维卷积的一些常见类型和变体,根据任务需求和模型架构的不同,可以选择适当的卷积操作。二维卷积在图像处理和计算机视觉领域有广泛的应用,它们能够有效地捕捉和提取图像中的特征。
5.图解Conv1d卷积
以一个长度为5的一维张量I和长度为3的一维张量k(卷积核)为例,介绍其过程。
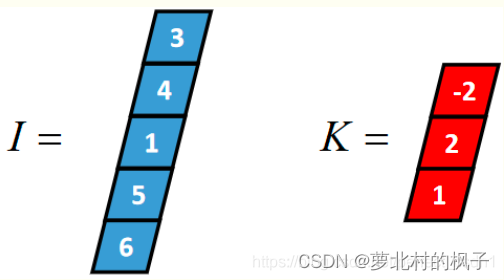
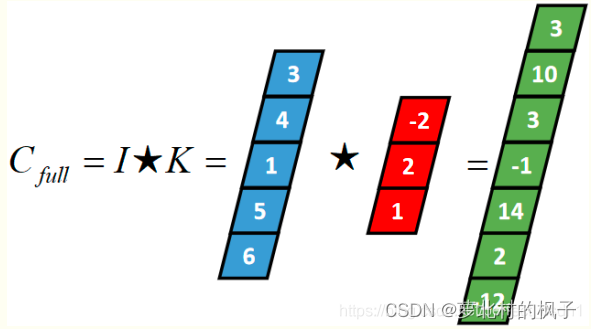
(1)Full 卷积(全卷积,Full Convolution)
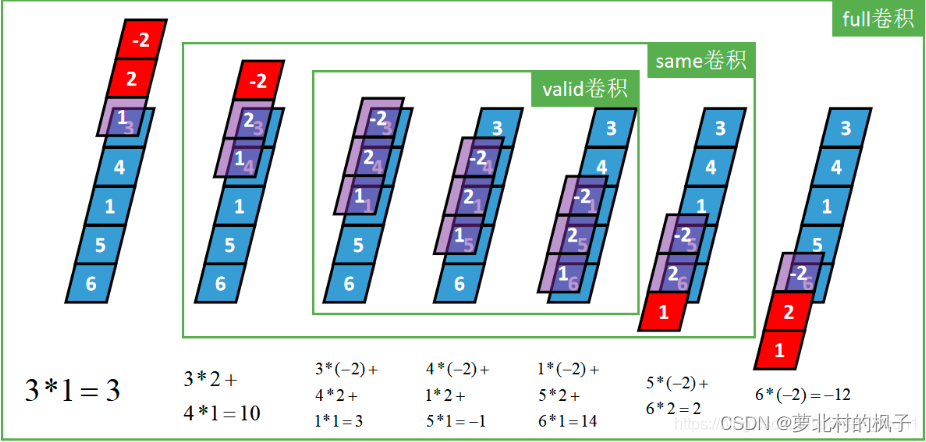
Full卷积的计算过程是:K沿着I顺序移动,每移动到一个固定位置,对应位置的值相乘再求和,计算过程如下:

将得到的值依次存入一维张量Cfull,该张量就是I和卷积核K的full卷积结果,其中K卷积核或者滤波器或者卷积掩码,卷积符号用符号表示,记Cfull=IK
(2)Same 卷积(相同卷积,Same Convolution)
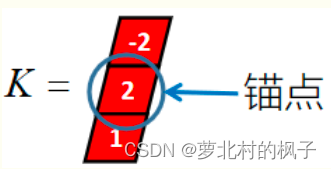
卷积核K都有一个锚点,然后将锚点顺序移动到张量I的每一个位置处,对应位置相乘再求和,计算过程如下:
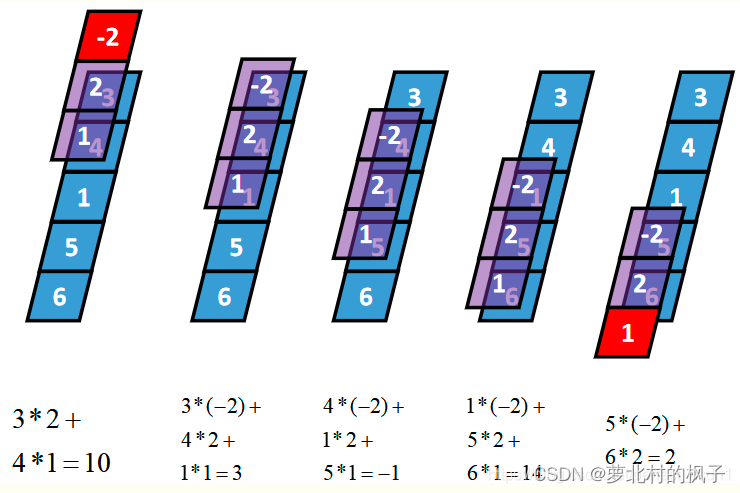
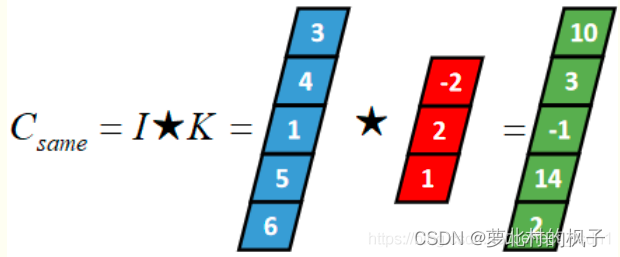
假设卷积核的长度为FL,如果FL为奇数,锚点位置在(FL-1)/2处;如果FL为偶数,锚点位置在(FL-2)/2处。
(3) Valid 卷积(有效卷积,Valid Convolution)
从full卷积的计算过程可知,如果K靠近I,就会有部分延伸到I之外,valid卷积只考虑I能完全覆盖K的情况,即K在I的内部移动的情况,计算过程如下:
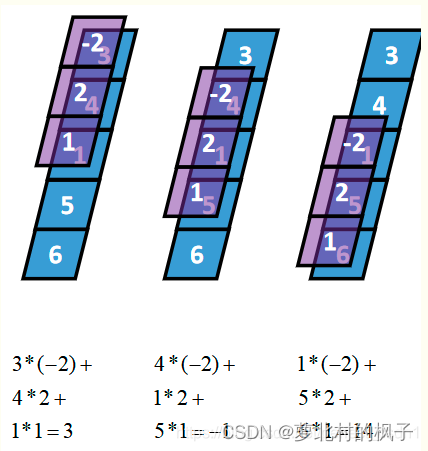
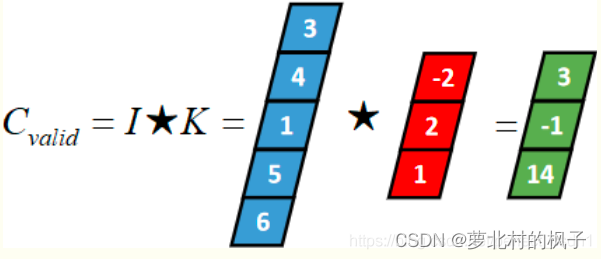
三种卷积类型的关系
6.图解Conv2d卷积
本文只介绍标准的二维卷积(2D Convolution)

下图蓝色表示输入,绿色表示输出,卷积核为:
| 0 | 1 | 2 |
|---|---|---|
| 2 | 2 | 0 |
| 0 | 1 | 2 |

7.Conv1d的pytorch实现
Conv1d 是一维卷积层,通常用于处理一维序列数据,如文本数据或时间序列数据。在深度学习中,它常用于提取序列数据中的特征。下面是 Conv1d 的基本用法以及一个示例:
首先,我们需要导入 PyTorch 中的相关库和模块:
import torch
import torch.nn as nn
然后,可以创建一个 Conv1d 层并指定一些参数,如输入通道数、输出通道数、卷积核大小、填充等。通常还需要定义一个激活函数(如 ReLU)来应用在卷积后的结果上。
# 创建 Conv1d 层
conv1d_layer = nn.Conv1d(in_channels, out_channels, kernel_size, stride, padding)
# 创建激活函数(可选)
relu = nn.ReLU()
接下来,我们可以使用 conv1d_layer 对输入数据进行卷积操作,并在卷积结果上应用激活函数。最后可以获得卷积后的结果。
# 对输入数据进行卷积操作
conv_output = conv1d_layer(input_data)
# 应用激活函数
output = relu(conv_output)
(1)代码示例
以下是一个示例,演示了如何使用 Conv1d 处理一维序列数据:
import torch
import torch.nn as nn
# 创建示例输入数据,假设有一批文本数据,每个文本包含10个单词,每个单词用一个嵌入向量表示
batch_size = 64
sequence_length = 10
embedding_dim = 50
# 随机生成输入矩阵
input_data = torch.randn(batch_size, embedding_dim, sequence_length)
# 创建 Conv1d 层,对文本数据进行卷积操作
in_channels = embedding_dim # 输入通道数,等于嵌入向量的维度
out_channels = 64 # 输出通道数,可以根据任务需求调整
kernel_size = 3 # 卷积核的大小,通常设置为3或5等
stride = 1 # 步幅,通常为1
padding = 1 # 填充大小,根据卷积核的大小和序列长度来调整
conv1d_layer = nn.Conv1d(in_channels, out_channels, kernel_size, stride, padding)
# 创建激活函数(ReLU)
relu = nn.ReLU()
# 对输入数据进行卷积操作
conv_output = conv1d_layer(input_data)
# 应用激活函数
output = relu(conv_output)
print(output.shape) # 输出的形状取决于卷积操作的参数设置
#torch.Size([64, 64, 10])
在这个示例中,我们首先创建了一个示例的输入数据,假设它是一批文本数据,每个文本包含10个单词,每个单词用一个50维的嵌入向量表示。然后,我们创建了一个 Conv1d 层,对文本数据进行卷积操作,最后应用了 ReLU 激活函数。输出的形状取决于卷积操作的参数设置。通常,你可以将卷积操作的输出作为后续神经网络的输入,以继续进行任务如文本分类或情感分析。
(2)注意事项
在上述代码中,padding 参数的不同值将会影响卷积的类型,具体如下:
1) padding=0: 如果将 padding 设置为 0,那么卷积将执行有效卷积(Valid Convolution)。这意味着卷积核只会在输入的有效区域内滑动,输出的大小会随着卷积核的大小和步幅而减小。
2) padding=1: 如果将 padding 设置为 1,那么卷积将执行一维 “same” 卷积(Same Convolution)。这意味着卷积核会在输入的两侧添加一个单位的填充,以保持输出的大小与输入的大小相同。
3)****padding = kernel_size - 1: 假设你的卷积核大小为 kernel_size,那么要实现一维 Full 卷积,padding 的值应该是 kernel_size - 1。例如,如果你的卷积核大小为kernel_size= 3,那么为了执行一维 Full 卷积(Full Convolution),你应该将padding设置为 2,因为 3 - 1 = 2。这将在输入序列的两侧分别添加 2 个单位的填充,从而使输出的大小大于输入的大小。
所以,不同的 padding 值会导致不同类型的卷积操作,其中 padding=0 对应有效卷积,而 padding=1 对应一维 “same” 卷积, kernel_size - 1对应全卷积。这会影响输出的大小和卷积操作的性质。你可以根据你的任务需求选择适当的填充方式。
8.Conv2d的pytorch实现
Conv2d 是二维卷积层,通常用于处理图像数据,它在卷积神经网络(CNN)中被广泛使用以提取图像中的特征。下面是 Conv2d 的基本用法以及一个示例:
首先,我们需要导入 PyTorch 中的相关库和模块:
import torch
import torch.nn as nn
然后,我们可以创建一个 Conv2d 层并指定一些参数,如输入通道数、输出通道数、卷积核大小、填充等。同样的,还需要定义一个激活函数(如 ReLU)来应用在卷积后的结果上。
# 创建 Conv2d 层
conv2d_layer = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# 创建激活函数(可选)
relu = nn.ReLU()
接下来,我们可以使用 conv2d_layer 对输入数据进行卷积操作,并在卷积结果上应用激活函数。最后可以获得卷积后的结果。
# 对输入数据进行卷积操作
conv_output = conv2d_layer(input_data)
# 应用激活函数
output = relu(conv_output)
(1)代码示例
以下是一个示例,演示了如何使用 Conv2d 处理图像数据:
import torch
import torch.nn as nn
# 创建示例输入数据,假设有一批图像数据,每个图像的尺寸为64x64像素,具有3个通道(RGB)
batch_size = 64
channels = 3
height = 64
width = 64
# 随机生成输入矩阵
input_data = torch.randn(batch_size, channels, height, width)
# 创建 Conv2d 层,对图像数据进行卷积操作
in_channels = channels # 输入通道数,等于图像的通道数
out_channels = 64 # 输出通道数,可以根据任务需求调整
kernel_size = 3 # 卷积核的大小,通常设置为3x3或5x5等
stride = 1 # 步幅,通常为1
padding = 1 # 填充大小,根据卷积核的大小和图像尺寸来调整
conv2d_layer = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# 创建激活函数(ReLU)
relu = nn.ReLU()
# 对输入数据进行卷积操作
conv_output = conv2d_layer(input_data)
# 应用激活函数
output = relu(conv_output)
print(output.shape) # 输出的形状取决于卷积操作的参数设置
# torch.Size([64, 64, 64, 64])
在这个示例中,我们首先创建了一个示例的输入数据,假设它是一批图像数据,每个图像的尺寸为64x64像素,具有3个通道(RGB)。然后,我们创建了一个 Conv2d 层,对图像数据进行卷积操作,最后应用了 ReLU 激活函数。输出的形状取决于卷积操作的参数设置。通常,你可以将卷积操作的输出作为后续神经网络的输入,以继续进行图像分类、目标检测或其他图像处理任务。
(2)注意事项
在上面的代码中,实现不同类型的二维卷积主要涉及改变卷积核的设置和使用不同的PyTorch卷积层。虽然padding值是其中一个参数,但它不是唯一的参数,不同类型的卷积需要更多的变化。以下是一些常见的二维卷积类型和变体以及它们的参数设置:
1) 标准的二维卷积:
使用 nn.Conv2d 创建卷积层,设置合适的 in_channels、out_channels、kernel_size、stride 和 padding。
2) 分离卷积:
分离卷积需要使用 nn.Conv2d 创建两个卷积层,一个用于深度卷积(depthwise),另一个用于逐点卷积(pointwise)。
需要合适地设置卷积核的大小和步幅,以及在两个卷积层之间进行数据的转换。
3) 转置卷积:
使用 nn.ConvTranspose2d 创建卷积层,设置合适的 in_channels、out_channels、kernel_size、stride 和 padding。
转置卷积通常用于上采样任务,所以通常会增大特征图的尺寸。
4) 空洞卷积:
使用 nn.Conv2d 创建卷积层,设置合适的 in_channels、out_channels、kernel_size、stride、padding 和 dilation(膨胀率)参数。
5) 深度可分离卷积:
深度可分离卷积需要使用 nn.Conv2d 创建两个卷积层,一个用于深度卷积,另一个用于逐点卷积。
需要合适地设置卷积核的大小和步幅,以及在两个卷积层之间进行数据的转换。
不同类型的卷积需要不同的设置,包括卷积核大小、步幅、填充等。因此,改变卷积类型通常需要更改卷积层的参数设置,并根据任务需求进行适当的调整。在PyTorch中,有多种不同类型的卷积层可以用来实现这些卷积操作,需要根据具体需求进行选择和配置。